Command Palette
Search for a command to run...
Idea2Story:一种将研究概念自动转化为完整科学叙事的流水线
Idea2Story:一种将研究概念自动转化为完整科学叙事的流水线
摘要
基于大型语言模型(LLM)的智能体在自主科学发现领域近期取得了显著进展,展现出自动化端到端科研工作流的潜力。然而,现有系统大多依赖以运行时为中心的执行范式,频繁地在线读取、总结并推理大量科学文献,这种实时计算策略导致高昂的计算开销,受限于上下文窗口长度,并常引发推理脆弱性和幻觉问题。为此,我们提出Idea2Story——一种以预计算驱动的自主科学发现框架,将文献理解从在线推理转向离线知识构建。Idea2Story持续收集经过同行评审的论文及其评审反馈,提取核心方法学单元,构建可复用的研究范式,并将其组织为结构化的方法学知识图谱。在运行时,用户模糊的研究意图可被对齐至已建立的研究范式,从而实现高质量研究模式的高效检索与复用,避免开放式的生成与试错过程。通过将科研规划与执行建立在预先构建的知识图谱之上,Idea2Story有效缓解了LLM的上下文窗口瓶颈,显著减少了对文献的重复运行时推理。我们通过定性分析与初步的实证研究验证,Idea2Story能够生成连贯、方法学基础扎实且具有创新性的研究模式,并在端到端设置下成功生成多个高质量的研究范例。结果表明,离线知识构建为可靠、可扩展的自主科学发现提供了切实可行的基础。
一句话总结
AgentAlpha 团队提出了 Idea2Story,这是一种预计算框架,通过从同行评审论文中构建方法论知识图谱,将模糊的研究想法转化为结构化、可复用的模式,从而减少大语言模型的上下文限制与幻觉,同时在无需运行时重新处理文献的前提下实现高效、新颖的科学发现。
主要贡献
- Idea2Story 引入了一种基于预计算的框架,从同行评审论文及评审意见中构建结构化的方法论知识图谱,以离线知识整理取代低效的运行时文献处理,从而提升可扩展性并降低幻觉风险。
- 该系统通过从知识图谱中检索并组合已验证的研究模式,将用户的研究意图具体化,实现高效、上下文感知的规划,规避大语言模型上下文窗口限制,避免开放式试错生成。
- 初步实证研究表明,Idea2Story 可端到端生成连贯、新颖且方法论扎实的研究演示,验证了离线知识构建在自主科学发现中的实际可行性。
引言
作者利用大语言模型自动化科学发现,但针对现有系统依赖实时、高上下文文献处理的关键低效问题提出改进。先前方法因重复在线摘要与试错探索,面临高计算成本、上下文窗口限制和脆弱推理等问题。Idea2Story 引入一种预计算框架,在离线阶段从同行评审论文及其评审意见中提取并组织方法论单元,构建结构化知识图谱。运行时,系统将模糊的研究意图映射至图谱中已验证的研究模式,实现更快速、更可靠、更连贯的科学规划,无需重新发明已知方法。这一转变降低了幻觉风险与计算负载,同时使研究扎根于实证支持的范式。
数据集

- 作者从近三年内发表的约 13,000 篇已接收机器学习论文(5,000 篇来自 NeurIPS,8,000 篇来自 ICLR)构建论文池,保留全文(标题、摘要、正文)及关联评审材料(评论、评分、置信度分数、元评审)。
- 每篇论文经匿名化处理以移除作者/审稿人标识(姓名、机构、邮箱),并进行安全过滤以剔除有毒或攻击性内容,最终生成去标识化语料库,在保留技术与评价信号的同时最小化隐私与安全风险。
- 该数据集用于训练 Idea2Story,系统利用论文-评审对学习研究贡献的表述与评估方式,支持可复用方法论模式的检索与组合,而非领域特定内容。
- 从该数据构建的知识图谱呈现“中心-辐射”结构:高频领域作为中心连接大量论文,而方法论模式常跨越多个领域——支持超越论文级相似性的抽象感知检索与综合。
方法
Idea2Story 框架采用两阶段范式,将离线知识构建与在线研究生成解耦,使系统能将非正式用户想法转化为结构化、学术扎实的研究方向。整体架构分为离线阶段(构建持久性方法论知识库)与在线阶段(锚定用户输入并生成精炼研究模式)。
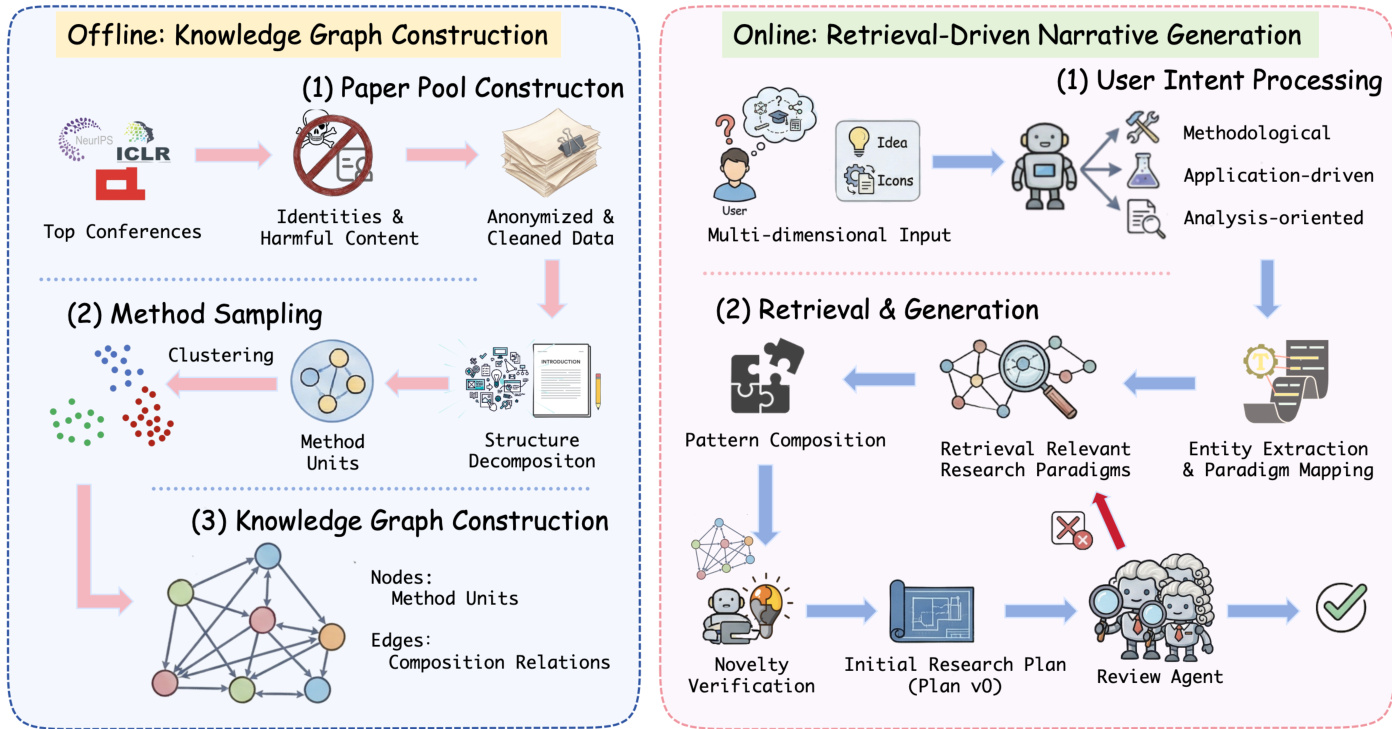
在离线阶段,系统首先从顶级同行评审会议构建精选论文池,过滤身份与有害内容以保障隐私与安全。该匿名化且清洗后的数据集经方法单元提取处理,每篇论文被分解为核心方法论贡献。提取过程利用学术论文的结构化布局,分析引言、方法与实验部分,隔离可复用的方法单元,捕捉关键技术思想,同时排除超参数调优或数据集选择等实现细节。每个方法单元被规范化为结构化属性(包括原子元方法与组合层级模式),并表示为其关联单元的向量嵌入。这些嵌入通过 UMAP 投影至低维空间,再经 DBSCAN 密度聚类识别文献中反复出现的方法论结构,形成连贯的研究模式。
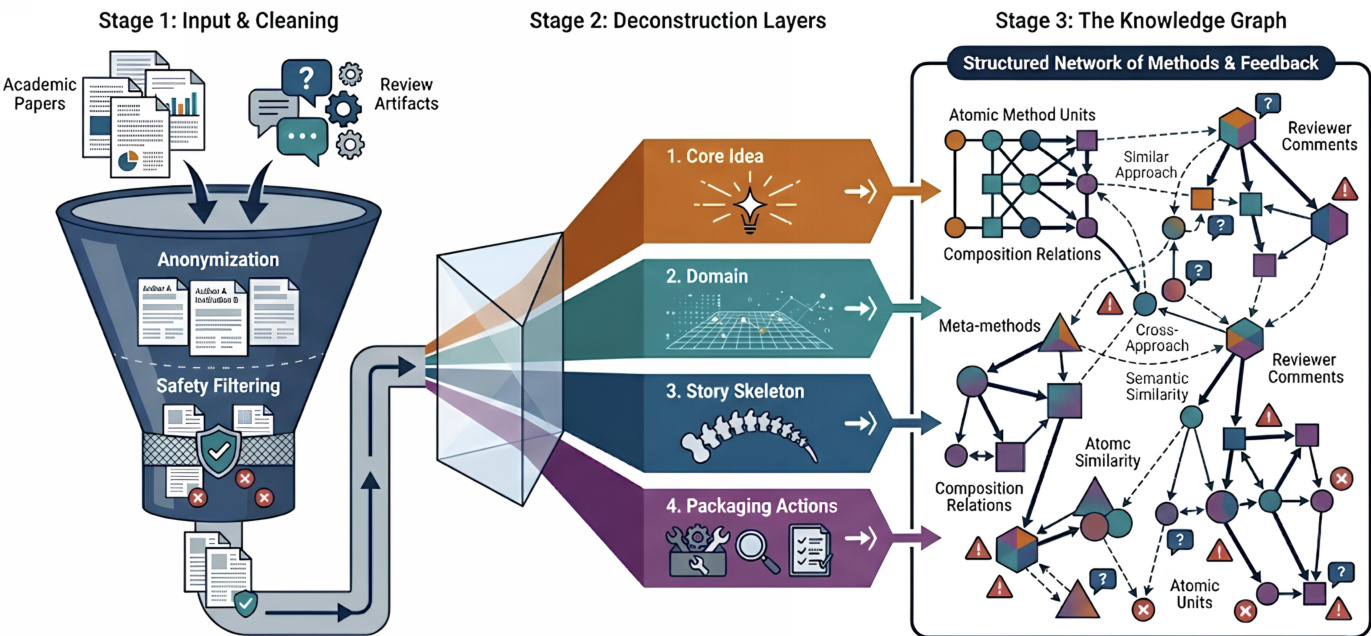
提取的方法单元与研究模式被组织为结构化知识图谱,作为持久性方法论记忆。该图谱定义为有向图 G=(V,E),其中节点代表标准化方法单元或元方法,边编码先前工作中观察到的方法单元间组合关系。标准化将语义相似单元归入共享抽象,减少表层变异同时保留核心方法论意图。该图谱明确捕捉可复用方法论元素与实证观察到的兼容性,使系统能在高于单篇论文的抽象层级上推理方法。
在线阶段,给定用户提供的研究想法,系统将方法发现视为基于知识图谱的检索与组合问题。过程始于用户意图处理,将输入解释为多维查询(可为方法论驱动、应用驱动或分析驱动)。随后系统通过多视角检索公式执行检索与生成,从理念级、领域级和论文级检索视角聚合互补信号,各视角根据与输入查询的语义相似性贡献相关性得分。最终研究模式排序由各视角得分加权求和决定,生成候选模式排序列表。
检索后,系统启动评审引导的精炼循环。大语言模型作为评审者,依据技术严谨性、新颖性与概念连贯性等标准评估检索到的研究模式。基于反馈,系统通过重组兼容方法单元或调整问题表述迭代修订模式。该“生成–评审–修订”循环持续至模式满足评审者对新颖性、连贯性与可行性标准,或无进一步改进为止。输出为精炼研究模式,作为下游规划与论文生成的结构化蓝图。
实验
- 在 13,000 篇 ICLR 与 NeurIPS 论文上评估 Idea2Story,评估其从模糊输入中提取可复用方法论结构并生成连贯研究模式的能力。
- 分析提取的方法单元,确认其代表有意义、可复用的抽象。
- 使用三个真实用户想法进行定性案例研究,将 Idea2Story(基于 GLM-4.7)与缺乏显式模式建模的直接大语言模型基线对比。
- 发现 Idea2Story 将模糊意图重构为动态、结构扎实的研究蓝图,强调生成式精炼与演化表示。
- 直接大语言模型输出仍较抽象,依赖常规表述,缺乏具体方法论支撑。
- Gemini 3 Pro 独立评估始终更青睐 Idea2Story,在新颖性、方法论实质与整体研究质量方面表现更优。