Command Palette
Search for a command to run...
一种实用的VLA基础模型
一种实用的VLA基础模型
摘要
在机器人操作领域具有巨大潜力,一个优秀的视觉-语言-动作(Vision-Language-Action, VLA)基础模型应具备跨任务与跨平台的强泛化能力,同时确保成本效益(例如,适应过程所需的数据量和GPU计算时长)。为此,我们构建了LingBot-VLA模型,其训练数据源自9种主流双臂机器人配置的约20,000小时真实世界数据。通过对3种不同机器人平台进行系统性评估,每种平台完成100项任务,每项任务包含130次训练后评估(post-training episodes),我们的模型在性能上显著优于现有竞争者,充分展现了其卓越的表现力与广泛的泛化能力。此外,我们还开发了一个高效的代码框架,在8张GPU的训练配置下,实现了每GPU每秒261个样本的吞吐量,相较于现有的VLA专用代码库,性能提升达1.5至2.8倍(具体取决于所依赖的视觉语言模型基础架构)。上述特性共同确保了本模型在真实场景部署中的高度适用性。为进一步推动机器人学习领域的发展,我们开放提供代码、基础模型及基准数据集,旨在支持更具挑战性的任务研究,并促进更加科学、严谨的评估标准建设。
一句话总结
Robbyant 研究人员提出了 LingBot-VLA,这是一种在 9 个平台上基于 20,000 小时真实机器人数据训练的视觉-语言-动作基础模型,通过混合 Transformer 架构和空间感知深度对齐实现最先进的泛化能力,并将训练吞吐量提升 1.5–2.8 倍,从而支持可扩展且可部署的机器人操作。
主要贡献
- LingBot-VLA 在来自 9 个平台的 20,000 小时真实双臂机器人数据上训练,证明了 VLA 性能随数据量增加而显著提升,且在当前规模下未出现饱和,从而在跨任务和跨实体场景中实现更强的泛化能力。
- 该模型在 3 个机器人平台上进行严格的真实世界评估,完成 100 个多样化任务(每任务 130 个回合),表现优于竞争对手,建立了多平台 VLA 评估的新基准。
- 优化后的训练代码库在 8-GPU 设置下实现每 GPU 每秒 261 个样本,相比现有 VLA 框架提速 1.5–2.8 倍,降低计算成本并加速部署就绪模型的开发。
引言
作者利用视觉-语言-动作(VLA)基础模型,使机器人能够根据自然语言指令执行多样化的操作任务,旨在弥合大规模预训练与真实世界部署之间的差距。先前工作缺乏在真实机器人上的系统性评估,且训练代码库效率低下,限制了数据扩展和多平台测试。其主要贡献是 LingBot-VLA,该模型在 9 个平台上的 20,000 小时真实双臂机器人数据上训练,展示了性能随数据规模稳定提升,并在 100 个任务上跨 3 个机器人实体实现最先进的泛化能力。同时,他们还发布了优化的训练代码库,相比现有框架提速 1.5–2.8 倍,加速迭代并降低成本,同时通过公开代码、模型和基准促进开放科学。
数据集

-
作者使用一个大规模预训练数据集,数据来源于 9 个双臂机器人平台的遥操作数据,包括 AgiBot G1、AgileX、Galaxea R1Lite/Pro、Realman Rs-02、Leju KUAVO 4 Pro、Oinglong、ARX Lift2 和 Bimanual Franka——每个平台具有不同的自由度机械臂、相机配置和夹爪设置。
-
对于语言标注,人工标注员将多视角机器人视频分割为与原子动作对齐的片段,并裁剪静态的起始/结束帧。随后使用 Qwen3-VL-235B-A22B 为每个片段生成精确的任务和子任务指令。
-
对于 GM-100 基准,通过在三个平台上遥操作收集每任务 150 条原始轨迹;保留其中表现最佳的 130 条(根据任务完成度、流畅度和协议遵守情况)。物体按 GM-100 规范标准化,每条轨迹中物体位姿随机化以增强环境多样性。
-
遥操作遵循严格准则:保持末端执行器间隙、接触时动作缓慢、确保起始/结束视觉状态清晰。自动过滤移除技术异常,再通过多视角视频人工审核排除不符合协议或场景杂乱的片段。
-
测试集包含约 50% 未出现在训练集中最频繁 100 个动作中的原子动作,以确保强泛化评估。图 3a 和 3b 中的词云可视化了训练/测试拆分中的动作类别分布。
-
所有轨迹均处理以符合 GM-100 任务规范,元数据包括标准化物体信息、随机位姿和质量评级的轨迹标签。未提及裁剪;处理重点在于分割、过滤和指令标注。
方法
作者采用混合 Transformer(MoT)架构,将预训练视觉语言模型(VLM)与动作生成模块结合,构成 LingBot-VLA 的核心。该框架通过独立的 Transformer 路径处理视觉-语言和动作模态,并通过共享自注意力机制耦合,实现逐层统一的序列建模。VLM(具体为 Qwen2.5-VL)编码多视角操作图像和任务指令,而动作专家处理包含初始状态和动作块的本体感知序列。该设计确保 VLM 的高维语义先验在所有层引导动作生成,同时通过模态特定处理最小化跨模态干扰。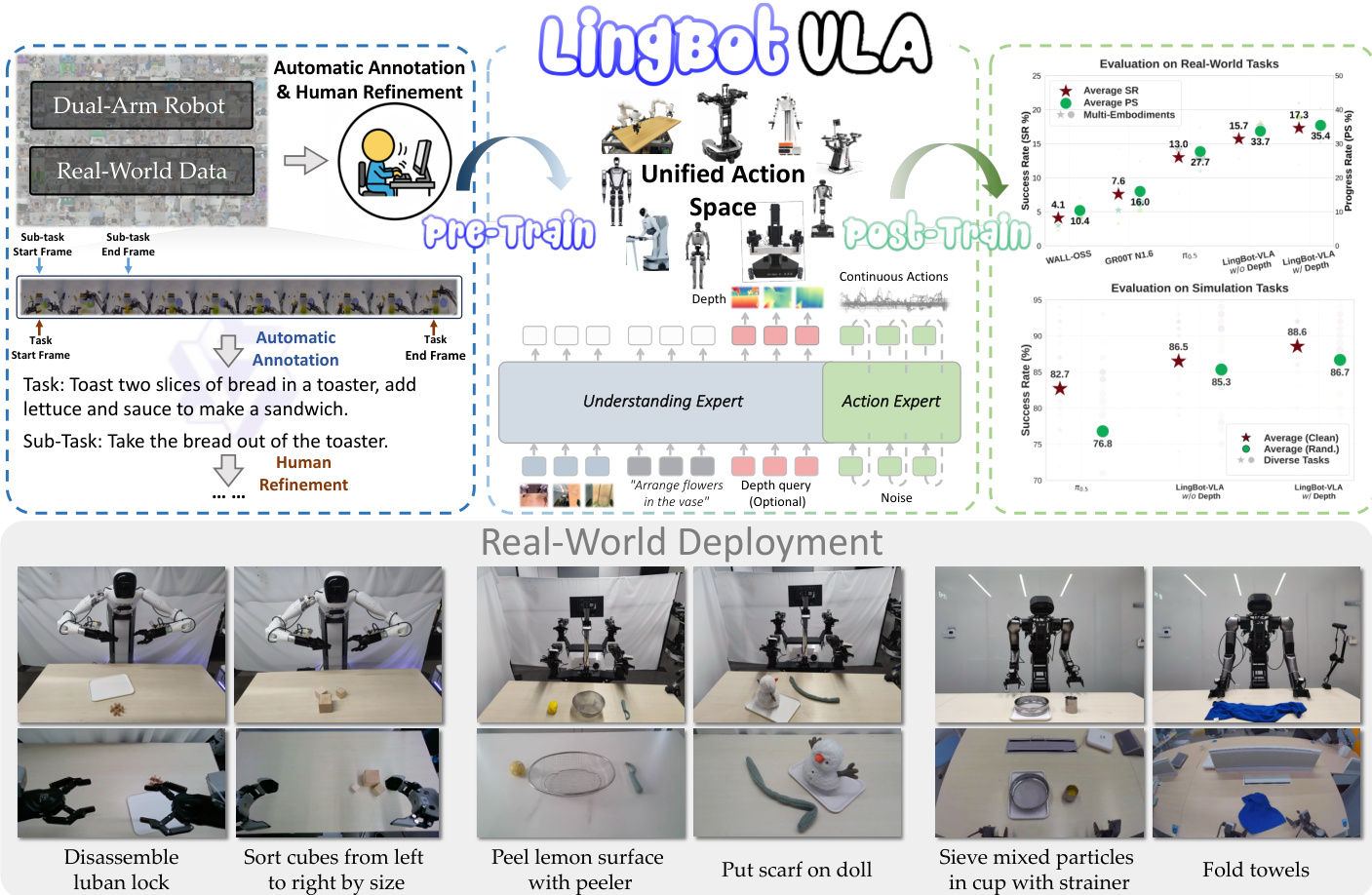
在时间戳 t 的联合建模序列为观察上下文 Ot 与动作块 At 的拼接。观察上下文定义为 Ot=[It1,It2,It3,Tt,st],包含双臂机器人三视角操作图像的标记、任务指令 Tt 和机器人状态 st。动作序列表示为 At=[at,at+1,…,at+T−1],其中 T 为动作块长度,预训练时设为 50。训练目标是使用流匹配(Flow Matching)建模条件分布 p(At∣Ot),以实现精确机器人控制所需的平滑连续动作建模。
对于流时间步 s∈[0,1],中间动作 At,s 通过真实动作 At 与高斯噪声 ϵ∼N(0,I) 的线性插值得到,即 At,s=sAt+(1−s)ϵ。At,s 的条件分布表示为 p(At,s∣At)=N(sAt,(1−s)I)。动作专家 vθ 通过最小化流匹配目标训练以预测条件向量场:
LFM=Es∼U[0,1],At,ϵ∥vθ(At,s,Ot,s)−(At−ϵ)∥2,其中目标速度源自理想向量场 At−ϵ。
为确保正确信息流,对联合序列 [Ot,At] 实施块级因果注意力。序列划分为三个功能块:[It1,It2,It3,Tt]、[st] 和 [at,at+1,…,at+T−1]。因果掩码限制注意力,使得每个块内的标记仅能关注自身及先前块,而块内标记使用双向注意力。这防止未来动作标记的信息泄露到观察表示中。
为增强空间感知和执行鲁棒性,采用视觉蒸馏方法。与三视角图像对应的可学习查询 [Qt1,Qt2,Qt3] 由 VLM 处理,并与 LingBot-Depth 提供的深度标记 [Dt1,Dt2,Dt3] 对齐。该对齐通过最小化蒸馏损失 Ldistill 实现:
Ldistill=EOt∣Proj(Qt)−Dt∣,其中 Proj(⋅) 是使用交叉注意力进行维度对齐的投影层。该整合将几何信息注入模型,提升复杂操作任务中的感知能力。
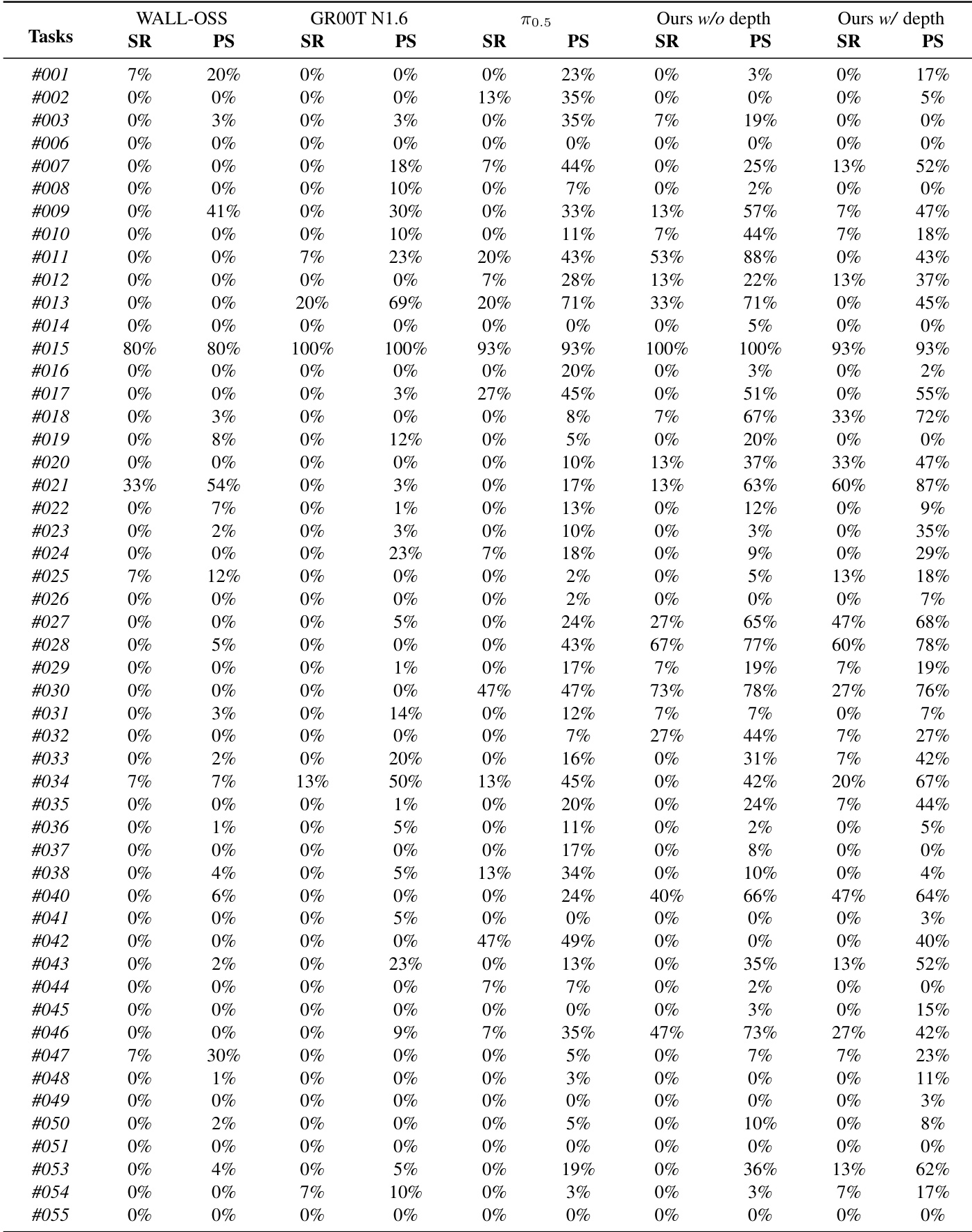
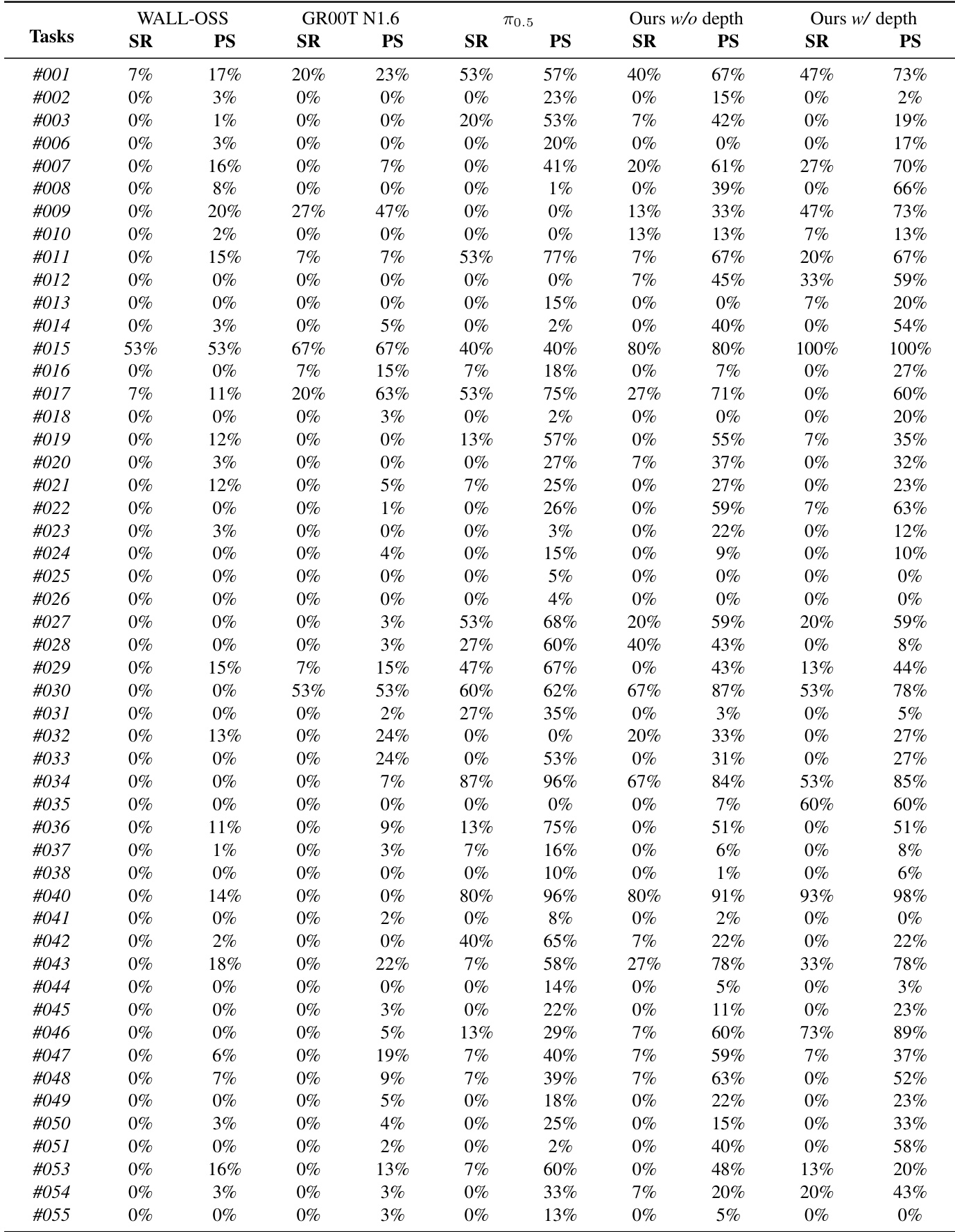
实验
- 在 3 个平台(AgileX、Agibot G1、Galaxea R1Pro)的 25 台机器人上使用 GM-100 基准(100 个任务,39K 演示)评估 LingBot-VLA,完成 22.5K 次受控试验,与 3 个基线在相同条件下对比。
- 在真实世界 GM-100 上,带深度的 LingBot-VLA 相比 π0.5 在各平台平均提升 +4.28% 成功率和 +7.76% 进度得分;持续优于 WALL-OSS 和 GR00T N1.6,GR00T 因预训练对齐在特定平台表现更优。
- 在 RoboTwin 2.0 仿真中,带深度的 LingBot-VLA 在清洁场景下相比 π0.5 提升 +5.82% 成功率,在随机化场景下提升 +9.92% 成功率,利用深度增强的空间先验实现鲁棒的多任务泛化。
- 训练吞吐量分析显示,LingBot 的代码库在 Qwen2.5-VL-3B-π 和 PaliGemma-3B-pt-224-π 上实现最快样本/秒,高效扩展至 256 GPU,优于 StarVLA、Dexbotic 和 OpenPI。
- 扩展实验显示,预训练数据从 3K 小时增至 20K 小时时,成功率和进度得分持续提升,跨平台对齐证实了鲁棒泛化能力。
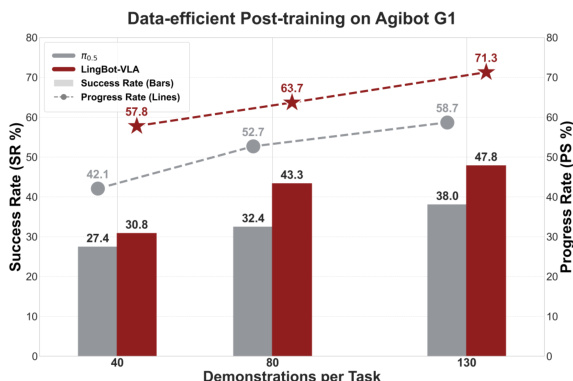
- 在 Agibot G1 平台上的数据效率测试表明,仅使用每任务 80 条演示的 LingBot-VLA 优于使用 130 条演示的 π0.5,且随着数据增加性能差距扩大。
作者使用大规模真实世界基准,在三个机器人平台上评估 LingBot-VLA 与三个最先进的基线,结果显示,不带深度的 LingBot-VLA 在成功率和进度得分上均优于 WALL-OSS 和 GR00T N1.6。通过引入深度信息,带深度的 LingBot-VLA 在所有平台上相比 π₀.₅ 平均提升 4.28% 成功率和 7.76% 进度得分。
作者在 Agibot G1 平台上使用数据高效的后训练实验比较 LingBot-VLA 与 π₀.₅ 基线,显示 LingBot-VLA 使用更少演示即可实现更高的成功率和进度得分。结果表明,即使每任务仅训练 80 条演示,LingBot-VLA 仍优于 π₀.₅,且随着演示数量增加性能差距扩大,证明其卓越的数据效率。
结果显示,LingBot-VLA 在所有平台上均优于 π0.5 基线,引入深度信息的变体实现最高平均成功率 86.68%。作者使用受控评估协议确保公平比较,证明基于深度的空间信息显著提升真实世界任务表现。
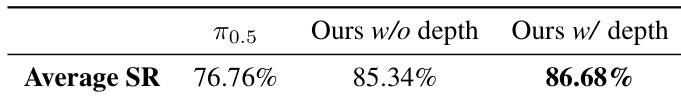
结果显示,LingBot-VLA 在三个机器人平台上均优于所有基线,无论成功率还是进度得分,引入深度信息的变体表现最佳。模型展现出强大的泛化能力,体现在各平台及所有实体平均表现上均持续优于基线。

作者使用大规模真实世界基准,在三个机器人平台上评估 LingBot-VLA 与三个最先进的基线,结果显示,不带深度的 LingBot-VLA 在成功率和进度得分上均优于 WALL-OSS 和 GR00T N1.6。通过引入深度信息,带深度的 LingBot-VLA 在所有平台上相比 π₀.₅ 实现 4.28% 更高的成功率和 7.76% 更高的进度得分,证明通过增强空间理解提升了性能。