Command Palette
Search for a command to run...
MMFineReason:通过开放数据驱动方法弥合多模态推理差距
MMFineReason:通过开放数据驱动方法弥合多模态推理差距
Honglin Lin Zheng Liu Yun Zhu Chonghan Qin Juekai Lin Xiaoran Shang Conghui He Wentao Zhang Lijun Wu
摘要
视觉语言模型(Vision Language Models, VLMs)的最新进展显著推动了视觉推理能力的发展。然而,当前开源VLMs在性能上仍显著落后于闭源系统,其主要原因在于高质量推理数据的匮乏。现有数据集在涵盖STEM图示、视觉谜题等高难度领域方面覆盖有限,且缺乏一致的、长序列的思维链(Chain-of-Thought, CoT)标注,而这类标注对于激发模型强大的推理能力至关重要。为弥合这一差距,我们提出MMFineReason——一个大规模多模态推理数据集,包含180万条样本和51亿个解题标记(solution tokens),其高质量的推理标注源自Qwen3-VL-235B-A22B-Thinking模型的提炼。该数据集通过一个系统化的三阶段流程构建:(1)大规模数据收集与标准化;(2)思维链推理过程生成;(3)基于推理质量与难度感知的综合筛选。最终形成的数据库涵盖STEM问题、视觉谜题、游戏场景及复杂图示,每条样本均配有基于视觉信息的可解释推理轨迹。基于MMFineReason,我们对Qwen3-VL-Instruct模型进行了微调,开发出MMFineReason-2B/4B/8B三个版本。实验结果表明,这些模型在各自参数规模类别中均达到了新的最先进水平。尤为突出的是,MMFineReason-4B在多项任务上超越了Qwen3-VL-8B-Thinking,而MMFineReason-8B甚至在性能上超过Qwen3-VL-30B-A3B-Thinking,并接近Qwen3-VL-32B-Thinking的表现,展现出卓越的参数效率。关键发现在于,通过引入难度感知的过滤策略,我们揭示了一种“少即是多”(less is more)的现象:仅使用全数据集7%(12.3万条样本)的子集,即可获得与完整数据集相当的性能。此外,我们进一步发现,以推理为导向的数据构成具有协同增益效应,能够同时提升模型的通用能力与专业推理表现。
一句话总结
来自上海人工智能实验室、北京大学和上海交通大学的研究人员推出了 MMFineReason,这是一个从 Qwen3-VL-235B 蒸馏出的 180 万样本多模态推理数据集,其微调后的 MMFinereason-2B/4B/8B 模型通过高效、难度过滤的训练和协同数据组合,超越了更大的专有系统。
主要贡献
- 我们推出了 MMFineReason,一个包含 51 亿 token 的 180 万样本多模态推理数据集,通过三阶段流程构建:收集、从 Qwen3-VL-235B-A22B-Thinking 蒸馏思维链(CoT)推理,并按质量和难度过滤,以解决 STEM 和谜题领域的数据稀缺问题。
- 在 MMFineReason 上微调 Qwen3-VL-Instruct 得到的 MMFineReason-2B/4B/8B 模型在各自尺寸类别中创下新 SOTA:MMFineReason-4B 超越 Qwen3-VL-8B-Thinking,MMFineReason-8B 超越 Qwen3-VL-30B-A3B-Thinking,接近 Qwen3-VL-32B-Thinking。
- 我们揭示了“少即是多”的效果:仅 7% 的难度过滤子集(12.3 万样本)即可匹配完整数据集性能,并通过消融实验验证,以推理为中心的数据组合可同时提升专业和通用能力。
引言
作者采用以数据为中心的方法,弥合开源与专有视觉语言模型(VLM)在多模态推理方面的差距。尽管先前工作扩展了多模态数据量,但仍缺乏高质量、一致的思维链标注——尤其在 STEM 图表、视觉谜题和复杂图表方面,受限于数据稀缺和标注成本。现有数据集还存在标注风格碎片化和推理深度不足的问题,限制了可复现研究。作者的主要贡献是 MMFineReason,一个包含 180 万样本、51 亿 token 的蒸馏式视觉锚定推理轨迹数据集,通过三阶段流程生成:聚合、从 Qwen3-VL-235B 蒸馏 CoT、难度感知过滤。在此数据上微调 Qwen3-VL-Instruct 得到的 MMFineReason-2B/4B/8B 模型超越了更大规模的专有基线——仅用 7% 数据即可匹配完整数据集性能,揭示了“少即是多”的效率。他们的工作还发现,以推理为中心的数据可提升通用能力,并为未来多模态模型开发提供实用训练方案。
数据集

作者使用 MMFineReason,一个完全由本地部署模型构建、不依赖闭源 API 的大规模开源多模态推理数据集。其构成、处理和使用方式如下:
-
数据集构成与来源:
该数据集聚合并精炼了来自 30 多个开源多模态数据集的 230 多万样本,包括 FineVision、BMMR、Euclid30K、Zebra-CoT-Physics、GameQA-140K 和 MMR1。涵盖四大领域:数学(79.4%)、科学(13.8%)、谜题/游戏(4.6%)和通用/OCR(2.2%)。最终训练集 MMFineReason-1.8M 在过滤后保留 177 万高质量样本。 -
关键子集细节:
- 数学:以 MMR1(127 万)为主,辅以 WaltonColdStart、ViRL39K、Euclid30K 等,增强几何与符号多样性。
- 科学:以 VisualWebInstruct(15.7 万)和 BMMR(5.46 万)为基础,加入 TQA、ScienceQA 等小规模数据。
- 谜题/游戏:以 GameQA-140K(7.17 万)为主,加入 Raven、VisualSphinx、PuzzleQA 以支持抽象推理。
- 通用/OCR:仅 3.87 万样本来自 LLaVA-CoT,用作正则化,保留视觉感知能力而不稀释推理焦点。
所有数据集均严格过滤:多图、过于简单或高度专业化(如医疗)数据被排除。
-
处理与元数据:
- 图像清理:丢弃损坏或无法读取的图像;超大图像(>2048px)按比例缩放;全部转为 RGB 格式。
- 文本标准化:非英文问题翻译为英文;移除噪音(链接、索引、格式);重写浅层提示以要求逐步推理。
- 元数据包括:source.id、原始问题/答案、标准化图像/问题/答案、增强标注(Qwen3-VL-235B 生成的标题和推理轨迹)、指标(通过率、一致性标志)。
- 所有样本均获得 100% 密集图像标题(平均 609 token),远超以往数据集。
-
标注与过滤:
- Qwen3-VL-235B-A22B-Thinking 使用四阶段框架生成 CoT 解释,输出严格模板:推理部分在
...块中,最终答案在<answer>...</answer>标签内。 - 过滤阶段:
- 模板/长度验证(丢弃 <100 词或结构错误样本)。
- N-gram 去重(移除 50-gram 重复 ≥3 次的 CoT)。
- 正确性验证(对比提取答案与真实答案;丢弃不匹配样本)。
- 难度过滤:Qwen3-VL-4B-Thinking 对每题尝试 4 次;0% 通过率样本(12.3 万)保留用于困难 SFT;<100% 通过率样本(58.6 万)用于消融研究。
- Qwen3-VL-235B-A22B-Thinking 使用四阶段框架生成 CoT 解释,输出严格模板:推理部分在
-
模型训练用途:
- 180 万数据集划分:4 万样本用于 RL 训练,其余用于 SFT。
- 混合数据优先选择高难度样本(通过率过滤)以加速收敛。
- CoT 长度显著长于基线(平均 2,910 token vs. HoneyBee 的 1,063),谜题/游戏任务平均达 4,810 token,反映高强度推理需求。
- 视觉内容 75.3% 为 STEM/图表类(几何、逻辑、图表),确保符号推理焦点,同时保留多样自然图像以促进泛化。
该流程使开源 VLM 可复现、高质量训练,缩小与专有系统的差距。
方法
作者采用多阶段框架,整合数据构建、标注、选择和模型训练,处理并求解数学问题。整体架构始于数据构建阶段,原始数据经标准化与清洗后准备用于下游任务。随后是数据标注阶段,模型执行思维蒸馏与标题生成,从输入生成结构化文本描述。如下图所示,标注数据随后进入数据选择阶段,通过模板验证与冗余检查,筛选出高质量、难度均衡的子集。
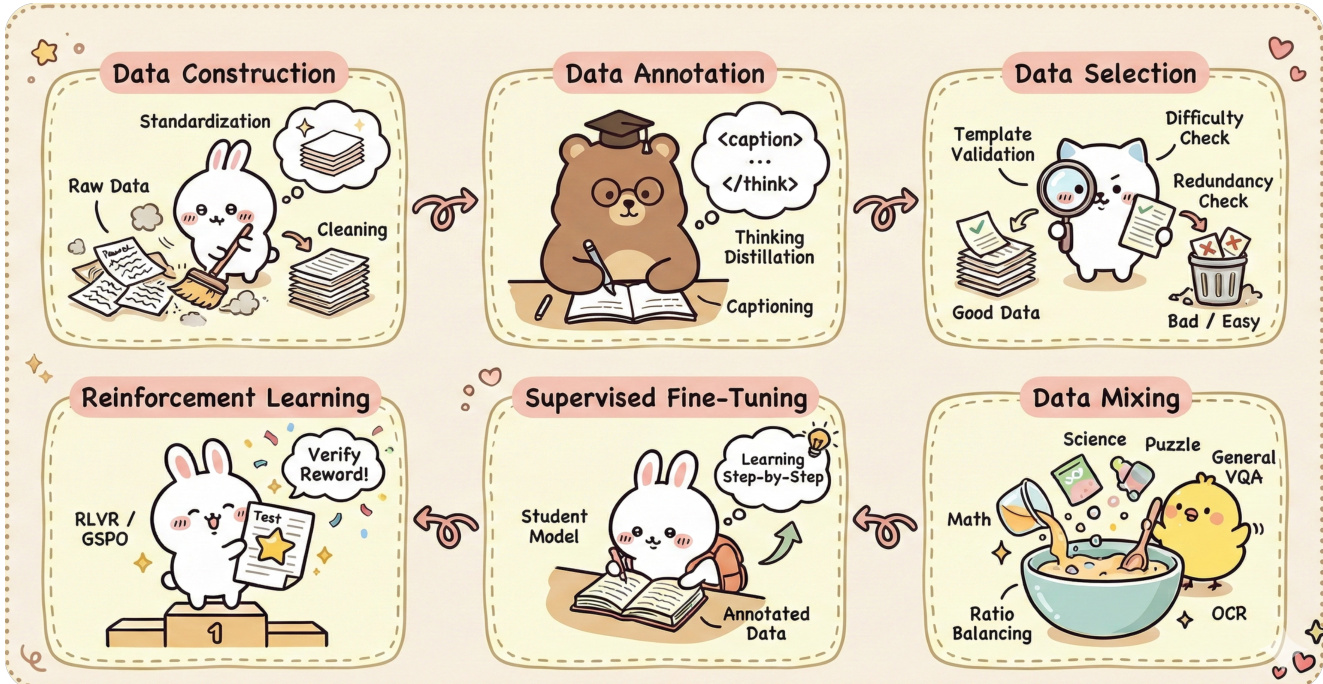
选定数据用于通过监督微调训练学生模型,模型从标注数据学习逐步推理。该过程通过强化学习增强,使用奖励机制优化模型在测试任务上的表现,采用 RLVR 或 GSPO 等方法。同时,数据混合将数学、科学、谜题和通用 VQA 等不同问题类型整合为统一训练集,通过比例平衡和 OCR 集成确保各领域多样性与覆盖度。
框架进一步包含结构化答案提取流程,由一组优先级规则指导从解题中提取最终答案。这些规则强调保留 LaTeX 格式、避免简化、适当处理多解或文字答案。提取答案后通过与参考答案对比进行验证,聚焦语义等价性与事实正确性。评估过程判断生成答案是否传达与参考答案相同结论,输出格式包含简明分析及等价性或差异判断。
实验
- 以数据为中心的策略实现强扩展:在 51 亿 token 上训练的 MMFineReason 模型超越 Qwen3-VL-30B-A3B-Thinking,接近 GPT-5-mini-high 性能。
- 难度感知过滤仅用 7% 数据(MMFineReason-123K)即达到完整数据集 93% 性能,确认高数据效率。
- 以推理为中心的数据混合同时提升通用与推理任务表现,即使通用数据极少。
- 超高分辨率(2048²)对推理任务增益有限,但在 RealWorldQA 等通用视觉基准中仍有益。
- 一旦推理链成熟,标题增强提供边际或无收益,因 CoT 已编码足够视觉上下文。
- MFR-8B 在 DynaMath 上达 83.4%,优于 Qwen3-VL-32B-Thinking(82.0%)和 Qwen3-VL-30B-A3B-Thinking(76.7%);在 MathVerse 上达 81.5%,接近 Qwen3-VL-32B-Thinking(82.6%)。
- MFR-8B 在 MathVision 上以 67.1% 超越 HoneyBee-8B(37.4%)和 OMR-7B(36.6%),超 30 分,证明推理链质量更优。
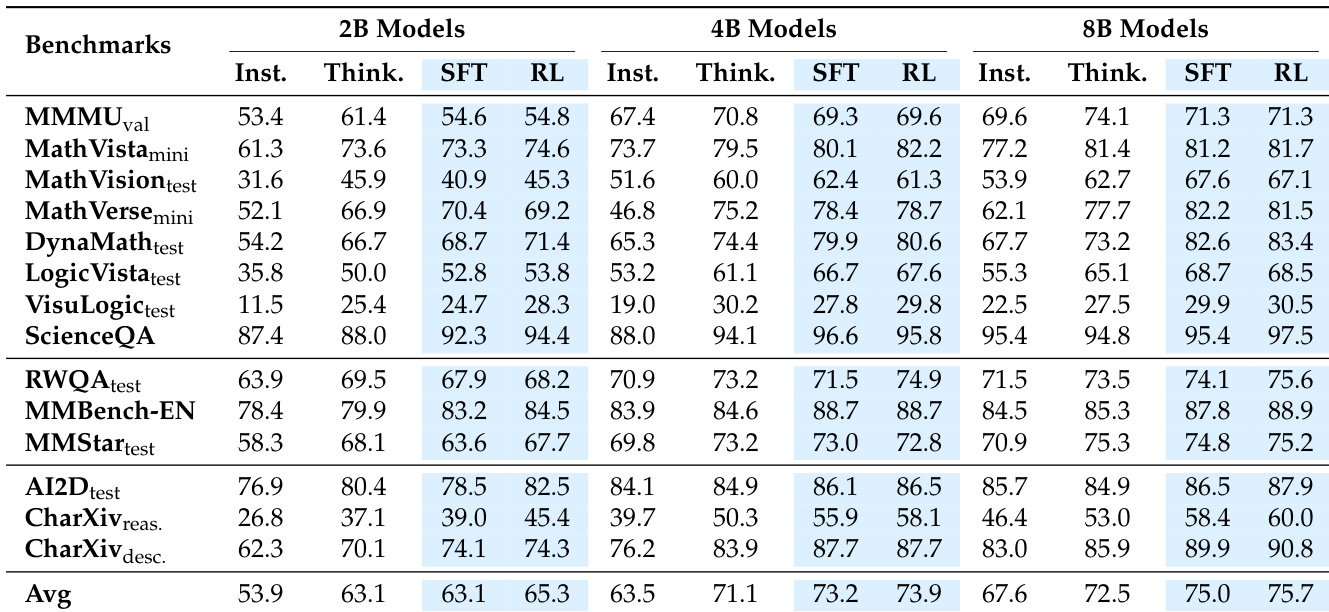
- SFT 驱动主要推理提升(如 8B 在 MathVision 上 +13.66%),RL 增强图表与现实任务泛化(如 2B 在 AI2D 上 +4.04%)。
- MMFineReason-1.8M 在基准测试中达 75.7,优于 HoneyBee-2.5M(65.1)和 MMR1-1.6M(67.4),尽管数据量更小。
- MMFineReason-123K 达 73.3,仅用 ~5% 数据量即匹配或超越全规模基线。
- MFR-4B 超越 Qwen3-VL-8B-Thinking(73.9 vs. 72.5),证明数据质量可补偿 2 倍模型尺寸差距。
- MFR-8B 在其尺寸类别创 SOTA(75.7),超越 Qwen3-VL-30B-A3B-Thinking(74.5)和 Gemini-2.5-Flash(75.0)。
- ViRL39K 仅用 2.4% 数据即达 MMR1 98.9% 性能,确认超出精选数据阈值后收益递减。
- WeMath2.0-SFT(814 样本)达 70.98%,媲美大 1000 倍数据集,验证高密度指令是能力触发器。
- 谜题/游戏数据集(如 GameQA-140K、Raven)因推理风格不匹配表现不佳;纯几何数据(Geo3K、Geo170K)泛化有限。
- 广泛学科覆盖(如 BMMR)优于窄领域(GameQA-140K),凸显多样性比任务深度更强驱动。
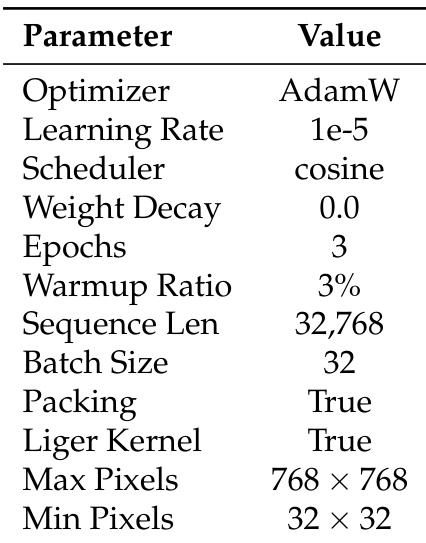
作者在监督微调中使用 AdamW 优化器与余弦调度器,学习率为 1e-5,训练 3 个 epoch,序列打包长度为 32,768,并启用 Liger Kernel。训练时图像缩放至最大 768 × 768 像素,最小分辨率为 32 × 32 像素。
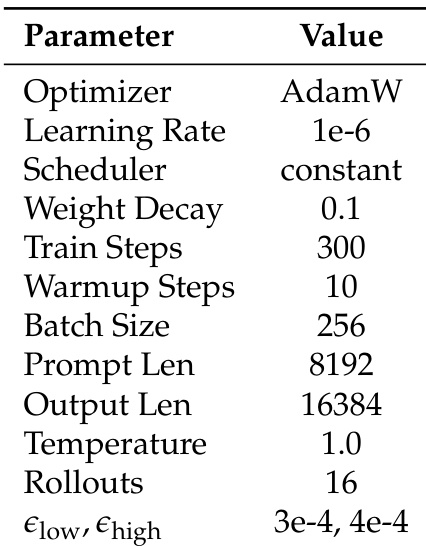
作者在强化学习阶段使用恒定学习率调度器和 AdamW 优化器,训练 300 步,每提示 16 次 rollout。模型训练温度为 1.0,提示长度为 8192 token,KL 散度惩罚设为 3e-4 和 4e-4。
作者采用多阶段训练方法,结合监督微调(SFT)与强化学习(RL),评估 MMFineReason 模型在各基准测试中的表现。结果显示,SFT 在推理任务中驱动主要提升,而 RL 增强通用理解与图表推理基准的泛化能力,8B 模型在同类尺寸中达到最先进水平,超越更大规模的开源与闭源模型。
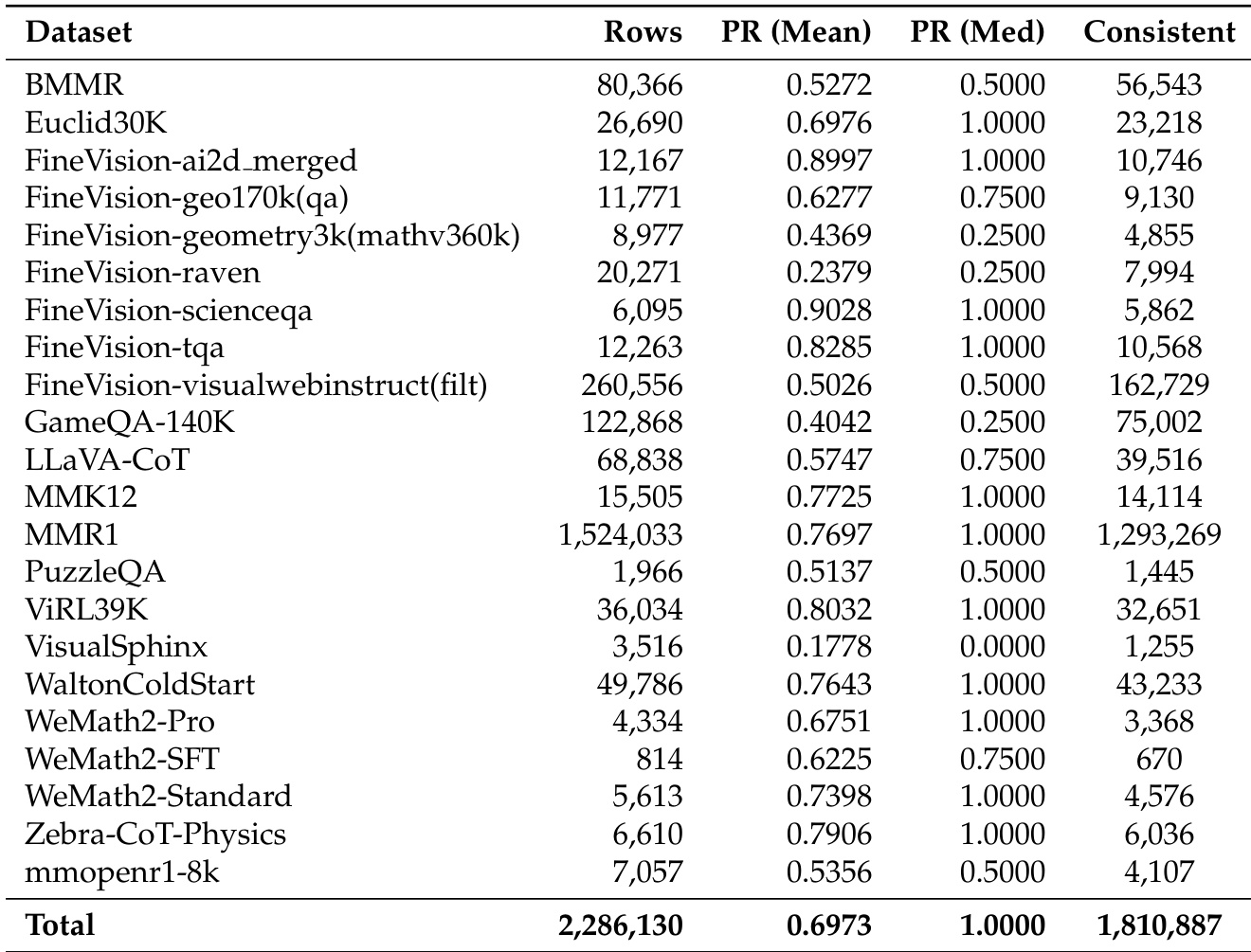
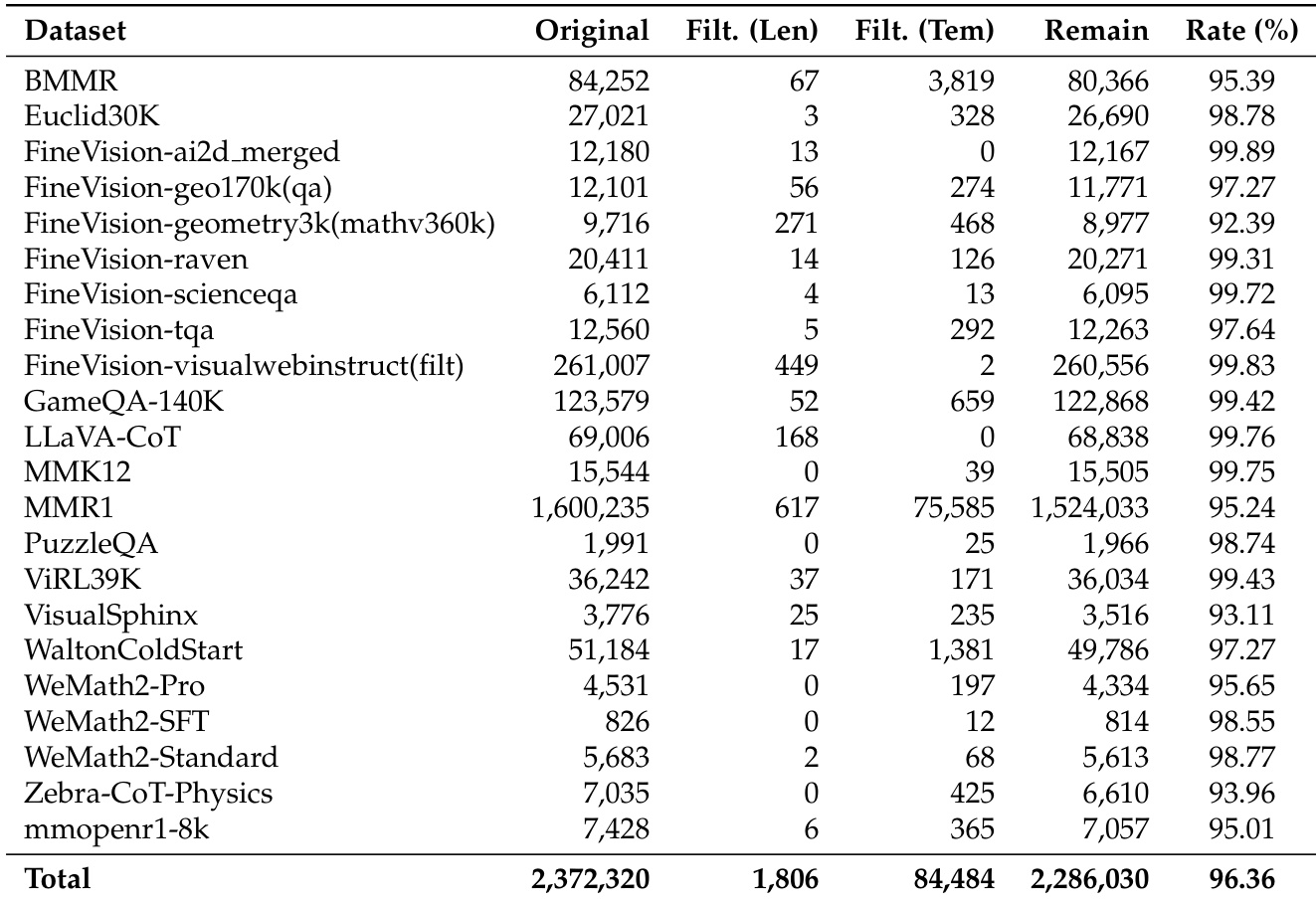
作者使用表格量化其过滤过程对数据集规模与质量的影响,显示过滤将总样本数从 2,372,320 降至 1,806,同时保持 96.36% 的高保留率。结果表明,过滤策略有效移除低质量或冗余数据,尤其在 MMR1 和 FineVision-visualwebinstruct 等数据集中样本数大幅减少,同时保留高质量推理数据。
作者使用表格比较各数据集在推理任务上的表现,指标包括平均通过率(PR)、中位通过率和一致性。结果显示,FineVision-ai2d_merged 和 FineVision-scienceqa 等数据集平均通过率高,而 FineVision-geometry3k 和 FineVision-raven 等表现显著较低,表明各数据集难度差异显著。