Command Palette
Search for a command to run...
掩码深度建模用于空间感知
掩码深度建模用于空间感知
摘要
空间视觉感知是自动驾驶与机器人操作等现实世界应用中的基本需求,其核心在于与三维环境进行有效交互。使用RGB-D相机获取像素对齐的度量深度信息,是实现这一目标最具前景的途径。然而,该方法通常受限于硬件性能以及复杂成像条件,尤其在面对镜面反射或无纹理表面时,难以获得准确的深度数据。本文提出,深度传感器产生的误差可被视为一种“掩码”信号,其本质反映了底层几何结构的模糊性。基于这一认识,我们提出了LingBot-Depth——一种深度补全模型,该模型通过掩码深度建模机制,利用视觉上下文信息对深度图进行精细化重构,并引入自动化数据清洗与整理流程,以支持大规模训练。令人鼓舞的是,实验结果表明,LingBot-Depth在深度精度与像素覆盖范围方面均优于当前顶级的RGB-D相机。在一系列下游任务中的测试进一步验证了该模型能够实现RGB与深度模态之间对齐的潜在表征。为推动空间感知领域的发展,我们已向社区开源代码、预训练模型权重,以及包含200万真实数据与100万仿真数据的300万组RGB-深度图像对。
一句话总结
Robbyant 研究人员提出 LingBot-Depth,这是一种基于 Vision Transformer 的模型,采用“掩码深度建模”(Masked Depth Modeling)方法,将 RGB-D 相机的传感器故障视为自然掩码,通过联合 RGB-深度上下文实现鲁棒的深度补全;该模型在 300 万精心构建的训练对上训练,性能超越顶级 RGB-D 相机,并提升机器人抓取与 3D 跟踪能力。
主要贡献
- LingBot-Depth 引入“掩码深度建模”(MDM),将 RGB-D 相机传感器故障视为自然掩码以引导深度重建,利用 RGB 上下文推断因几何或外观模糊(如镜面反射表面)导致的缺失深度值。
- 该模型在 300 万 RGB-深度对(200 万真实数据 + 100 万合成数据)上训练,实现最先进的深度精度与像素覆盖率,超越商用 RGB-D 传感器,并通过 Transformer 架构中的自适应掩码实现统一的单目深度估计与深度补全。
- 在下游任务中评估,LingBot-Depth 替代 SpatialTrackerV2 中的 VGGT 提升 3D 跟踪性能,并实现对透明或反射等挑战性物体的鲁棒灵巧抓取,展示零样本泛化至视频与无需 CAD 模型的实际机器人部署能力。
引言
作者利用 RGB-D 传感器固有的缺陷(如因镜面或无纹理区域导致的深度缺失值),不将其视为需丢弃的噪声,而是作为编码几何模糊性的自然掩码。先前的深度补全方法常依赖随机掩码或缺乏可扩展的真实世界训练数据,限制了其在真实成像条件下的泛化能力。其主要贡献是“掩码深度建模”(MDM),一种自监督框架,训练 Vision Transformer 通过融合完整 RGB 上下文与稀疏有效深度标记重建缺失深度,使用来自合成与真实世界源的 300 万 RGB-深度对构建数据集。最终的 LingBot-Depth 模型在深度精度与覆盖率上超越商用传感器,并支持无需 CAD 模型或完美仿真的鲁棒下游应用,如 3D 跟踪与灵巧机器人抓取。
数据集

-
作者使用自定义构建的 RGB-D 数据集,结合合成与真实世界数据训练掩码深度模型,解决现有数据集中自然不完整深度图稀缺的问题。
-
合成数据(LingBot-Depth-S)使用 Blender 生成,模拟真实主动式深度相机:442 个室内场景生成 1000 万样本,每个样本包含 RGB、完美深度、带散斑图案的立体图像对、真值视差及通过 SGM 计算的传感器深度。相机参数(基线 0.05–0.2 米,焦距 16–28 毫米)随机化以增加多样性。传感器深度从 720×960 上采样至 960×1280。
-
真实世界数据(LingBot-Depth-R)来自一套可扩展采集系统,多个商用 RGB-D 相机安装在定制 3D 打印支架上,由便携式 PC 通过厂商 SDK 管理数据流。200 万次采集覆盖多样室内场景(住宅、商业、公共、专业),伪深度通过立体红外图像对的左右一致性检查计算。
-
作者将其 320 万自建数据补充以 7 个开源 RGB-D 数据集(总计 1000 万训练样本)。对于无缺失深度的合成开源数据,应用基于块的随机掩码(60–90% 掩码率)。对于深度基本完整的开源真实数据,也使用随机掩码。
-
训练期间,所有深度图(合成、真实或开源)均添加高斯噪声并进行掩码。原始深度图作为重建目标,有效像素掩码排除缺失测量值。最终训练混合包含 320 万自建 + 680 万开源样本,确保场景与深度变化广泛。
方法
作者基于 Vision Transformer(ViT)编码器-解码器架构构建掩码深度建模框架,专为从 RGB-D 输入预测深度图设计。整体框架通过一系列结构化模块联合处理 RGB 与深度模态,实现有效的跨模态学习。请参考框架图 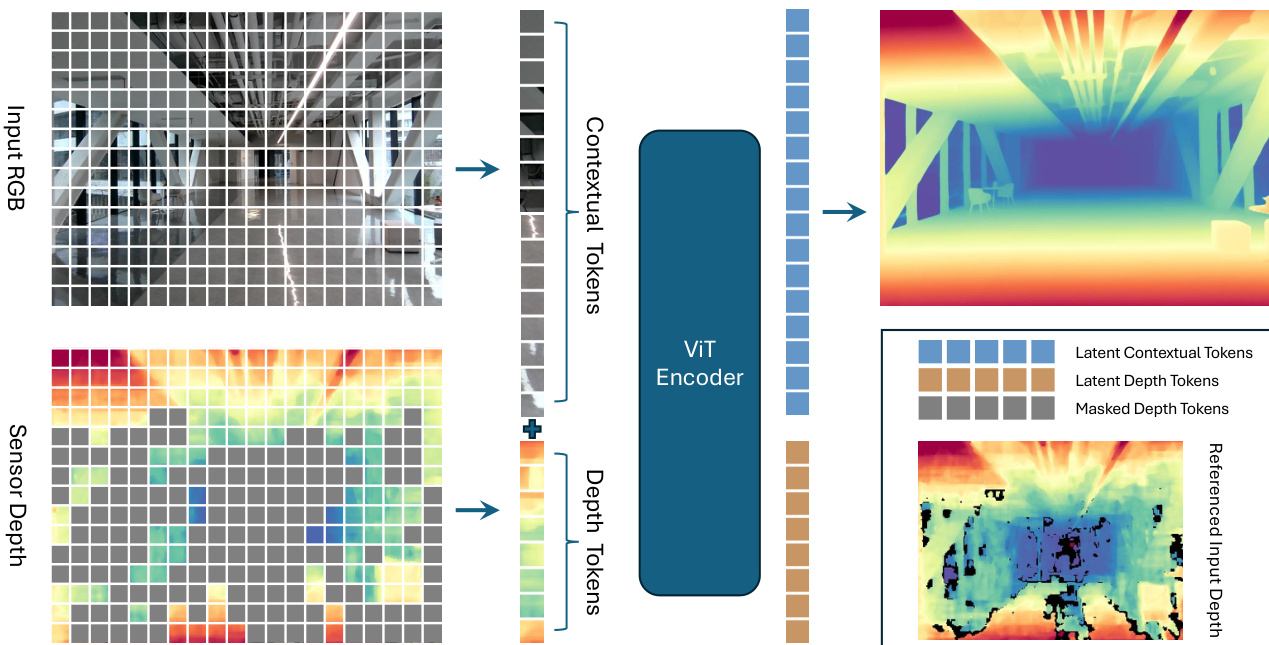 理解高层流程。
理解高层流程。
流程始于 RGB 与深度输入的独立分块嵌入层。每种模态独立投影为分块标记序列,RGB 图像作为 3 通道输入处理,深度图作为单通道输入。这些嵌入在 2D 网格上空间对齐,确保每个标记对应两种模态中的相同空间位置。分块大小设为 14,与 DINOv2 一致,得到每模态 N=HW/142 个标记,其中 H 和 W 为输入空间维度。第 i 个 RGB 标记记为 ci∈Rn,第 i 个深度标记记为 di∈Rn,其中 n 为嵌入维度。
为编码位置信息,引入两种嵌入:共享的可学习 2D 空间位置嵌入,捕获每个标记在图像平面上的位置;模态特定嵌入,区分相同空间位置的 RGB 与深度标记。RGB 标记的模态嵌入设为 1,深度标记设为 2。每个标记的最终位置编码是其空间嵌入与模态嵌入之和,在输入注意力块前加入标记。
模型采用基于 RGB-D 数据中自然缺失深度测量的掩码策略。深度块若完全缺失值则始终被掩码,若混合有效与无效值则以更高概率(如 0.75)掩码。若掩码标记总数未达目标比例,则随机采样额外完全有效的深度标记完成掩码集。此策略确保信息性深度标记保持未掩码,实现与上下文 RGB 标记的有效交互。深度图整体掩码比例范围为 60% 至 90%。
掩码后,未掩码深度标记与所有 RGB 标记连接,作为 ViT-Large 编码器输入。保留 [cls] 标记以捕获跨模态全局上下文。编码器包含 24 个自注意力块,仅保留最终层输出标记用于后续处理。与传统方法聚合多中间层特征不同,此设计通过聚焦最终编码器输出简化架构。
深度重建采用改编自 MoGe 的 ConvStack 解码器,相比标准 MAE 中的浅层 Transformer 解码器,更适用于密集几何预测。编码后,丢弃潜在深度标记,保留潜在上下文标记。[cls] 标记广播并与每个上下文标记逐元素相加,注入全局场景上下文。这些增强标记作为输入查询送入分层卷积解码器。
解码器采用金字塔结构,共享卷积瓶颈与多个任务专用头。瓶颈通过堆叠残差块与转置卷积逐步上采样特征,每阶段空间分辨率翻倍,直至 (16h,16w)。每尺度注入源自图像坐标圆形映射的 UV 位置编码,保留空间布局与宽高比。生成的多尺度特征金字塔在所有任务头间共享,实现高效特征重用。最终深度预测通过双线性上采样匹配原始输入分辨率。
训练使用 24 层 ViT-Large 编码器,初始化自 DINOv2 预训练检查点,解码器随机初始化。采用差异化学习率策略,编码器主干优化率为 1×10−5,解码器为 1×10−4。优化器为 AdamW,动量参数 β1=0.9,β2=0.999,权重衰减 0.05。复合学习率调度包括编码器线性预热 2000 次迭代,以及每 25000 次迭代对两学习率进行步进衰减。训练运行 250000 次迭代,全局批大小 1024,使用 128 个 GPU,每 GPU 批大小 8。数据增强包括随机缩放裁剪、水平翻转及合成退化(如颜色抖动、JPEG 压缩、运动模糊、散粒噪声)。应用梯度裁剪(最大范数 1.0)与 BF16 混合精度训练。预测深度图使用有效真值深度像素上的 L1 损失监督。
实验
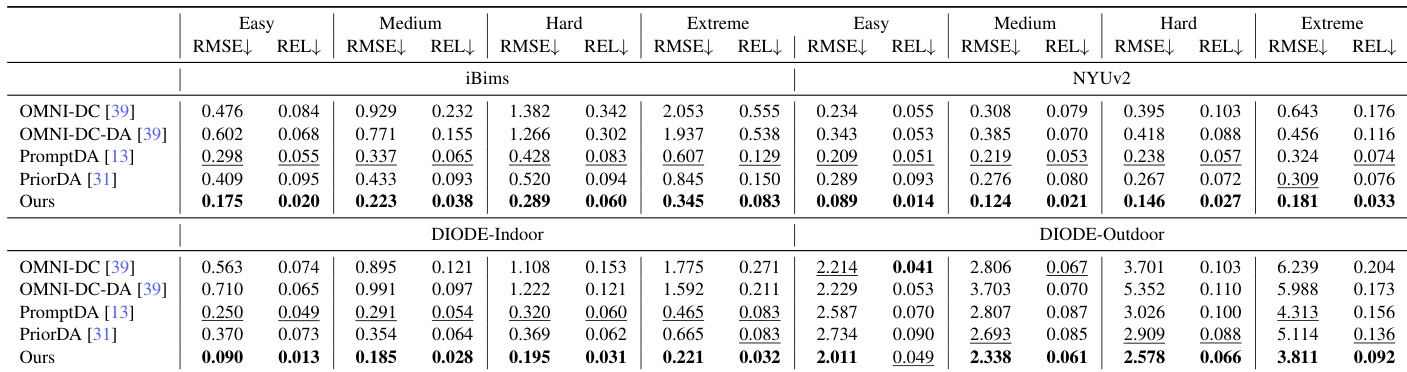
- 通过在 iBims、NYUv2 和 DIODE 上的块状掩码深度补全验证 MDM 预训练:在极端设置下,LingBot-Depth 相比 PromptDA RMSE 降低 >40%,在 ETH-SfM 稀疏 SfM 输入下室内降低 47%、室外降低 38%。
- 在单目深度估计中,以 LingBot-Depth 初始化的 MoGe 在 10 个基准(NYUv2、KITTI、DIODE 等)上优于基于 DINOv2 的模型,展示从 RGB 单独推断更强空间推理能力。
- 在 FoundationStereo 中,MDM 预训练加速收敛(如第 5 轮 HAMMER EPE 0.27 对比 0.46),提升最终性能(如第 15 轮 HAMMER EPE 0.17),并在稳定性与精度上优于基于 DepthAnythingV2 的变体。
- 应用于视频深度补全,LingBot-Depth 在透明/反射表面(玻璃、镜子、水族箱)填充大块缺失区域并保持时间一致性,在挑战性真实序列中超越 ZED 立体深度。
- 通过 SpatialTrackerV2 实现鲁棒在线 3D 点跟踪:优化深度减少相机漂移,支持玻璃丰富环境中动态物体的连贯运动跟踪。
- 提升机器人灵巧抓取:在 4 个挑战性物体(含透明储物箱)上,LingBot-Depth 实现 50% 成功率,而原始深度完全失败,证明对真实操作至关重要。
结果表明,该方法在 iBims、NYUv2 和 DIODE 上所有难度级别下,均一致优于所有基线方法,实现室内与室外设置下的最低 RMSE 值。模型对结构不完整与测量噪声表现出强鲁棒性,尤其在极端条件下显著优于最佳竞争对手。
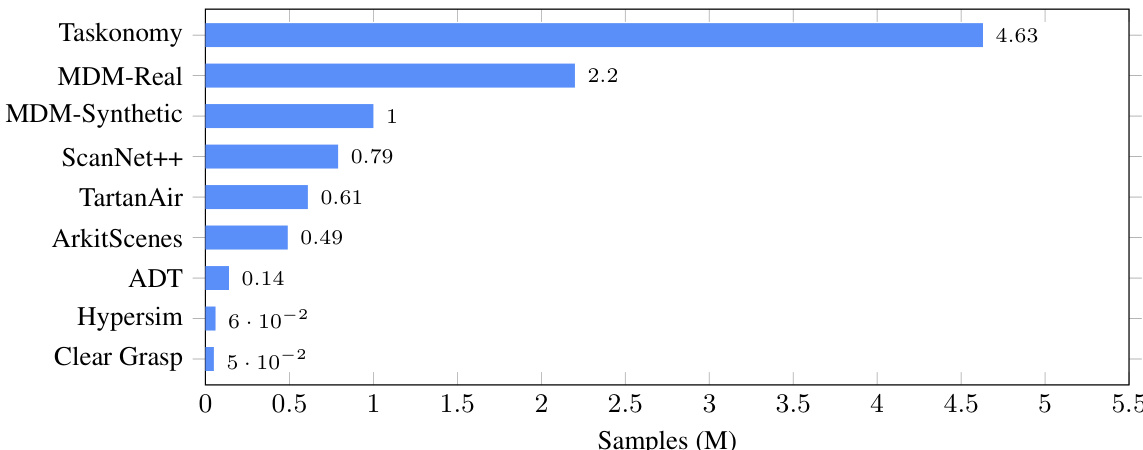
作者使用条形图比较不同方法训练所需样本数量(单位:百万),Taskonomy 需要最多(4.63 百万),Clear Grasp 需要最少(5 × 10⁻² 百万)。结果表明 MDM-Real 需要 2.2 百万样本,显著少于 Taskonomy 但多于所列其他方法,表明数据效率与性能间存在权衡。
结果表明,该方法在室内与室外数据集所有难度级别下,均一致优于所有基线方法。在室内基准中,极端设置下 RMSE 比最佳竞争对手降低超 40%;在室外数据集中,所有级别均实现最低误差,展示对结构不完整与测量噪声的强鲁棒性。
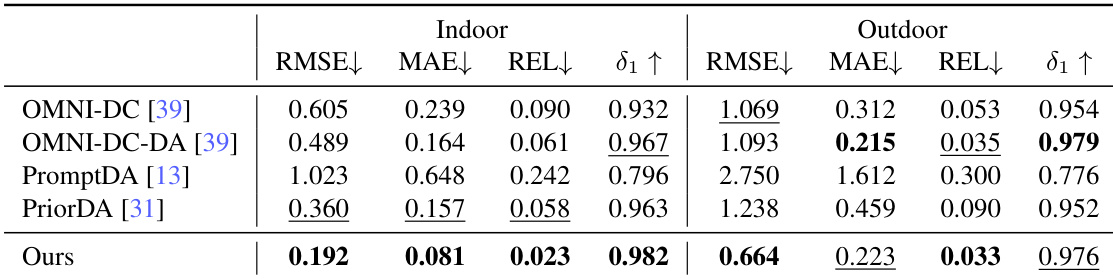
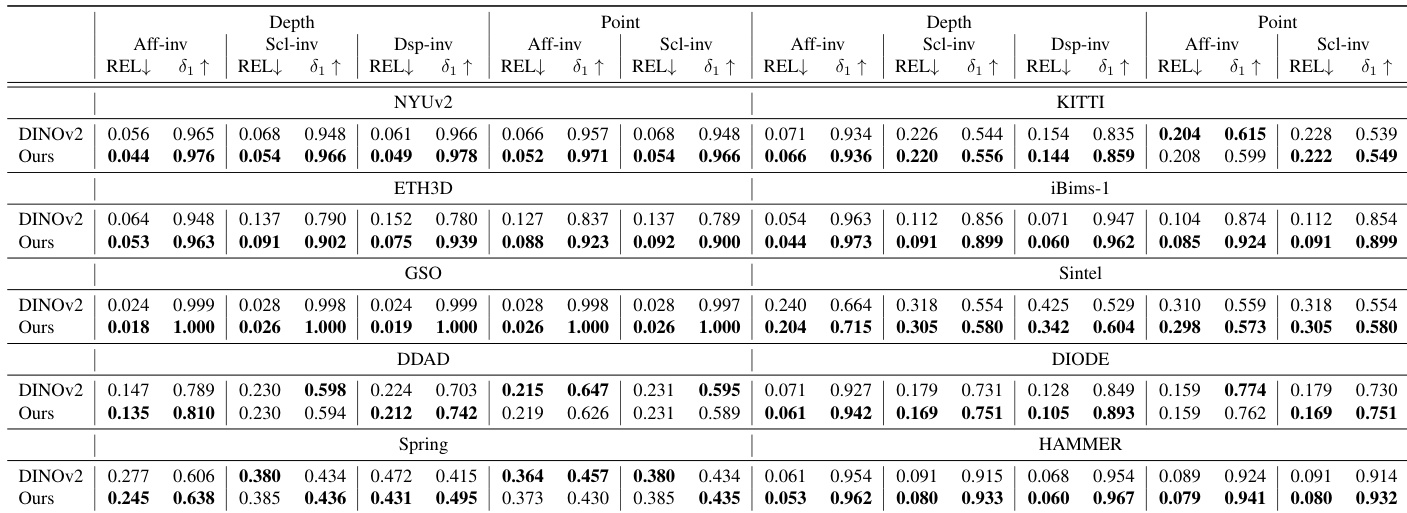
作者使用经 MDM 预训练的 LingBot-Depth 模型,在多个基准上评估单目深度估计,与 DINOv2 作为骨干网络比较。结果表明,以 LingBot-Depth 初始化的模型在所有数据集上均实现一致且显著改进,展示更强泛化能力与增强的空间理解。
作者使用 LingBot-Depth 与原始传感器深度评估四个挑战性物体(含透明与反射物体)的抓取成功率。结果表明,LingBot-Depth 持续提升成功率,在透明储物箱上实现 50% 成功率,而原始深度完全失败。
