Command Palette
Search for a command to run...
DreamActor-M2:通过时空上下文学习实现通用角色图像动画
DreamActor-M2:通过时空上下文学习实现通用角色图像动画
Mingshuang Luo Shuang Liang Zhengkun Rong Yuxuan Luo Tianshu Hu Ruibing Hou Hong Chang Yong Li Yuan Zhang Mingyuan Gao
摘要
角色图像动画旨在通过将驱动序列中的运动信息迁移至静态参考图像,生成高保真度的视频。尽管近年来取得了显著进展,现有方法仍面临两个根本性挑战:(1)运动注入策略不够优化,导致身份保真度与运动一致性之间存在权衡,表现为“跷跷板”效应;(2)过度依赖显式的姿态先验(如骨骼结构),难以充分捕捉复杂的动态细节,且限制了在任意非人形角色上的泛化能力。为应对上述挑战,我们提出 DreamActor-M2——一种通用的角色动画框架,将运动条件建模重新定义为一种上下文学习(in-context learning)问题。该方法采用两阶段范式:首先,通过将参考图像的外观特征与运动线索融合至统一的潜在空间,弥合输入模态间的差异,使模型能够借助基础模型的生成先验,联合推理空间身份信息与时间动态特性;其次,我们设计了一种自引导式数据合成流程,构建伪跨身份训练样本对,从而实现从依赖姿态控制到直接端到端RGB驱动动画的平滑过渡。该策略显著提升了模型在多样化角色与运动场景下的泛化能力。为进一步支持全面评估,我们还引入了 AW Bench,一个多功能基准测试平台,涵盖广泛的角色类型与运动场景。大量实验表明,DreamActor-M2 在多项指标上均达到当前最优性能,展现出卓越的视觉保真度与强大的跨域泛化能力。项目主页:https://grisoon.github.io/DreamActor-M2/
一句话总结
来自字节跳动、中科院和东南大学的研究人员提出了 DreamActor-M2,这是一种通用的角色动画框架,通过上下文学习和自举数据替代姿态先验,克服身份-运动权衡问题,实现高保真、RGB 驱动的多样化角色与动作动画。
主要贡献
- DreamActor-M2 引入了一种时空上下文运动条件策略,将外观与运动融合到统一的潜在空间中,使基础视频模型能够在不产生“跷跷板”权衡的前提下同时保留身份和运动。
- 该框架采用自举数据合成流水线生成伪跨身份训练对,从依赖姿态控制过渡到端到端 RGB 驱动动画,显著增强对非人形角色和复杂动作的泛化能力。
- 为支持稳健评估,作者引入 AWBench —— 一个涵盖多种角色类型和运动场景的新基准,DreamActor-M2 在该基准上展现出最先进的视觉保真度和跨域泛化能力。
引言
作者利用基础视频扩散模型解决角色图像动画问题,即从驱动视频中提取运动并迁移至静态参考图像——这对数字娱乐至关重要,但受限于身份保留与运动保真度之间的权衡。先前方法要么通过基于姿态的注入扭曲身份,要么通过基于注意力的压缩丢失运动细节,且依赖在非人形角色上失效的显式姿态先验。DreamActor-M2 将运动条件重构为上下文学习问题,通过时空融合运动与外观形成统一输入,以同时保留身份与动态。它引入了一种自举流水线,从姿态引导过渡到端到端 RGB 驱动动画,消除姿态估计器,实现跨多样角色与运动的稳健泛化。作者还发布了 AWBench,用于严格评估跨域性能的新基准。
数据集

- 作者使用 AWBench —— 他们自建的基准,用于评估 DreamActor-M2 从驱动视频和参考图像对任何主体(人或非人)进行动画化的能力。
- AWBench 包含 100 个驱动视频和 200 张参考图像,旨在覆盖广泛的运动与身份多样性。
- 驱动视频包括人类动作(面部、上半身、全身;儿童、成人、老人;跳舞、日常活动;跟踪和固定摄像头)及非人类动作(如猫和猴子等动物,汤姆和杰瑞等动画角色)。
- 参考图像同样体现这种多样性,涵盖人类、动物和卡通角色,还包括多主体案例(多对多、一对多),以测试先前数据集未覆盖的复杂场景。
- 数据集通过人工收集与筛选确保质量与范围,视觉示例见图 3。
- AWBench 仅用于评估,不涉及训练或混合比例,本节未描述裁剪或元数据构建。
方法
作者采用名为 DreamActor-M2 的统一框架,设计用于根据参考图像和驱动运动信号(无论是姿态序列还是原始视频片段)生成角色动画。该架构模块化,从基于姿态的变体演进至完全端到端流水线,两者均基于采用 MMDiT 架构的潜在扩散模型(LDM)主干,用于多模态视频生成。核心创新在于一种时空上下文运动注入策略,避免身份泄漏同时保留细粒度运动保真度。
在基础层面,模型通过 3D VAE 将输入图像编码至潜在空间,其中高斯噪声被逐步注入并在条件引导下去噪。去噪网络参数化为 ϵθ,训练目标为最小化重建损失:
L=Ezt,c,ϵ,t(∣∣ϵ−ϵθ(zt,c,t)∣∣22)其中 c 表示由上下文运动注入机制导出的条件输入。
时空上下文注入策略通过将参考图像与第一帧运动图像在空间上拼接,并在后续帧的参考侧填充零图像,构造复合输入序列 C∈RT×H×2W×3。这在无需有损压缩或显式姿态对齐的情况下保留空间对应关系。运动与参考区域通过二值掩码 Mm 和 Mr 区分,空间拼接形成 M。复合视频 C、其潜在投影 Z、噪声潜在 Znoise 和掩码 M 通道拼接,构成扩散变换器的综合输入。
请参阅框架图以获得流水线的视觉分解,图中展示了从驱动视频和参考图像经时空拼接、条件掩码到扩散生成的流程。图中还突出了文本引导的集成及两种训练范式——基于姿态和端到端。
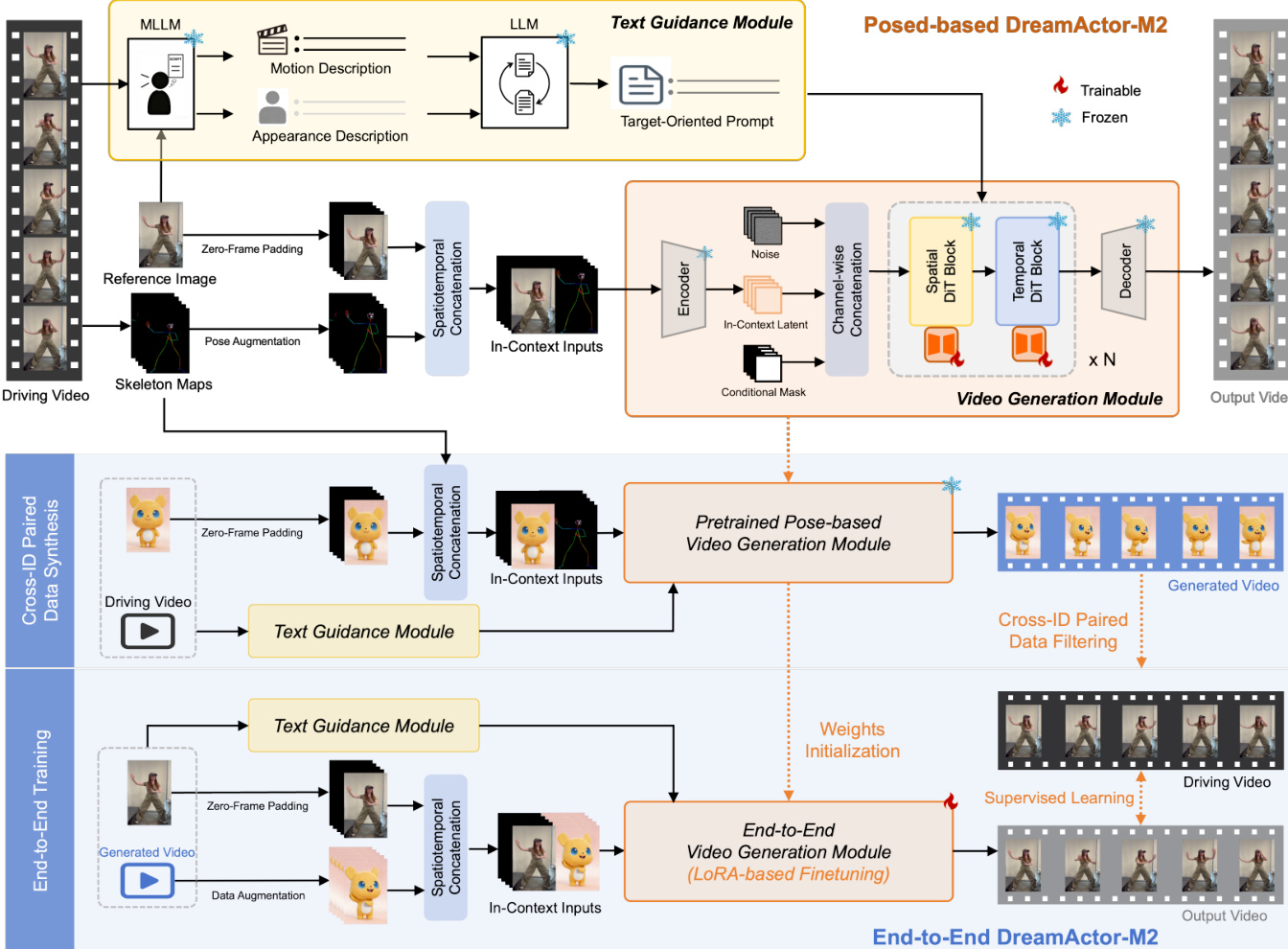
在基于姿态的变体中,2D 骨架作为运动信号。为减轻姿态数据中结构线索导致的身份泄漏,作者应用两种增强策略:随机骨骼长度缩放和基于边界框的归一化。这些策略在保留运动动态的同时解耦身体形状与运动语义。为恢复增强过程中可能丢失的细粒度运动细节,引入文本引导模块。多模态 LLM 解析驱动视频和参考图像以生成运动与外观描述,融合为面向目标的提示。该提示作为高层语义先验,与上下文视觉输入一同注入。
为高效适应,作者采用 LoRA 微调,冻结主干参数,仅在前馈层插入低秩适配器。文本分支保持冻结以保留语义对齐,实现低计算开销的即插即用定制。
端到端变体通过直接在原始 RGB 帧上训练消除对显式姿态估计的依赖。这通过自举数据合成流水线实现:预训练的基于姿态模型通过将运动从源视频迁移至新身份生成伪配对数据。所得视频 Vo 与源视频形成伪对 (Vsrc,Vo)。通过 Video-Bench 自动评分后人工验证的双阶段过滤过程,确保仅保留高质量、语义一致的配对。
随后,端到端模型训练目标为从 (Vo,Iref) 重建 Vsrc,其中 Iref=Vsrc[0]。训练数据集定义为:
D={(Vo,Iref,Vsrc)}模型从基于姿态的变体热启动,继承稳健的运动先验并加速收敛。此端到端范式支持直接从原始 RGB 序列迁移运动,形成统一且通用的角色动画框架。
实验
- DreamActor-M2 在跨身份动画中表现优异,通过自动化和人工评估在图像质量、运动平滑度、时间一致性和外观一致性方面验证其卓越性能。
- 在主观和客观基准上优于现有最先进方法及行业产品如 Kling 和 Wan2.2,展示在人类到卡通、多人、非人类迁移等多样化场景中的稳健性。
- 定性结果确认其在身份保留、细粒度运动对齐和语义运动理解方面的强大能力,即使在手势复制和一对多驱动等挑战性案例中亦然。
- 消融研究证实时空注入、姿态增强和 LLM 驱动文本引导对结构保真度、运动准确性和身份保留的必要性。
- 该模型在非人类主体、多样镜头类型和复杂多人动态中泛化良好,但因训练数据有限,目前在轨迹交叉等复杂交互上仍存在困难。
- 强调伦理保障,包括限制模型访问和依赖公共数据,以减轻人类图像动画相关的滥用风险。
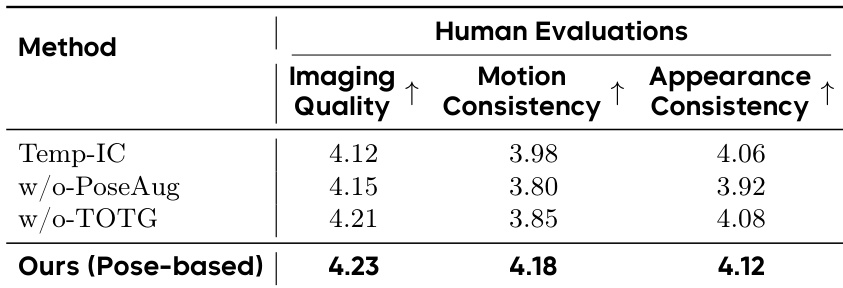
作者将消融版本模型与完整基于姿态的 DreamActor-M2 进行对比评估,表明移除姿态增强或面向目标的文本引导会导致图像质量、运动一致性和外观一致性得分下降。结果表明,姿态增强与 LLM 驱动文本引导均对模型保留结构细节与运动保真度有显著贡献。完整基于姿态的变体获得最高人工评估得分,确认集成设计的有效性。
作者使用 Video-Bench 和人工评估评估 DreamActor-M2 在多样化动画任务中的表现,显示其在自动化与主观指标上均持续优于先前方法。结果表明,端到端变体在图像质量、运动平滑度、时间一致性和外观保留方面得分最高,验证其在跨身份与跨域场景中的稳健性。模型表现与人类判断高度一致,确认其在多样化角色类型和驱动输入下生成视觉连贯且运动一致动画的能力。