Command Palette
Search for a command to run...
视觉生成通过多模态世界模型解锁类人推理
视觉生成通过多模态世界模型解锁类人推理
Jialong Wu Xiaoying Zhang Hongyi Yuan Xiangcheng Zhang Tianhao Huang Changjing He Chaoyi Deng Renrui Zhang Youbin Wu Mingsheng Long
摘要
人类通过构建内部世界模型,并在这些模型中操作概念来进行推理。近年来,人工智能领域,特别是链式思维(Chain-of-Thought, CoT)推理的进展,正在逼近人类的认知能力,人们普遍认为,世界模型被嵌入于大型语言模型之中。当前系统在数学、编程等形式化与抽象领域已实现专家级表现,主要依赖于语言推理。然而,在物理智能与空间智能等领域的表现仍远落后于人类,这些领域需要更丰富的表征能力和先验知识。因此,能够同时生成语言与视觉内容的统一多模态模型(Unified Multimodal Models, UMMs)的出现,激发了研究者对基于互补多模态路径、更贴近人类认知的推理机制的兴趣,但其实际优势尚不明确。从世界模型的视角出发,本文首次系统性地探究了视觉生成在何种情境下以及如何促进推理。我们提出核心假设——视觉优越性假说:对于某些任务,尤其是那些根植于物理世界的任务,视觉生成更自然地适合作为世界模型;而纯粹的语言世界模型则因表征能力受限或先验知识不足而面临瓶颈。理论上,我们将内部世界建模形式化为CoT推理的核心组成部分,并分析了不同形式世界模型之间的差异。实证上,我们识别出需要交错式视觉-语言CoT推理的任务,并构建了一个新的评估基准——VisWorld-Eval。在最先进的UMM模型上的控制实验表明,在有利于视觉世界建模的任务中,交错式CoT显著优于纯语言CoT;而在其他任务中则未展现出明显优势。综上,本研究澄清了多模态世界建模在实现更强大、更接近人类的多模态人工智能方面的潜力。
一句话总结
清华大学与字节跳动Seed团队研究人员提出“视觉优先假设”,表明在统一多模态模型中,交错式视觉-语言思维链推理在物理世界任务上优于纯语言方法,其新提出的VisWorld-Eval基准测试验证了该结论。
主要贡献
- 论文提出“视觉优先假设”,认为对于物理世界任务,视觉生成比纯语言推理更适合作为世界模型,因后者面临表征与知识瓶颈。
- 形式化定义了思维链推理中的世界建模,并引入VisWorld-Eval——一套新基准测试套件,专为评估需显式视觉模拟的任务中的交错式视觉-语言推理设计。
- 在当前最先进的统一多模态模型上的实证结果表明,交错式思维链在视觉偏好任务中显著优于纯语言思维链,而在无需视觉建模的任务中无优势,从而明确了多模态推理收益的适用范围。
引言
作者利用统一多模态模型(UMMs)探索视觉生成如何通过充当显式视觉世界模型来增强推理能力——补充大型语言模型中嵌入的语义世界模型。尽管当前AI系统在抽象领域中通过语言思维链推理表现优异,但在物理与空间任务中因表征瓶颈与视觉先验知识不足而表现不佳。作者提出“视觉优先假设”,认为对于扎根于物理世界的任务,视觉生成能提供更丰富、更具体的表征。其主要贡献是建立一个将世界建模与推理关联的理论框架,以及VisWorld-Eval基准测试——一套受控任务集,旨在隔离视觉生成何时发挥作用。实证结果表明,交错式语言-视觉思维链在需要空间或物理模拟的任务中显著提升性能,但在如Sokoban等简单符号任务中无增益,验证了其假设。
数据集

作者使用VisWorld-Eval,一套精心设计的七项推理任务,用于评估视觉世界建模,分为两类:世界模拟与世界重建。
-
纸张折叠(改编自SpatialViz-Bench):模拟纸张折叠并打孔后的展开过程。网格尺寸3–8,折叠次数1–4;孔洞形状5种。测试集采用最高难度(8x8网格,4次折叠)。思维链通过基于规则的模板生成,由Gemini 2.5 Pro优化。视觉世界建模插入展开步骤图像;语言建模使用网格矩阵;隐式建模跳过状态追踪。
-
多跳操作(基于CLEVR):在Blender渲染场景中,物体(立方体、球体、圆柱体)进行空间操作(添加/移除/变更)。问题针对最终布局。测试提示变化初始物体数量(3–6)与操作次数(1–5)。思维链模拟逐步执行过程,由Gemini 2.5 Pro优化。
-
球体追踪(改编自RBench-V):预测球体经弹性墙面反射后的轨迹。球体起始方向由绿色箭头指示;4–8个随机孔洞。测试案例要求至少一次墙面反弹。思维链由Seed 1.6生成,解释帧间动力学。
-
推箱子:网格谜题(6–10x10),含一个箱子与目标点。思维链使用搜索算法寻找最优路径;仅渲染关键步骤(接近、推动、方向变更)。增加随机绕路以增强反思能力。思维链来自Seed 1.6。视觉建模插入渲染步骤图像;语言建模移除图像;隐式建模以[masked]遮蔽坐标。
-
迷宫:固定5x5网格谜题。思维链来自基于规则的模板,重写以增强自然性。视觉建模插入渲染路径步骤;语言与隐式建模遵循推箱子协议,以[masked]遮蔽位置。
-
立方体三视图投影(来自SpatialViz-Bench):根据等轴测图+两个正交视图推断未见正交视图。网格尺寸3–5,两种立方体颜色。测试集使用随机网格尺寸。思维链构建查询视图,用辅助颜色标记遮挡,计数立方体——由Gemini 2.5 Pro重写。视觉建模添加查询视图图像;语言建模使用字符矩阵编码颜色。
-
真实世界空间推理(MMSI-Bench子集):使用真实世界相机-物体/区域位置问题。训练思维链通过视觉-CoT流水线生成,使用SFT训练的BAGEL进行新视角合成,再由Gemini 2.5 Pro筛选与重写。
所有任务采用问答格式,答案可验证。训练数据包括通过模板或模型生成的思维链,经优化以增强清晰度。视觉世界建模插入中间状态图像;语言建模使用符号表征;隐式建模移除或遮蔽显式状态追踪。各任务的训练与测试样本数汇总于表2。
方法
作者形式化定义了多模态推理的世界模型视角,将底层环境概念化为多可观测马尔可夫决策过程(MOMDP)。该框架认为,多模态模型通过维护世界状态的内部表征进行操作,该表征从不同模态的多个、可能不完整的观测中推断而来。该方法的核心在于两个原子能力:世界重建与世界模拟。世界重建使模型能从部分观测推断世界完整结构,从而生成同一状态的新视角。形式化为将一组观测编码为内部表征,s^=enc(oϕ1,…,oϕn),再解码以合成未见观测,o^ϕn+1=dec(s^,ϕn+1)。在现代生成模型中,该能力通过端到端新视角生成实现,pθ(oϕn+1∣oϕ1,…,oϕn)。第二能力——世界模拟,使模型能预测世界状态的未来演化。形式化为预测当前状态与动作的转移,s^′∼pred(s^,a),或在生成模型中更常见地预测未来观测,pθ(ot+1∣o≤t,a≤t)。作者认为,有意推理(如思维链)是对这些内部世界观测的操作过程。形式化为一系列推理步骤与观测,R=(r1,o1),(r2,o2),…,(rH,oH),其中每步ri为逻辑操作,oi为调用原子世界建模能力生成的观测。该形式化与模态无关,支持语言、视觉或隐式世界建模。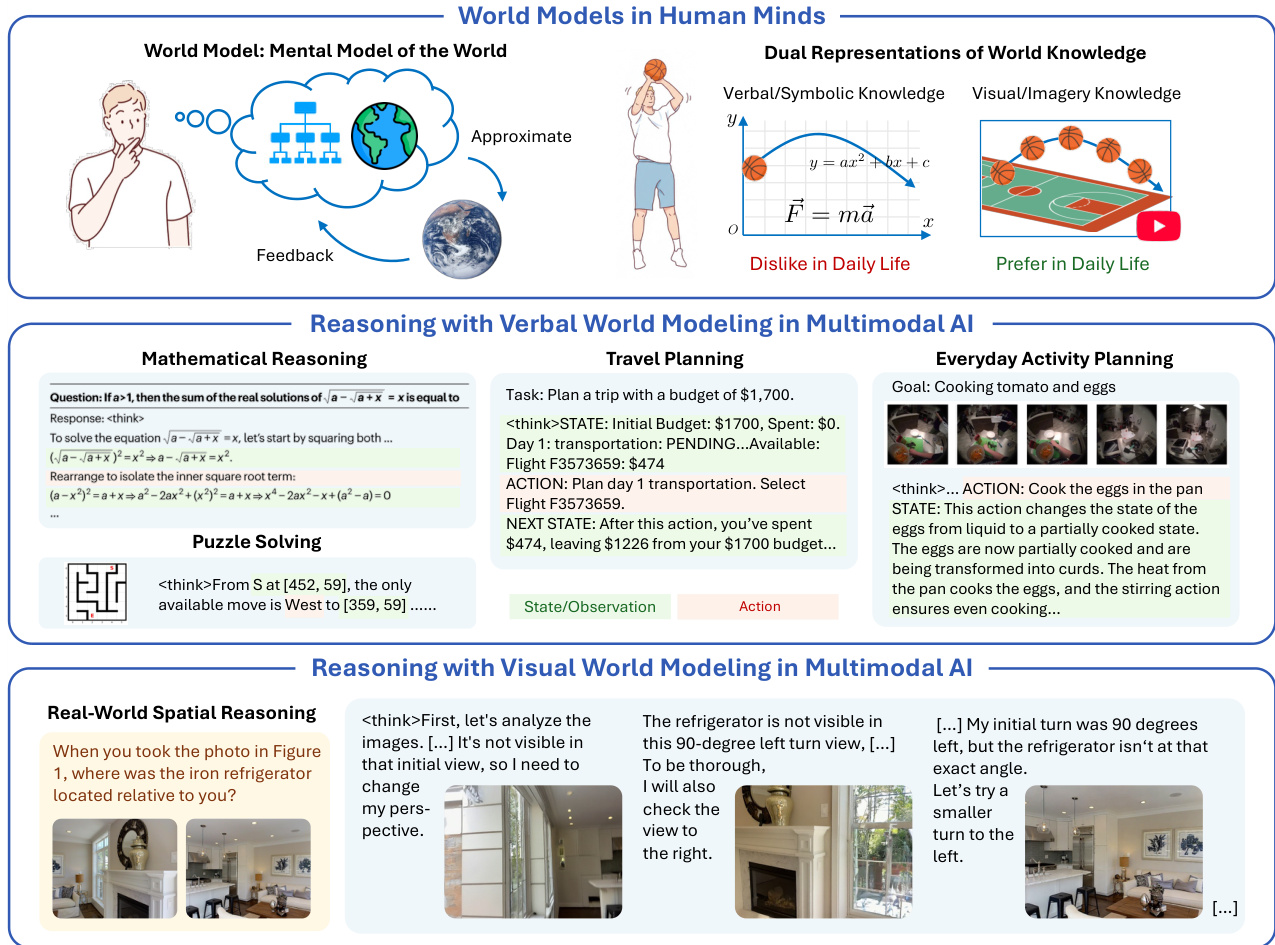
模型架构基于统一多模态基础,具体为BAGEL模型,设计用于处理语言与视觉生成。训练过程旨在优化模型生成交错式语言与视觉推理步骤的能力。首先在特定任务数据集上进行监督微调(SFT),同时优化语言推理步骤与视觉中间输出。视觉世界建模的损失函数结合语言生成的交叉熵与视觉生成的流匹配损失,旨在学习新视角合成所需的内部表征。训练目标为最小化以下损失:Lθ(Q,I,R,A)=−∑i=1H+1∑j=1∣ri∣logpθ(ri,j∣ri,<j,Ri)+∑i=1HEt,ϵ∥vθ(oit,t∣R~i)−(ϵ−oi)∥22。SFT后,应用可验证奖励强化学习(RLVR)进一步优化模型。强化学习期间,语言生成组件使用GRPO优化,视觉生成组件则通过KL散度正则化,相对于SFT训练的参考模型,以防止性能退化。整体训练框架旨在使模型能通过显式生成与操作视觉与语言观测,执行复杂多模态推理。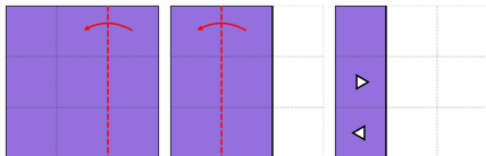
实验
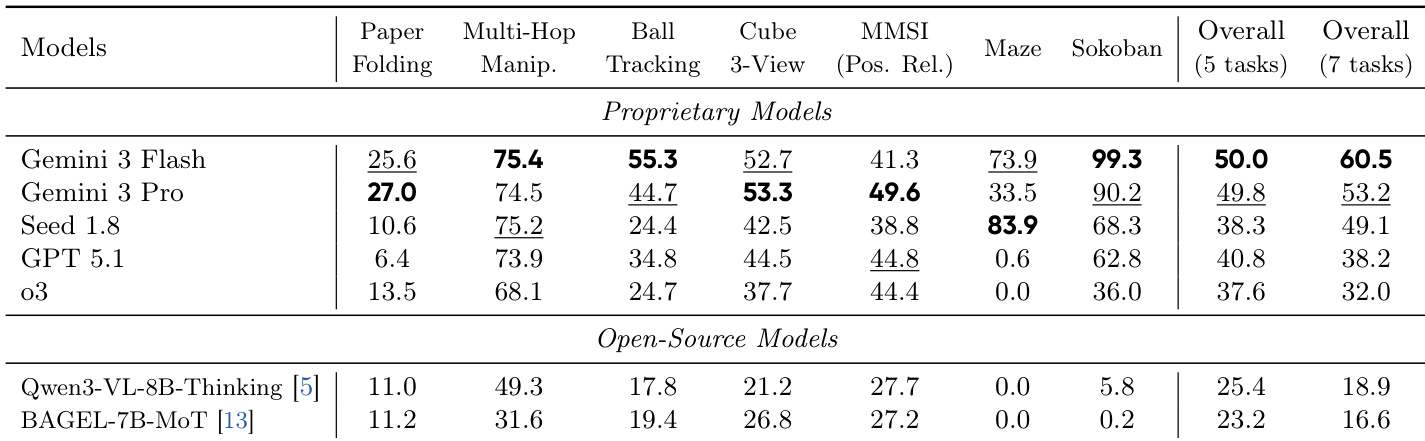
- 通过VisWorld-Eval(涵盖合成与真实世界领域的7项任务)评估视觉世界建模;先进VLM(Gemini 3 Flash/Pro)表现优于其他模型,但在纸张折叠与空间推理等复杂任务中仍不理想。
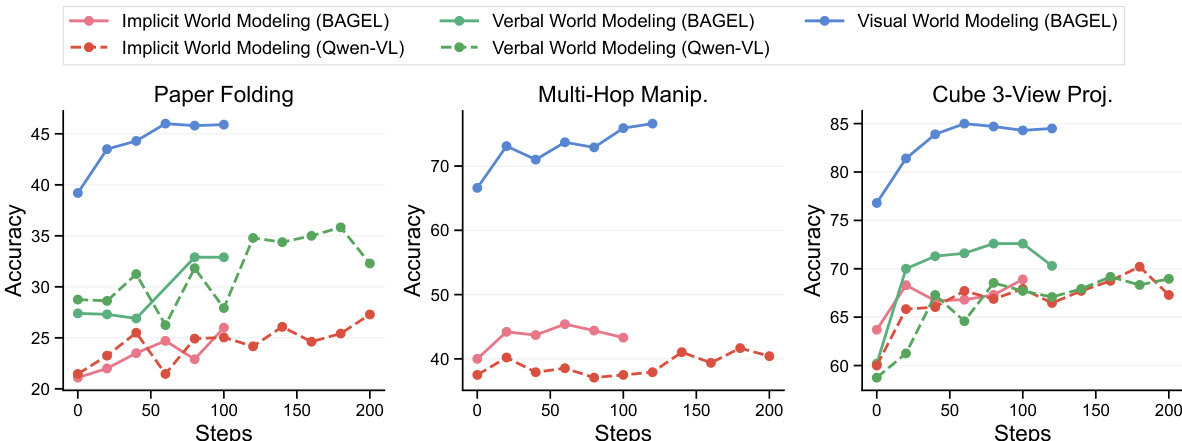
- 视觉世界建模通过更丰富的空间基础,在世界模拟任务(纸张折叠、球体追踪、多跳操作)中显著提升性能;在纸张折叠任务中,样本效率比语言建模高4倍。
- 通过利用视觉先验,在世界重建任务(立方体三视图、真实世界空间推理)中提升性能;即使在分布外立方体堆叠(尺寸6)中仍保持约10%准确率优势,并在视角合成中实现>50%保真度,而语言建模接近零。
- 在网格世界任务(迷宫、推箱子)中无增益;隐式世界建模已足够,内部模型表征在预训练后自然形成,并通过SFT进一步优化,无需显式坐标监督。
- 即使VLM在相同语言思维链数据上微调,UMM仍优于VLM基线(Qwen2.5-VL),确认视觉建模固有优势,非因语言推理受损。
- RLVR提升所有思维链形式,但未缩小性能差距;视觉世界建模优势持续存在,表明其优越性源于结构而非训练限制。
- 定性分析揭示语言推理中的幻觉(尤其对称任务)与视觉建模中的生成伪影,跨视角空间理解仍受限——预期随更强基础模型与精选数据改进。
作者使用柱状图比较不同模型与推理方法在三项任务(纸张折叠、多跳操作、立方体三视图投影)上的表现。结果显示,视觉世界建模在所有任务中始终优于语言与隐式世界建模,多跳操作与立方体三视图投影中增益最大。在纸张折叠中,视觉世界建模准确率最高,而隐式与语言建模表现相近且较低。
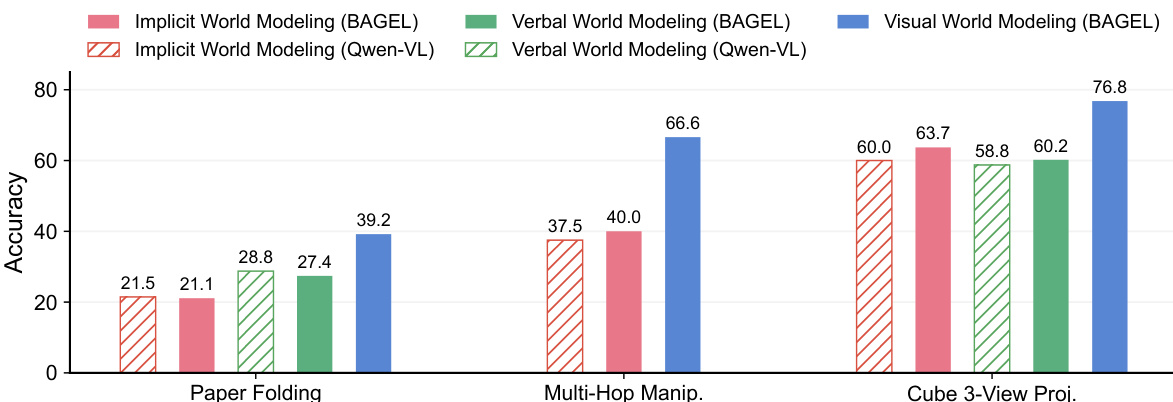
作者在MMSI-Bench位置关系任务中比较隐式与视觉世界建模,显示视觉世界建模在Cam.-Obj.与Cam.-Reg.子任务中准确率更高,而隐式世界建模在Obj.-Obj.与Obj.-Reg.中表现更好。视觉世界建模总体表现更优,表明其在空间推理中的有效性。

作者使用监督微调,超参数包括学习率1×10−5、批量大小128、GRPO小批量大小32。视觉生成的KL损失系数设为0.1,语言生成系数为0.0,表明训练聚焦视觉生成。

作者使用VisWorld-Eval套件评估先进VLM,报告七项任务的零样本性能。结果显示Gemini 3 Flash与Gemini 3 Pro显著优于其他模型,尤其在纸张折叠与球体追踪等复杂任务中,但整体表现仍不理想。
作者使用监督微调评估不同思维链形式对多模态推理任务的影响。结果显示,在纸张折叠与多跳操作中(需精确几何理解的空间推理),视觉世界建模显著优于语言与隐式世界建模。相比之下,在立方体三视图投影中,视觉世界建模比语言方法准确率更高、世界模型保真度更好,但性能趋于平稳,幻觉问题仍存。