Command Palette
Search for a command to run...
Youtu-VL:通过统一的视觉-语言监督释放视觉潜能
Youtu-VL:通过统一的视觉-语言监督释放视觉潜能
摘要
尽管视觉-语言模型(Vision-Language Models, VLMs)取得了显著进展,但现有架构在保留细粒度视觉信息方面仍存在局限,导致多模态理解趋于粗粒度。我们认为,这一缺陷源于当前主流VLMs固有的训练范式不够优化,其表现出以文本为中心的优化偏差——将视觉信号仅视为被动的条件输入,而非监督目标。为缓解该问题,我们提出Youtu-VL框架,该框架基于视觉-语言统一自回归监督(Vision-Language Unified Autoregressive Supervision, VLUAS)范式,从根本上将优化目标从“视觉作为输入”转变为“视觉作为目标”。通过将视觉标记直接融入预测序列,Youtu-VL对视觉细节与语言内容均施加统一的自回归监督。此外,我们将该范式拓展至以视觉为中心的任务,使标准VLM无需引入特定任务的附加模块即可完成视觉主导型任务。大量实证评估表明,Youtu-VL在通用多模态任务与视觉主导型任务上均展现出具有竞争力的性能,为构建全面的通用视觉智能体奠定了坚实基础。
一句话总结
腾讯优图实验室团队推出 Youtu-VL,这是一种从文本主导转向统一自回归监督的视觉-语言模型,将视觉标记视为预测目标,以保留细粒度细节,并使标准架构无需任务特定模块即可执行以视觉为中心的任务,在多模态和密集感知基准上实现具有竞争力的性能。
主要贡献
- Youtu-VL 通过引入视觉-语言统一自回归监督(VLUAS),解决了视觉-语言模型中的文本主导优化偏差问题,将视觉标记视为预测目标而非被动输入,以恢复细粒度视觉理解。
- 该框架通过将视觉与语言预测整合到单一自回归流中,使标准 VLM 架构能够原生执行以视觉为中心的任务,无需任务特定模块,在保持架构简洁性的同时扩展了功能范围。
- 实证评估表明,Youtu-VL 在通用多模态和以视觉为中心的基准测试中表现优异,证明统一监督支持无需辅助头或解码器的全面通用视觉代理能力。
引言
作者利用统一的自回归监督范式,解决现有视觉-语言模型中的文本主导偏差问题——这些模型常将视觉输入视为被动线索而非预测目标。先前模型难以保留细粒度视觉细节,且需任务特定模块来处理以视觉为中心的任务,限制了其通用性。Youtu-VL 重构训练过程,同时预测视觉标记与文本,使单一架构能在无需辅助头的情况下,竞争性地处理多模态和纯视觉任务,同时为通用视觉代理奠定基础。
数据集

作者使用由以视觉为中心、图像描述、OCR、STEM 和 GUI 数据组成的多模态数据集,数据来源包括开源数据集、内部收集和合成流水线。以下是简要分解:
-
以视觉为中心的数据
- 结合开源数据集(如 RefCOCO、ADE20K、Cityscapes)与通过自动化标注和大语言模型增强流水线生成的合成数据。
- 任务包括定位、检测、分割、姿态估计和深度估计。
- 分割任务中,掩码映射为文本标签并进行标记化;无效区域在计算损失时忽略。
- 深度数据使用线性或对数均匀量化(1–1000 个区间);评估时反量化为真实深度。
- 增强包括随机裁剪、填充、调整大小、颜色抖动和 cutout;部分任务使用 1.2 倍填充 + 1280 像素调整大小用于分割。
- 开放世界合成采用双分支:检测/分割(通过定位模型 + 数据绑定)和深度(通过伪标签 + 量化)。复制粘贴策略将透明对象放置在背景上。
-
图像描述与知识数据
- 从开源图像-文本对中获取 5T 标记,通过 CLIP 分数、NSFW 过滤和分辨率检查进行筛选。
- 通过以下方式增强:
- 概念平衡采样:使用双语本体和 CLIP 检索获取通用概念,关键词匹配获取命名实体。
- 稀有类别挖掘:基于 JEPA 的语义密度分数捕获长尾样本。
- 知识注入重描述:大语言模型将稀疏描述改写为密集、具象化的描述。
- 最终数据集:经 MD5 去重和重复过滤后保留 1T 标记。
-
OCR 数据
- 结合人工标注数据集与来自 PDF、图表和文本语料库的合成数据。
- 合成流水线:
- 大语言模型生成多样化问题;视觉语言模型生成详细、分步答案。
- 逻辑一致性优化:大语言模型验证推理;视觉语言模型重新生成模糊响应。
- 渲染引擎添加排版噪声、背景、模糊和仿射变换以模拟真实场景。
-
STEM 数据
- 覆盖图表、物理、化学和工程示意图。
- 三阶段流水线:
- 多维过滤(视觉相关性、答案正确性、推理完整性)。
- 合成 + 一致性验证:视觉语言模型重新生成答案;大语言模型验证对齐或强制扰动查询下的不变性。
- 视觉引导的问题扩展:微调的视觉语言模型从图像 + 答案预测问题;大语言模型从描述中提取实体以生成教育性问题。
- 通过动态文本渲染到图像模拟真实使用场景。
-
GUI 数据
- 双流流水线:
- 单轮定位:聚合开源 UI 数据集;通过大语言模型作为评判器集成过滤标签正确性。
- 长期轨迹:通过桌面/移动/网页沙盒系统合成;隐私可控。
- 奖励引导的混合验证:最佳轨迹进行人工标注;其余用于持续预训练。
- 双流流水线:
-
SFT 与 RL 数据整理
- SFT:从预训练语料库中通过视觉语言模型评分 + 关键词分类平衡挖掘高质量样本;开源数据集由视觉语言模型重写为段落级响应。
- RL:
- 任务分类为视觉、STEM、OCR、VQA、指令跟随。
- 可验证性驱动过滤:优先选择客观、确定性样本;排除多项选择/是非题。
- 基于共识的问答验证:使用多个模型验证。
- 复杂度校准:丢弃 8 个 SFT 模型响应全部正确的样本。
-
处理与元数据
- 定位:使用边界框或多项式输出;开放世界提示支持中英文灵活表述。
- 分割:每张图像内标签随机打乱;RLE 编码掩码;后处理通过 DenseCRF 或 sigmoid + 阈值(用于开放集)。
- 深度:提示位于图像前;量化区间反量化为真实深度;焦距归一化为 2000 像素。
- 所有数据均进行任务特定增强;裁剪和调整大小因任务和分辨率而异。
方法
作者基于视觉-语言统一自回归监督(VLUAS)范式构建了新颖框架 Youtu-VL,该范式从根本上将训练目标从文本主导方法转向视觉与语言的生成式统一。这种范式转变将视觉信号视为自回归预测的主动目标,而非依赖文本的被动输入,从而缓解了通常导致细粒度视觉细节丢失的文本主导优化偏差。核心架构如框架图所示,整合了视觉编码器、视觉-语言投影器和大语言模型(LLM),形成统一系统。视觉编码器基于 SigLIP-2,以原生分辨率处理图像,并采用 2D 旋转位置嵌入(RoPE)和窗口注意力机制,实现高效且空间感知的特征提取。其输出通过空间合并投影器压缩并投影至 LLM 的标记空间,该投影器将相邻 2×2 块特征拼接后应用两层 MLP。LLM 为自研的 Youtu-LLM,扩展以纳入统一视觉-语言词汇表。这通过多阶段训练实现:首先训练专用协同视觉标记器,构建视觉码本,形成统一词汇表 Vunified 的视觉部分。该标记器通过交叉注意力机制融合 SigLIP-2 的高层语义概念与 DINOv3 的低层几何结构,确保生成的离散码保留语义与空间信息。随后应用统一自回归目标 LVLUAS,即文本与视觉预测损失的加权和,使模型能同时重建语言与视觉内容。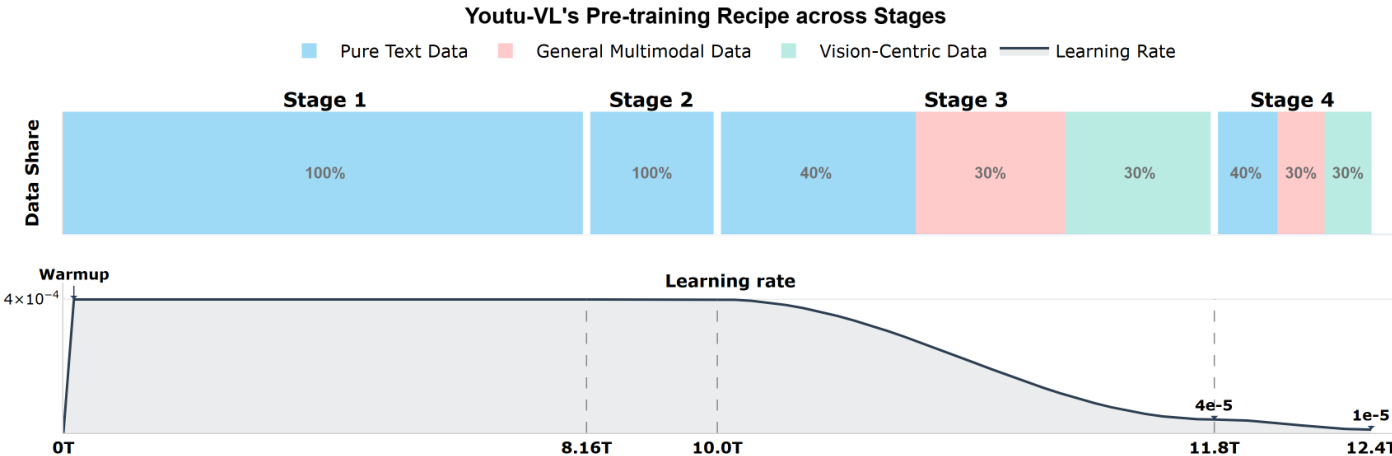
该框架设计使标准架构无需任务特定模块即可执行以视觉为中心的预测。对于基于文本的预测任务(如物体检测与视觉定位),模型直接生成精确边界框作为文本标记,使用带绝对像素坐标的轴特定词汇表,无需归一化。对于密集预测任务(如语义分割与深度估计),模型利用其原生对数概率表示。作者提出多标签下一标记预测(NTP-M)目标监督这些任务。该方法独立建模词汇表中每个标记的概率,允许多标签监督——单个图像块可关联多个语义标签和任务。为解决大词汇表固有的严重类别不平衡问题,采用鲁棒的 NTP-M 损失函数,解耦正负样本处理:计算所有有效正样本的平均损失,仅对按预测概率排序的前 k 个相关负样本计算平均损失,以防止梯度稀释并加速收敛。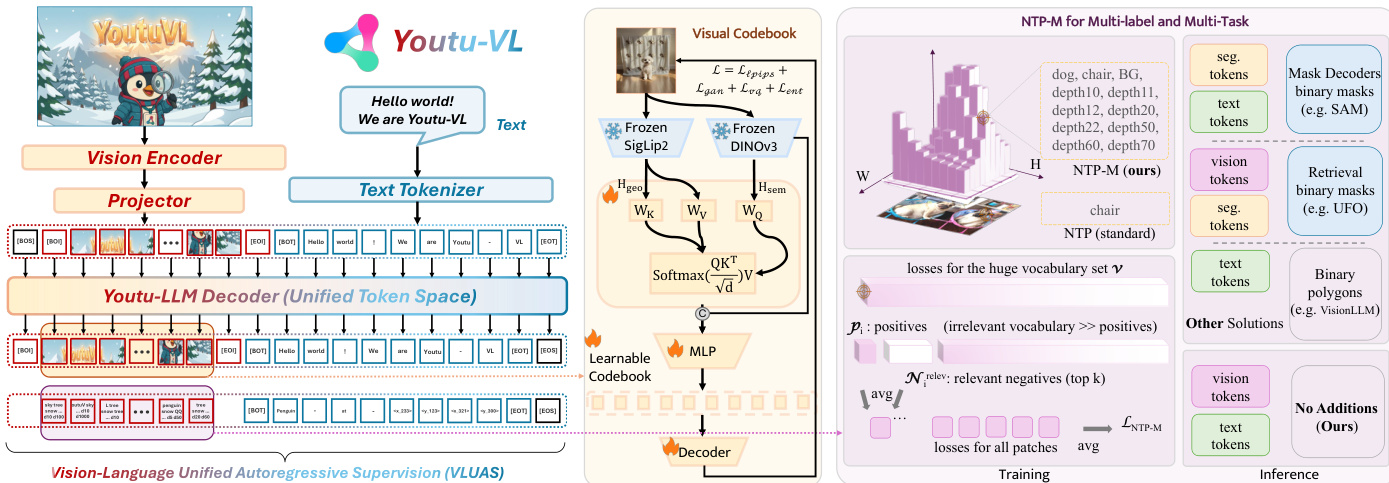
训练过程遵循渐进式四阶段方案。第 1 和第 2 阶段使用纯文本数据预训练语言主干,建立强大的语言基础。第 3 阶段(多模态基础预训练)引入多样化的图像-描述对与以视觉为中心的数据,端到端训练所有组件以获取广泛世界知识与跨模态理解。第 4 阶段(多功能任务适配)使用高质量多模态指令数据集,使模型能有效泛化至多样化用户指令。第 3 和第 4 阶段采用双流监督策略,结合通用多模态数据的自回归视觉重建损失与以视觉为中心数据的专用 NTP-M 损失。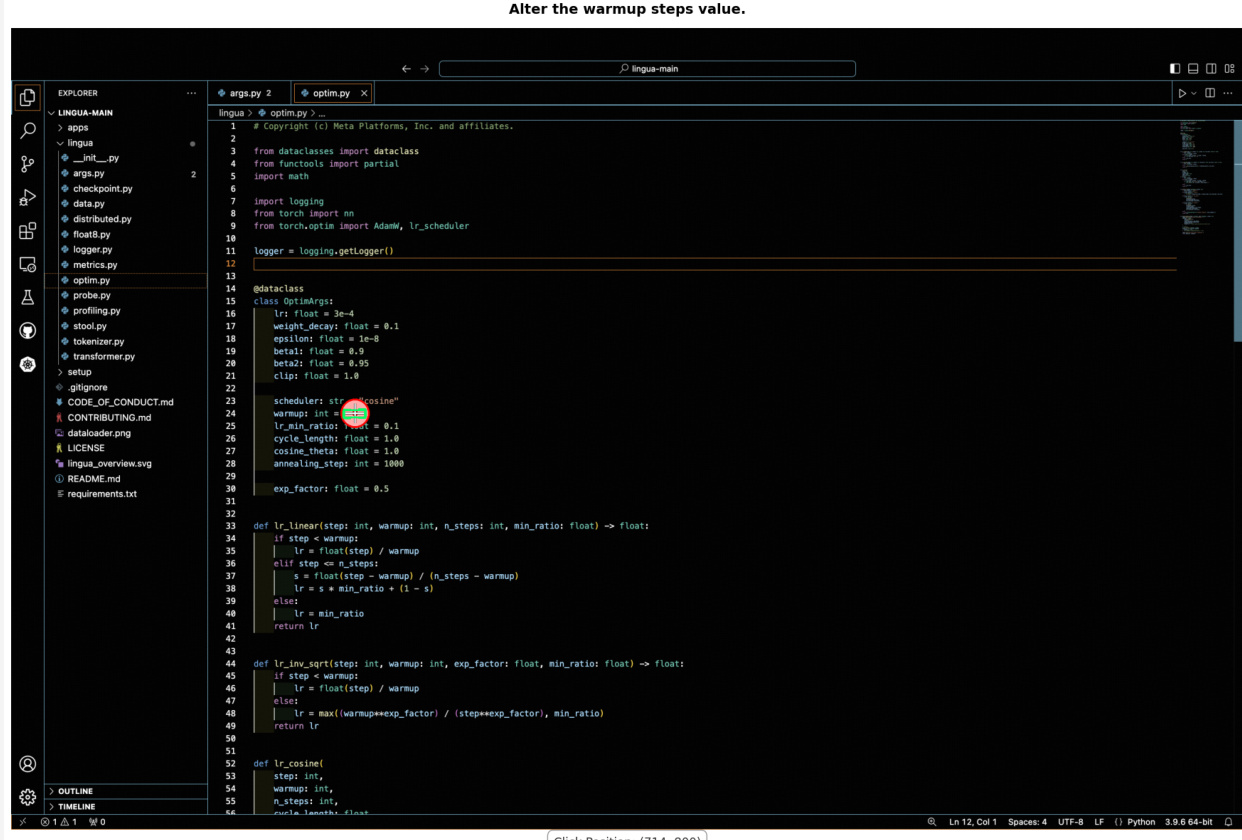
实验
- VLUAS 预训练范式在 27 个多模态基准测试中优于文本主导基线,避免早期饱和,并在第 3 和第 4 阶段实现更优的数据效率。
- 在 2.4T 标记上的扩展性分析证实 VLUAS 符合神经缩放定律(第 3 阶段 α ≈ 0.102,第 4 阶段 α ≈ 0.079),平均得分从 0.43 提升至 >0.74。
- 视觉标记监督提升视觉表征质量,在 PCA 可视化中相较于无此类监督的模型,呈现更清晰的物体分离与语义结构。
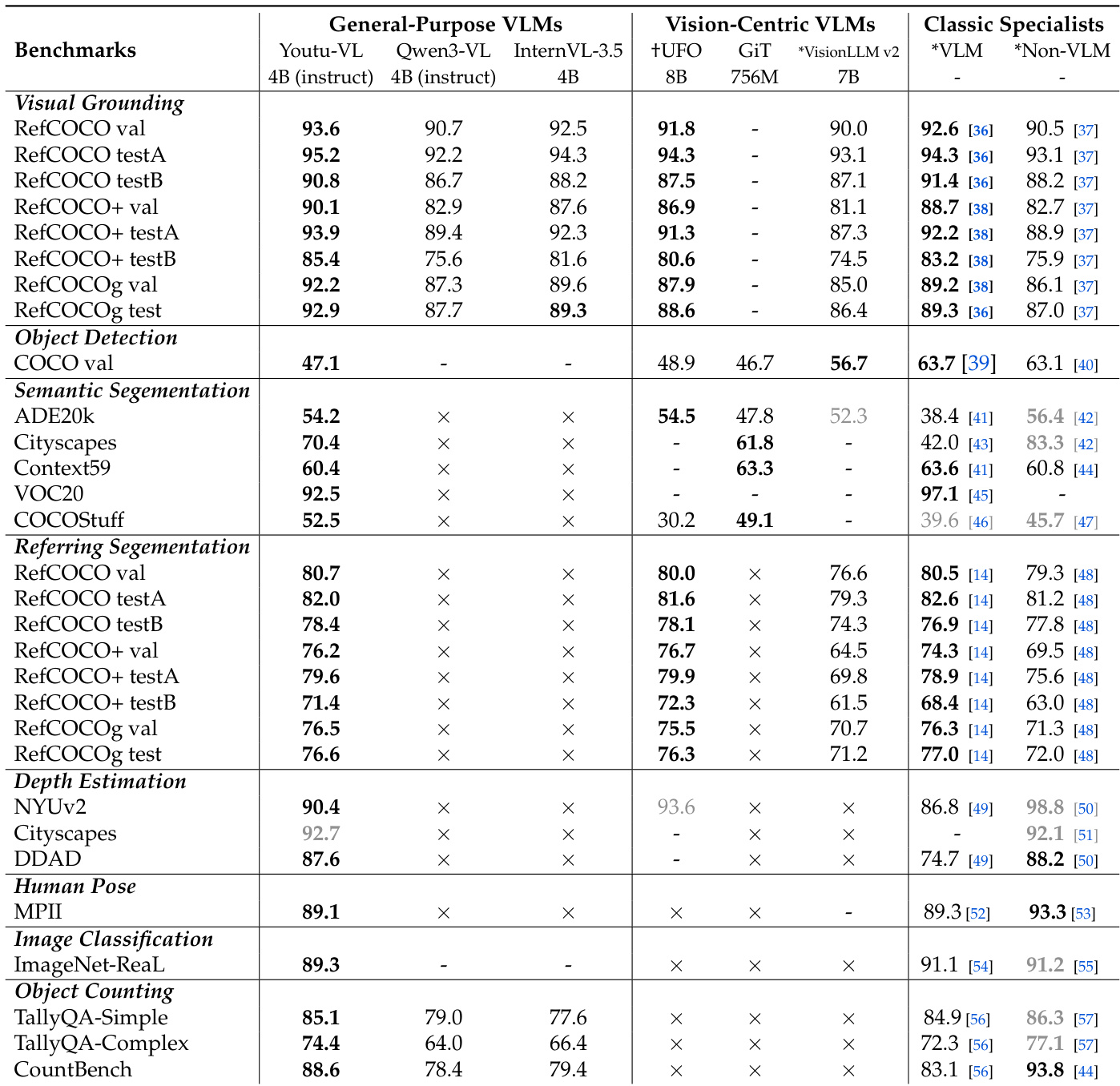
- 在以视觉为中心的任务中,Youtu-VL 在 RefCOCO 上平均得分为 91.8%(对比 InternVL-3.5-4B 的 89.4%),COCO 检测 mAP 为 47.1%(对比 GiT 的 46.7%),ADE20K 分割 mIoU 为 54.2(对比 GiT 的 47.8%)。
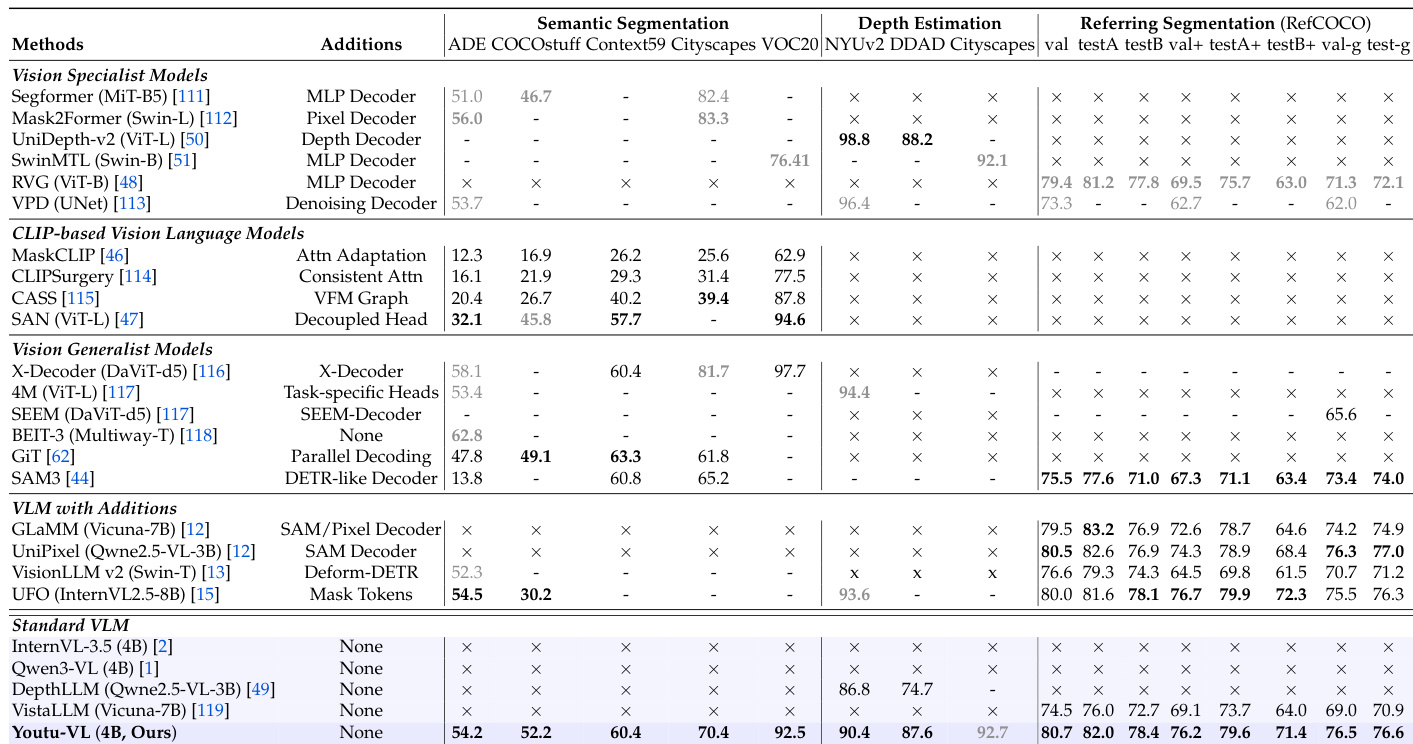
- 在密集预测任务中,Youtu-VL 在 NYUv2 深度估计中达到 90.4 δ1(对比 DepthLLM-3B 的 86.8%),RefCOCO 指代分割 mIoU 为 80.7%(对比 UFO 的 80.0%)。
- 在通用多模态任务中,Youtu-VL 在 MMBench-EN 上得分为 83.9,VLMs Are Blind 上为 88.9%,MathVerse 上为 56.5%,RealWorldQA 上为 74.6,幻觉抑制表现优于同行(HallusionBench 上为 59.1%)。
- GUI 代理评估在 OSWorld 上实现最先进的 38.8% 成功率,展示强大的定位到动作映射能力和多轮计算机使用中的容错性。
- Youtu-VL 在物体计数(CountBench 上 88.6%)、姿态估计(MPII 上 [email protected] 为 89.1%)和分类(ImageNet-ReaL 上 Top-1 为 89.3%)任务中匹配或超越专用模型,无需任务特定头或微调。
作者将 Youtu-VL 与各种视觉专用、通用及多模态模型在检测、计数和定位任务上进行比较。结果显示,Youtu-VL 在检测任务(COCO 上 47.1 mAP)表现具有竞争力,在计数任务(CountBench 上 88.6)领先,并在定位任务(尤其是 RefCOCO 分割)中优于许多模型。
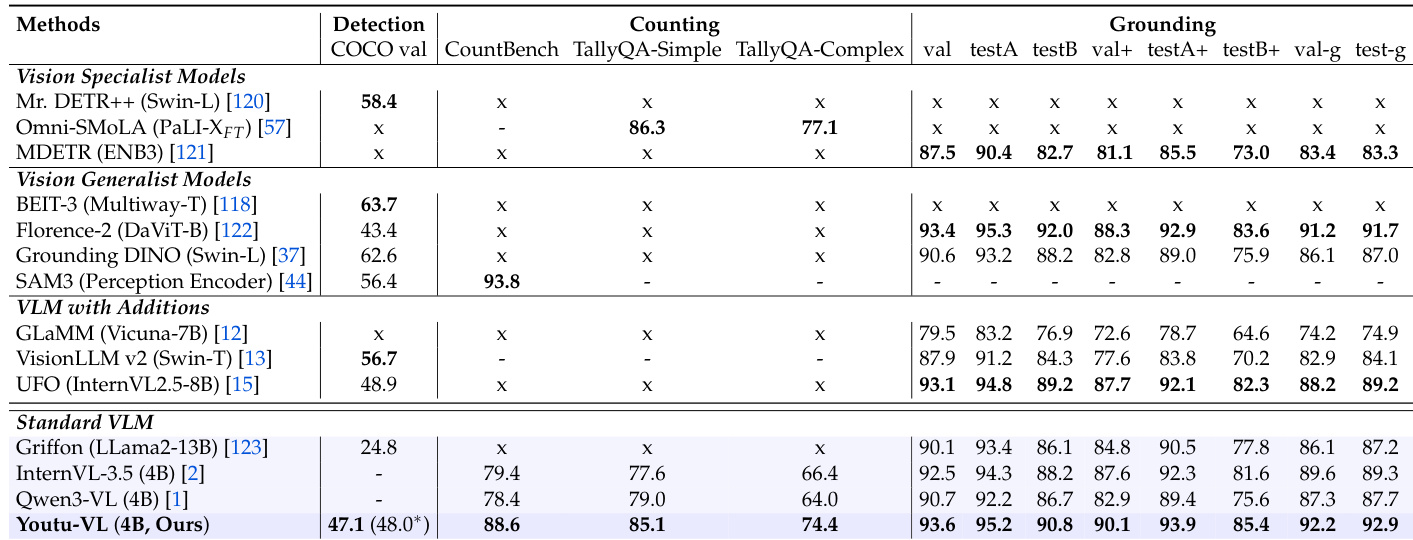
作者使用全面评估框架,将 Youtu-VL 与通用 VLM、以视觉为中心的 VLM 和经典专用模型在广泛视觉任务上进行比较。结果表明,Youtu-VL 在视觉定位、物体检测、语义分割和深度估计等任务中达到最先进或具有竞争力的性能,同时在物体计数和人体姿态估计方面表现强劲。该模型在许多领域优于或匹配专用模型,特别是在大多数通用 VLM 不适用的密集预测任务中,突显其作为统一视觉-语言模型的多功能性和有效性。
作者使用全面评估框架,将 Youtu-VL 与各种以视觉为中心和通用模型在密集预测任务上进行比较。表格显示,Youtu-VL 在语义分割和深度估计中表现强劲,无需额外解码器或标记等任务特定添加,优于许多视觉通用和基于 CLIP 的模型。这表明 Youtu-VL 有效利用其标准 VLM 架构处理复杂视觉任务,展示在密集预测中的多功能性和高能力。
作者使用全面评估框架,将 Youtu-VL 与最先进模型在广泛多模态任务上进行比较。结果表明,Youtu-VL 在大多数基准测试中表现具有竞争力或更优,尤其在视觉定位、物体检测和语义分割等视觉任务中表现突出,同时在多模态推理、OCR 和 GUI 代理任务中也表现出强大能力。