Command Palette
Search for a command to run...
脚本即一切:一种面向长时程对话到影视视频生成的智能体框架
脚本即一切:一种面向长时程对话到影视视频生成的智能体框架
摘要
近年来,视频生成技术取得了显著进展,涌现出能够仅凭简单文本提示便合成令人惊叹视觉内容的模型。然而,这些模型在从高层次概念(如对话)生成长篇且连贯的叙事时仍面临挑战,暴露出创意构想与电影化实现之间的“语义鸿沟”。为弥合这一鸿沟,我们提出一种全新的端到端智能体框架,用于实现从对话到电影级视频的生成。该框架的核心是ScripterAgent,一种经过训练的模型,可将粗略的对话内容转化为精细、可执行的电影剧本。为支持这一能力,我们构建了ScriptBench——一个具有丰富多模态上下文的新一代大规模基准数据集,并通过专家指导的标注流程完成标注。生成的剧本随后由DirectorAgent调度,该智能体采用跨场景连续生成策略,协调当前最先进的视频生成模型,以确保长时程内容的连贯性。我们的综合评估引入了由AI驱动的CriticAgent,并提出了一种新的视觉-剧本对齐(Visual-Script Alignment, VSA)度量指标,结果表明,该框架在所有测试视频模型上均显著提升了剧本忠实度与时间一致性。此外,我们的分析揭示了当前最先进模型在视觉震撼力与严格遵循剧本之间存在关键权衡,为自动化电影制作的未来发展提供了重要洞见。
一句话总结
腾讯混元与西安电子科技大学的研究人员提出了 ScriptAgent,这是一个通过 ScripterAgent(在 ScriptBench 上训练)、DirectorAgent(确保时间连贯性)和 CriticAgent(用于评估)弥合对话到视频生成语义鸿沟的智能体框架——在提升当前最优模型保真度的同时,揭示了自动化电影叙事中的关键权衡。
主要贡献
- 我们提出了一种端到端的智能体框架,通过将任务分解为剧本生成(ScripterAgent)、视频编排(DirectorAgent)和评估(CriticAgent),弥合稀疏对话与电影视频之间的语义鸿沟,从而实现连贯的长篇叙事合成。
- 我们构建了 ScriptBench,一个通过专家指导流程标注的大规模多模态基准,并使用两阶段监督微调(SFT)和 GRPO 方法训练 ScripterAgent,以生成可执行的电影剧本,解决对话歧义并编码特定领域的电影制作知识。
- 我们在当前最优视频模型上的评估揭示了视觉质量与剧本遵循度之间的权衡,并通过新颖的视觉-剧本对齐(VSA)指标证明了在剧本忠实度和时间连贯性上的持续改进,忠实度最高提升 +0.4,VSA 最高提升 +7。
引言
作者利用近期视频生成技术的进展,应对从稀疏对话生成长篇连贯电影内容的挑战——当前模型因高层叙事与可执行视觉规划之间的语义鸿沟而失败。先前系统在时间连贯性方面表现不佳,缺乏自动化电影推理能力,且需要大量人工输入,限制了其在叙事创作中的应用。其主要贡献是一个端到端智能体框架,包括 ScripterAgent(使用新颖的两阶段训练方法将对话转化为详细电影剧本)、DirectorAgent(通过跨场景连续生成策略协调视频模型以实现长时程连贯性)和 CriticAgent(用于评估)。他们还引入了 ScriptBench 大规模多模态基准和新的视觉-剧本对齐指标,以量化时间保真度——表明该方法在主流视频模型上提升了剧本忠实度和连贯性,同时揭示了视觉质量与叙事遵循度之间的关键权衡。
数据集

-
作者使用一个自建数据集 ScriptBench,包含 1,750 个高保真电影剧本实例,源自电影过场动画的原始多模态输入(视频 + 音频),筛选标准为丰富的对话、专业电影摄影和视觉一致性。
-
每个实例对应平均 15.4 秒的视频片段,支持多镜头序列,同时保持在生成模型的容量范围内。数据集分为 1,700 个训练实例和 50 个测试实例,测试集设计用于挑战模型仅从对话推断完整电影元素的能力——模拟真实导演工作流程。
-
剧本通过一个三阶段的大型语言模型驱动流程(使用 Gemini 2.5 Pro)生成,严格受专家模板和验证规则约束:
- 上下文重建与对话融合 —— 整合音频和文本推断角色、场景、情绪和意图。
- 镜头级语义规划 —— 将场景分割为自包含的、≤10 秒的镜头,受叙事、技术和连续性约束指导。
- 多轮自适应错误修正 —— 通过四个模块迭代验证剧本:对话完整性、角色外观一致性、场景连贯性和位置/物理合理性。
-
生成后,60% 的实例经过专家审核,发现细微错误(如角色瞬移、道具不一致),这些反馈被用于优化提示和验证逻辑。最终剧本结构清晰、内部一致,并基于长时程叙事和物理连续性。
方法
作者采用三智能体框架解决长时程对话到电影视频生成的挑战,其中 ScripterAgent 作为基础组件,负责将原始对话转化为结构化的镜头级电影剧本。该过程始于两阶段训练范式。第一阶段为监督微调(SFT),模型通过将多轮对话输入映射到结构化 JSON 格式的剧本目标,学习电影剧本的结构语法。基础模型 Qwen-Omni-7B 经微调以最大化真实剧本的条件对数似然,确保输出结构正确且内容完整。该 SFT 阶段为叙事连贯性奠定坚实基础。
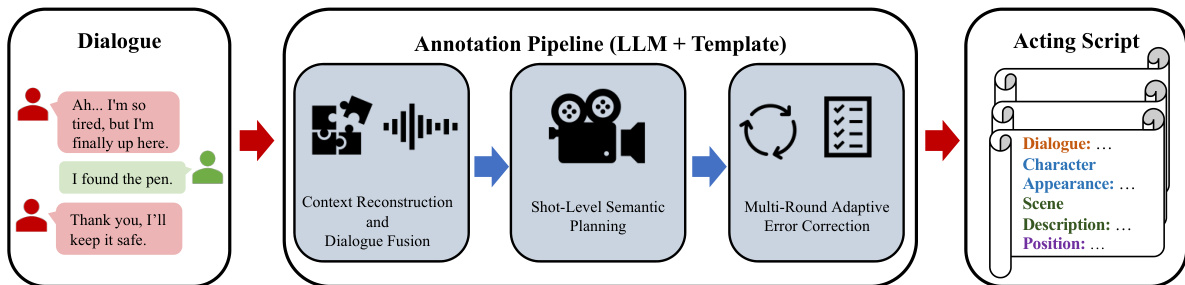
如图所示,ScripterAgent 接收对话作为输入,输出详细表演剧本,包括对话、角色外观、场景描述和位置等结构化字段。该剧本作为后续视频生成过程的蓝图。

第二阶段采用强化学习(RL),使模型输出与专业导演美学对齐,超越结构正确性,捕捉镜头构图、节奏和情感影响等主观品质。作者使用组相对策略优化(GRPO)训练 ScripterAgent,该方法适用于具有主观性、一对多有效输出的创造性任务。关键创新是混合奖励函数 Rtotal,平衡客观正确性与主观质量。该函数是基于规则的结构奖励 Rstructure(通过自动化检查评估技术正确性)和人类偏好奖励 Rhuman(通过基于 BERT 的回归模型建模专家人类判断捕捉电影美学)的加权和。优化过程中,策略通过最大化优势加权对数似然更新,受 KL 散度惩罚约束,防止偏离 SFT 初始化。
DirectorAgent 解决将生成剧本转化为连续视频序列的挑战,克服当前最优视频生成模型有限的时间容量。其主要功能是确保多个生成片段之间的语义连贯性和视觉一致性。DirectorAgent 的核心是跨场景连续生成策略,结合智能镜头感知分割与帧锚定机制。智能镜头分割将剧本划分为符合自然电影边界的场景,遵循镜头完整性、时长适配、语义连贯性和技术可行性原则。为确保场景间无缝视觉过渡,DirectorAgent 采用首尾帧连接机制。如图所示,生成场景的最后一帧用作后续场景第一帧生成的视觉锚点或条件图像。该帧锚定策略在多个生成周期中保持角色外观、服装和场景布局的视觉一致性,实现无缝视觉衔接。

该方法通过将长时程生成问题转化为一系列局部可解、保持连续性的子问题,有效扩展了任何底层视频模型的连贯性窗口。尽管该策略显著减少身份漂移和布局不一致,但唇形同步不完美和细粒度动作残留错位等问题仍存在。
实验
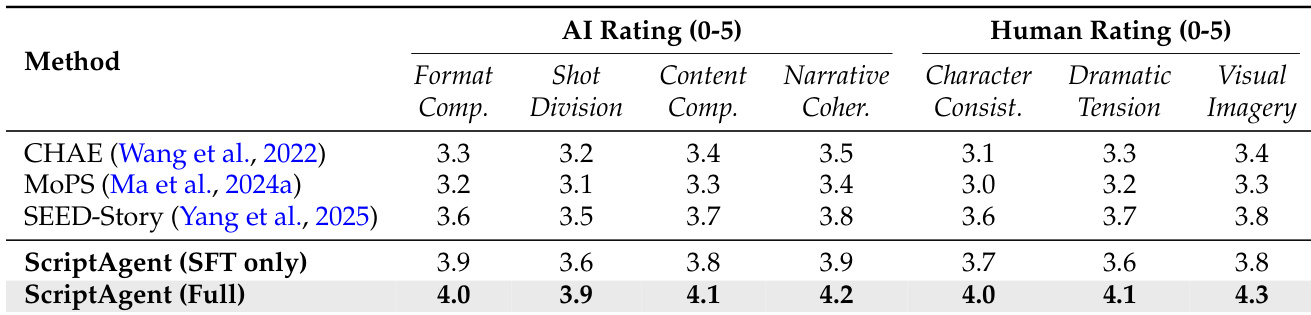
- 剧本生成通过 CriticAgent(gemini-2.5-pro)和人类导演评估:ScripterAgent 在 ScriptBench 上优于基线(MoPS、CHAE、SEED-Story),结构指标提升 +0.4,视觉意象评分 4.3/5(MovieAgent 为 3.8);RL 微调将戏剧张力从 3.6 提升至 4.1。
- 视频生成通过 CriticAgent、人类评分者和新颖的 VSA 指标评估:基于 ScripterAgent 剧本的条件生成使平均 AI 评分从 4.2 提升至 4.5,人类评分从 3.7 提升至 4.2;HYVideo1.5 在剧本忠实度(4.6)领先,Sora2-Pro 在视觉吸引力(4.8)领先。
- VSA 指标确认时序-语义对齐:HYVideo1.5 得分 54.8,Sora2-Pro 从 48.6 提升至 50.6;CLIP 分数平均提升 +1.7,但保真度有时以牺牲美学为代价。
- 消融实验显示完整智能体(剧本 + 分割 + 帧锚定)占优:提升叙事节奏与时间控制和电影镜头表现力;仅 ScripterAgent 提升视觉描述保真度和身体遮挡。
- 观察到权衡:Sora2-Pro 在视觉奇观(动态程度 79.5,物理法则 4.5)方面表现优异,HYVideo1.5 在叙事完整性(主体一致性 97.2,背景一致性 97.5)方面表现优异。
作者使用综合评估框架评估基于 ScripterAgent 生成剧本的视频生成模型。结果表明,基于 ScripterAgent 输出的条件生成显著提升了所有模型的 AI 和人类评分,人类评分从 3.7 提升至 4.2,AI 评分从 4.2 提升至 4.5。改进在剧本忠实度和叙事连贯性方面最显著,表明结构化剧本增强了时序-语义对齐和叙事质量。
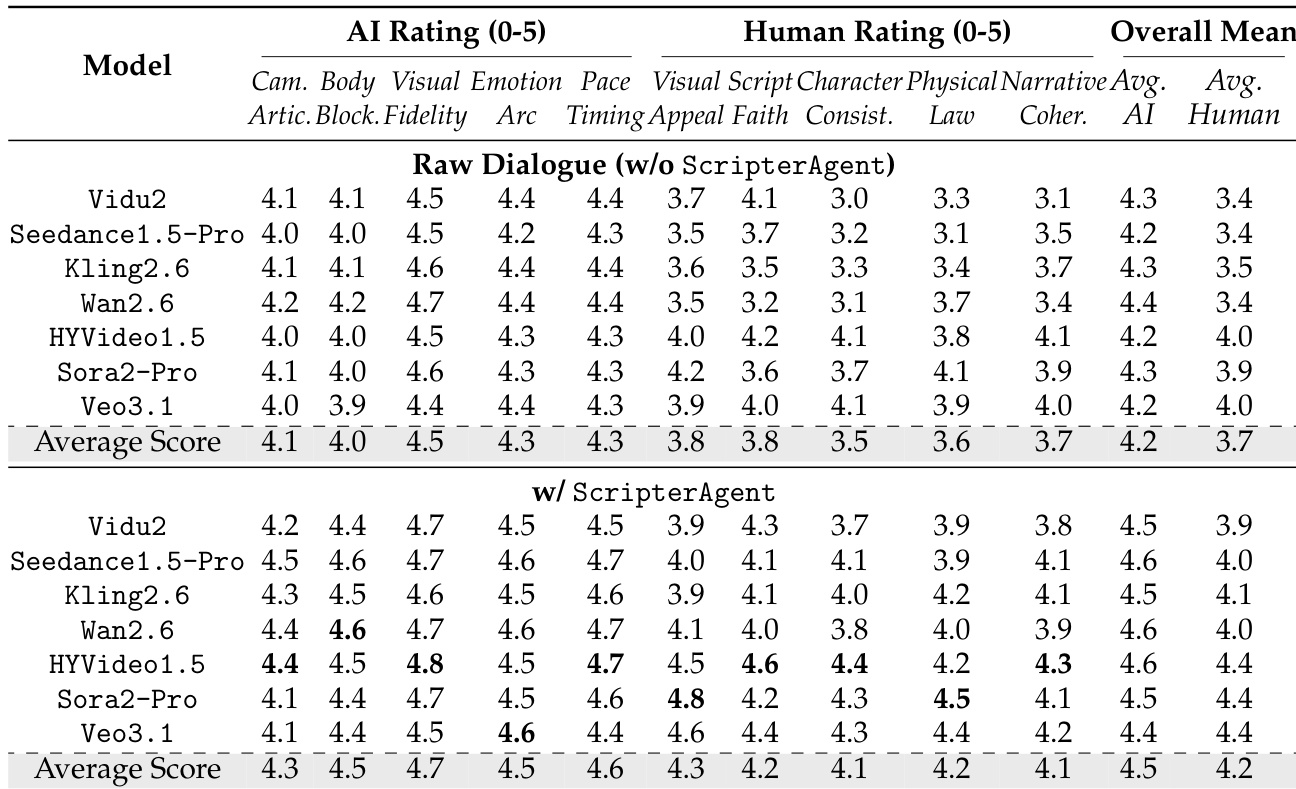
结果表明,基于 ScripterAgent 生成剧本的视频生成模型显著提升了对齐保真度和视觉质量。完整流程在所有指标上得分更高,尤其在视觉-剧本对齐(VSA)和主体一致性方面表现突出,表明结构化剧本增强了与源对话的时间和语义对齐。
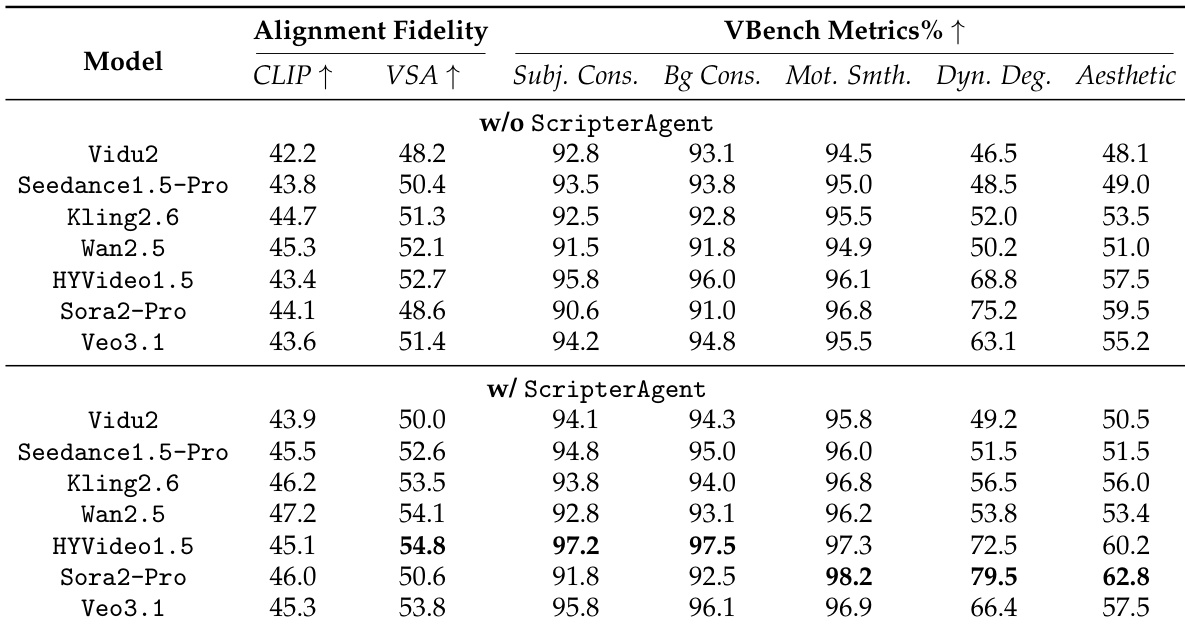
作者使用多阶段框架评估视频生成质量,比较结构化剧本和分割对模型性能的影响。结果表明,完整智能体流程在所有模型和评估者中持续优于基线,叙事连贯性、视觉保真度和情感表达方面提升最显著。
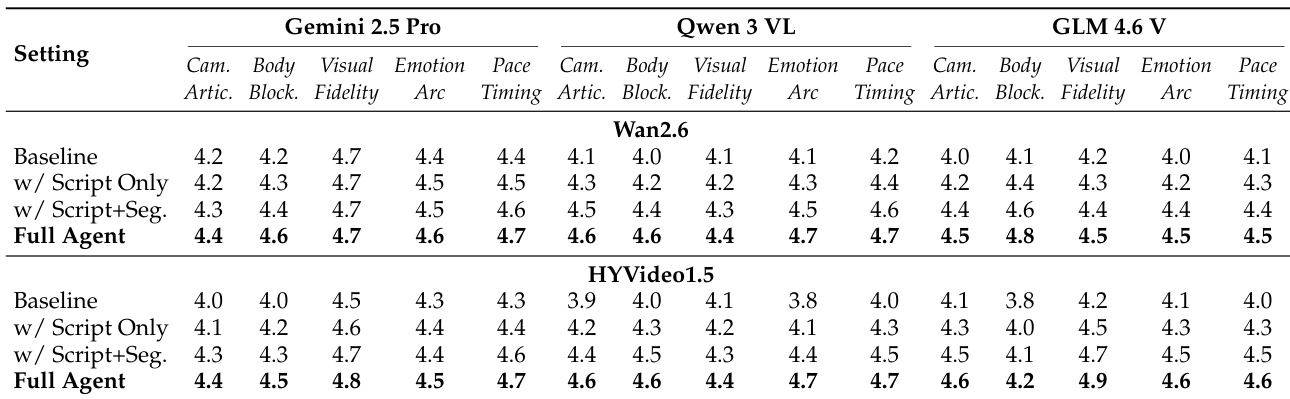
作者使用 ScripterAgent 为视频生成模型提供结构化剧本条件,结果在所有评估维度上显著提升。结果表明,平均 AI 评分从 4.1 提升至 4.6,尤其在电影镜头表现力、动态肢体语言和叙事节奏方面提升显著,表明结构化剧本增强了生成视频的技术执行和叙事连贯性。
作者使用评估框架评估剧本生成方法,比较 ScriptAgent 与 CHAE、MoPS 和 SEED-Story 等基线。结果表明,ScriptAgent(完整版)在 AI 和人类评估指标上均优于所有基线,在格式合规性、内容完整性、叙事连贯性、角色一致性、戏剧张力和视觉意象方面得分最高。