Command Palette
Search for a command to run...
Innovator-VL:面向科学发现的多模态大语言模型
Innovator-VL:面向科学发现的多模态大语言模型
摘要
我们提出 Innovator-VL,这是一种面向科学领域的多模态大语言模型,旨在推动跨多样化科学领域理解与推理能力的发展,同时在通用视觉任务上保持优异性能。与当前依赖大规模领域特定预训练及黑箱式流程的趋势不同,本工作表明,通过严谨的训练设计与透明的方法论,可在显著降低数据需求的前提下实现强大的科学智能。(i)首先,我们构建了一个完全透明、端到端可复现的训练流程,涵盖数据收集、清洗、预处理、监督微调、强化学习以及评估等环节,并提供详尽的优化策略。该流程便于社区系统性地拓展与复现。(ii)其次,Innovator-VL 展现出卓越的数据效率,在仅使用不足五百万条精心筛选样本、无需大规模预训练的情况下,即可在多种科学任务上达到具有竞争力的性能。这一结果表明,通过有原则的数据选择即可实现有效推理,而非依赖无差别的数据规模扩张。(iii)第三,Innovator-VL 具备出色的泛化能力,在通用视觉、多模态推理及科学基准测试中均表现出色,说明科学对齐可被有效融入统一模型架构中,而不会损害其通用性。我们的实践表明,即便在缺乏大规模数据的前提下,仍可构建高效、可复现且高性能的科学多模态模型,为未来研究提供了切实可行的技术基础。
一句话总结
上海交通大学、DP Technology 及合作者提出 Innovator-VL,这是一种数据高效、透明的多模态大语言模型,仅使用不到 500 万精选样本,即可在科学和通用视觉任务上取得优异表现,挑战了大规模领域特定预训练的必要性,同时支持可复现、可扩展的科学人工智能。
主要贡献
- Innovator-VL 引入了一套完全透明、端到端可复现的科学多模态建模训练流程,涵盖数据整理、微调、强化学习和评估,并提供详细的超参数配置,便于社区复现与扩展。
- 该模型在少于五百万精选样本下即实现具有竞争力的科学推理性能,证明数据效率与原则性训练设计可替代大规模领域特定预训练。
- Innovator-VL 在通用视觉、多模态推理和科学基准测试中保持强大泛化能力,证明科学对齐可与广泛多模态能力共存,无需牺牲后者。
引言
作者利用一套原则性、透明的训练流程构建了 Innovator-VL —— 一种在科学推理方面表现出色、同时保留强大通用视觉能力的多模态大语言模型。以往科学领域的多模态大语言模型常依赖大规模领域特定数据集与不透明训练方法,限制了可复现性与泛化能力;许多模型亦为科学性能牺牲了广泛的多模态能力。Innovator-VL 通过在科学与通用基准测试中取得具有竞争力的结果(仅使用少于五百万精选样本,且无需科学预训练)解决此问题,并引入结构化视觉编码与强化学习以增强推理保真度。其统一设计证明科学对齐与通用实用性可共存,为未来科学人工智能研究提供可复现、数据高效的基础。
数据集

作者使用多阶段、多模态数据集流程训练与评估 Innovator-VL,结合通用指令数据、推理导向语料、科学领域数据集与强化学习专用样本。具体分解如下:
-
通用多模态指令数据:
使用 LLaVA-OneVision-1.5-Instruct(约 2200 万样本),涵盖 Caption、图表与表格、代码与数学、VQA、定位与 OCR 等类别。设计用于均衡覆盖,并通过强劲基准表现验证。 -
思维链与多步推理数据:
整合 Honey-Data-15M(约 1500 万样本),覆盖多元领域。作者移除显式“思考”标签以避免模板噪声,保留自然推理结构,同时提升鲁棒性。 -
科学理解数据:
通过结构化流程合成三个领域的高质量数据集:- 野外 OCSR:使用 E-SMILES 格式(SMILES〈sep〉EXTENSION)表示复杂化学结构。结合 700 万合成样本与真实专利/论文 PDF,通过主动学习、人工介入校正与集成置信度评分优化。
- 化学反应理解:从 PDF 中提取反应方案,结合布局解析与裁剪。问答对由模型生成后经专家精修;包含对抗干扰项与“以上皆非”选项以减少幻觉。
- 微观结构表征(EM):聚合真实 EM 图像,裁剪非结构区域,使用 9D 属性模式标注。通过迭代人工介入工作流完成分割与描述,并辅以交叉验证与专家裁决。
-
强化学习训练数据(Innovator-VL-RL-172K):
通过差异驱动选择:保留 Pass@N 高但 Pass@1 低的样本(指示策略不一致)。按奖励分数过滤保留中等难度样本。所有样本标准化为统一推理格式。组成:56.4% STEM 与代码,34.9% 通用多模态,其余为科学(5.0%)、空间(2.4%)、定位(0.9%)、计数(0.2%)、OCR 与图表(0.2%)。 -
处理与元数据:
- 对 EM 数据(去除水印/文字)和 PDF(保留标题/标签)进行裁剪。
- 化学结构使用 E-SMILES 格式,兼容 RDKit 并支持序列建模。
- 专家验证、集成评分与迭代再训练循环确保各科学领域数据质量。
- 所有 RL 样本标准化为逐步推理输出以稳定训练。
-
评估基准:
在三个维度测试:- 通用视觉:AI2D、OCRBench、ChartQA、MMMU、MMStar、VStar-Bench、MMBench、MME-RealWorld、DocVQA、InfoVQA、SEED-Bench、SEED-Bench-2-Plus、RealWorldQA。
- 数学与推理:MathVista、MathVision、MathVerse、WeMath。
- 科学:ScienceQA、RxnBench、MolParse、OpenRxn、EMVista、SmolInstruct、SuperChem、ProteinLMBench、SFE、MicroVQA、MSEarth-MCQ、XLRS-Bench。
这种结构化、多源方法使模型在发展广泛多模态能力的同时,专精于复杂的科学与推理任务。
方法
作者为 Innovator-VL 采用三阶段架构,遵循视觉编码器-投影器-语言模型的成熟范式,有效桥接视觉与文本模态。整体框架整合视觉编码器、投影器与语言模型,实现多模态理解与推理。请参见框架图以了解模型结构与数据流的视觉概览。
视觉编码器组件基于 RICE-ViT,这是一种专为区域感知表示学习设计的视觉 Transformer 变体。不同于仅关注全局块交互的模型,RICE-ViT 引入专用区域 Transformer 层,同时捕获整体与局部视觉线索。此能力对科学图像至关重要,因其常包含细粒度结构与空间局部模式。RICE-ViT 中的区域感知聚类判别机制通过联合优化对象与 OCR 区域表示增强语义嵌入,从而提升定位与密集预测等任务表现。采用 RICE-ViT 使 Innovator-VL 获得符合科学多模态理解需求的强大视觉表示能力。
为桥接视觉编码器与语言模型,Innovator-VL 采用一种称为 PatchMerger 的学习型标记压缩模块。该模块解决了处理视觉 Transformer 密集视觉标记带来的二次计算成本问题。通过学习将大量输入块嵌入合并为少量代表性标记,PatchMerger 显著减少下游组件需处理的序列长度,从而大幅降低计算复杂度与内存占用。此压缩促进与语言模型更高效的跨模态交互,同时不损害视觉表示的丰富性,尤其在有限科学数据集训练时尤为有益。PatchMerger 模块位于视觉编码器与语言模型之间,如框架图所示。
对于语言建模与推理组件,作者采用 Qwen3-8B-Base,这是一种在涵盖多领域与语言的多样化语料库上预训练的大语言模型。Qwen3-8B-Base 在 STEM、逻辑推理与长上下文理解方面表现强劲,适合需整合文本与视觉信息的科学多模态任务。其开源性质与成熟的工具生态系统亦契合构建完全透明、可复现科学多模态大语言模型的目标。
Innovator-VL 的预训练过程包含两个阶段。第一阶段“语言-图像对齐”涉及预训练投影器,使视觉特征与 LLM 词嵌入空间对齐,使用 LLaVA-1.5 558k 数据集。第二阶段“高质量中期训练”转向所有模块的全参数训练,使用 LLaVA-OneVision-1.5-Mid-Training 数据集,该数据集包含约 8500 万高质量图文对,源自多样来源,并采用基于特征的概念平衡采样策略,确保语义多样性与平衡,促进稳健的视觉-语言对齐。
预训练后,Innovator-VL 经过分阶段后训练以精炼能力,包括监督微调与强化学习。监督微调阶段旨在提升模型的指令遵循能力、多步推理与科学理解。强化学习阶段进一步增强模型的多模态推理能力及其解决复杂科学问题的能力。训练流程由高性能分布式训练框架支持,采用先进优化策略以最大化计算吞吐量与内存效率。
实验
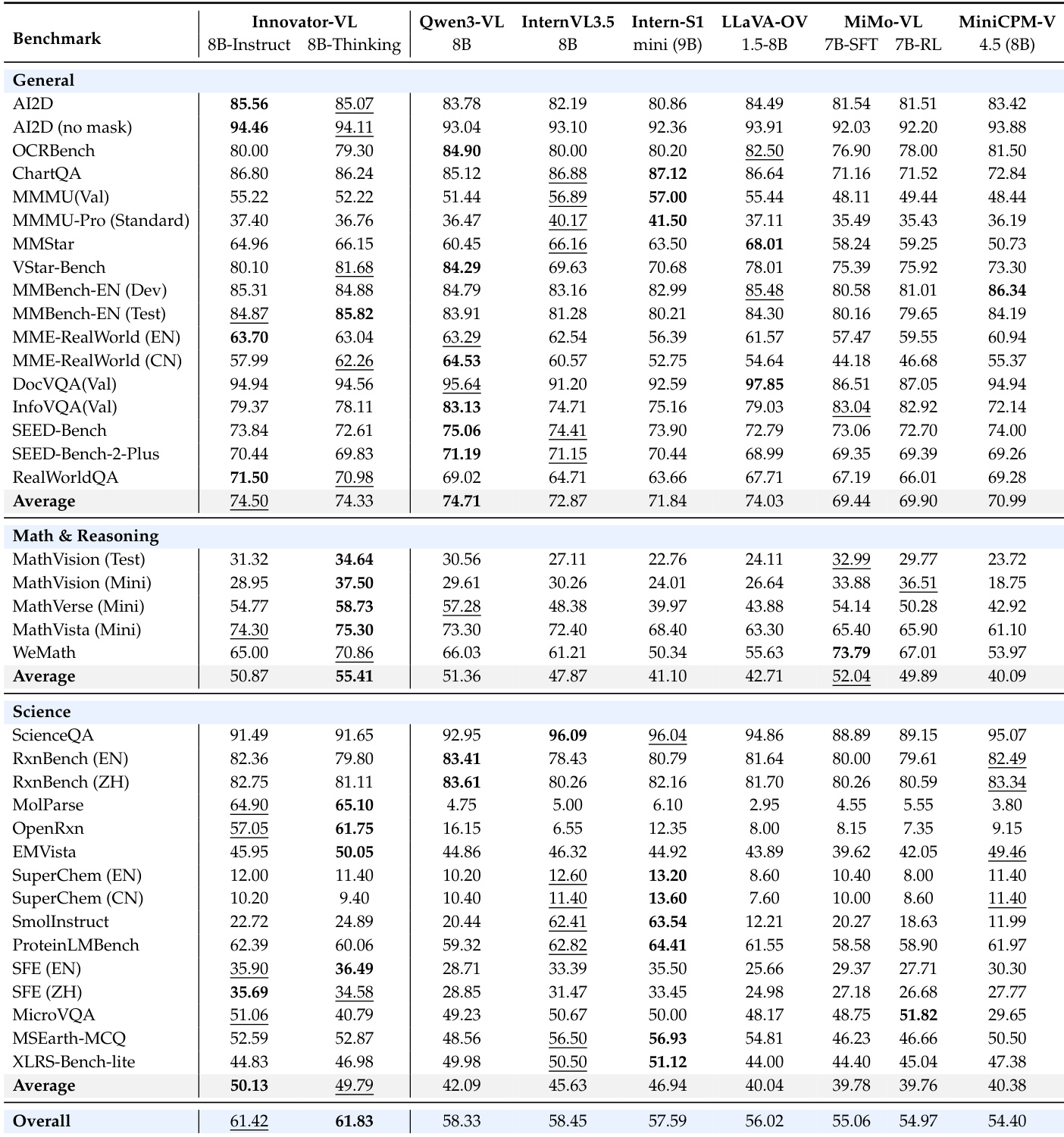
- Innovator-VL-8B-Thinking 在 37 个基准测试中平均得分 61.83%,超越包括 Qwen3-VL-8B、InternVL3.5-8B 与 MiMo-VL-7B 在内的所有 7B–9B 模型。
- Innovator-VL-8B-Instruct 在通用多模态任务中得分为 74.50%,与 Qwen3-VL-8B 相当,并在 MME-RealWorld、AI2D 与 RealWorldQA 上领先。
- Innovator-VL-8B-Thinking 在数学与推理任务中表现优异(55.41%),比其指令变体高 4.54%,通过 RL 增强推理超越所有同类模型。
- 在科学领域,Innovator-VL 获得前两名平均分(50.13%、49.79%),在化学任务中表现突出(如 OpenRxn 得分 57%,MolParse 得分 64%,其他模型均低于 17%)。
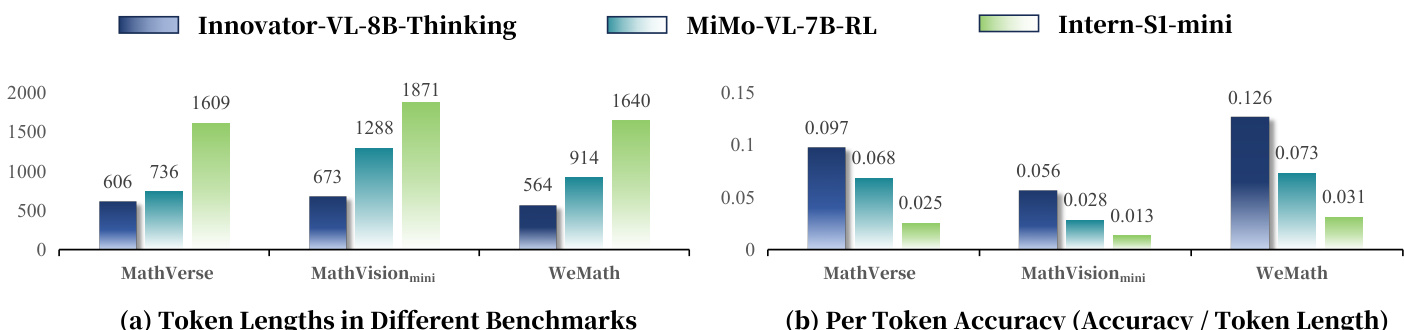
- Innovator-VL-8B-Thinking 生成的标记比 Intern-S1-mini 少 62–66%,比 MiMo-VL-7B-RL 少 18–48%,同时实现 1.4–4.3 倍更高的准确率-标记比,展现卓越的推理效率。
- 定性案例证实其鲁棒性:在视觉问答、复杂几何、化学符号与科学诊断等基线模型失败的任务中给出正确答案。
作者为 Innovator-VL 使用多阶段训练流程,从使用投影器与 LLaVA-1.5 数据集的语言-图像对齐开始,继而进行大规模数据集的高质量中期训练、监督微调,最后使用推理导向数据集进行强化学习。此结构化方法使模型在通用、数学与科学基准测试中均取得强劲表现,同时保持高推理效率。

作者使用 Innovator-VL-8B-Thinking 在通用、数学与科学基准测试中实现最先进性能,整体平均得分为 61.83%,超越所有可比模型。结果表明,Innovator-VL-8B-Thinking 在科学领域显著优于其他模型,尤其在 OpenRxn 与 MolParse 等化学任务中表现突出,同时在更短推理链与更高准确率-标记比下展现出卓越推理效率。
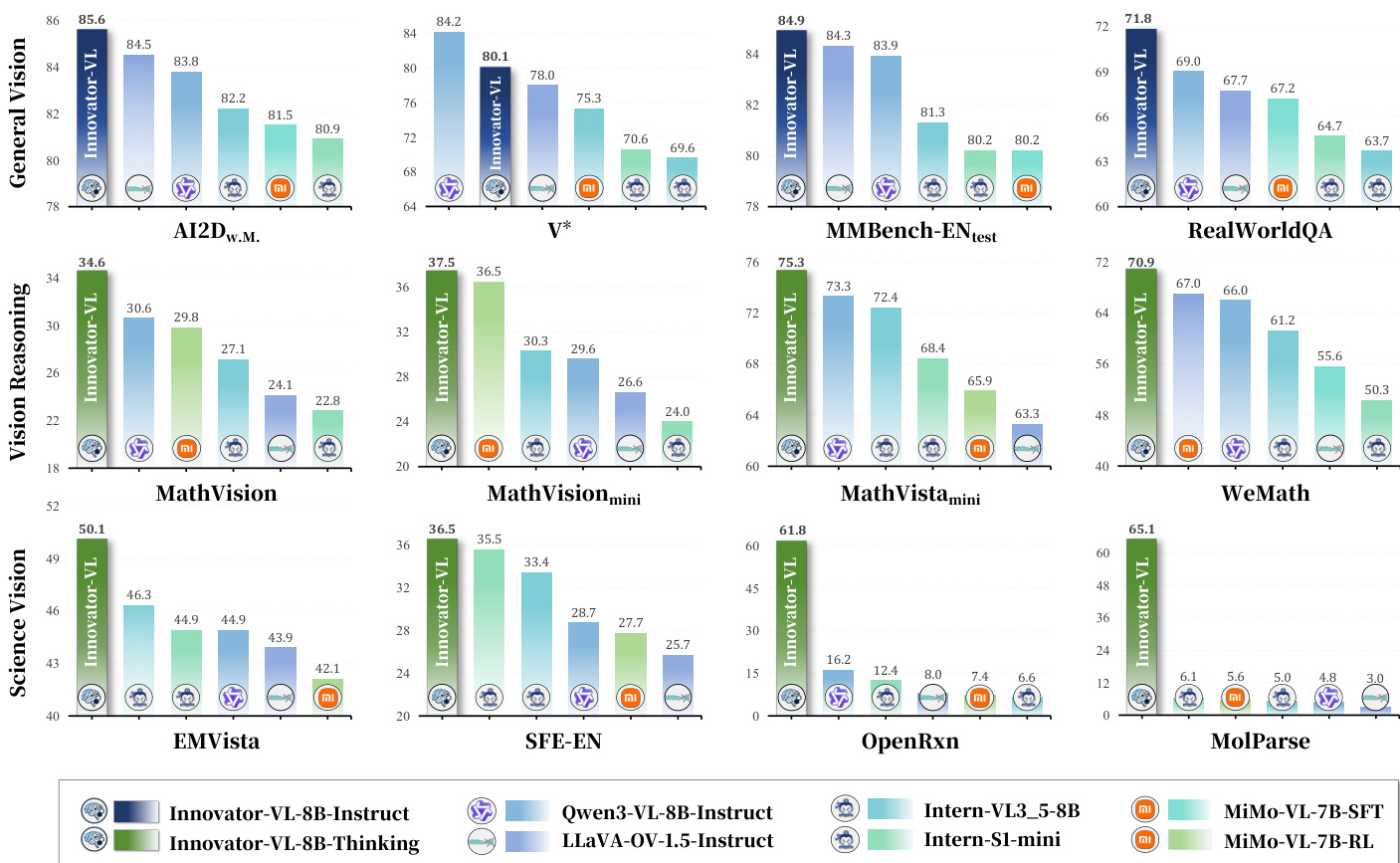
作者使用 Innovator-VL-8B-Thinking 在多个基准测试中实现最先进性能,模型在通用视觉、数学推理与科学领域均获得最高分。结果表明,Innovator-VL-8B-Thinking 在所有对比模型中表现最优,尤其在 OpenRxn 与 MolParse 等专业科学任务中表现卓越,得分分别超过 57% 与 64%,而其他模型均未超过 17%。
作者使用表格比较 Innovator-VL-8B-Thinking、MiMo-VL-7B-RL 与 Intern-S1-mini 在视觉推理基准测试中的标记效率。结果表明,Innovator-VL-8B-Thinking 生成的推理链显著更短,比 Intern-S1-mini 少消耗约 62% 至 66% 的标记,比 MiMo-VL-7B-RL 少 18% 至 48%,同时实现更高的准确率-标记比,表明其推理效率更优。