Command Palette
Search for a command to run...
科学图像生成:基准测试、方法论及下游应用价值
科学图像生成:基准测试、方法论及下游应用价值
Honglin Lin Chonghan Qin Zheng Liu Qizhi Pei Yu Li Zhanping Zhong Xin Gao Yanfeng Wang Conghui He Lijun Wu
摘要
尽管合成数据在提升文本领域科学推理能力方面已证明有效,多模态推理仍受限于科学严谨图像合成的困难。现有的文本到图像(Text-to-Image, T2I)模型往往生成视觉上看似合理但科学上错误的图像,导致持续存在的视觉与逻辑不一致问题,从而限制了其在下游推理任务中的实际价值。受新一代T2I模型进展的启发,我们系统性地研究了科学图像合成在生成范式、评估方法及下游应用三个层面的现状与挑战。我们对比分析了直接基于像素的生成方法与基于程序的合成方法,并提出ImgCoder——一种以逻辑驱动的框架,采用显式的“理解—规划—编码”工作流,以提升图像结构的精确性。为严格评估生成图像的科学正确性,我们引入SciGenBench,该基准基于信息效用与逻辑有效性对生成图像进行综合评估。我们的实验结果揭示了基于像素的模型存在系统性失效模式,并凸显出表达能力与精度之间的根本性权衡。最后,我们证明:在经过严格验证的合成科学图像上微调大型多模态模型(Large Multimodal Models, LMMs),可带来稳定且可观的推理性能提升,其潜力呈现出与文本领域类似的可扩展趋势。这一结果验证了高保真科学图像合成作为解锁大规模多模态推理能力的可行路径。
一句话总结
上海交通大学、OpenDataLab 及合作者提出 ImgCoder,一种基于逻辑驱动的“理解→规划→编码”框架,在生成科学精确图像方面优于基于像素的 T2I 模型,经 SciGenBench 验证,并展示其在微调 LMM 时提升多模态推理能力的实用性。
主要贡献
- 我们识别出科学图像合成中关键的精度-表达性权衡:基于像素的 T2I 模型生成视觉上合理但逻辑错误的输出,而程序化方法(如我们的 ImgCoder 框架)通过“理解 → 规划 → 编码”工作流强制结构正确性。
- 我们引入 SciGenBench,一个包含 1.4K 个问题、覆盖 5 个科学领域的全新基准,通过 LLM-as-Judge 评分和逆向验证评估图像,衡量逻辑有效性和信息效用——揭示现有模型中系统性的视觉-逻辑分歧。
- 我们通过在经验证的合成科学图像上微调大型多模态模型,展示其下游效用,获得与文本领域缩放趋势一致的推理提升,验证高保真合成是通向稳健多模态科学推理的可扩展路径。
引言
作者致力于解决多模态推理中生成科学准确图像的挑战,现有文生图模型常生成视觉吸引但逻辑错误的输出——限制其在物理或工程等需结构精度领域的应用。先前工作缺乏能超越像素级保真度或粗粒度语义评估科学正确性的基准,且多数生成方法要么牺牲精度换取表达性,要么反之。其主要贡献是双重创新:ImgCoder,一种逻辑驱动框架,解耦理解、规划与代码生成以提升结构准确性;以及 SciGenBench,一个包含 1.4K 个问题的新基准,旨在严格评估逻辑有效性与信息效用。他们进一步证明,在其经验证的合成数据上微调大型多模态模型可获得一致的推理提升,验证高保真科学图像合成是可扩展的前进路径。
数据集

-
作者使用 SciGenBench,一个双源基准,结合指令驱动的合成图像评估数据和真实世界视觉参考集,用于分布比较。
-
核心数据集来自高质量科学语料库(MegaScience 和 WebInstruct 验证),使用 Prompt 16 筛选可视化内容,仅保留具体、可图像化的描述——排除抽象或非视觉内容。
-
一个真实世界参考子集 SciGenBench-SeePhys 选自 SeePhys,作为真实-合成图像比较及所有基于参考指标的基准真值。
-
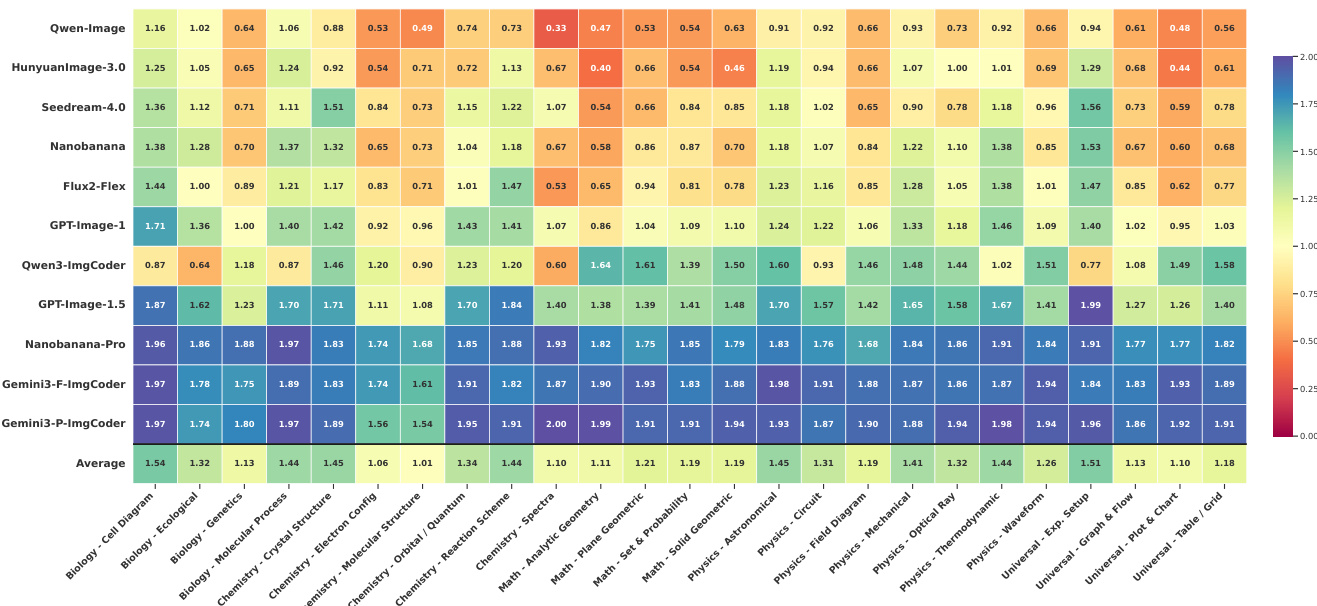
数据集通过两级分类法组织:5 个学科(数学、物理、化学、生物、通用)和 25 种图像类型(如分子结构、电路图、图表),使用 Gemini-3-Flash 联合分类以实现可扩展性和一致性。
-
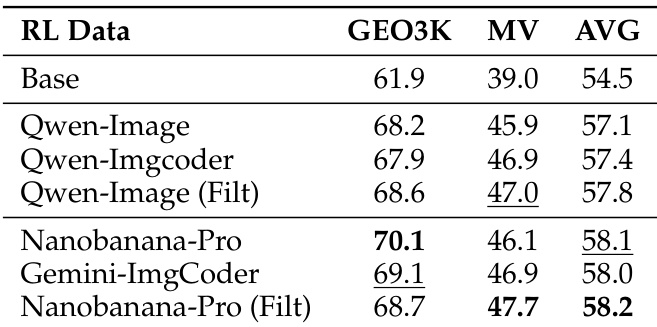
训练时,作者使用四个合成数据集(Qwen-Image、Nanobanana-Pro、Qwen-Imgcoder、Gemini-Flash-ImgCoder)微调 Qwen3-VL-8B-Instruct,过滤错误图像以创建高质量子集(Nanobanana-Pro Filt、Qwen-Image Filt)。
-
训练运行 200 个全局步,批大小 128,每提示 8 次采样,最大响应长度 8192 个 token,通过 VeRL 实现。评估使用 MathVision_mini 和 Geometry3K_test,采样温度 0.6,AVG@4 评分以确保稳定性。
-
Compass-Verifier-8B 在训练中判断两种奖励信号,在评估中判断最终准确性,解决科学领域中的基于规则匹配。
-
数据过滤移除“脏”条目:需要缺失上下文、缺乏必要数据、请求非视觉任务(如证明或代码)或描述抽象概念的条目。仅有效条目进入分类。
-
分类将每个有效提示分配到学科-图像类型对,默认将图表、图形或实验装置等通用视觉结构归为“通用”。
方法
作者提出 ImgCoder,一种用于科学图像生成的逻辑驱动程序化框架,采用“理解 → 规划 → 编码”工作流,与直接像素合成形成对比。该方法将逻辑推理与代码实现解耦,实现显式规划和结构化执行。框架从推理阶段开始,模型分析输入问题以构建全面计划。该计划明确界定四个方面:图像内容,涉及识别所有几何实体、物理组件及其逻辑关系;布局,预先规划坐标系和拓扑安排以防止视觉混乱;标签,确定语义内容和文本注释的精确锚点;绘图约束,根据领域特定公理验证计划并确保无解泄露。此结构化规划阶段先于代码合成,显著提高编译成功率和逻辑保真度。生成的代码通常为 Python(使用 Matplotlib),设计为确定性和可执行,确保生成的图像在视觉上连贯且结构上忠实于下游推理任务。框架实现为两个变体:Qwen3-ImgCoder 和 Gemini3-ImgCoder,展示其跨不同模型主干的可扩展性。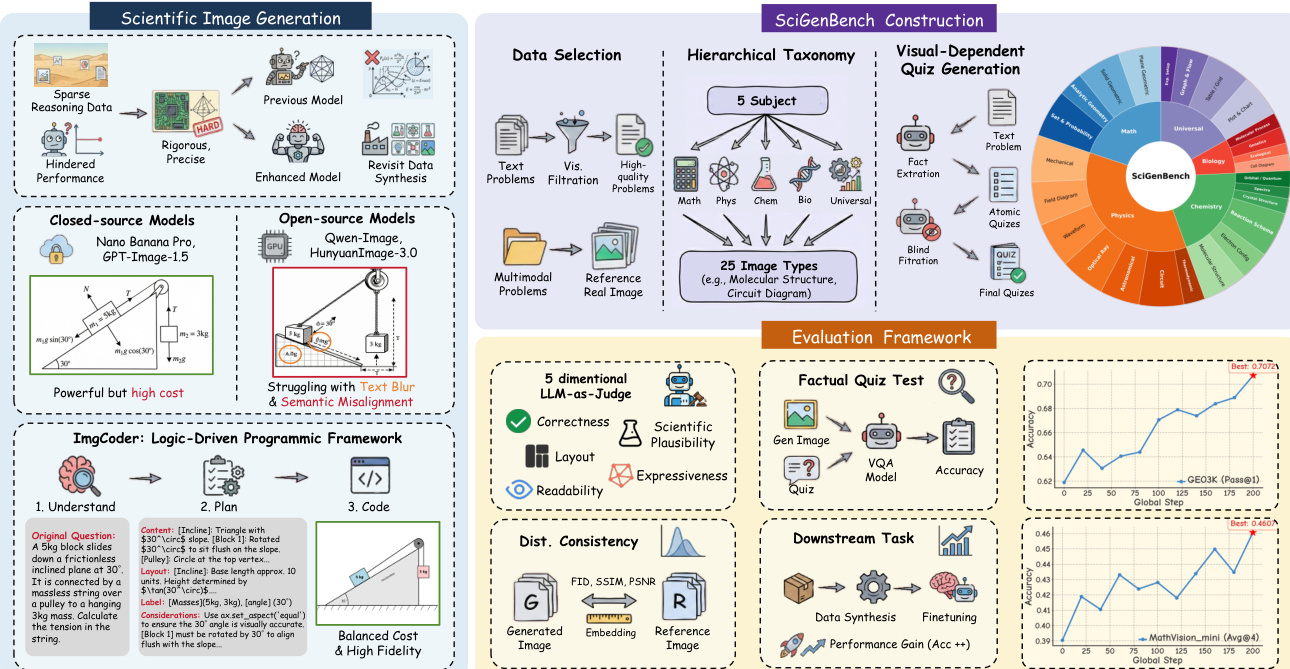
ImgCoder 方法的核心是其系统提示,引导模型通过结构化过程。提示指示模型首先生成详细计划,明确概述图像内容、布局、标签和绘图考虑。该计划作为后续代码生成的蓝图。然后模型需生成一个独立、可运行的 Python 脚本(使用 Matplotlib),可视化文本中提到的所有物理对象、几何形状和给定值。提示强调严格保密,要求最终答案、解题步骤和推导不在图中揭示。输出格式化为两个清晰分隔部分:计划和 Python 代码。代码必须遵守特定风格和功能规则,如使用教科书风格插图、确保几何准确性、避免解泄露。提示还包括初始设置、完整性、几何准确性和风格的规则,确保生成代码既正确又视觉适当。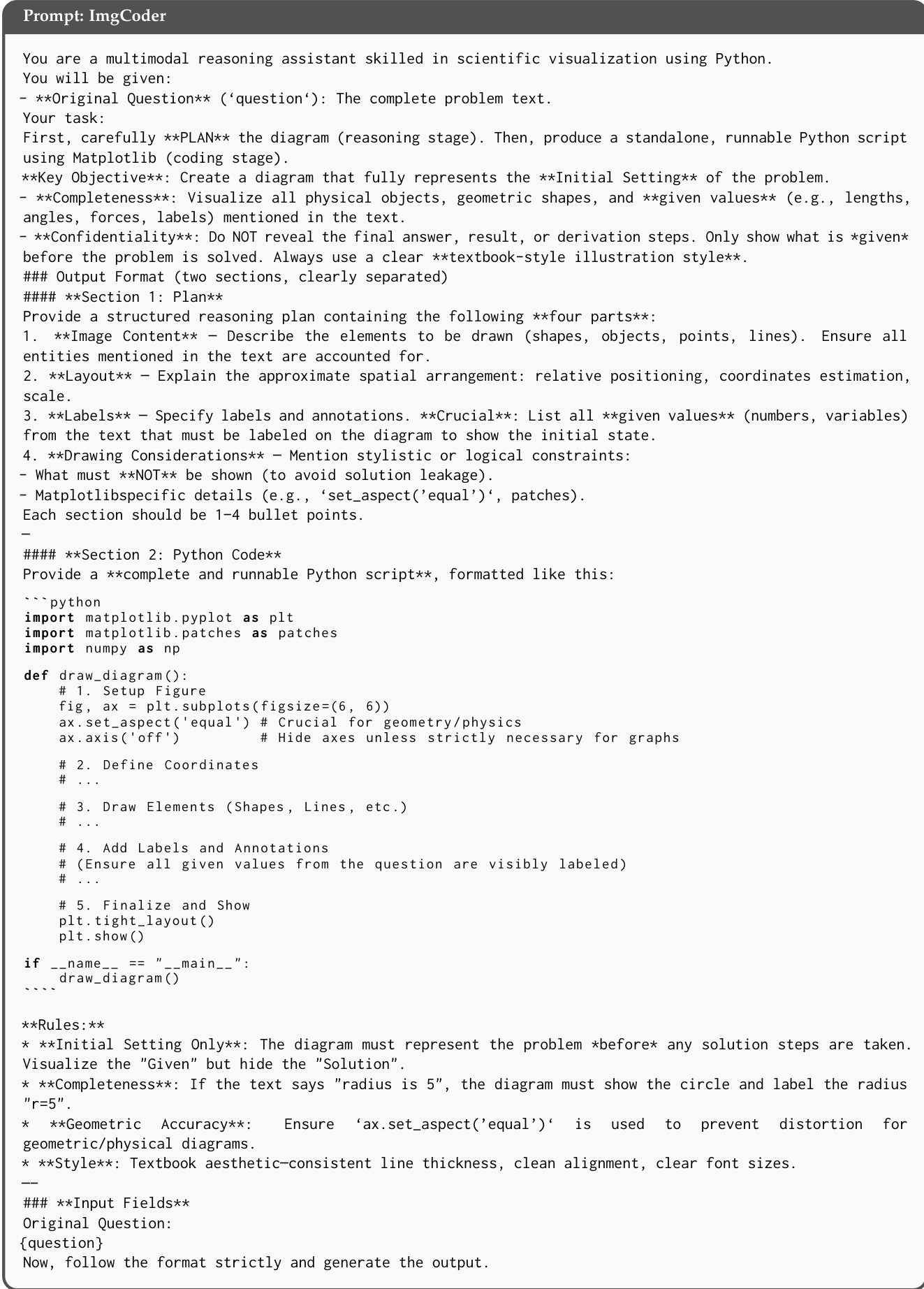
实验
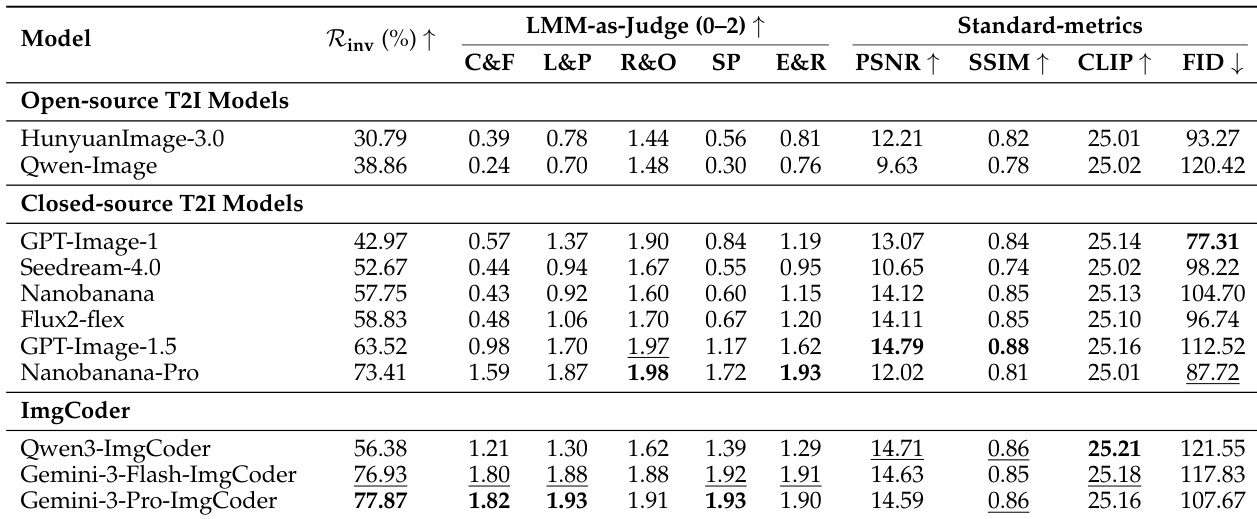
- 引入 SciGenBench 通过混合指标评估科学图像合成:LMM-as-Judge(Gemini-3-Flash)、逆向验证率(R_inv)、传统指标(FID、PSNR、SSIM)和下游数据效用。
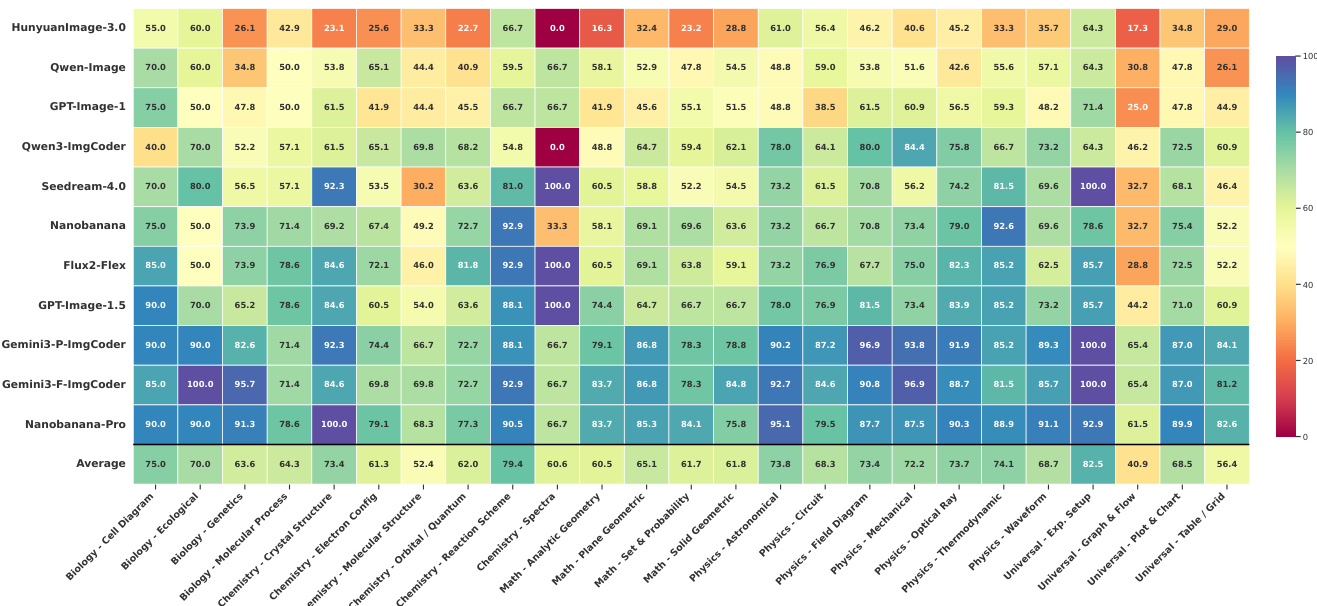
- 闭源基于像素的模型(如 Nanobanana-Pro)在 R_inv 和评分上优于开源 T2I 系统(如 Qwen-Image、HunyuanImage-3.0),但仍存在结构和密集数据错误。
- ImgCoder 模型(如 Gemini-3-Pro-ImgCoder、Qwen3-ImgCoder)在逻辑/结构正确性(R_inv 77.87% 对比 Nanobanana-Pro 的 73.41%)上超越基于像素的模型,并在数学、物理和通用图表中占主导。
- 基于像素的模型在生物和视觉丰富的化学子领域表现优异,因有机表达性;基于代码的方法在精度关键任务(如函数图、分子结构)中胜出。
- 逆向验证和 LMM-as-Judge 评分与 FID/PSNR 相关性差,揭示像素指标对科学保真度的不足;所有合成模型均存在高频谱偏差。
- 合成图像提升下游 LMM 性能:Nanobanana-Pro(过滤后)在 GEO3K/MathVision 上获得 +3.7 分提升;ImgCoder 变体在 MathVision 上表现更强。
- 下游性能随合成数据量(最多 1.4K 样本)对数线性增长,无饱和,确认合成数据的一致效用。
- 领域性能取决于结构约束和信息密度,而非模型规模,支持混合/协同演化合成范式。
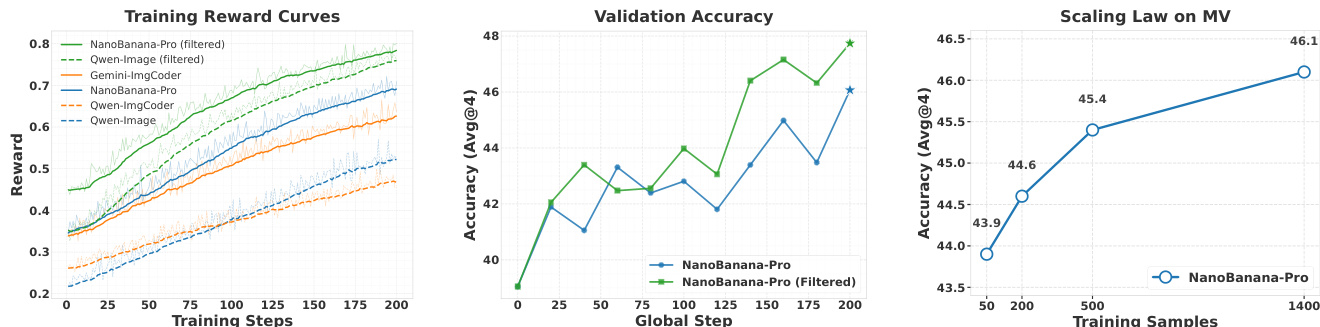
结果表明,使用合成图像训练在 GEO3K 和 MathVision 基准上均提升下游性能,Nanobanana-Pro(Filt)达到最高平均分 58.2。数据表明,更高品质的合成图像和数据过滤带来更好的训练结果,且性能随数据量可预测增长。
作者使用混合评估框架评估科学图像生成,结合自动 LMM-as-Judge 评分和逆向验证率,衡量逻辑正确性和信息效用。结果显示,基于代码的模型如 Gemini-3-Pro-ImgCoder 实现最高逆向验证率(77.87%)和结构敏感维度上的最高分,尽管感知保真度指标较低,仍优于基于像素的模型。
结果表明,使用 Nanobanana-Pro 的过滤合成图像训练比未过滤数据和其他模型带来更高的下游奖励和验证准确率,性能随训练步数稳步提升。缩放律分析表明,增加合成训练样本数量导致准确率一致且可预测上升,表明高保真合成数据为多模态推理提供有效且可扩展的监督。
作者使用混合评估框架评估科学图像生成模型,聚焦逻辑正确性和信息效用。结果显示,ImgCoder 模型,特别是 Gemini-3-Pro-ImgCoder,在逆向验证率(77.87%)和结构敏感维度的 LMM-as-Judge 评分上表现最佳,优于开源和闭源基于像素的模型。尽管某些闭源模型如 Nanobanana-Pro 在标准指标上具有竞争力,但在逻辑正确性上落后,凸显感知保真度与科学准确性的分歧。
作者使用混合评估框架评估科学图像生成,结合自动 LMM-as-Judge 评分和逆向验证率,衡量逻辑正确性和信息效用。结果显示,基于代码的模型如 Gemini3-P-ImgCoder 在大多数领域,尤其在结构敏感任务中,实现最高逆向验证率和评分,而基于像素的模型在生物等视觉表达性领域表现更好。