Command Palette
Search for a command to run...
DynamicVLA:一种用于动态物体操作的视觉-语言-动作模型
DynamicVLA:一种用于动态物体操作的视觉-语言-动作模型
Haozhe Xie Beichen Wen Jiarui Zheng Zhaoxi Chen Fangzhou Hong Haiwen Diao Ziwei Liu
摘要
动态物体操作仍是视觉-语言-动作(Vision-Language-Action, VLA)模型面临的一项开放性挑战。尽管现有VLA模型在静态操作任务中展现出强大的泛化能力,但在需要快速感知、时序预测和持续控制的动态场景中仍表现欠佳。为此,我们提出DynamicVLA框架,旨在实现高效动态物体操作,其核心在于通过三项关键设计融合时序推理与闭环自适应机制:(1)采用轻量级0.4B参数量的VLA模型,结合卷积视觉编码器实现空间高效且结构保真的特征编码,从而支持快速的多模态推理;(2)连续推理(Continuous Inference)机制,支持推理与执行过程的重叠进行,显著降低延迟,并实现对物体运动的及时响应;(3)隐空间感知的动作流(Latent-aware Action Streaming),通过强制动作执行与感知状态在时间上对齐,有效弥合感知与执行之间的鸿沟。为弥补动态操作领域缺乏基础数据集的空白,我们构建了首个面向动态物体操作的基准测试平台——动态物体操作基准(Dynamic Object Manipulation, DOM)。该基准从零开始构建,依托自动化数据采集流水线,高效收集了涵盖2,800个场景、206种物体的20万条合成任务数据,并可无需遥操作即可快速采集2,000条真实世界任务数据。大量实验评估表明,DynamicVLA在响应速度、感知能力与泛化性能方面均实现显著提升,展现出在不同机器人形态间统一应对动态物体操作任务的强大潜力,为通用动态物体操作提供了一个统一、高效的框架。
一句话总结
南洋理工大学 S-Lab 的研究人员提出了 DynamicVLA,这是一个参数量仅 0.4B 的紧凑型 VLA 模型,采用连续推理与潜变量感知动作流技术,消除动态操作中的感知-执行间隙,并在他们新提出的 DOM 基准测试集上验证,该数据集包含 20 万合成场景和 2 千真实世界场景,覆盖多种机器人形态。
主要贡献
- DynamicVLA 引入了一个参数量为 0.4B 的紧凑型 VLA 模型,配备卷积视觉编码器,实现快速、空间高效的推理,支持在动态物体操作中进行实时闭环控制——延迟对任务成功率至关重要。
- 它实现了连续推理与潜变量感知动作流,消除感知-执行间隙和块间等待,确保即使在物体运动和推理延迟下,动作执行仍保持时间对齐且连续。
- 论文构建了 DOM 基准测试集,包含 20 万合成场景和 2 千真实世界场景,覆盖 2.8K 场景与 206 个物体,通过自动化流程采集,支持对动态操作任务中的感知、交互与泛化能力进行严格评估。
引言
作者利用视觉-语言-动作(VLA)模型应对动态物体操作这一关键挑战——机器人需对移动物体做出精确且实时的响应,而静态任务中延迟可被容忍。以往的 VLA 和机器人系统常受感知-执行延迟困扰,且缺乏动态场景数据,常依赖可预测运动或宽容任务(如拍球)。DynamicVLA 引入一个 0.4B 参数的紧凑模型,配备卷积视觉编码器以实现快速推理,并引入两个关键模块:连续推理用于重叠预测与动作,潜变量感知动作流用于丢弃过时指令并保持时间对齐。为支持评估与训练,他们构建了 DOM 基准测试集,通过自动化流程采集 20 万合成场景和 2 千真实世界场景,支持跨场景、物体与机器人形态的泛化评估。
数据集

-
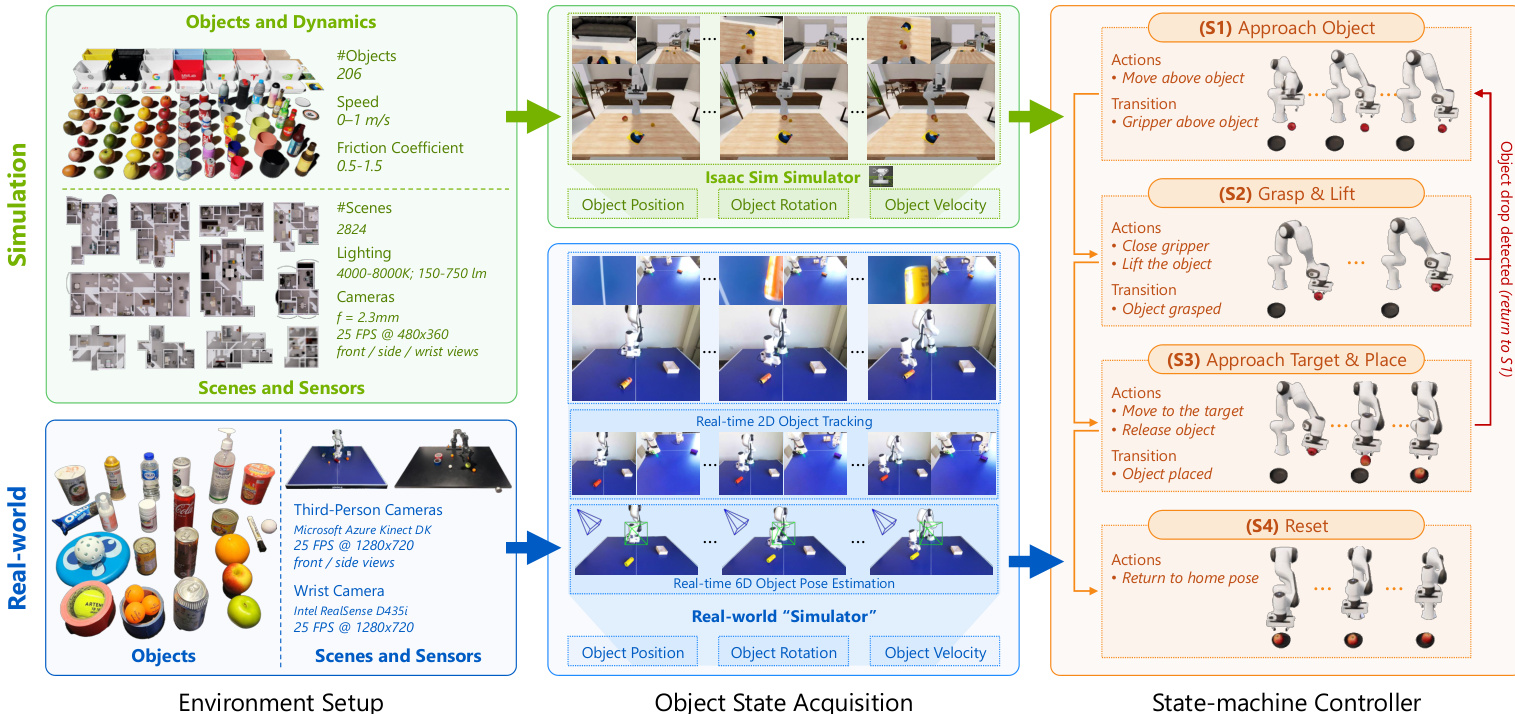
作者使用 DOM——首个面向动态物体操作的大规模基准测试集——填补机器人策略在移动物体上缺乏标准化数据集的空白。该数据集结合了 20 万来自仿真的合成场景和 2 千真实世界场景,后者因物体运动过快而难以通过人工遥操作采集。
-
真实世界数据来自一个定制“模拟器”系统,使用商用 RGB-D 传感器(两台 Azure Kinect DK 摄像头和腕部 RealSense D435i)实时估计物体的 6D 位姿与速度。该设置支持无需人工遥操作、高频数据采集(每场景约 10 秒),并覆盖 Franka 与 PiPER 机器人,实现一致的多形态评估。
-
真实世界场景包含 25 个家用物品(容器、食品、瓶子、工具),每场景含多个物体——部分为目标,其余为干扰项。物体状态通过 EfficientTAM 进行分割,再经几何三角测量获取 3D 质心,结合运动拟合估算速度,输出低延迟、控制器兼容的状态流。
-
与仿真中相同的四阶段控制器直接用于真实世界,输入为估算的 6D 物体状态与目标位姿。该统一管道确保仿真与真实环境行为一致,支持在交互、感知与泛化维度进行可扩展、可复现的评估。
方法
作者采用一个参数量为 0.4B 的紧凑型视觉-语言-动作(VLA)模型,称为 DynamicVLA,专为动态物体操作任务中的快速高效多模态推理而设计。整体框架整合了视觉-语言主干与基于扩散的动作专家,支持连续推理与时间一致的动作执行。架构设计旨在最小化延迟,同时在物体状态持续演化的环境中保持稳健的感知与推理能力。
视觉-语言主干采用卷积视觉编码器 FastViT,高效处理多帧视觉输入。该选择避免了基于 Transformer 的视觉编码器所固有的二次方 token 增长,支持对时间观测窗口进行可扩展处理。语言主干源自 SmolLM2-360M,截断至前 16 个 Transformer 层,以降低推理延迟,同时对多模态推理影响最小。视觉观测、语言指令与机器人本体状态被联合编码并由语言主干处理。具体而言,时间窗口内的 RGB 图像被拼接并由 FastViT 编码,输出一组降维的视觉 token。机器人的本体状态(32 维向量)被线性投影至语言嵌入空间,作为单个状态 token。这些视觉、语言与状态 token 被拼接后由语言主干处理,生成键值表示,并在推理周期中缓存复用。
动作生成由一个专用的基于扩散的动作专家处理,其实例化为从语言主干复制的轻量级 Transformer,同样截断至 16 层。该专家预测一个动作块,时间跨度为 n=20 步,足以在连续推理下保持低延迟。每个动作是一个 32 维向量,表示末端执行器位姿与夹爪状态。动作专家采用 720 的隐藏维度以降低计算量。训练期间,专家被优化以在从视觉观测提取的多模态特征 ft 条件下,对噪声动作块 Atτ 进行去噪,使用流匹配目标。目标定义为:
ℓτ(θ)=Ep(At∣ft),q(A∗τ∣At)[Eθ(Atτ,Ot)−u(Atτ∣At)]其中 q(Atτ∣At)=N(τAt,(1−τ)I) 且 Atτ=τAt+(1−τ)ϵ,ϵ∼N(0,I)。在此目标下,动作专家学习匹配去噪向量场 u(Atτ∣At)=ϵ−At。
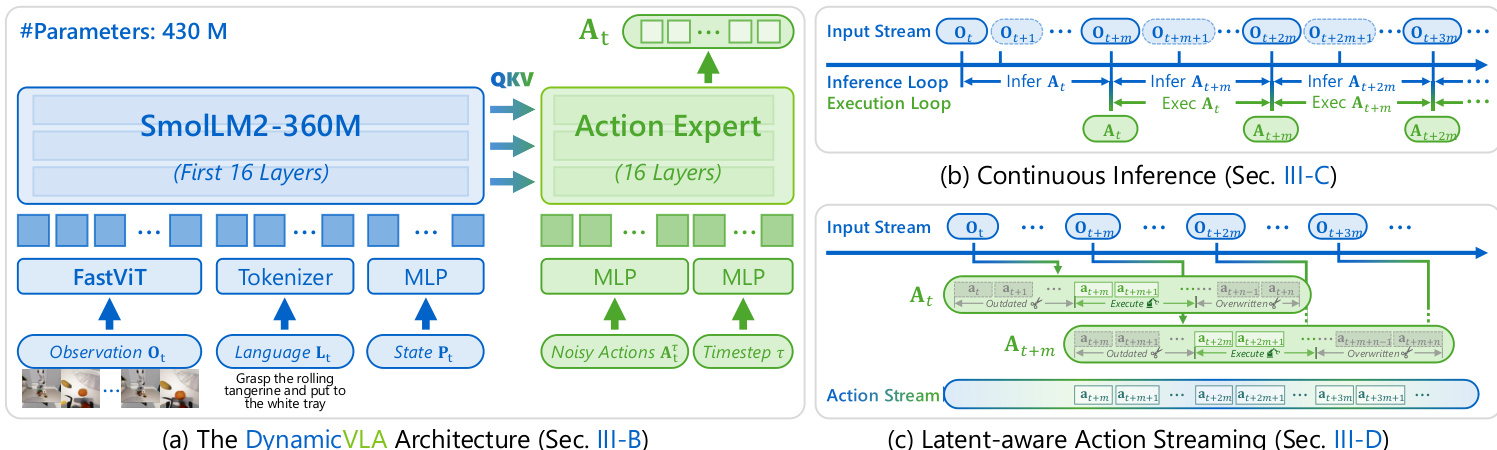
为应对动态环境中推理延迟的挑战,模型采用连续推理策略。在此范式下,一旦前次推理完成即触发新推理周期,无论前次预测的动作序列是否已执行完毕。该流水线方法允许在当前动作执行时并行推理下一动作序列,消除块间等待,实现非阻塞动作执行。推理延迟 m 表示推理周期开始与结束之间的时间步数。模型在时间 t 预测动作序列 At={at,…,at+n},下一推理周期在 t+m 开始,预测 At+m。
然而,连续推理导致预测动作与演化环境之间出现时间错位,表现为感知-执行间隙及重叠动作块间的冲突。为解决这些问题,作者实现了潜变量感知动作流(LAAS)策略。当前动作块 At 中对应于早于 t+m 时间步的动作被丢弃为过时。对于当前与下一动作块重叠的时间步,优先采用新序列 At+m 的动作,覆盖 At 中的动作。这确保执行能迅速适应最新环境状态,尤其在物体动态运动时。模型分三阶段训练:第一阶段在 1.5 亿英文图文对上预训练,第二阶段在合成的动态物体操作(DOM)数据集上中训,第三阶段在真实机器人演示上后训,以适配新形态与传感配置。
实验
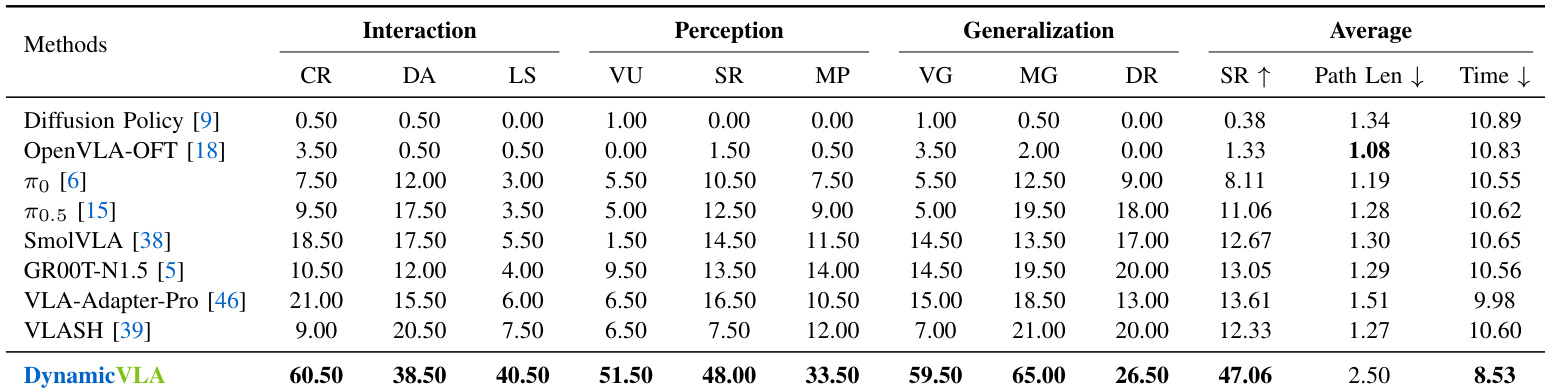
- DynamicVLA 在实时约束下动态物体操作中表现优异,在 DOM 基准测试(1800 次试验)的交互、感知与泛化维度上超越基线,交互任务成功率达 60.5%/38.5%/40.5%,较最佳基线提升 +188.1% 至 +440.0%。
- 在真实世界测试(Franka 与 PiPER 机械臂)中,DynamicVLA 在感知任务中成功率达 51.9%,而最佳基线仅为 11.7%,在运动下展现出卓越的时空推理能力。
- 泛化测试表明,DynamicVLA 对未见物体与运动模式鲁棒,但环境扰动仍具挑战;真实世界外观与运动变化下表现稳定。
- 消融实验确认 360M LLM 主干在容量与延迟间取得平衡;FastViT 编码器因低延迟优于 Transformer;连续推理与潜变量感知动作流对时间对齐至关重要,最高提升成功率 22.3%。
- 集成至 SmolVLA 与 π0.5 中,CI+LAAS 通用提升性能,但受限于模型特定推理延迟。
- 截断 16 层 LLM 主干提供最优效率-鲁棒性权衡;稀疏两帧视觉上下文(t-2, t)在无额外延迟下最大化运动感知。
- 在 RTX A6000 上以 88Hz 运行,占用 1.8GB GPU 显存,训练耗时两周,使用 32 张 A100 GPU。
作者通过消融研究评估 DynamicVLA 关键设计选择的影响,包括模型大小、视觉编码与执行机制。结果表明,结合连续推理与潜变量感知动作流的 360M 模型取得最高成功率 47.06%,移除任一组件均显著降低性能,表明二者在动态操作中维持稳定与响应性具有互补作用。
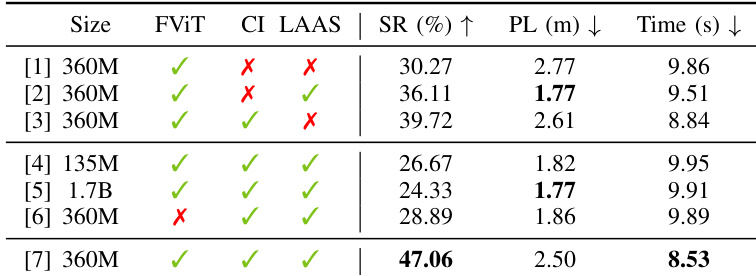
作者通过时间消融研究评估视觉上下文对动态操作性能的影响,调整观测窗口以包含不同组合的历史帧。结果表明,使用稀疏时间窗口(t−2 与 t 帧)取得最高成功率与最短任务完成时间,表明该配置在无冗余前提下提供最优运动线索。
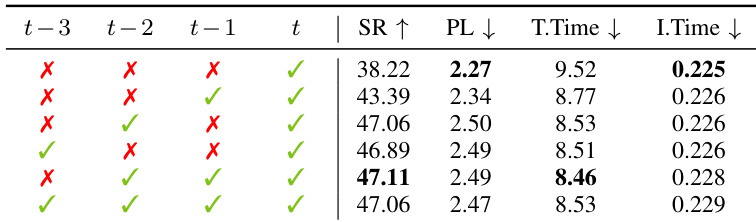
作者使用仿真基准测试评估 DynamicVLA 与基线模型在动态物体操作任务上的表现,报告成功率、路径长度与任务完成时间。结果表明,DynamicVLA 成功率达 47.06%,在成功率与任务完成时间上均优于 π₀.₅ 与 SmolVLA,同时路径长度更长。

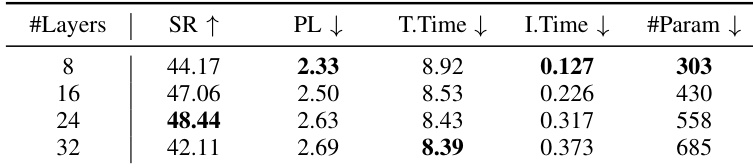
作者通过在推理时保留前 l 个 Transformer 层,评估 LLM 主干深度对 DynamicVLA 性能的影响。结果表明,16 层主干在保持高效推理的同时取得最高成功率,表明其在模型容量与计算效率间取得最优平衡。
结果表明,DynamicVLA 在动态物体操作基准测试中显著超越所有基线方法,在交互、感知与泛化类别中均取得最高成功率。作者通过表格展示,DynamicVLA 在闭环响应、动态适应与长时序规划中分别取得 60.5%、38.5% 与 40.5% 的成功率,大幅超越各交互子任务中的最佳基线。