Command Palette
Search for a command to run...
VisGym:面向多模态Agent的多样化、可定制化、可扩展环境
VisGym:面向多模态Agent的多样化、可定制化、可扩展环境
摘要
当前的视觉-语言模型(VLMs)在多步视觉交互任务中仍缺乏充分表征,尤其是在如何在长时程中整合感知、记忆与动作方面存在明显不足。为此,我们提出了 VisGym——一个包含17个环境的综合性评估与训练平台,用于评测和训练VLMs。该系列环境涵盖符号谜题、真实图像理解、导航以及操作任务,支持对难度、输入表征、规划时域和反馈机制的灵活调控。我们还提供了多步求解器,可生成结构化的示范数据,从而支持监督微调。评估结果表明,所有前沿模型在交互式场景中均表现不佳,无论在简单配置(成功率46.6%)还是困难配置(成功率26.0%)下均难以取得理想成果。实验揭示了若干显著局限:模型难以有效利用长时上下文信息,其表现反而在使用无界历史记录时劣于采用截断窗口的情况;此外,我们发现若干基于文本的符号任务在转为视觉呈现后难度显著提升。然而,在部分可观测或动态未知的设定下,引入显式的任务目标观测、文本反馈以及探索性示范数据进行监督微调,能够带来稳定性能提升,这揭示了当前模型在多步视觉决策中的具体失效模式,并为未来改进提供了明确路径。代码、数据与模型资源可访问:https://visgym.github.io/。
一句话总结
加州大学伯克利分校的研究人员推出了 VisGym,这是一个包含 17 个可定制视觉环境的套件,用于评估和训练视觉-语言模型(VLM)在多步交互任务中的表现。研究发现,即使是前沿模型在长时程推理、上下文管理和视觉定位方面仍存在困难;但通过提供明确的目标提示、文本反馈和信息揭示式演示,模型性能显著提升,为增强现实世界多模态智能体能力提供了清晰路径。
主要贡献
- VisGym 引入了 17 个多样化的可定制环境,涵盖导航、操作和符号任务,系统性评估 VLM 在长时程视觉决策中的表现,通过精细控制上下文长度、反馈和可观测性,隔离失败模式。
- 该框架包含用于生成结构化演示的“神谕求解器”,揭示关键限制:模型在无界上下文下表现更差,视觉定位能力弱于符号输入,且严重依赖显式文本反馈和目标提示来提高成功率。
- 对 12 个最先进模型的评估显示一致低表现(简单任务 46.6%,困难任务 26.0%),仅在部分可观测场景中使用探索式演示和显式反馈时性能才有所提升,突显了改进多模态智能体训练的可行路径。
引言
作者利用 VisGym——一套包含 17 个可定制长时程环境的新基准套件——系统性评估视觉-语言模型(VLM)在涵盖导航、操作和符号推理的多步视觉决策任务中的表现。先前研究缺乏跨领域的统一可控诊断,常依赖特定领域或观察性研究,未能隔离上下文长度、反馈设计或目标可见性等因素。VisGym 通过提供对难度、观测模态和反馈的精细控制,以及用于生成结构化训练数据的“神谕求解器”弥补了这一不足。实验表明,即使顶级 VLM 仍难以处理长上下文、视觉定位和状态推断——在简单和困难设置中成功率仅为 46.6% 和 26.0%——同时识别出明确目标提示和探索式演示等可操作杠杆,能在部分可观测条件下提升性能。
数据集

-
作者使用 VisGym,一套基于 Gymnasium 构建的 17 个视觉交互环境套件,训练视觉-语言模型。每个环境支持可定制的任务参数和难度级别,详细规格见表 2 和附录 B。
-
动作以函数调用形式表示(如 ('move', 2) 或 ('rotate', [90.0, 0.0, 0.0])),而非传统向量,使模型能进行组合式推理。每个任务在初始化时提供自然语言函数说明,支持零样本执行。
-
环境反馈为文本形式(如“动作执行成功”或“格式无效”),帮助模型即使在视觉感知较弱时也能锚定动作。反馈还包括步数计数器和剩余步数限制。
-
内置求解器通过应用启发式多步策略(可选加入随机性)生成多样化的演示轨迹,支持监督微调。各任务求解器设计详见附录 A。
-
系统使用统一的步进函数(算法 1,附录 D)解析、验证、执行每个动作并返回反馈,支持模块化任务创建和跨领域一致监督。
-
演示包含观察、动作和反馈序列,如逐步旋转、夹爪指令或基于坐标的移动,全部记录执行状态和步数元数据。
方法
该系统采用模块化架构,通过一系列结构化动作解决多样化的视觉推理任务。其核心是解释环境当前状态并生成动作序列以达成指定目标。流程始于视觉观测,由视觉-语言模型(VLM)处理生成原始输出,再解析为具体动作并在环境中执行。环境提供反馈,过程持续迭代直至满足终止条件。
架构包含若干关键组件。首先是环境接口,定义每个任务的状态空间和动作空间。例如在 Maze 2D 环境中,状态表示为包含智能体和目标的网格,可用动作为移动指令。动作执行模块负责将 VLM 输出解析为有效动作并应用于环境。该模块包含通用步进函数(详见算法 1),处理解析、验证和执行。函数首先检查动作格式是否有效;若解析失败,返回“格式无效”反馈;若动作名和负载有效,则调用 Apply 函数执行动作并接收环境反馈。终止和截断由 Apply 函数内判断,奖励仅在终止时计算。
VLM 作为主要决策引擎,以当前观测为输入生成动作序列。VLM 输出为原始字符串,需解析为结构化动作。例如在 Matchstick Equation 任务中,VLM 可能输出字符串 ('move', [0, 0, 2, 0]),随后解析为动作名 move 和负载 [0, 0, 2, 0]。VLM 输出并不总是正确,系统需优雅处理无效动作。求解器组件是一组预定义算法,用于为给定任务生成最优动作序列。例如在 Maze 2D 任务中,求解器使用图搜索算法找到最优路径,再转换为移动动作序列。若要求特定步数,求解器用可逆动作填充序列以满足长度要求。
任务专用求解器设计用于处理各环境独特需求。例如在 Colorization 任务中,求解器计算当前与目标色调和饱和度差异,生成旋转和饱和度调整动作序列以逼近正确颜色。在 Jigsaw 任务中,求解器可使用重排策略(计算单次置换立即重排碎片)或交换策略(生成最小交换动作序列)。在 Matchstick Equation 任务中,求解器可使用 BFS 策略寻找最短解路径、DFS 策略探索解空间,或 sos 策略先找最短路径再填充随机绕行。填充机制是系统关键特性,通过插入可逆动作生成指定长度序列。例如在 Maze 2D 任务中,求解器用随机可逆移动对(如上移后下移)填充最优路径以满足目标步数。
反馈循环对系统运行至关重要。每次动作后,环境提供反馈用于更新当前状态。VLM 利用更新后的状态生成下一动作。此过程持续直至达成目标或满足终止条件。系统设计为能容错无效动作,步进函数可处理“无效动作”反馈并继续流程。视觉和文本表示用于向 VLM 提供决策所需信息。例如在 Maze 2D 任务中,视觉表示显示智能体位置和迷宫结构,文本表示提供基于网格的迷宫描述。任务专用指令为 VLM 提供各任务规则和目标,确保生成的动作有效且相关。
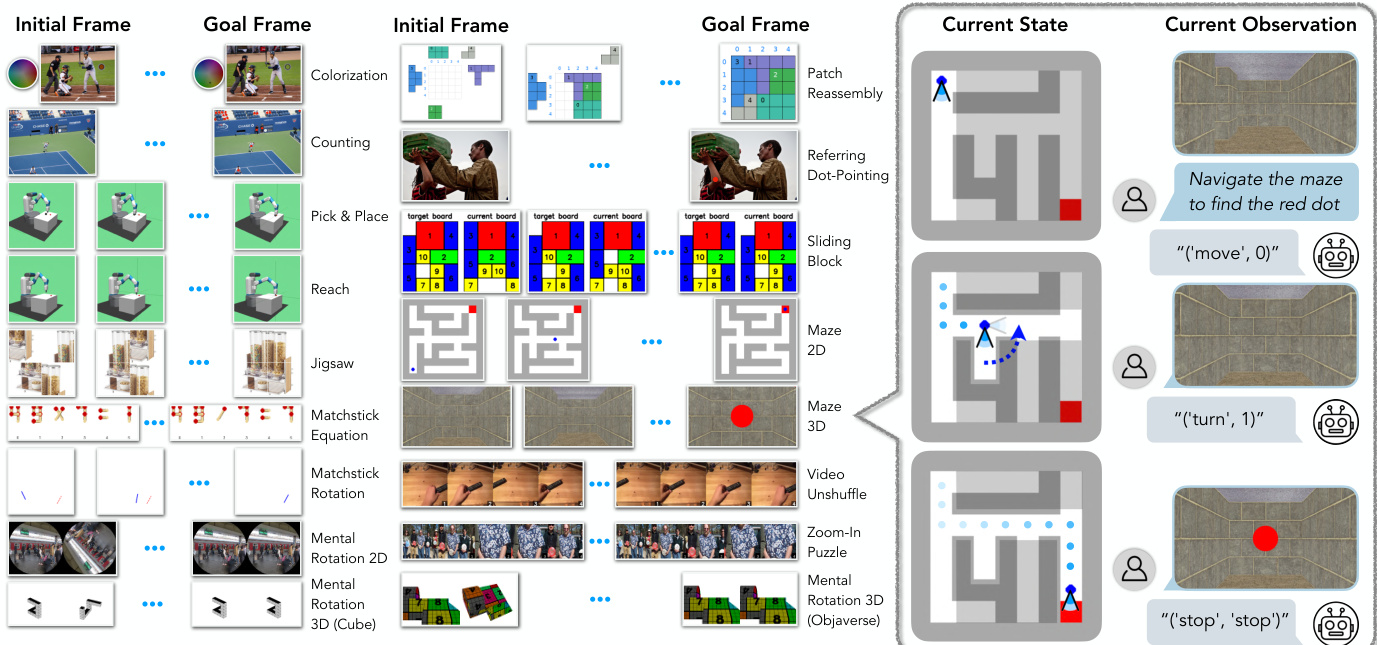
实验
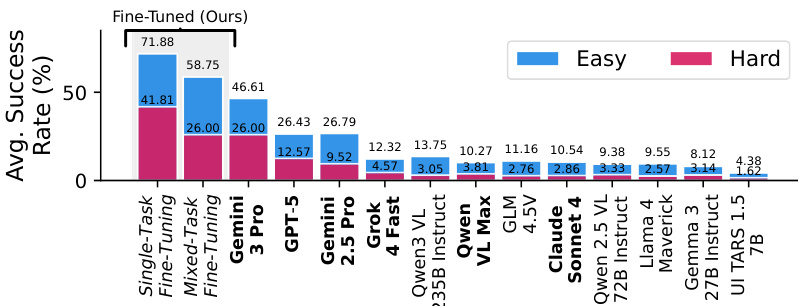
- 在 VisGym 上评估了 12 个 VLM(专有、开源权重、GUI 专用),每任务 70 个回合;最佳模型(Gemini-3-Pro)在简单设置中达成 46.61%,困难设置中 26.00%,揭示前沿模型的重大挑战。
- 观察到模型专精现象:GPT-5 在长上下文任务(如 Matchstick Rotation)中表现优异,Gemini 2.5 Pro 在精细视觉感知(如 Jigsaw、Maze 2D)中突出,Qwen-3-VL 在物体定位(Referring Dot-Pointing)中领先。
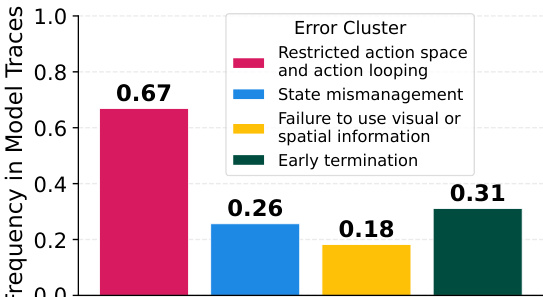
- 常见失败模式:动作循环(60%+ 轨迹)、状态管理不当、过早终止、忽略视觉/空间线索;较弱模型(如 UI-Tars 1.5-7B)显示 87% 动作循环。
- 上下文截断提升性能:限制历史至约 4 步优于完整历史;任务特异性提升(如 Gemini 2.5 Pro 在 Maze2D、GPT-5 在 Matchstick Rotation)。
- ASCII 表示法使 GPT-5 在多数任务中性能提升 3–4 倍,表明视觉定位是其主要瓶颈;Gemini 2.5 Pro 表现混合,开源模型在两种模态中均表现不佳。
- 移除文本反馈一致降低性能,表明 VLM 严重依赖文本提示而非视觉转换进行动作验证。
- 提前提供目标图像提升各任务表现,但 GPT-5 和 Gemini 2.5 Pro 在 Zoom-In Puzzle 和 Matchstick Equation 上表现不佳,因视觉误判(同一性检查错误率分别为 80% 和 57%)。
- 在求解器生成轨迹上监督微调(Qwen2.5-VL-7B)达到最先进结果;Qwen3-VL-8B 在困难任务泛化能力上接近 Qwen2.5-VL 的两倍。
- 同时微调视觉编码器和 LLM 提升性能最多;LLM 微调贡献更大,尤其在部分可观测或动态未知任务中。
- 信息揭示式演示(如 Matchstick Rotation 中的结构化探索)使成功率从 32.9% 提升至 70.0%;提升源于状态消歧行为,而非轨迹长度。
作者使用受控实验评估演示设计对多步视觉任务中模型性能的影响。结果表明,结构化演示揭示动作幅度与感知效果的关系——具体而言,两个单位步长后接最终对齐动作——显著提高成功率(0.700),对比三个随机动作(0.329)。这表明训练数据中的信息揭示行为能显著提升模型性能。

作者使用 VisGym 评估视觉-语言模型,表明即使表现最佳的前沿模型 Gemini-3-Pro,在简单设置中仅达成 46.61% 成功率,困难设置中为 26.00%。结果表明模型在长上下文视觉交互中表现显著困难,常因动作循环、状态管理不当、过早终止和忽略视觉线索而失败,且随着任务难度增加性能急剧下降。
作者使用失败分析流程识别模型轨迹中的常见失败模式,结果表明受限动作空间和动作循环是最频繁错误,出现在 67% 的轨迹中,其次是状态管理不当、未能使用视觉或空间信息,以及过早终止。
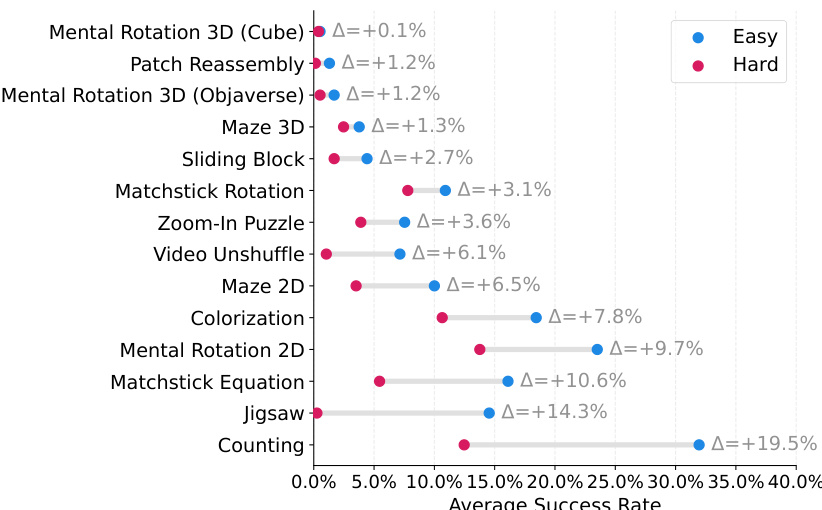
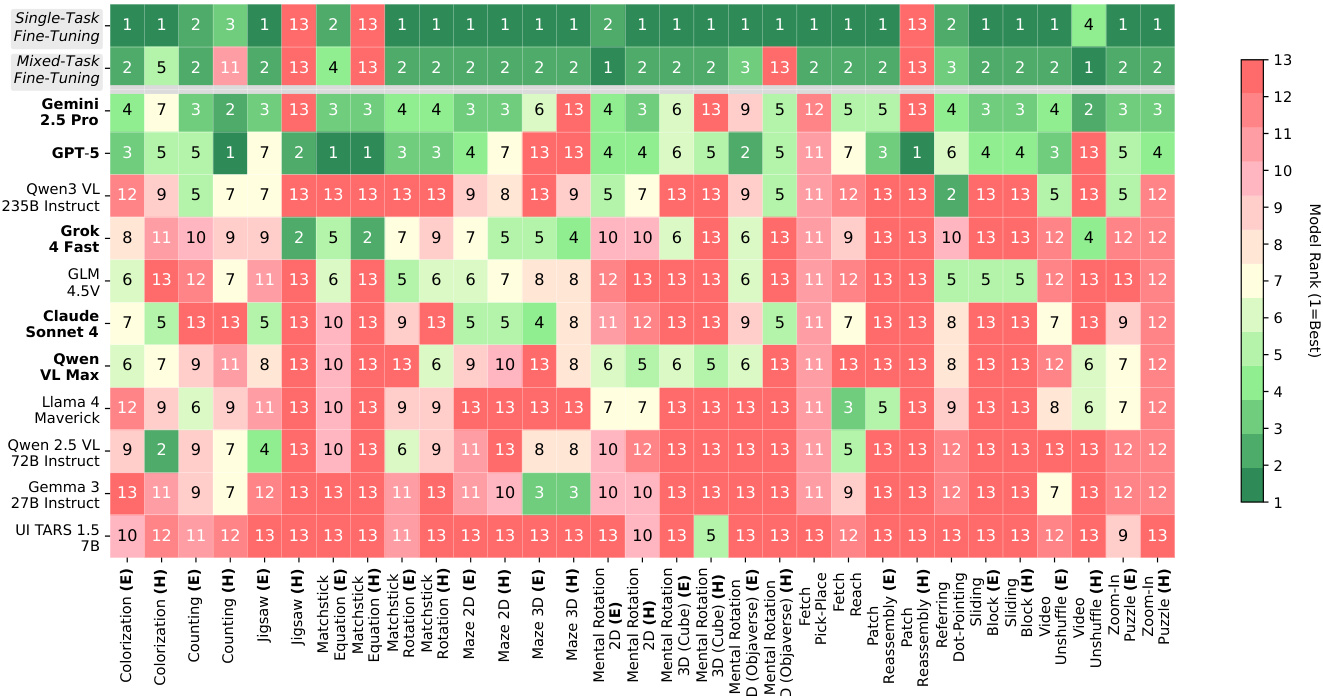
作者使用表格呈现各种视觉-语言模型在 VisGym 基准任务集上的表现,结果按任务难度(简单和困难)及模型微调方法(单任务和混合任务)分类。表格显示,微调模型(尤其是使用混合任务微调的模型)在多数任务中成功率显著高于未训练模型,表现最佳模型常在简单设置中排名第一。结果表明,许多任务在简单与困难设置间存在显著性能差距,且单任务微调模型通常优于混合任务训练模型,表明任务特定适应有益。
作者在 VisGym 上使用监督微调提升模型性能,微调模型在多数任务中达到最先进结果。柱状图显示单任务微调获得最高平均成功率,在简单设置中达 71.88%,困难设置中达 41.81%,显著优于所有其他模型。