Command Palette
Search for a command to run...
SWE-Pruner:面向编码Agent的自适应上下文剪枝
SWE-Pruner:面向编码Agent的自适应上下文剪枝
Yuhang Wang Yuling Shi Mo Yang Rongrui Zhang Shilin He Heng Lian Yuting Chen Siyu Ye Kai Cai Xiaodong Gu
摘要
大型语言模型(LLM)代理在软件开发任务中展现出卓越的能力,但其性能常受限于长交互上下文带来的高API成本与延迟问题。尽管诸如LongLLMLingua等上下文压缩方法相继提出以应对这一挑战,但这些方法通常依赖于固定的评估指标(如PPL),忽视了代码理解任务的特定性,因而往往破坏代码的语法与逻辑结构,难以保留关键的实现细节。为此,本文提出SWE-Pruner——一种专为编程代理设计的自适应上下文剪枝框架。受人类程序员在开发与调试过程中“有选择性地快速浏览”源代码行为的启发,SWE-Pruner实现了面向任务的自适应上下文剪枝。在给定当前任务的前提下,代理会明确设定一个目标(例如“聚焦于错误处理”)作为提示,以指导剪枝的重点方向。一个轻量级神经浏览模块(仅0.6B参数)被训练用于根据该目标动态筛选上下文中的相关代码行。在四个基准测试及多种模型上的评估结果表明,SWE-Pruner在不同场景下均表现出色:在SWE-Bench Verified等代理任务中实现23%至54%的token压缩率;在LongCodeQA等单轮任务中最高实现14.84倍的压缩比,同时对模型性能的影响极小。
一句话总结
来自上海交通大学、中山大学和抖音集团的研究人员提出了 SWE-Pruner,这是一种面向任务的上下文剪枝框架,专为代码代理设计,使用轻量级神经略读器保留关键代码细节,在 SWE-Bench Verified 等基准测试中减少 23–54% 的 token 数量,同时性能损失极小。
主要贡献
- SWE-Pruner 引入了一种面向任务、按行级别的上下文剪枝框架,用于代码代理,通过根据“关注错误处理”等明确的自然语言目标动态保留语法和逻辑关键代码,解决“上下文墙”问题。
- 它采用一个仅 0.6B 参数的轻量级神经略读器,基于 61K 个合成样本训练,可自适应选择相关行,实现高效、目标导向的压缩,无需针对特定仓库调优,也不会破坏代码结构。
- 在包括 SWE-Bench Verified 和 LongCodeQA 在内的四个基准测试中评估,它在多轮代理任务中实现 23–54% 的 token 减少,在单轮任务中最高实现 14.84 倍压缩,性能损失极小,同时最多减少 26% 的代理交互轮次。
引言
作者利用大语言模型代理在软件工程中日益增长的应用,指出长上下文窗口会导致成本高昂且嘈杂的交互,从而降低性能。先前的上下文压缩方法——为自然语言或静态代码任务设计——无法保留语法结构、忽略任务特定目标,且缺乏在多轮代理工作流中的适应性。SWE-Pruner 通过引入轻量级、目标导向的剪枝模型解决此问题,该模型根据代理当前目标动态选择相关代码行,在保留结构的同时,在代理任务中实现 23–54% 的 token 减少,在单轮任务中最高实现 14.8 倍压缩,且性能损失极小。
数据集

-
作者使用 GitHub Code 2025 —— 一个包含 150 多万个仓库的精选语料库 —— 作为基础来源,选择高星(成熟)和 2025 年代(新兴)仓库,以平衡质量和新颖性。移除二进制文件、构建产物和压缩代码,保留干净的多语言源代码。
-
从中采样 20 万个代码片段,覆盖 195,370 个文件和 5,945 个仓库,使用 Qwen3-Coder-30B-A3B-Instruct(温度 0.7,top-p 0.9)生成查询和行级保留掩码。任务在 9 种代理类型(如代码总结、调试、优化)、3 种片段长度和 3 种相关性级别之间平衡。
-
使用 Qwen3-Next-80B-A3B-Thinking 作为大语言模型评判器进行质量过滤,仅保留约 1/6 的样本(最终训练样本 61,184 个),依据推理质量、标注一致性和任务对齐性。平均查询长度为 39.98 词(中位数 24),每个查询平均 291.69 字符(中位数 169)。
-
该数据集用于训练神经略读器以进行上下文剪枝;推理时,模型处理与任务特定查询对齐的行级保留掩码的代码片段。训练期间不应用裁剪,但推理可能涉及 50 token 重叠和 500 字符最小值的分块,通过本地剪枝服务使用 0.5 阈值。
-
元数据包括任务类型、片段长度、相关性级别和行级保留标签。该流程确保代理式编码任务的多样化、真实监督,生成和过滤提示详见论文附录。
方法
SWE-Pruner 框架作为中间件,位于编码代理与其环境之间,拦截来自文件操作的原始上下文,并向代理交付剪枝后相关的子集。交互工作流始于编码代理向环境发出文件读取命令(如 grep 或 cat)。SWE-Pruner 捕获通常庞大且嘈杂的原始上下文。同时,代理生成“目标提示”——对其当前信息需求的自然语言描述,如“关注 InheritDocstrings 中的 MRO 解析逻辑”。该提示与原始上下文一起输入轻量级略读器进行处理。略读器评估上下文并返回剪枝后的上下文,然后传递回代理以进行进一步推理。此过程使代理能够专注于相关代码段,同时最小化噪声和计算开销。
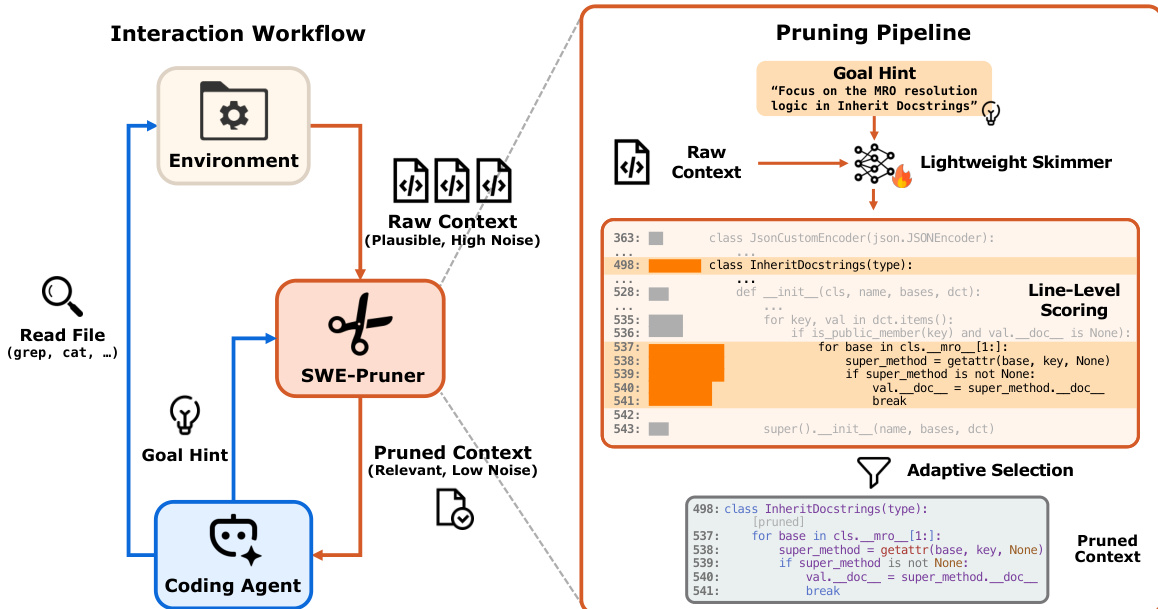
SWE-Pruner 的核心是轻量级略读器,基于 Qwen3-Reranker-0.6B 骨干网络构建。略读器处理原始上下文和目标提示,为每个 token 计算相关性分数。模型架构设计为同时执行两项任务:行级剪枝和文档级重排序。对于剪枝,模型使用神经评分函数 F(q,xi∣C;θ) 为每个 token xi 计算相关性分数 si,其中 q 是目标提示,C 是完整上下文。这些 token 分数通过平均每行内所有 token 的分数聚合到行级,得到行级相关性分数 sˉj。此聚合确保行基于整体相关性评估,而非被少数高分 token 主导,保持语义连贯性。
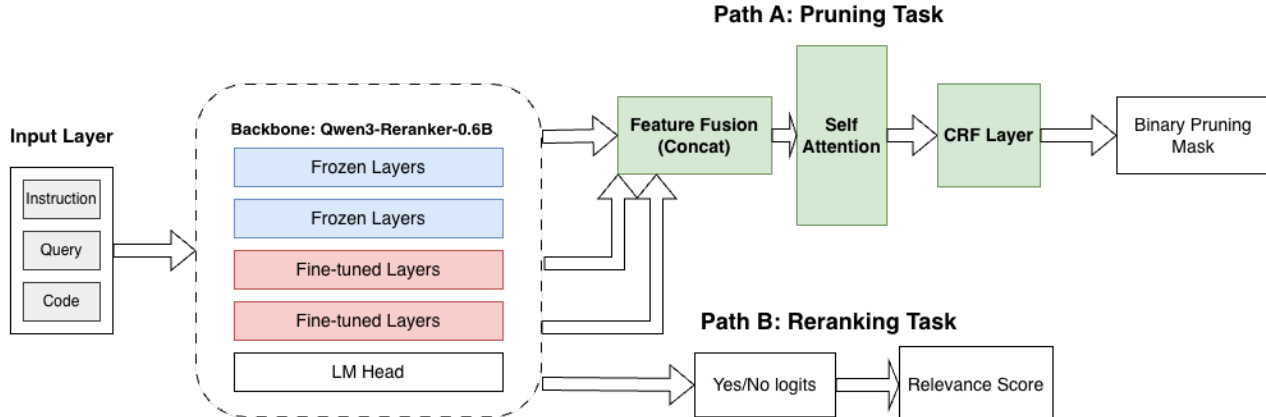
剪枝任务被建模为使用条件随机场(CRF)的结构化序列标注问题。CRF 层计算发射和转移势能,以建模相邻行级决策之间的依赖关系。发射代表每个 token 的局部置信度,而转移捕获相邻决策之间的依赖关系。这种结构化公式鼓励尊重语法边界的连贯剪枝模式。另一方面,重排序任务重用 Qwen3-Reranker 的原始语言建模头,为整个文档生成标量相关性分数。最终目标结合两项任务,使用平衡权重 λ,确保模型可在单次前向传递中同时执行细粒度剪枝和粗粒度相关性评估。模型使用教师-学生范式训练,其中教师大语言模型合成面向任务的查询和行级注释,使略读器能够从高质量、多样化的训练数据中学习。
实验
- 在 SWE-Bench Verified(500 个 GitHub 问题)和 SWE-QA(3 个仓库)上评估 SWE-Pruner,集成 Mini SWE Agent 和 OpenHands,使用 Claude Sonnet 4.5 和 GLM-4.6;在 SWE-Bench 上实现 23–38% 的 token 减少,在 SWE-QA 上实现 29–54% 的减少,成功率下降 <1%。
- 在 SWE-Bench Verified 上,SWE-Pruner 将交互轮次减少 18–26%(例如,GLM-4.6 实现 44.2% 的 token 减少和 34.6% 的轮次减少),加快任务完成速度并降低 API 成本。
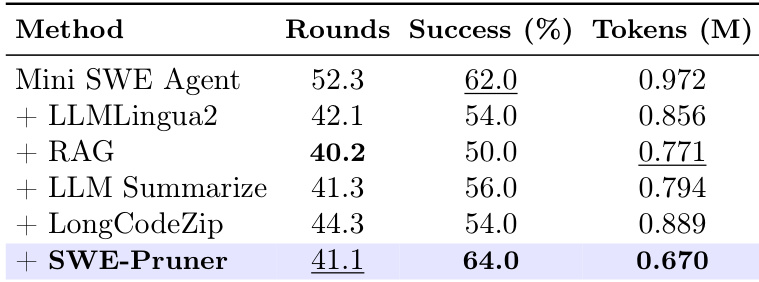
- 在 SWE-Bench 上优于基线方法(LLMLingua-2、RAG、LLM Summarize):实现 64% 的成功率,token 数减少 31%,而基线为 62%;基于 token 的方法因破坏语法而性能下降。
- 在单轮任务(长代码补全/QA)中,SWE-Pruner 在 8 倍约束下实现最高 14.84 倍压缩,同时保持 58.71% 的准确率(QA)和 57.58 的 ES(补全),优于 Selective-Context 和 LongCodeZip。
- 保持 87.3% 的 AST 正确率,而基于 token 的方法接近零,通过行级、查询感知的剪枝保留语法结构。
- 引入可忽略的延迟(8K token 下 TTFT <100ms),通过 23–54% 的 token 节省和减少轮次摊销;案例研究表明,在失败到成功场景中 token 减少 83.3%,在成功轨迹中峰值提示长度减少 30.2%。
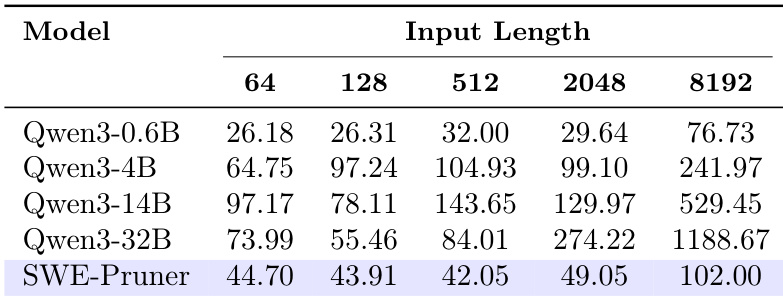
作者使用 SWE-Pruner 评估其在不同模型大小和输入长度下的效率,测量首 token 延迟。结果表明,SWE-Pruner 始终保持低延迟,即使在 8192 token 下也低于 100 毫秒,而 Qwen3-32B 等更大模型表现出显著更高且快速增长的延迟。
结果表明,SWE-Pruner 在将 token 消耗减少至 0.670 百万的同时,实现最高的成功率 64.0%,在任务性能和压缩效率方面均优于所有基线方法。该方法相比 LLMingua2、RAG 和 LongCodeZip 等替代方案,以显著更少的交互轮次和 token 数维持高成功率。
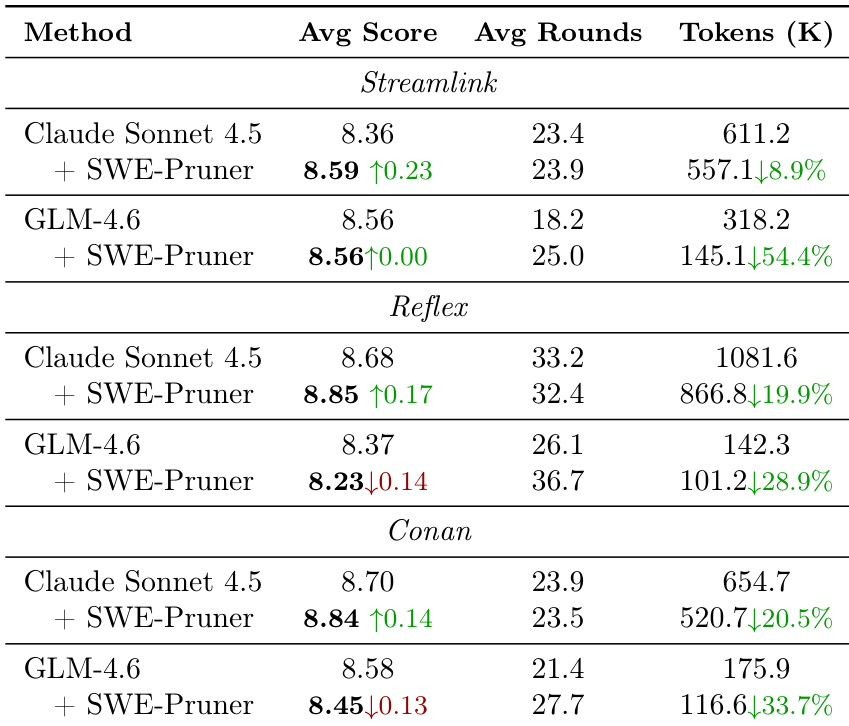
作者使用 SWE-Pruner 在三个仓库的 SWE-QA 任务中减少代码代理的 token 消耗,实现 28.9% 至 54.4% 的 token 减少,同时维持或略微提高平均分数并减少交互轮次。结果表明,SWE-Pruner 有效剪枝无关上下文而不降低任务性能,实现更高效的代理行为。
作者使用 SWE-Pruner 在文件读取过程中过滤冗余上下文以减少代码代理的 token 消耗。结果表明,剪枝器将 token 使用量减少 83.3%,并将步骤数从 164 减少到 56,使代理在因资源耗尽而失败的基线情况下完成任务。

作者使用 SWE-Pruner 在文件读取过程中过滤冗余上下文以减少代码代理的 token 消耗。结果表明,剪枝器将 token 使用量减少 6%,同时增加读取操作次数并减少执行步骤,表明更聚焦的探索和更少的冗余处理。
