Command Palette
Search for a command to run...
潜在思维链作为规划:将推理与语言化分离
潜在思维链作为规划:将推理与语言化分离
Jiecong Wang Hao Peng Chunyang Liu
摘要
思维链(Chain-of-Thought, CoT)赋予大型语言模型(Large Language Models, LLMs)解决复杂问题的能力,但在离散的标记空间中进行推理时,仍受限于高昂的计算成本以及推理路径的坍缩问题。近期的隐式推理方法尝试通过在连续隐状态中执行推理来提升效率。然而,这些方法通常作为从显式推理步骤到隐状态的“黑箱”端到端映射,且在推理过程中往往需要预先设定隐状态步数,缺乏灵活性。在本工作中,我们提出PLaT(Planning with Latent Thoughts)——一种将隐式推理重新建模为规划过程的框架,其核心在于从根本上将推理与语言表达解耦。我们把推理建模为隐式规划状态的确定性轨迹,而一个独立的解码器仅在必要时将这些隐式思考转化为自然语言文本。这种解耦机制使模型能够动态判断推理终止时机,而不依赖于固定的超参数。在数学推理基准上的实证结果表明,PLaT在贪婪解码准确率上略低于基线方法,但在推理多样性方面展现出更优的可扩展性。这一现象表明,PLaT能够学习到更鲁棒、更广阔的解空间,为推理时搜索(inference-time search)提供了一个透明且可扩展的坚实基础。
一句话总结
来自北航的王杰聪和彭昊,联合滴滴出行的刘春阳,提出了PLaT——一种解耦推理与语言表达的潜在规划框架,支持动态、可扩展的推理,在推理多样性方面优于基线方法,同时保持复杂问题求解的透明性。
主要贡献
- PLaT 将潜在推理重新定义为连续空间中的规划过程,将内部思维轨迹与语言输出解耦,避免离散标记坍缩,并支持无需固定步数的动态终止。
- 该框架引入了 Planner-Decoder 架构,其中潜在状态确定性演化,仅按需语言化,提供可解释的中间推理和灵活的推理控制。
- 在数学基准测试中,PLaT 以较低的贪心准确率为代价,换取显著更好的 Pass@k 扩展性和推理多样性,表明其适用于搜索式推理的更广泛、更稳健的解空间。
引言
作者利用潜在空间推理解决传统思维链(CoT)方法的低效性和路径坍缩问题——传统方法迫使模型过早锁定离散标记,剪枝替代解并带来高计算成本。先前的潜在方法虽提升效率,但将推理视为黑箱并固定推理步数,限制了适应性。作者的主要贡献是 PLaT——一种 Planner-Decoder 框架,将连续潜在规划与语言表达解耦,支持动态终止和可解释的中间状态。实证表明,PLaT 以牺牲贪心准确率为代价换取更优的推理多样性,在搜索式推理下扩展性更好,并学习更广泛的解流形。
数据集

- 作者使用 GSM8k-Aug 进行训练,这是 GSM8k 的增强版本,其中推理链被重格式化为 GPT-4 生成的方程式,结构为 问题 → 步骤1 → 步骤2 → ⋯ 答案,以支持潜在步骤分割。
- 评估时,他们在三个分布外基准数据集(GSM-HARD、SVAMP 和 MultiArith)上测试,以评估泛化性和鲁棒性。
- 模型主干为 GPT-2(小型),选择该架构以确保与近期使用相同架构的潜在推理基线进行公平比较。
- 训练从 CoT-SFT 检查点初始化,微调 25 轮,学习率为 5e-4,潜在维度 ds = 2048。
- Planner 共享主干参数,但额外添加两层 Transformer 以增强规划能力;Decoder 共享相同主干。
- 未提及裁剪或元数据构建;处理聚焦于方程式风格链格式和潜在状态训练。
- 模型使用贪心准确率(利用)和 Pass@k(k=32,64,128)进行评估,以衡量潜在空间中的探索和推理多样性。
方法
作者提出了一种名为 PLaT(Planning with Latent Trajectories)的新框架,将推理建模为潜在自回归过程,解耦中间推理步骤的生成与其语言化。该架构引入连续潜在变量表示每个推理步骤,相比基于离散标记的自回归模型,支持更灵活、稳定的推理路径探索。
PLaT 的核心包含两个主要模块:Planner 和 Decoder,通过线性投影器连接潜在空间与 LLM 主干维度。Planner 在连续潜在流形中运行,为每个推理步骤生成一系列潜在状态,而不提前锁定特定标记。它首先使用专用编码器投影器将输入问题编码为初始潜在状态。后续状态自回归生成:潜在历史被投影到模型隐藏维度,与分隔符标记拼接后输入主干 LLM,以预测下一个隐藏状态,再映射回潜在空间。关键在于,Planner 生成确定性潜在向量,确保训练和推理过程的稳定性。
如下图所示,Decoder 从 Planner 的潜在轨迹合成文本输出。它采用指数移动平均(EMA)机制稳定各步骤的潜在状态,为每个潜在槽位维护独立聚合器。这些聚合器累积前序步骤对应槽位的信息,形成每个推理步骤的最终聚合状态。Decoder 随后将该状态投影到标记空间并生成相应文本段,严格依赖当前聚合状态以确保语义完整性。
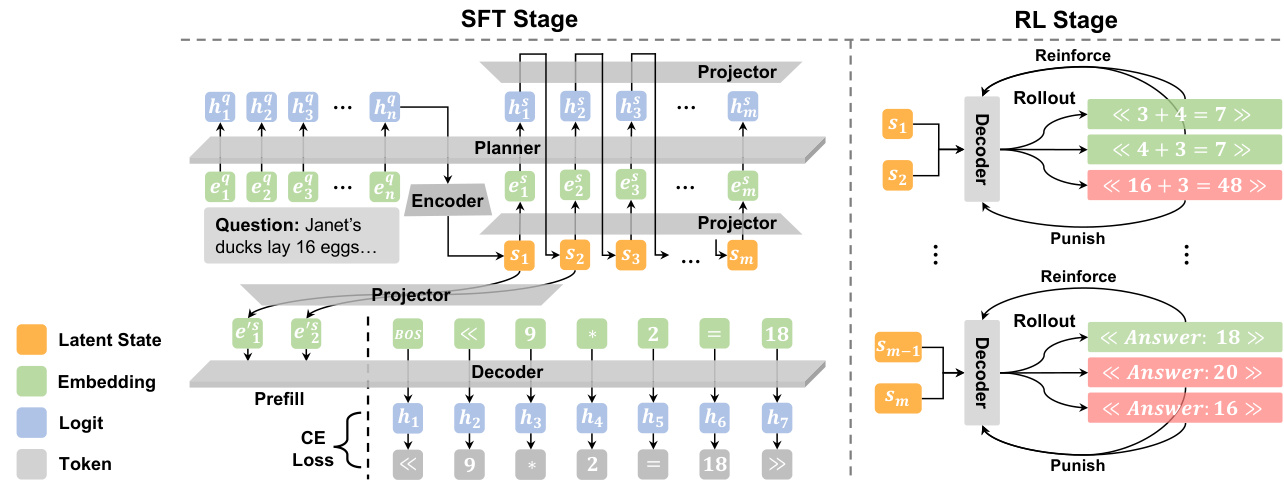
训练分为两个阶段。在监督微调(SFT)阶段,整个管道通过重建损失端到端优化,最小化真实推理步骤与 Decoder 预测之间的交叉熵。为鼓励鲁棒性并防止过拟合点对点映射,训练期间向累积潜在状态注入高斯噪声。此阶段在潜在空间内统一处理所有推理步骤,无需模式切换或固定步数。
对于策略优化,作者采用强化学习(RL),同时冻结 Planner 参数以保持学习的潜在流形。探索仅通过 Decoder 的温度采样诱导,允许从相同确定性潜在状态生成多个语言化路径。使用组相对策略优化(GRPO)目标最大化正确有效输出的可能性,优势在每组采样轨迹内相对于奖励计算。这种解耦方法确保推理拓扑稳定,同时优化语言化策略。
推理通过“惰性解码”策略实现高效化。由于 Planner 在潜在空间运行,模型可生成完整推理轨迹而不产生中间文本。为判断是否继续推理或输出最终答案,模型仅解码每步的第一个标记进行语义探测。若该标记非答案分隔符,模型丢弃它并继续;若是,则从当前潜在状态完整解码最终答案。这显著降低计算成本,同时保持可解释性。
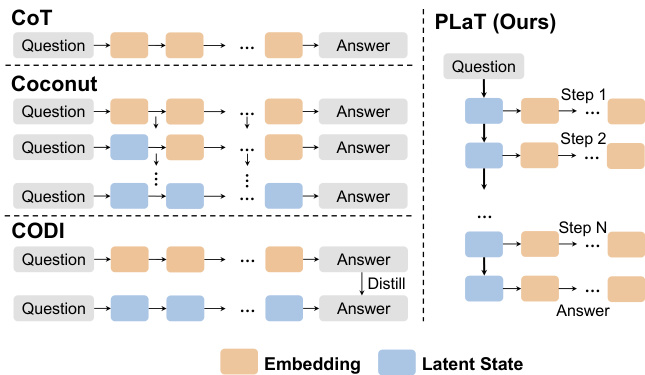
参见框架图,PLaT 与 CoT、Coconut 和 CODI 等先前方法的高层次对比。PLaT 架构明确分离潜在规划与文本解码,通过解耦优化实现高效推理和稳定策略优化。
实验
- PLaT 在推理路径多样性(Pass@128)方面表现卓越,优于 Coconut 和 CODI,表明其潜在空间能高效采样多样化解,而基线方法趋于饱和。
- 增加潜在状态数(N_L=2)可提升多样性和域内准确率,但可能损害域外性能,暗示容量与泛化之间的权衡。
- 强化学习提升域内任务的贪心准确率,但降低多样性并损害 OOD 性能,揭示对域特定奖励的过拟合,凸显多任务奖励设计的必要性。
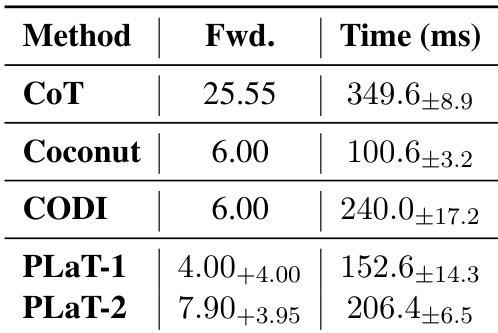
- PLaT 相比显式 CoT 显著加速推理(快 56%),同时保持可解释性,在效率、透明性和高多样性推理间取得平衡。
- PLaT 的潜在状态可解释且支持主动探索,保持更高分支因子并更长时间保留有效推理路径,非常适合搜索式推理方法。
- 消融研究证实上下文注入、EMA 聚合和去噪对稳定性能的重要性;参数共享提升正则化,移除上下文则以精度为代价增加多样性。
- 超参数分析表明 N_L=2、α_EMA=0.5、d_s=2048 取得最优性能;更长潜在链或更高维度因优化挑战而性能下降。
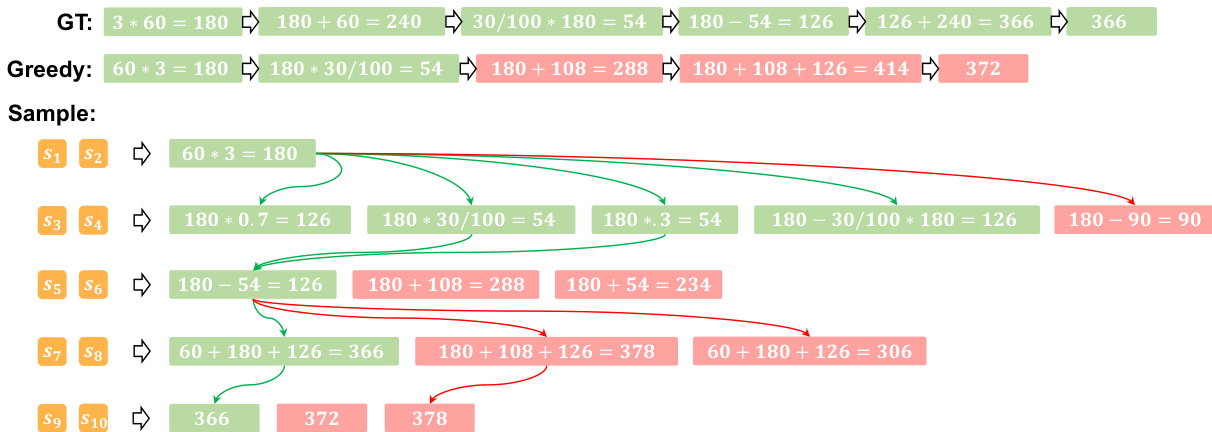
- 案例研究证实 PLaT 在潜在状态中编码多种推理策略,即使贪心解码失败,正确路径仍可共存,支持其作为多样化推理生成器的角色。
作者通过消融研究评估 PLaT 关键架构组件,发现移除上下文注入导致贪心准确率最大下降,而忽略 EMA 或去噪则同时损害准确率和多样性。结果表明 Residual 变体整体表现最差,独立 Decoder 获得有竞争力的多样性但精度较低,暗示参数共享有助于正则化潜在空间。
作者使用 GPT-4o-mini 自动评估推理步骤有效性,并通过人工标注验证其可靠性,达到 95.0% 准确率和近乎完美的协议(Cohen’s Kappa = 0.8721)。结果表明自动评估器略宽松但一致,从不拒绝有效步骤,支持方法间的公平比较分析。
作者使用 PLaT 将推理压缩至潜在状态,相比显式 CoT 推理延迟降低 56%,同时保持采样解的更高多样性。尽管因解码器检查,PLaT 相比 Coconut 和 CODI 承担适度开销,但提供可解释中间状态并支持高效推理路径探索。结果表明,PLaT 在速度、多样性和透明性间取得良好平衡,适合搜索式推理方法。