Command Palette
Search for a command to run...
弹性注意力:面向高效Transformer的测试时自适应稀疏率
弹性注意力:面向高效Transformer的测试时自适应稀疏率
Zecheng Tang Quantong Qiu Yi Yang Zhiyi Hong Haiya Xiang Kebin Liu Qingqing Dang Juntao Li Min Zhang
摘要
标准注意力机制的二次方复杂度在长上下文场景下为大语言模型(LLMs)带来了显著的可扩展性瓶颈。尽管混合注意力策略通过在单个模型中结合稀疏注意力与全注意力机制提供了一种可行的解决方案,但这类方法通常采用静态的计算比例(即稀疏注意力与全注意力的固定比例),无法在推理过程中适应下游任务对稀疏性的不同敏感性。为解决这一问题,我们提出弹性注意力(Elastic Attention),使模型能够根据输入动态调整整体稀疏性。该方法通过在现有预训练模型中引入一个轻量级的注意力路由模块(Attention Router),动态地为每个注意力头分配不同的计算模式。仅需在8块A800 GPU上训练12小时,我们的方法即可使模型在保持优异性能的同时实现高效的推理。在多个广泛应用的大语言模型上,针对三个长上下文基准的实验结果充分验证了该方法的优越性。
一句话总结
清华大学与阿里巴巴的研究人员提出 Elastic Attention,这是一种使用轻量级 Attention Router 动态调整每头计算模式的稀疏性自适应方法,在长上下文大语言模型中优于静态混合方法,且仅需极少重训练。
主要贡献
- Elastic Attention 引入轻量级 Attention Router,根据输入上下文动态将每个注意力头分配至全量或稀疏计算模式,实现自适应稀疏性,无需修改预训练模型的主干参数。
- 该方法通过学习根据任务敏感性分配稀疏性,克服了静态混合注意力的局限——在问答等稀疏敏感任务中保持性能,同时在摘要等稀疏鲁棒任务中提升效率。
- 在 Qwen3 和 Llama-3.1-8B-Instruct 上评估三个长上下文基准,Elastic Attention 仅需在 8×A800 GPU 上训练 12 小时即取得更优性能,同时通过融合内核和极小参数开销(每层 0.27M)维持推理效率。
引言
作者利用 Elastic Attention 解决大语言模型在长上下文推理中的二次复杂度瓶颈。此前的稀疏注意力方法依赖静态模式或固定稀疏率,限制了跨任务的适应性,且需精细超参数调优。其核心贡献是轻量级 Attention Router,可根据输入特征动态将每个注意力头分配至稀疏或全量计算模式,实现无需重训练基础模型的测试时稀疏性自适应。该方法在极小训练开销下实现优异性能与效率增益。
数据集

作者使用由五个来源构建的组合训练数据集训练 Qwen3-(4B/8B) 和 Llama-3.1-8B-Instruct 模型,覆盖稀疏敏感与稀疏鲁棒任务。数据集结构与使用方式如下:
-
数据集组成与来源:
- ChatQA2-Long-SFT-data:涵盖单文档与多跳问答(稀疏敏感)。
- MuSiQue:多跳问答基准(稀疏敏感)。
- CoLT-132K:代码补全与上下文学习任务(稀疏鲁棒)。
- GovReport:长文档摘要(稀疏鲁棒)。
- XSum:短摘要(稀疏鲁棒)。
-
关键子集细节:
- 总 token 数:约 0.74B。
- 序列长度:8K 至 64K token。
- 任务权重:稀疏鲁棒任务使用 t=1.0;稀疏敏感任务使用 t=0.7。
-
训练使用方式:
- 在 8×A800 GPU 上训练,每次运行不超过 12 小时。
- 混合比例通过 t 值反映任务类别(稀疏敏感 vs. 稀疏鲁棒)。
- 超参数详见表 6;完整训练设置见附录 D。
-
处理与配置:
- 未明确提及裁剪;序列最长可达 64K token。
- 未单独构建元数据;任务类别驱动权重分配。
- 测试的注意力模式:Streaming Sparse Attention (SSA) 与 XAttention (XA, τ=0.9)。
- 头计算模式记为“{检索头模式}-{稀疏头模式}”,例如 FA-SSA。
方法
作者采用以 Elastic Attention 机制为核心的模块化框架,引入轻量级 Attention Router 动态调整 Transformer 层内注意力计算的稀疏性。整体架构(如框架图所示)将该模块集成至标准 Transformer 块中,无需修改主干模型参数。方法核心在于 Attention Router,其工作方式类似于混合专家(MoE)门控机制。它处理键隐藏状态(xK∈Rs×H×d′),执行头级路由,决定每个注意力头应采用全注意力(FA)或稀疏注意力(SA)计算。此动态分配使模型可根据输入任务模式自适应整体稀疏性。
Attention Router 的架构(如图所示)包含两个主要组件:Task MLP 与 Router MLP。流程始于沿序列维度池化键隐藏状态,获得任务表示(xK′∈RH×d′)。该池化表示随后输入 Task MLP 与 Router MLP。Task MLP 推断任务特定特征,Router MLP 则利用这些表示生成头级路由对数矩阵(z∈RH×2)。该对数矩阵转换为每个头的二值决策(rhard(ℓ,h)∈{0,1}),指示所选计算模式(FA 或 SA)。路由决策随后用于将每个注意力头分配至相应计算路径。
为优化 Attention Router,作者采用基于 Gumbel-Softmax 策略的连续松弛方案,允许可微训练同时逼近离散路由决策。通过将 Gumbel-Softmax 应用于路由对数,获得软路由矩阵(rsoft(ℓ)∈RH×2)。硬路由决策通过 arg max 操作从软矩阵导出。为解决 arg max 函数的不可微性,采用直通估计器(STE),使梯度可在反向传播时通过软路由分布流动,同时在前向传播中保留硬路由行为。训练目标设计为最小化语言建模损失,同时优化模型稀疏率(ΩMSR)以满足任务特定约束,采用带可训练拉格朗日乘子的 min-max 优化框架,解耦稀疏性-性能权衡。
为高效部署,框架使用融合注意力内核,在单次前向传播中同时处理检索头与稀疏头。该设计消除了数据重排需求并减少内核启动开销,对长上下文序列的高吞吐推理至关重要。融合内核利用线程块级分支,每个线程块动态从路由元数据中检索其分配头的计算模式,实现统一内核启动与最优 GPU 硬件调度。此方法确保 Attention Router 的计算开销极小,每层仅增加 0.27M 参数,从而保持推理效率与计算成本。
实验
- 在 LongBench 任务上评估 Ω_MSR 对 Llama3.1-8B-Instruct 的影响,揭示两类任务:稀疏鲁棒(如摘要)与稀疏敏感(如问答),支持动态注意力模式选择。
- 在 LongBench-E 与 RULER 上,Elastic Attention 优于基线方法(如 InfLLM-V2、MoBA),平均 Ω_MSR ~0.65–0.85,在 256K token 时取得最佳性能(RULER 得分 68.51),同时保持 1.51× 加速(FA-XA)或极端稀疏下 3.28× 加速(XA-SSA)。
- 消融实验证实 Task MLP 增强任务区分度(降低余弦相似度),且 MLP 隐藏层大小 ×4 提供最优性能-效率权衡。
- 目标稀疏度调优(t_sen=0.7, t_rob=1.0)平衡性能与效率;降低 t_sen(如 0.4)可提升准确率但减少推理收益。
- Router 延迟可忽略(平均 0.196 ms),在 512–1M token 范围内稳定;边界池化(前/后 100 token)优化任务识别,避免噪声干扰。
- 在 LongBench-V2 上,Elastic Attention(FA-XA/FA-SSA)取得最高平均分;Qwen3-4B 使用 XA-SSA 在全稀疏下保持接近主干性能(差距 <1 分)。
- 错误分析显示在检索关键上下文片段时精度更优,避免了基线在法律、政策与叙事任务中的幻觉问题。
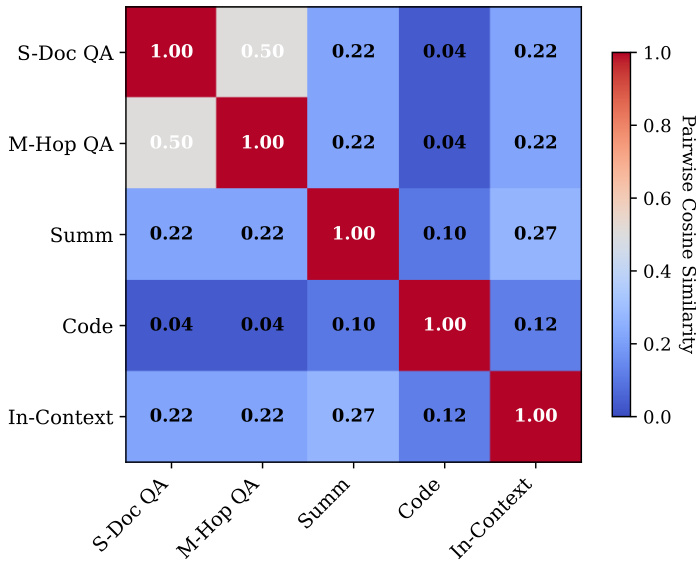
作者使用热力图可视化 Task MLP 处理前后任务表示的成对余弦相似度。结果显示 Task MLP 显著降低任务间相似度,表明任务区分度提升。这表明模型有效解耦任务特定特征,支持更精确的注意力路由决策。
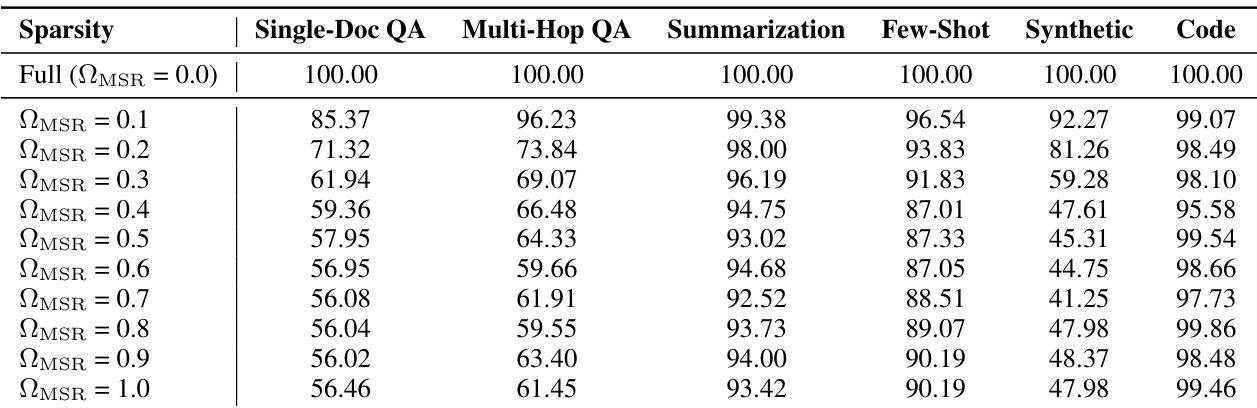
作者使用 Llama3.1-8B-Instruct 模型研究不同 ΩMSR 对下游任务的影响,在 LongBench 任务上评估性能。结果表明,问答与代码等稀疏敏感任务随 ΩMSR 增加性能显著下降,而摘要等稀疏鲁棒任务保持稳定,表明任务对注意力稀疏性存在依赖性。
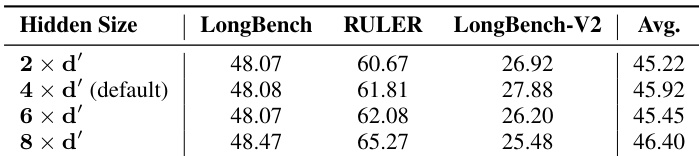
作者研究 Attention Router 隐藏层大小对多个基准上模型性能的影响。结果表明,将隐藏层大小从 2×d′ 增加至 4×d′ 可提升平均性能,4×d′ 设置在 RULER 与 LongBench-V2 上取得最高分。但进一步增至 8×d′ 导致性能下降,表明默认 4×d′ 设置在性能与效率间提供最优平衡。
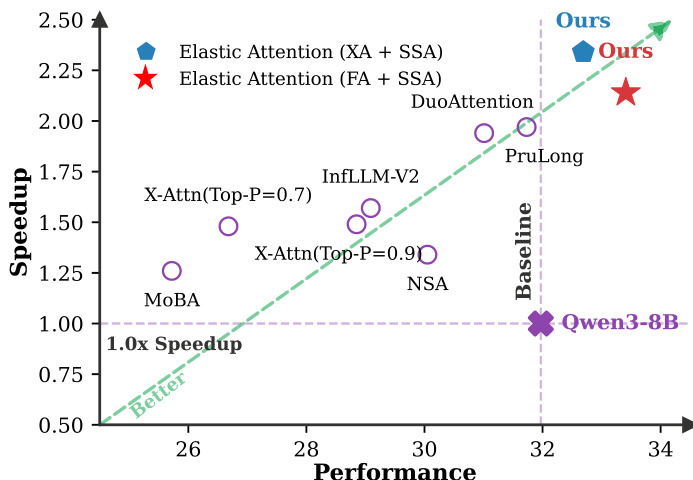
结果表明,Elastic Attention 在所有对比方法中取得最高性能与加速,优于 DuoAttention、PruLong 与 InfLLM-V2 等基线。该方法建立更优的帕累托前沿,在不同稀疏水平下平衡高性能与高效推理。
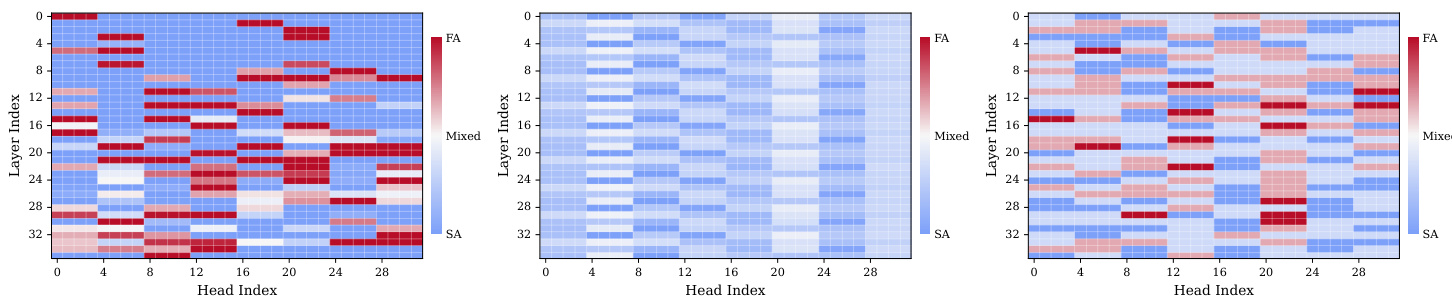
作者使用热力图可视化语言模型各层与头的注意力计算模式。结果表明,某些头(尤其在中高层)在所有任务中始终以全注意力(FA)模式激活,表明其作为检索头功能。其他头表现出任务特定切换行为,而多数头始终路由至稀疏注意力(SA),显示注意力机制根据任务需求清晰划分。