Command Palette
Search for a command to run...
通过简单点预测实现像素级VLM感知
通过简单点预测实现像素级VLM感知
摘要
我们提出 SimpleSeg,一种简洁而高效的方法,用于赋予多模态大语言模型(MLLMs)原生的像素级感知能力。我们的方法将图像分割重构为一个简单的序列生成问题:模型直接在语言空间内预测描述目标边界的点序列(以文本形式表示的坐标),无需依赖额外的视觉处理模块。为实现高精度,我们设计了一种两阶段的 SFoRL 训练流程,其中基于交并比(IoU)奖励的强化学习机制对点序列进行优化,使其精准匹配真实边界轮廓。我们发现,标准的 MLLM 架构本身具备强大的底层感知能力,仅通过适当训练即可释放这一潜力,而无需引入专用的视觉架构。在多个分割基准测试中,SimpleSeg 的性能与现有复杂、任务定制化方法相当,且在多数情况下更优。本研究表明,仅通过简单的点预测即可实现精确的空间理解,挑战了当前对辅助组件的依赖,为构建更加统一且强大的视觉语言模型(VLMs)开辟了新路径。项目主页:https://simpleseg.github.io/
一句话总结
来自月之暗面AI与南京大学的研究人员提出了SimpleSeg,这是一种极简方法,使多模态大语言模型(MLLM)能够在语言空间中通过点序列预测实现像素级分割,并通过SFT→RL训练结合IoU奖励机制增强性能,超越复杂架构,证明空间理解能力可自然从标准模型中涌现。
主要贡献
- SimpleSeg使MLLM能够通过预测描述对象边界的文本坐标序列实现像素级分割,无需专用解码器或辅助组件,完全在语言空间内运行。
- 该方法引入两阶段SFT→RL训练流程,其中基于IoU奖励的强化学习优化点序列以匹配真实轮廓,无需修改架构即可释放MLLM的细粒度感知潜力。
- 在refCOCO等基准测试中,SimpleSeg表现媲美或超越复杂且任务特定的方法,展现出跨领域与跨分辨率的强大泛化能力,同时保持可解释性与组合推理能力。
引言
作者利用标准多模态大语言模型(MLLM)将像素级分割视为序列生成任务——在模型原生语言空间内预测追踪对象边界的文本坐标。先前方法要么添加破坏架构统一性的复杂任务专用解码器,要么将掩码序列化为文本,牺牲分辨率与可解释性。SimpleSeg的主要贡献是一种极简、无解码器的方法,通过两阶段SFT→RL训练流程(使用IoU奖励优化点序列)实现高保真感知。这表明MLLM本身具备细粒度空间推理能力,无需架构修改即可激活,从而实现跨多样化视觉领域的统一、可解释且泛化能力强的像素级理解。
数据集

- 作者使用大规模开源与网络数据进行预训练,主要为LAION和Coyo,所有样本均通过第3.1节所述流程标注。
- 对于SFT阶段,他们从refCOCO、refCOCO+、refCOCOg和refCLEF的训练集构建了80万样本的数据集,遵循Text4Seg的处理协议。
- 对于RL阶段,他们从相同的RefCOCO系列中提取40万样本的提示集,保持数据来源一致。
- 表1和表2中的所有基准结果均仅使用在SFT和RL阶段(RefCOCO数据集)训练的模型,以确保与SOTA方法公平比较。
- 使用网络数据(LAION/Coyo)的预训练仅用于扩展性和消融分析,结果见表3。
- 元数据包括图像级描述与多边形坐标配对,如SimpleSeq示例所示:对象描述后接像素级精确的多边形坐标列表。
方法
作者采用一种简单而有效的框架SimpleSeg,通过点预测机制赋予标准多模态大语言模型(MLLM)原生像素级感知能力。核心设计是将分割输出表示为显式的二维坐标序列(即点轨迹),完全在语言空间内生成。该方法无需解码器且与架构无关,支持将点、边界框和掩码作为文本输出统一处理。框架通过预测归一化坐标序列追踪目标对象边界,避免了密集像素编码的需求。这种表示方式具有可解释性、可与其他文本输入组合,并支持随顶点数线性扩展的可控token预算,而非随图像分辨率扩展。
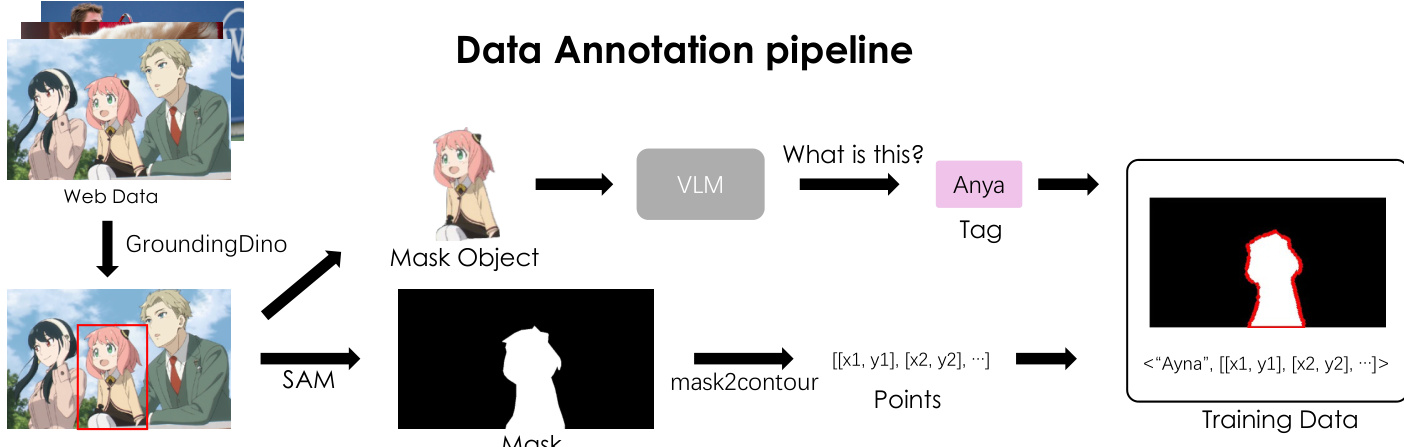
如图所示,数据标注流程旨在利用大规模网络数据扩展框架。流程始于网络数据,经Grounding-DINO处理进行对象检测以识别实例,再将检测到的对象输入SAM生成分割掩码。这些二值掩码通过轮廓提取算法转换为多边形轮廓,强制采用顺时针遍历顺序,并可选地应用稀疏化处理。最终的点序列与由视觉-语言模型(VLM)生成的文本描述结合,形成结构化训练数据。该流程可生成多样化的指令-响应对,使模型学会根据文本提示生成适当的点轨迹。

任务形式化将所有输出(点、边界框、掩码)统一视为文本token。掩码表示为点轨迹,边界被稀疏采样为归一化坐标序列。该表示通过最小化的类JSON语法约束输出格式,确保生成序列结构良好且可解析。框架支持多种定位查询,如根据文本描述预测边界框,或根据点生成多边形。该设计通过重组弱标签(如从掩码中提取点或框)增加监督来源,并标准化输出以支持指令微调与强化学习。
训练流程分为两个阶段。第一阶段为监督微调(SFT),通过整理文本到点、文本到边界框、文本/点到掩码等任务的指令-响应对冷启动模型。该阶段教会模型生成正确的输出格式,包括坐标语法、闭合括号与一致顺序,同时学习基础定位先验。第二阶段采用强化学习(RL)优化序列级、位置感知的目标。作者采用GSPO作为RL算法,使用基于规则的奖励系统,包括:Mask IoU奖励(衡量预测与真实掩码的交并比)、MSE距离IoU奖励(惩罚质心错位)和格式奖励(强制正确输出结构)。该RL阶段使模型发现替代的有效轨迹,提升边界保真度与闭合性,避免过拟合特定标注。
实验
- 在Qwen2.5-VL-7B和Kimi-VL上使用32张GPU、Muon优化器、带稀疏容差ε的多边形序列化进行验证;SFT与RL阶段使用特定学习率及GSPO优化。
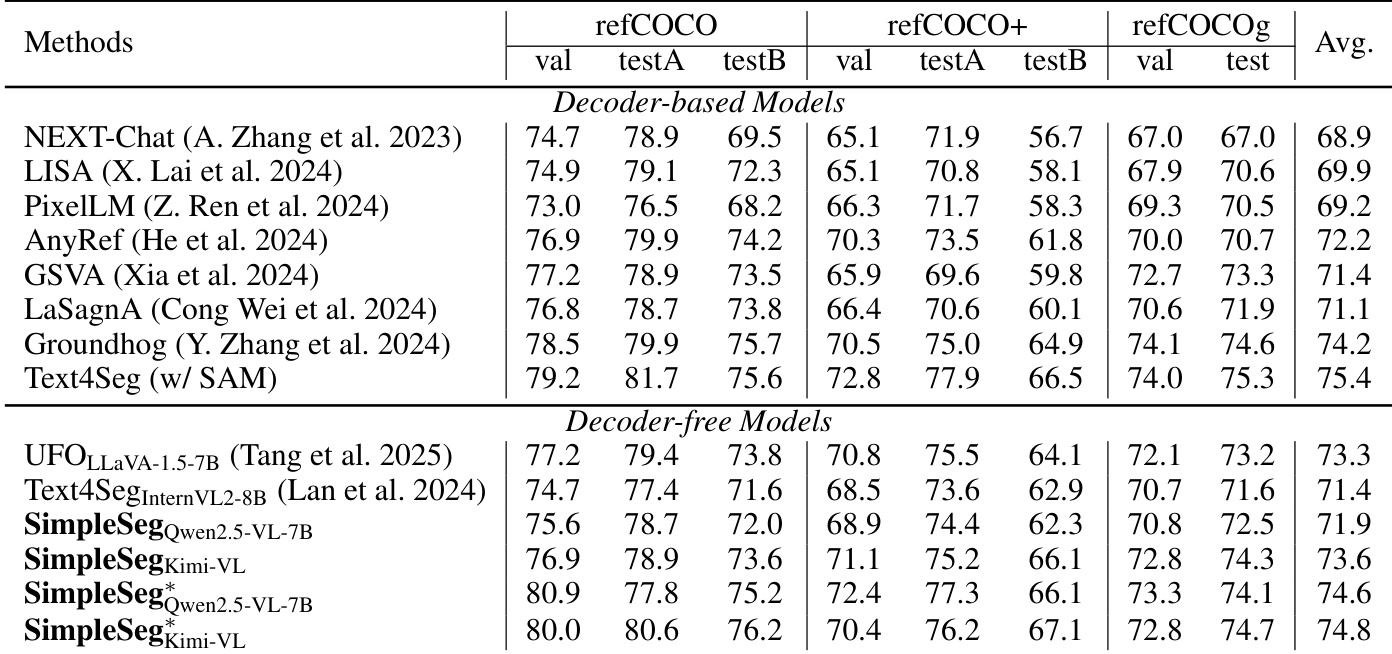
- 在指代表达理解(REC)任务中取得87.2 [email protected]的SOTA成绩,优于Text4Seg(无掩码精修器);在RES任务中匹配基于解码器的方法,且无解码器性能更优。
- 消融实验表明,仅SFT阶段获得约60–65.5 gIoU;RL阶段增加+9.7–10.5 gIoU,证实IoU奖励提升多边形精度与token效率;预训练使refCOCO上的SFT+RL提升13.0 gIoU。
- 最优ε值平衡token长度与几何保真度:221 token(ε=0.005)达到峰值cIoU;过少(78 token)或过多(859 token)均降低性能。
- 顺时针点序对生成有效多边形至关重要;无序或替代序列导致混乱输出与token效率降低。
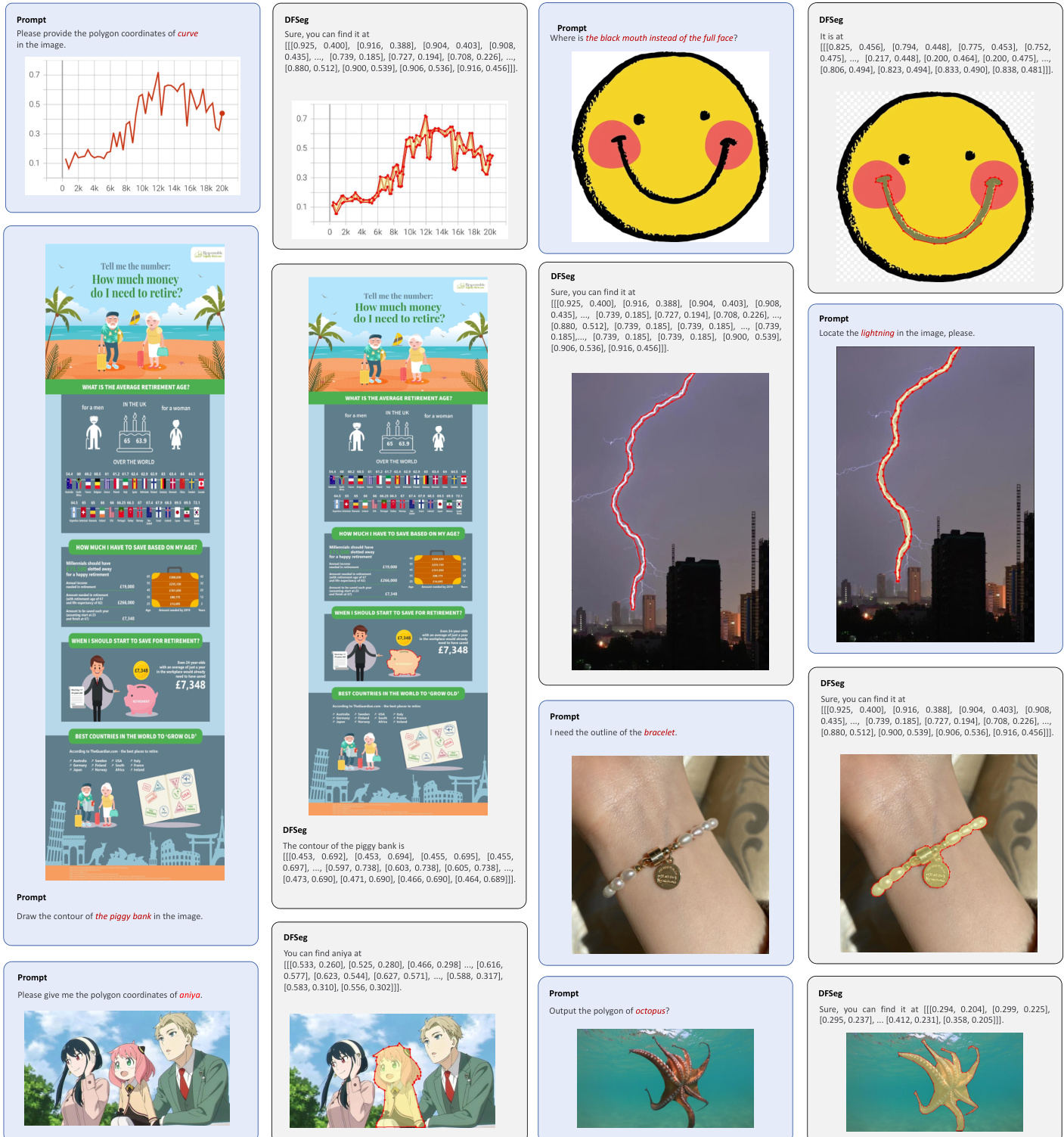
- 扩展至SAM类任务(点→掩码、框→掩码、文本→框)表现良好泛化能力,附录提供视觉结果。
- 局限性:在高分辨率、弯曲物体及锐角处激进稀疏化下表现不佳;未来工作应纳入边界F-score与顶点级指标。
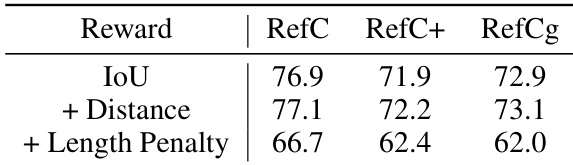
结果表明,加入距离奖励可提升所有数据集性能,gIoU得分约提高0.2。然而,加入长度惩罚会降低性能,表明对序列长度的硬约束损害分割精度。
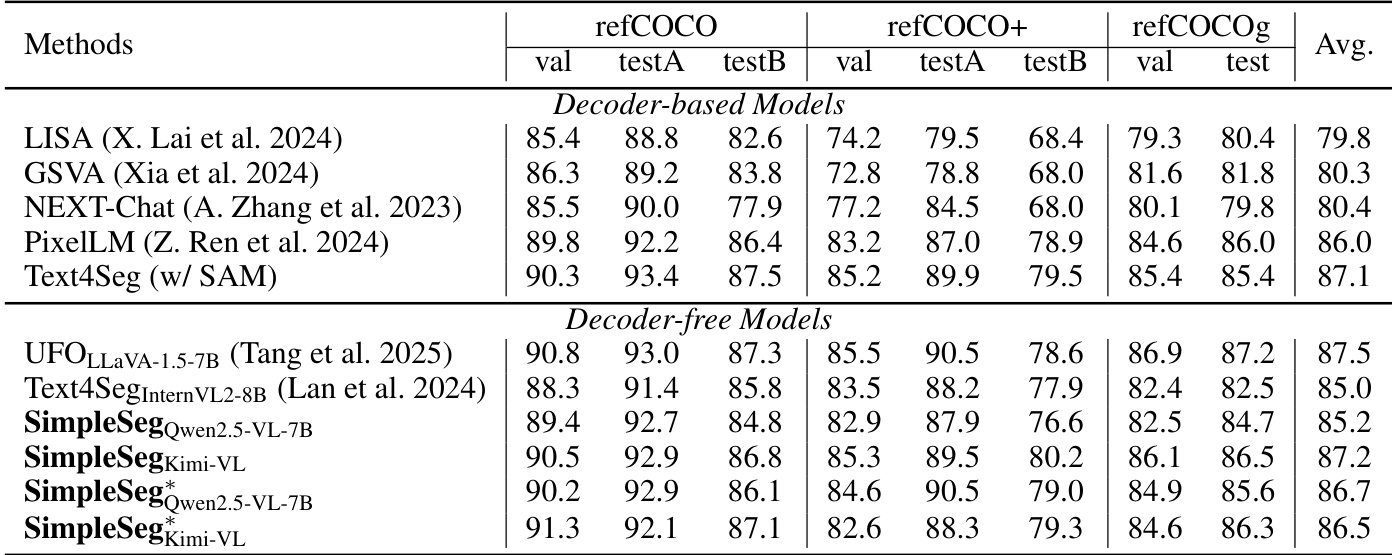
结果表明,SimpleSeg在指代表达分割基准上表现优异,优于其他无解码器模型,且匹配或超越基于解码器的方法。作者采用极简无解码器方法,利用大语言模型生成多边形坐标,展示无需架构修改即可实现强细粒度感知。
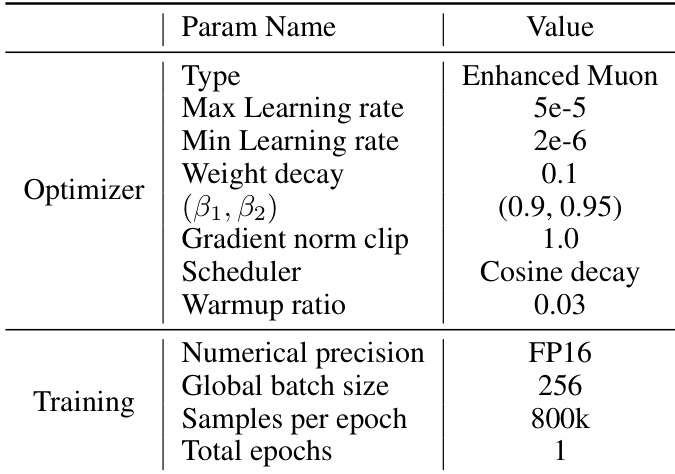
作者使用增强版Muon优化器,最大学习率为5e-5,最小学习率为2e-6,余弦衰减调度器,预热比例为0.03。训练使用全局批大小256,每轮80万样本,共训练1轮。
结果表明,监督微调与强化学习的结合显著提升指代表达分割性能,完整训练流程在所有数据集上取得最高分。消融研究表明,强化学习贡献最大,而单独预训练在无后续微调时无效。

结果表明,SimpleSeg在指代表达分割基准上表现优异,优于无解码器模型,且匹配或超越基于解码器的方法。模型在refCOCO、refCOCO+和refCOCOg数据集上的优异表现,证明其无需架构修改即可实现有效细粒度感知。