Command Palette
Search for a command to run...
daVinci-Dev:面向软件工程的Agent原生中段训练
daVinci-Dev:面向软件工程的Agent原生中段训练
摘要
近年来,大型语言模型(LLM)能力的前沿已从单轮代码生成转向代理式软件工程(agentic software engineering)——一种模型能够自主导航、编辑并测试复杂代码仓库的新范式。尽管后训练(post-training)方法已成为代码代理的主流实现路径,但代理式中训练(agentic mid-training)——即在大规模、贴近真实代理工作流的数据上进行中训练(mid-training, MT)——由于资源消耗巨大,仍处于严重未被充分探索的状态。然而,与依赖昂贵的强化学习相比,中训练为培养基础代理行为提供了更具可扩展性的潜在路径。实现高效代理式中训练的核心挑战在于:静态训练数据与真实开发环境中动态、反馈密集的交互环境之间存在显著分布偏差。为应对这一挑战,本文开展了一项系统性研究,提出了一套有效的代理中训练数据构建原则与训练方法论,旨在实现大规模代理能力的高效开发。我们方法的核心是引入代理原生数据(agent-native data),其监督信号由两类互补的轨迹构成:- 上下文原生轨迹(contextually-native trajectories):完整保留代理在实际运行中所经历的信息流,具有广泛的覆盖范围与多样性;- 环境原生轨迹(environmentally-native trajectories):从可执行代码仓库中采集,观测数据源自真实的工具调用与测试执行过程,从而提供深度的交互真实感。我们在 SWE-Bench Verified 基准上验证了模型的代理能力。实验表明,在使用相同基础模型与代理架构的前提下,相较于此前开源的软件工程中训练方案 Kimi-Dev,我们的方法在两种后训练设置下均展现出显著优势,且中训练阶段所消耗的 token 数量不足其一半(仅 731 亿)。除相对性能提升外,我们表现最佳的 32B 与 72B 模型分别取得了 56.1% 与 58.5% 的问题解决率,达到了当前同类方法中的领先水平。
一句话总结
来自SII、SJTU和GAIR的研究人员提出了一种基于“代理原生数据”的代理式中期训练方法——结合上下文原生轨迹与环境原生轨迹——以克服LLM软件代理中的分布不匹配问题,在更少的token下超越KIMI-DEV,并在SWE-Bench Verified上达到SOTA,同时提升通用代码与科学基准表现。
主要贡献
- 我们引入“代理原生数据”用于代理式中期训练,结合覆盖广泛的上下文原生轨迹与来自可执行仓库的真实交互环境原生轨迹,解决静态数据与动态开发工作流之间的分布不匹配问题。
- 我们的方法在SWE-Bench Verified上达到56.1%(32B)和58.5%(72B)的SOTA解决率,仅使用不到一半的中期训练token(73.1B),优于KIMI-DEV等先前开源方案,且从非编码器Qwen2.5-Base模型启动。
- 除代理任务外,我们的模型在通用代码生成与科学基准测试中表现更优,我们计划开源数据集、训练方案与检查点,以推动可扩展代理式LLM训练的广泛研究。
引言
作者利用代理式中期训练,应对LLM在复杂代码库中自主导航、编辑和验证代码的日益增长需求——从单一功能生成转向真实世界软件工程。先前工作主要依赖有限且人工筛选的轨迹进行后训练,存在数据稀缺、缺乏动态反馈、无法早期建立基础代理推理能力等问题。现有中期训练数据也未能反映实际开发中迭代式、工具驱动的工作流,导致静态训练样本与实时代理行为之间存在分布不匹配。他们的主要贡献是一种系统的代理原生中期训练框架,结合两种轨迹类型:上下文原生数据(68.6B token)重构PR中的开发者决策流,以及环境原生数据(3.1B token)来自真实测试执行。该方法在SWE-Bench Verified上达到56.1%和58.5%的解决率(分别对应32B和72B模型)——超越KIMI-DEV等先前开源方案,且使用不到一半训练token——并在代码与科学基准测试中提升泛化能力。
数据集

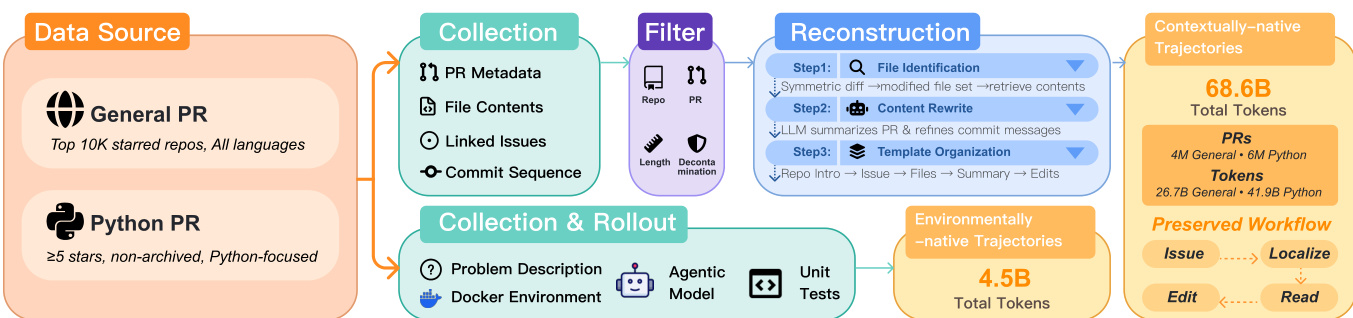
作者构建代理原生数据,弥合静态训练数据与交互式部署之间的差距,采用两种互补轨迹类型:上下文原生(来自GitHub PR)和环境原生(来自真实环境中的代理运行)。
-
数据集组成与来源
- 上下文原生轨迹来自GitHub Pull Requests,保留完整开发工作流,包括问题描述、文件内容与修改。
- 环境原生轨迹通过在Docker化环境中运行代理(GLM-4.6)生成,捕捉测试反馈与迭代编辑。
-
各子集关键细节
- 上下文原生(D^ctx):
- 两个子集:
- D_gen^ctx(26.7B token):来自所有语言中星标数最高的10,000个仓库;包含类XML标签、评审和开发者评论。
- D_py^ctx(41.9B token):聚焦Python,来自740K个星标≥5的仓库;使用Markdown + 搜索替换编辑;每PR过滤为1–5个Python文件。
- 两子集均排除机器人PR、仅保留已合并PR,并对SWE-Bench Verified仓库去污染。
- 使用LLM(Qwen3-235B)增强PR摘要与提交信息清晰度。
- 长度上限32K token;保留>90%的Python PR。
- 两个子集:
- 环境原生(D^env):
- 两个子集基于测试结果:
- D_pass^env(0.7B token,18.5K轨迹):所有测试通过。
- D_fail^env(2.4B token,55.5K轨迹):测试失败;提供调试信号。
- 通过SWE-AGENT在Docker环境中生成;训练期间上采样3倍。
- 轨迹上限128K token;总计3.1B token(约4.5B有效token)。
- 两个子集基于测试结果:
- 上下文原生(D^ctx):
-
数据使用方式
- 中期训练(MT)分阶段:先在D_gen^ctx上训练,再在D_py^ctx(或D_py^ctx + D_env)上训练。
- 对于监督微调(SFT),作者使用D_pass^env或D^SWE-smith(0.11B token),训练5个epoch。
- D^ctx + D^env合计73.1B token;按顺序使用,先建立广泛知识,再专业化。
-
处理与元数据
- 上下文样本结构化以模拟代理工作流:定位(文件路径)、读取(文件内容)、编辑(diff或搜索替换)、推理(LLM摘要)。
- 环境原生数据记录完整动作-观测序列:编辑、测试运行、错误、工具输出。
- 去污染:移除SWE-Bench Verified PR;通过13-gram重叠检查HumanEval/EvalPlus。
- 格式差异:通用子集使用含评审的XML;Python子集使用含搜索替换编辑与LLM生成推理头的Markdown。
方法
作者采用多阶段训练框架,旨在开发能通过与代码库迭代交互执行复杂软件工程任务的代理。整体架构围绕两个主要数据流构建:上下文原生轨迹与环境原生轨迹,通过不同训练阶段处理以构建代理能力。上下文原生轨迹源自真实Pull Requests(PR),并丰富了问题描述、提交信息和代码变更等元数据,形成一个捕捉软件开发自然工作流的多样化数据集。这些轨迹用于训练代理理解并生成上下文适当的动作。环境原生轨迹则源自真实执行环境,代理在Docker环境中执行定位、编辑、测试与修订等任务。该数据流确保代理从真实的反馈循环中学习,包括测试结果与编译器错误,这对精炼其行为至关重要。这两种数据流的整合使模型能够同时发展上下文感知与实践执行能力。
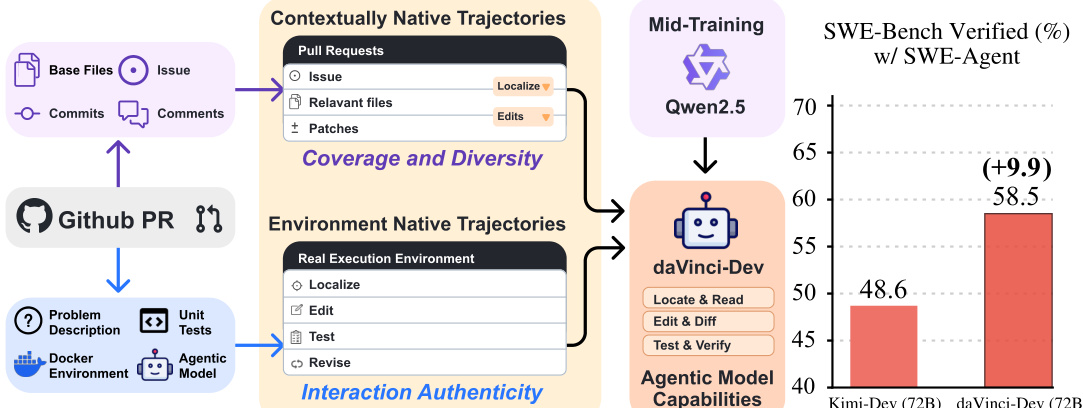
训练过程始于两个主要数据源的数据收集:来自所有语言中前10K星标仓库的通用PR,以及至少5星且非归档状态的Python PR。数据通过包含收集、过滤与重构的管道处理。收集阶段提取PR描述、文件内容和关联问题等元数据。过滤阶段移除低质量或冗余数据,重构阶段包括文件识别、内容重写和模板组织,以生成结构化高质量训练样本。重构后的数据用于创建上下文原生轨迹,再通过整合真实执行反馈精炼为环境原生轨迹。这确保代理不仅从静态代码片段学习,也从动态真实世界交互中学习。

模型架构设计支持静态代码语料库与分解子任务训练。在静态代码语料库方法中,使用孤立代码片段教模型代码外观,但不教其导航或修改方式。这与分解子任务训练形成对比,后者分别训练定位与编辑任务。定位阶段根据问题预测相关文件,编辑阶段在已识别文件基础上生成补丁。这种分解允许模型学习定位与编辑间的依赖关系,但假设完美文件检索,且推理时缺乏执行或测试反馈。上下文原生方法将定位与编辑统一为单一样本,在推理时可用的精确上下文中训练模型。该方法捕捉真实工具调用与真实输出,确保测试反馈驱动迭代精炼,使训练更真实有效。
实验
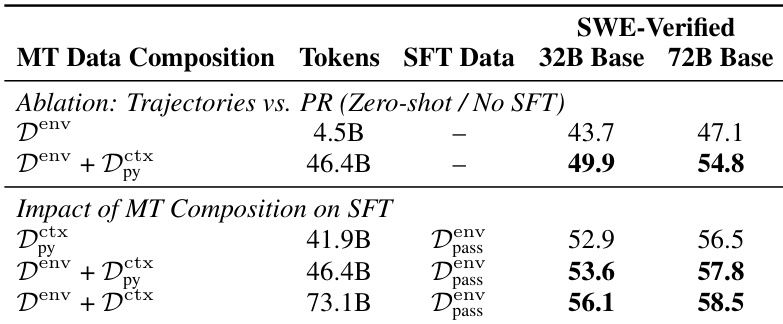
- 代理原生中期训练在各种SFT方案中提升性能:72B模型中,仅使用上下文数据(D^ctx)弱SFT从38.0%提升至46.4%,以一半token达到Kimi-Dev水平;强SFT达58.2%,超越RL调优的Kimi-Dev;加入环境数据(D^env)后提升至58.5%。
- 效果扩展至32B:D^ctx使弱SFT提升4.7%,强SFT提升1.1%;D^ctx + D^env达56.1%,比强SFT基线高3.1%。
- daVinci-Dev-72B(58.5%)和daVinci-Dev-32B(56.1%)在SWE-Bench Verified上超越开源基线,包括在32B规模下达到SOTA,尽管从非编码器基础模型启动。
- 泛化至SWE之外:提升HumanEval、EvalPlus、GPQA与SciBench,表明代理训练通过决策模式迁移至代码生成与科学推理。
- 令牌高效:68.6B token(D^ctx)+ 4.5B有效token(D^env)超越Kimi-Dev的150B-token方案,得益于更贴近测试分布与真实轨迹。
- 上下文数据放大轨迹学习:72B零样本性能在轨迹中加入PR上下文后提升+7.7%;中期训练轨迹也使最终SFT性能提升1.3%。
- 可预测扩展:性能随训练步数呈对数线性增长(R²≈0.90),无饱和迹象;72B在D^ctx + D^env上达54.9%,32B达49.9%。
- 数据可扩展性:Python PR子集来自1.3e7个PR;潜力扩展至1e9个仓库中的3e8个PR;自动化管道提供更深入、可验证的监督。
作者使用结合上下文原生与环境原生数据的中期训练方法提升SWE-Bench Verified表现,72B模型达58.5%,32B模型达56.1%,超越先前开源方法。结果表明该方法在不同模型规模与SFT方案中均有效,最强表现来自大规模上下文原生数据基础。
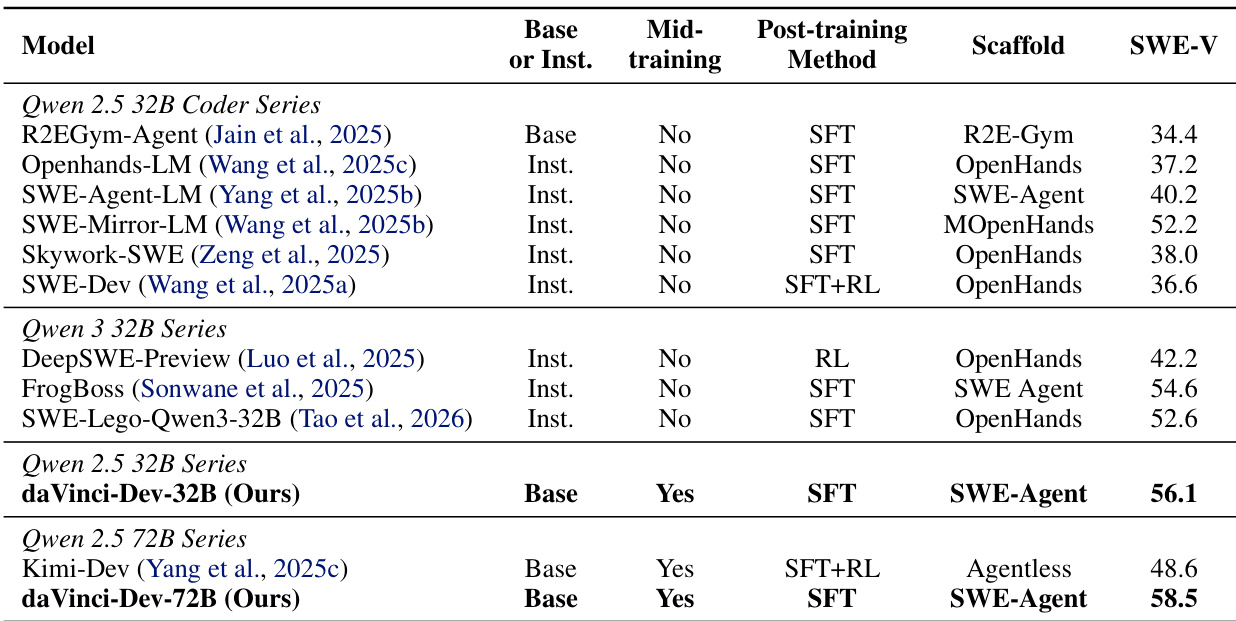
作者使用结合上下文原生与环境原生数据的中期训练方法提升SWE-Bench Verified表现,72B模型达58.5%,32B模型达56.1%,超越先前方法。结果表明,结合这些数据类型可增强泛化能力并实现高效、可扩展学习,最强表现来自大规模上下文原生监督。
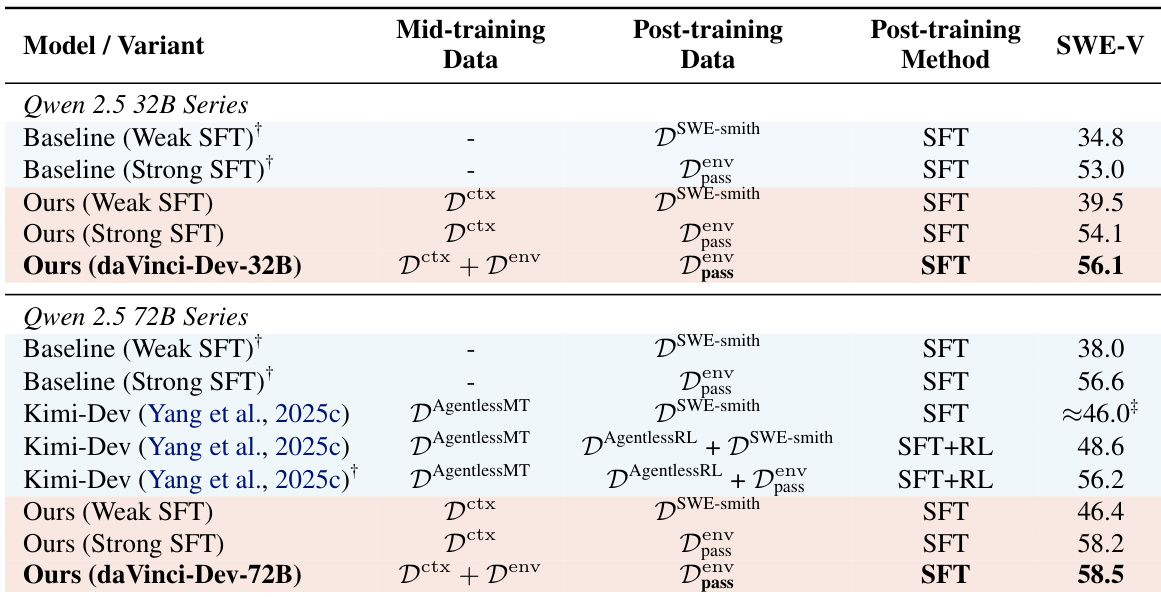
结果表明,在中期训练中结合上下文原生与环境原生数据可提升SWE-Bench Verified表现,完整组合在72B模型上达58.5%,32B模型上达56.1%。作者发现上下文原生数据对轨迹基础至关重要,且即使后续进行微调,中期训练中包含轨迹也能提升性能。
作者使用结合上下文原生与环境原生数据的中期训练(MT)方法提升模型在科学与代码基准上的表现。结果表明,他们的MT Mix方法显著提升所有评估任务的表现,HumanEval上提升高达+23.26%,GPQA-Main上提升+12.46%,表明其泛化能力超越软件工程领域。
