Command Palette
Search for a command to run...
LLM能否帮你收拾烂摊子?基于LLM的应用就绪数据准备综述
LLM能否帮你收拾烂摊子?基于LLM的应用就绪数据准备综述
摘要
数据准备旨在对原始数据集进行去噪处理,揭示跨数据集之间的关联关系,并从中提取有价值的洞察,这对于众多以数据为中心的应用场景至关重要。在以下三方面驱动下,基于大语言模型(LLM)的方法正迅速演变为数据准备领域一种具有变革性且可能占据主导地位的新范式:(i)对可直接用于应用的数据日益增长的需求(如用于分析、可视化和决策支持);(ii)大语言模型技术能力的持续增强;(iii)支持灵活智能体构建的基础设施的兴起(例如基于 Databricks Unity Catalog 的系统)。本文通过对数百篇近期文献的系统性调研,全面梳理了这一快速演进领域的现状,重点关注大语言模型技术在面向多样化下游任务的数据准备中的应用。首先,我们揭示了数据准备范式的核心转变:从传统的基于规则、依赖特定模型的流水线,转向以提示(prompt)驱动、上下文感知且具备智能体(agentic)特性的新型工作流。其次,我们提出了一种以任务为中心的分类体系,将该领域划分为三大核心任务:数据清洗(如标准化、错误处理、缺失值填补)、数据集成(如实体匹配、模式匹配)以及数据增强(如数据标注、数据画像)。针对每一类任务,本文系统梳理了代表性技术,深入分析其优势(如更强的泛化能力、更深入的语义理解)与局限性(如大语言模型在规模化时带来的高昂成本、先进智能体中仍存在的持续性幻觉问题,以及先进方法与薄弱评估体系之间的不匹配)。此外,本文还对当前研究中常用的数据集与评估指标进行了实证分析。最后,我们探讨了该领域面临的关键开放性挑战,并提出一个面向未来的发展路线图,强调构建可扩展的 LLM-数据系统、设计具有原则性的可靠智能体工作流,以及建立稳健的评估协议。
一句话总结
周伟等人综述了大语言模型(LLM)增强的数据预处理方法,提出了一种以任务为中心的分类体系,涵盖数据清洗、集成与增强,推动工作流从基于规则转向智能体驱动、上下文感知的模式,突出检索增强生成与混合LLM-ML系统等创新,同时探讨了在企业分析和机器学习流水线中面临的可扩展性、幻觉和评估缺失等挑战。
主要贡献
- LLM 使数据预处理范式从手动、基于规则的方式转向指令驱动、智能体化的工作流,通过自然语言提示和自动化流水线编排降低人工投入,适用于清洗与集成等任务。
- 论文提出以任务为中心的分类体系,涵盖数据清洗、集成与增强,强调 LLM 在语义推理方面的优势——如解决同义词或领域术语歧义——而传统方法受限于语法或统计局限。
- 通过对近期文献与实证基准的分析,该综述识别出关键挑战,包括 LLM 幻觉、可扩展性成本和薄弱的评估协议,并呼吁构建可扩展系统、可靠智能体设计和稳健的评估框架。
引言
作者利用大语言模型应对分析、决策与实时系统对“即用型数据”的日益增长需求。传统数据预处理方法严重依赖人工规则、语义理解有限、跨领域泛化能力差、标注成本高——这些因素均阻碍了可扩展性与适应性。作为回应,作者提出一项综合综述,围绕三个核心任务组织 LLM 增强技术:清洗、集成与增强。他们引入以任务为中心的分类体系,强调 LLM 如何实现提示驱动与智能体化工作流,并指出关键局限性,包括幻觉、高推理成本与薄弱评估协议——同时勾勒出通向可扩展、可靠、跨模态数据预处理系统的路线图。
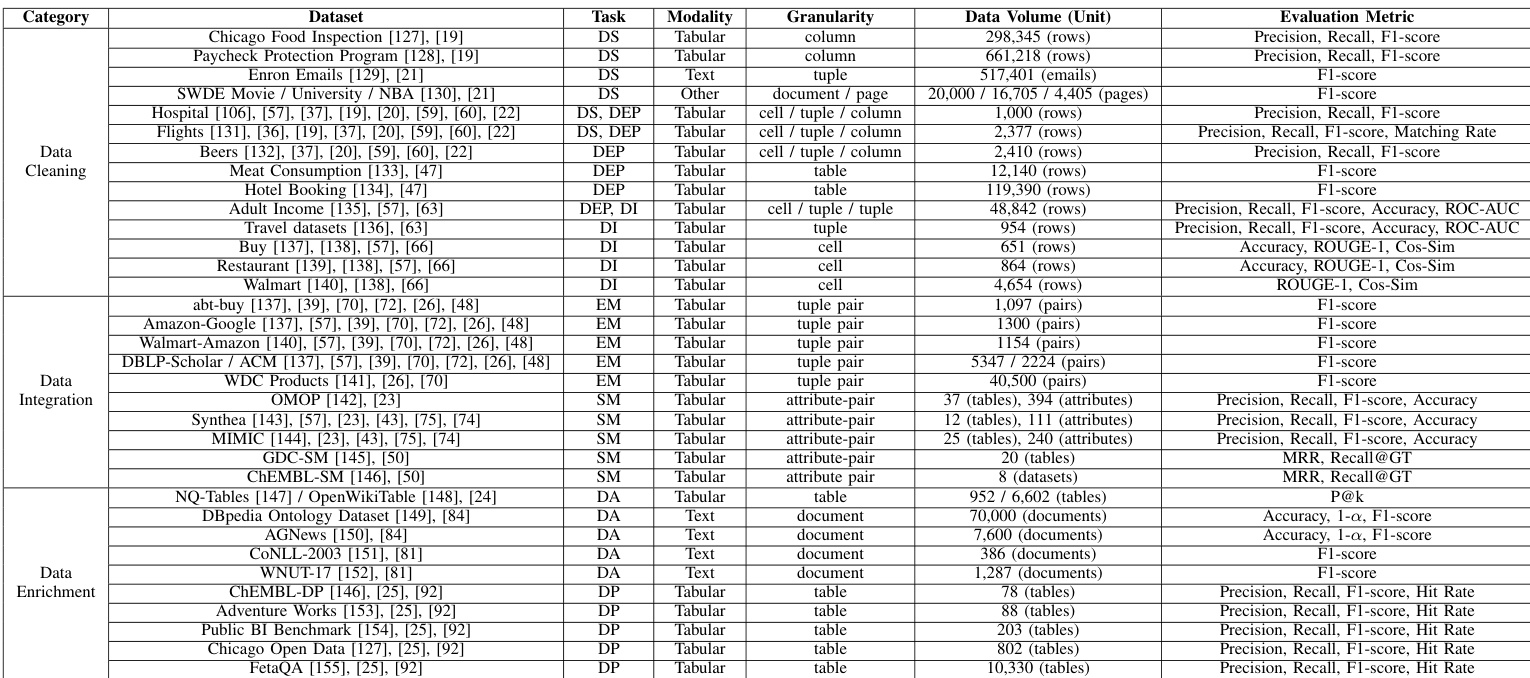
数据集

作者采用结构化数据集分类体系评估 LLM 增强的数据预处理方法,按处理粒度将基准数据集分组:记录级、模式级和对象级。
-
记录级数据集:关注单个元组、单元格或元组对,用于清洗、错误检测、插补与实体匹配。示例包括:
- 元组级:Adult Income, Hospital, Beers, Flights, Enron Emails
- 列级:Paycheck Protection Program, Chicago Food Inspection
- 单元格级:Buy, Restaurant, Walmart
- 元组对级:abt-buy, Amazon–Google, Walmart–Amazon, DBLP–Scholar, DBLP–ACM, WDC Products
-
模式级数据集:对齐异构模式中的列或属性,用于医疗与生物医学等领域的模式匹配。示例:
- OMOP, Synthea, MIMIC(临床)
- GDC-SM, ChEMBL-SM(科学/生物医学)
-
对象级数据集:将整张表或文档视为单位,用于需要全局上下文的分析与标注。示例:
- 表级:Public BI, Adventure Works, ChEMBL-DP, Chicago Open Data, NQ-Tables, FetaQA
- 文档级:AG-News, DBpedia, CoNLL-2003, WNUT-17
作者未直接在这些数据集上训练模型,而是用它们对 LLM 增强方法在清洗、集成与增强任务上进行基准测试。除数据集固有结构与评估指标外,未描述具体裁剪或元数据构建。处理过程包括应用 LLM 标准化格式、检测与修复错误、插补缺失值、匹配实体与模式、标注语义、生成元数据——均旨在提升下游分析与机器学习任务效果。
方法
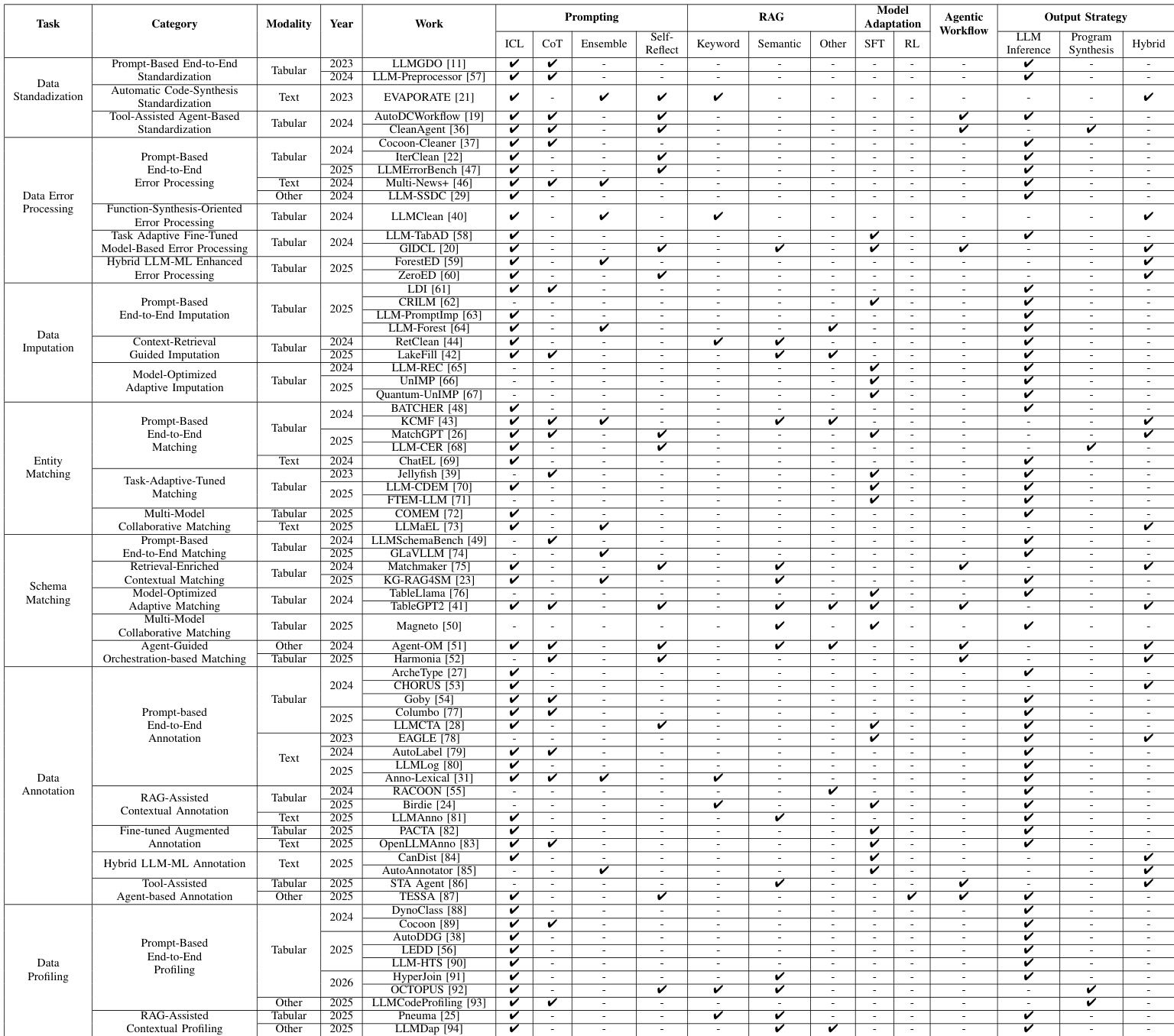
作者提出一个全面框架,用于在数据预处理中利用大语言模型(LLM),围绕三个核心领域构建:数据清洗、数据集成与数据增强。整体架构如框架图所示,将这些领域定位为将异构原始数据转化为结构化、可信、增强形式的基础流程,适用于可视化分析、企业商业智能、模型训练、欺诈监测与数据市场等下游应用。框架强调:数据清洗解决不一致标准、错误与不完整问题;数据集成解决语义歧义与模式冲突;数据增强通过元数据与标注增强数据集。这些过程相互关联,一个领域的输出常作为另一领域的输入,形成连贯的数据预处理流水线。
如框架图所示,数据清洗模块包含三个主要任务:数据标准化、错误处理与插补。对于数据标准化,作者描述了一种基于提示的端到端方法,结构化提示引导 LLM 将异构数据转换为统一格式,包括指令引导提示(使用人工设计指令与上下文示例)和推理增强批量处理(采用逐步推理与批量提示以提高鲁棒性与效率)。另一种范式是工具辅助智能体标准化,LLM 智能体通过生成并执行 API 调用或代码协调并执行标准化流水线,如 CleanAgent 示例所示。对于数据错误处理,框架概述了检测与修正两阶段过程,通过基于提示的端到端处理(使用结构化提示引导 LLM 进行迭代工作流)和任务自适应微调(在合成或上下文增强数据集上微调 LLM 以学习特定错误模式)实现。混合方法将 LLM 与机器学习模型结合,使用 LLM 生成伪标签训练轻量级 ML 分类器,或推导可解释决策结构指导基于 ML 的错误检测。
数据集成模块聚焦实体匹配与模式匹配。对于实体匹配,框架描述了一种基于提示的端到端方法,使用结构化提示引导 LLM 判断两条记录是否指向同一现实实体,包括指导驱动的上下文匹配(使用专家定义规则与多步流水线)和批量聚类匹配(同时处理多个实体对以提高效率)。任务自适应微调匹配涉及使用从更大模型蒸馏的推理轨迹或提高训练数据质量微调 LLM。多模型协作方法协调多个模型(如轻量级排序器与更强 LLM)实现可扩展且一致的匹配。对于模式匹配,框架提出基于提示的端到端方法,使用结构化提示识别不同模式间列名的对应关系,通过检索增强上下文匹配(用知识图谱等外部检索组件增强 LLM 输入)与模型优化自适应匹配(使用模态感知微调与专用架构组件如表编码器)加以增强。智能体引导编排方法使用 LLM 智能体管理并协调整个模式匹配流水线,通过基于角色的任务划分或工具规划机制实现。
数据增强模块处理数据标注与分析。对于数据标注,框架描述了一种基于提示的端到端方法,使用结构化提示引导 LLM 为数据实例分配语义或结构标签,包括指令引导标注与推理增强迭代标注(使用逐步推理与自我评估)。检索辅助上下文标注方法通过从语义相似示例或外部知识图谱检索相关上下文丰富提示。微调增强标注通过在特定任务数据集上微调 LLM 提升专业领域性能。混合 LLM-ML 标注方法结合 LLM 与机器学习模型,使用 LLM 生成候选标注,再由小型模型蒸馏与过滤。工具辅助智能体标注使用配备专用工具的 LLM 智能体处理复杂标注任务。对于数据分析,框架概述了基于提示的端到端方法,使用精心设计的提示引导 LLM 生成数据集描述、模式摘要与分层组织,包括指令与约束驱动分析和示例与推理增强分析(结合少样本示例与思维链推理)。检索辅助上下文分析方法结合多种检索技术与 LLM 推理,提高分析准确性,尤其在元数据稀疏时。
实验
- 从四个维度评估数据预处理方法:正确性、鲁棒性、排序质量与语义一致性。
- 正确性指标包括准确率、精确率、F1 分数(用于可靠性)和召回率、匹配率(用于覆盖率),在实体匹配与错误检测等任务上验证。
- 鲁棒性通过 ROC 和 AUC 评估,衡量在错误处理任务中不同数据分布下的稳定表现。
- 排序质量通过 P@k 和 MRR 衡量检索效用,通过 Recall@GT、1−α、命中率衡量标注与匹配任务中增强的完整性。
- 语义保留使用 ROUGE(词汇重叠)和余弦相似度(嵌入对齐)评估,确保标准化与分析任务输出与参考内容一致。
作者使用综合评估框架,从多个维度(包括正确性、鲁棒性、排序质量与语义一致性)评估数据预处理方法,指标包括精确率、召回率、F1 分数(正确性)、ROC 和 AUC(鲁棒性)、P@k 和 MRR(排序质量)、ROUGE 和余弦相似度(语义保留)。结果表明,尽管许多方法在特定领域(如正确性或排序质量)表现优异,但无单一方法在所有维度上持续优于其他方法,凸显不同评估标准间的权衡。
作者在数据清洗、集成与增强任务中使用多样化数据集评估预处理方法,指标选择基于正确性、鲁棒性、排序质量与语义一致性。结果表明,评估指标因任务与数据类型显著不同,精确率、召回率与 F1 分数最常用,而 ROC-AUC、MRR、ROUGE-1 等专用指标用于错误检测与文本增强等特定场景。