Command Palette
Search for a command to run...
AdaReasoner:用于迭代视觉推理的动态工具编排
AdaReasoner:用于迭代视觉推理的动态工具编排
Mingyang Song Haoyu Sun Jiawei Gu Linjie Li Luxin Xu Ranjay Krishna Yu Cheng
摘要
当人类面对超出自身即时能力范围的问题时,通常会依赖工具,这一机制为提升多模态大语言模型(MLLMs)的视觉推理能力提供了极具前景的范式。因此,有效的推理能力关键在于:准确识别应使用哪些工具、在何时调用这些工具,以及如何在多步操作中合理组合使用,即使面对全新的工具或任务亦能如此。我们提出了AdaReasoner——一个能够将工具使用习得为通用推理能力的多模态模型家族,而非局限于特定工具或依赖显式监督的行为。AdaReasoner 的实现依赖于三个核心组件:(i)可扩展的数据构建流水线,使模型能够接触长期、多步骤的工具交互场景;(ii)Tool-GRPO,一种基于最终任务成功目标优化工具选择与序列安排的强化学习算法;(iii)一种自适应学习机制,可动态调节工具的使用策略。上述组件协同作用,使模型能够根据任务上下文与中间结果推断工具的有效性,从而实现多工具间的协调配合,并具备对未见过工具的泛化能力。实证研究表明,AdaReasoner 展现出卓越的工具自适应与泛化能力:它能够自主采纳有益工具、抑制无关工具,并根据任务需求动态调整工具使用频率,而这些行为均未经过显式训练。这些能力显著提升了模型在多个挑战性基准测试中的表现,平均相较 7B 规模的基础模型提升达 +24.9%,并在多项任务(包括 VSP 和 Jigsaw)上超越了 GPT-5 等强大闭源系统,达到当前最优水平。
一句话总结
来自复旦大学、同济大学、新加坡国立大学、华盛顿大学和电子科技大学的研究人员提出了 AdaReasoner,这是一种通过可扩展数据、Tool-GRPO 强化学习和自适应调节机制自主学习工具使用的多模态模型,能够泛化到未见过的工具,并在 VSP 和 Jigsaw 基准测试中超越 GPT-5。
主要贡献
- AdaReasoner 引入了可扩展的数据流水线和 Tool-GRPO 强化学习算法,用于训练多模态模型处理长时程、多步骤的工具交互,使其能够根据任务上下文和中间结果自主选择、排序和调整工具使用。
- 该模型包含一种自适应学习机制,将工具使用逻辑与特定任务解耦,从而无需显式监督或预定义调用模式即可泛化到未见过的工具和新任务分布。
- 在具有挑战性的基准测试中评估,AdaReasoner 使 7B 基础模型平均提升 +24.9%,并在 VSP 和 Jigsaw 等任务中优于 GPT-5 和 Claude Sonnet 4 等专有系统,展示了开源多模态模型中强大的工具自适应推理能力。
引言
作者利用外部工具增强多模态大语言模型的视觉推理能力,认识到类人问题解决通常需要动态工具选择和多步骤协调。先前的方法要么依赖刚性的预定义工具调用模式,要么局限于单工具使用,无法适应未见过的工具或新任务。AdaReasoner 通过引入用于长时程工具交互的可扩展数据流水线、基于任务结果优化工具序列的强化学习算法(Tool-GRPO)以及将工具逻辑与特定任务解耦的自适应学习机制来解决这一问题。这使模型能够根据上下文和反馈自主选择、抑制和调节工具,实现最先进的性能——甚至超越 GPT-5 等专有模型——同时泛化到未见过的工具和任务。
数据集

作者使用了一个精心策划的高保真、工具增强推理轨迹数据集,涵盖三个任务:VSP、Jigsaw 和 GUIQA。每个轨迹遵循结构化、类人的问题解决蓝图,包含反思、回溯和工具失败案例以增强鲁棒性。
-
VSP(导航与验证):
- 来源:使用 Gymnasium 生成的程序化环境,训练网格尺寸为 4x4、6x6、8x8;测试网格为 5x5、7x7、9x9。
- 轨迹:使用 POINT 定位起点/终点/障碍物,文本推理,以及 DRAW2DPATH 进行路径验证。包含带自我修正的失败案例。
- 处理:工具调用程序化执行;CoT 通过 Gemini 2.5 Flash 生成。
-
Jigsaw:
- 来源:来自 COCO-2017 训练集的图像,分割为 3x3 网格;移除一块作为目标,其余五块中选一块作为干扰项。
- 轨迹:使用 DETECTBLACKAREA 定位缺失区域,然后迭代使用 INSERTIMAGE 尝试并结合视觉反馈。
- 变体:随机化块顺序、工具失败案例和无需工具即可解决的实例,以鼓励自适应工具使用。
-
GUIQA:
- 来源:从 44k Guichat 实例中筛选,使用 Qwen-VL-2.5-72B;保留 7,100 个模型失败的实例。
- 处理:人工检查后减少到 1,800 个有效案例;真实答案坐标渲染为边界框。
- 轨迹:使用 CROP 隔离相关区域,然后使用 OCR 提取。CoT 和工具序列通过 Gemini 2.5 Flash 生成;最终数据集:1,139 个验证实例。
所有轨迹通过两阶段流水线构建:(1)程序化工具执行以填充输入/输出,(2)LLM 生成 CoT 推理。最终数据集支持监督微调(TC 阶段),旨在教授不仅是工具使用,还包括步骤间的策略推理,包括工具失败时的回退行为。
方法
作者利用多阶段训练框架开发 AdaReasoner,这是一种能够有效进行工具增强推理的多模态大语言模型(MLLM)。整体架构围绕顺序决策过程设计,其中模型(表示为策略 πθ)生成推理轨迹 τ 来解决问题。该轨迹是一系列状态-动作-观察元组,其中状态 st 表示当前问题上下文,动作 at 是由特殊标记封装的工具调用,观察 ot 是工具执行的结果。策略根据新信息从状态 st 转换到 st+1。该框架基于一套多样化的视觉工具,分为感知类(如 POINT、OCR)、操作类(如 DRAWLINE、INSERTIMAGE)和计算类(如 AStar),并集成到推理过程中。训练过程包括两个主要阶段:冷启动阶段(TC)和强化学习阶段(TG)。
第一阶段,工具冷启动(TC),是一个监督微调(SFT)阶段。它始于使用 AdaDataCuration 模块生成高质量训练数据,该模块利用工具服务器执行工具调用并将结果整合到连贯对话中。该阶段使用来自 VSP、Jigsaw 和 WebQA 等任务的数据集。模型被训练生成遵循特定结构的多轮轨迹:以 мысл 标签包围的思考阶段,后接以 <tool_Call> 标签包围的工具调用或以 <response> 标签包围的最终响应。训练数据包括带有链式思维(CoT)占位符的抽象问题解决蓝图,由大语言模型填充以创建详细的推理步骤。模型学习正确格式化其输出并执行推理过程的初始步骤。
第二阶段,Tool-GRPO(TG),是一个强化学习阶段,用于优化模型规划和执行复杂多轮工具序列的能力。该阶段采用组相对策略优化(GRPO)算法。策略 πθ 为给定问题采样一组 N 个候选轨迹。每个轨迹由奖励函数评估,并通过将其奖励相对于组的均值和标准差归一化来计算组相对优势。然后使用包含 KL 散度惩罚的裁剪代理目标函数更新策略,以确保稳定更新。奖励函数设计为多维度,总奖励 Rtotal 是格式奖励、工具奖励和准确度奖励的组合。格式奖励作为二元门控,确保仅在输出符合所需结构语法时才授予工具使用和最终答案准确度奖励。工具奖励提供对工具调用过程的细粒度评估,采用从 0 到 4 的分层评分系统,基于调用结构、工具名称、参数名称和参数内容的正确性。准确度奖励仅在最终答案正确时授予。
为了增强模型的泛化能力,作者在 TC 和 TG 阶段引入了自适应学习策略。该策略在两个层面随机化工具定义。在标记层面,功能标识符如工具名称和参数名称被替换为随机字母数字字符串(例如,“GetWeather” 变为 “Func_X7a2”),迫使模型依赖语义描述而非标识符本身。在语义层面,工具和参数的描述由大语言模型改写,以创建多样化的表达方式,同时保持原始功能含义。这防止模型过拟合特定标识符或表达方式,并鼓励对工具文档变化的鲁棒性。评估表明,使用随机化定义训练的模型在泛化到新任务和新工具方面表现出显著改进,优于使用标准定义训练的模型。整体框架 AdaReasoner 是一个端到端系统,协调从数据整理到评估的整个模型生命周期,中央工具服务器管理所有可用工具。
实验
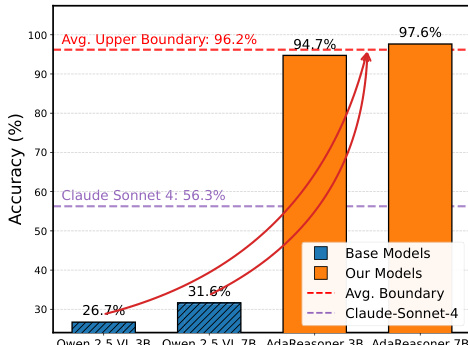
- 在 VSP、Jigsaw、GUIQA 和视觉搜索任务上使用 Qwen2.5-VL-3B/7B 进行评估;工具增强(TC + TG)使 7B 模型平均提升 +38.66%,VSP 从 ~31.64% 提升至 97.64%,超越直接 SFT(46.64%)和直接 GRPO(30.18%)。
- 在 VSP(97.64%)和 Jigsaw(96.60%)上达到最先进水平,超越 GPT-5(80.10%),缩小了 3B/7B 模型之间的差距——两者均达到 ~95%+ 准确率,显示工具克服了规模限制。
- AdaReasoner 学习自适应工具使用:采用 A* 进行导航(96.33% 分数),抑制无关工具(验证保持 99.20%),并调节调用频率(例如,Point 工具:导航时 3.2 次/样本,验证时 ~1.0 次)。
- 泛化到未见过的工具和任务:在 Jigsaw 上,以 3.54 CPS 达到 88.60% 准确率和 98.50% 成功率;在 VStar(无工具监督)上,调用工具 1.47 次/样本并得分 70.68%,在零样本工具适应下优于基线。
- 在结构化任务上优于专有模型(GPT-5、Claude、Gemini)和大型开源模型(Qwen-32B/72B);在 WebMMU 的代理动作子集上,纯 GRPO 达到 72.97%,显示 SFT 可能阻碍开放领域。
作者使用工具增强方法提升多模态模型在视觉推理任务上的性能,证明其方法在 VSP 基准测试上达到近乎完美的准确率(97.6%),显著超越基线模型,甚至优于 GPT-5 等更大的专有模型。结果表明,工具增强有效克服了基于规模的限制,使较小模型通过将瓶颈从内部推理转移到有效的工具规划,达到与更大模型相当的性能水平。
作者使用 Qwen2.5-VL-7B-Instruct 模型,冻结视觉塔并进行全量微调,训练 332,649 个样本,最大序列长度为 35,536,64 个预处理工作进程。模型训练 3 个周期,使用余弦学习率调度器,预热比例为 0.1,混合精度为 bfloat16,每设备批大小为 1,每 10 和 100 步分别记录日志和保存检查点,并在 90%/10% 的训练/验证分割上评估,验证批大小为 1。
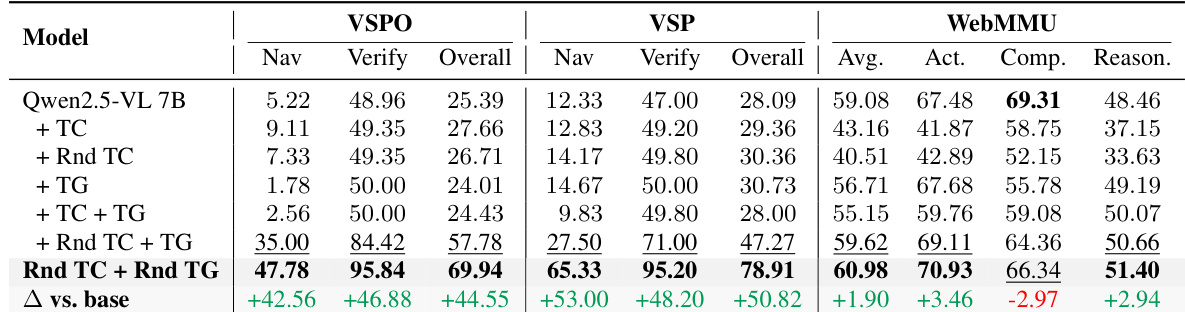
作者结合工具冷启动(TC)和工具-GRPO(TG)训练以提升模型在视觉推理任务上的性能。结果表明,Rnd TC + Rnd TG 方法在所有基准测试中均获得最高分数,相比基础模型有显著提升,特别是在 VSP 和 WebMMU 上,大幅超越其他配置。
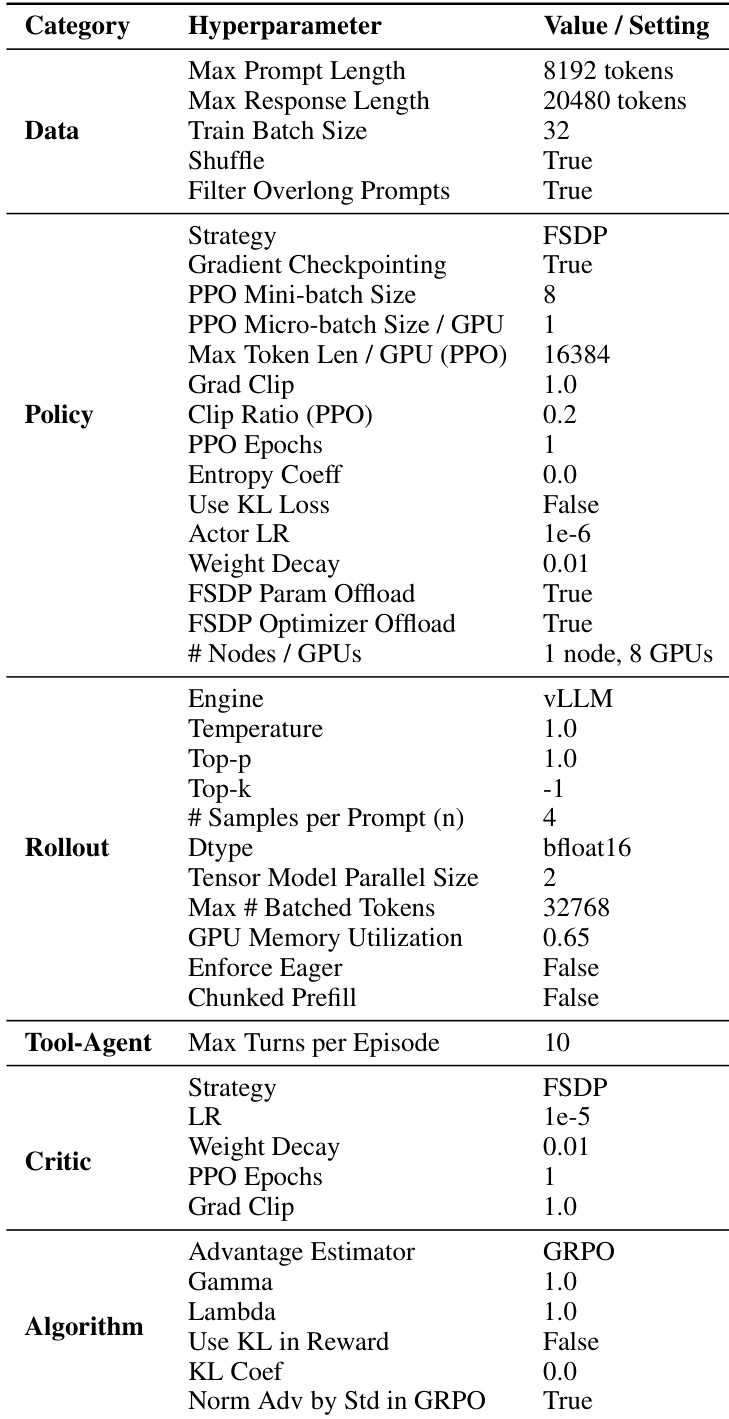
作者使用一套全面的超参数训练模型,关键设置包括最大提示长度 8192 个标记,训练批大小 32,每 GPU 的 PPO 微批大小 16384。训练采用 vLLM 引擎、FSDP 进行模型并行,以及 GRPO 优势估计器,为策略、rollout 和评论组件设置特定配置,以确保稳定高效的强化学习。
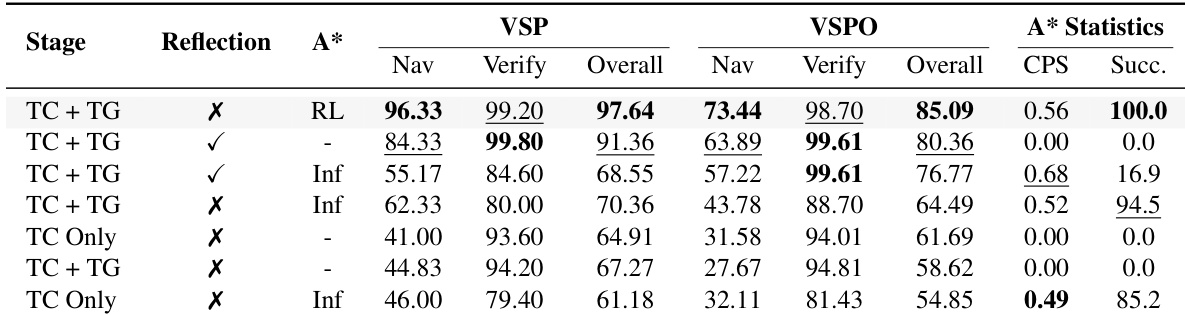
作者使用受控消融研究评估反思和工具可用性对 VSP 任务中自适应工具使用的影响。结果表明,训练期间启用反思显著提升导航和验证任务的性能,最佳结果在推理时结合反思和 A* 可用性,实现 99.80% 的验证准确率和 96.33% 的导航准确率。A* 工具的有效性高度依赖其上下文,若无反思则会导致不稳定行为和性能下降,突显稳定训练信号对可靠工具适应的重要性。