Command Palette
Search for a command to run...
LongCat-Flash-Thinking-2601 技术报告
LongCat-Flash-Thinking-2601 技术报告
摘要
我们推出 LongCat-Flash-Thinking-2601,这是一个参数规模达5600亿的开源混合专家(Mixture-of-Experts, MoE)推理模型,具备卓越的智能体式推理能力。在涵盖智能体搜索、智能体工具调用以及工具融合推理等多个领域的智能体基准测试中,LongCat-Flash-Thinking-2601 在开源模型中达到了当前最先进的性能水平。除了在基准测试中的优异表现,该模型在复杂工具交互任务上展现出强大的泛化能力,并在噪声干扰的现实环境条件下保持稳健的行为表现。其先进性能源于一个统一的训练框架,该框架融合了领域并行专家训练与后续的专家融合机制,同时实现了从预训练到后训练阶段的数据构建、环境设计、算法优化与基础设施的端到端协同设计。特别地,模型在复杂工具使用场景中表现出的强泛化能力,得益于我们对环境扩展(environment scaling)的深入探索以及基于原则的任务构建方法。为优化长尾分布、数据偏斜条件下的生成任务,以及多轮智能体交互过程中的稳定性,并支持在超过10,000个环境、覆盖20多个不同领域的大规模多环境训练中实现稳定高效的训练,我们系统性地扩展了异步强化学习框架 DORA,显著提升了大规模多环境训练的稳定性与效率。此外,考虑到现实世界任务 inherently 具有噪声特性,我们对真实环境中的噪声模式进行了系统性分析与分解,并设计了针对性的训练策略,将这些现实中的不完美因素显式地融入训练过程,从而显著增强了模型在真实应用场景下的鲁棒性。为进一步提升复杂推理任务的表现,我们引入“深度思考”(Heavy Thinking)模式,通过在推理过程中协同扩展推理的深度与广度,实现高效的测试时扩展(test-time scaling),显著增强模型在高难度推理任务中的表现能力。
一句话总结
美团LongCat团队推出LongCat-Flash-Thinking-2601,一款560B参数的MoE模型,通过统一的域并行训练与抗噪设计,在代理式推理任务中表现出色,支持在10,000+环境中稳健使用工具,并通过“Heavy Thinking”模式增强实际应用性能。
主要贡献
- LongCat-Flash-Thinking-2601引入统一训练框架,结合域并行专家训练与融合,通过数据、环境与基础设施的端到端协同设计,在BrowseComp(73.1%)和RWSearch(77.7%)等代理式基准测试中达到开源领先水平。
- 模型采用扩展的异步强化学习系统DORA,在20+领域、超10,000个环境中稳定训练,同时将真实噪声模式注入训练过程,提升在嘈杂、分布外场景中的鲁棒性。
- 模型支持“Heavy Thinking”测试时扩展模式,通过并行思维同时扩展推理深度与宽度,无需额外训练即可增强复杂推理性能,并开源以支持未来代理系统研究。
引言
作者采用5600亿参数的混合专家模型推进代理式推理——即通过与外部环境(如工具或搜索系统)自适应交互解决复杂任务的能力。此前模型在长时程、多领域交互和真实噪声环境下表现不足,常缺乏可扩展的训练基础设施或对不完美环境的鲁棒性。其主要贡献是统一训练流水线,结合域并行专家训练、自动化多领域环境扩展与基于课程的强化学习注入噪声,以提升泛化能力。同时引入“Heavy Thinking”模式,在测试时通过并行扩展推理深度与宽度提升性能,实现开源代理式基准测试的领先结果。
数据集

-
作者采用双环境框架进行代理式训练:一个用于编码(可执行代码沙盒),另一个用于通用工具使用(领域特定工具图),二者均设计为支持可扩展、可复现和多样化的交互模式。
-
对于代码沙盒,他们构建高吞吐系统,标准化终端工具(搜索、文件I/O、Shell执行),并通过异步预配调度数千个并发沙盒,消除训练期间的启动开销。
-
对于工具使用环境,他们通过自动化流水线构建20多个领域特定工具图(每个含60+工具),将高层领域规范转换为可执行工具-数据库对,经单元测试和调试代理验证(成功率95%)。
-
每个环境从采样种子工具链开始,通过受控的BFS式图扩展保持数据库一致性与可执行正确性,避免级联依赖失败。
-
环境可通过基于结构复杂度、剩余节点数和求解难度添加新种子链进一步复杂化——并设有回退机制,确保每个环境至少包含20个工具。
-
冷启动训练数据来源于真实平台(用于编码/数学)或合成(用于搜索/工具使用),并严格过滤:可执行性检查、动作级剪枝和基于评分标准的验证。
-
对于通用推理,他们使用K-Center-Greedy选择结合滑动窗口困惑度,优先选择暴露推理缺口的样本,下采样21万高质量轨迹。
-
对于代理式编码,轨迹需满足完整可执行性、功能正确性和长时程推理——早期步骤被压缩以保留上下文,避免长度惩罚。
-
对于代理式搜索,合成轨迹强制多步证据收集、显式条件验证和抗捷径能力;移除简单案例。
-
对于代理式工具使用,他们在33个领域生成结构、长度可变且具多种有效解的任务;训练中通过回合级损失掩码排除失败或格式错误动作。
-
所有合成任务包含三部分:任务描述、用户画像和评估标准——通过一致性检查验证以确保可靠监督并拒绝不完整轨迹。
方法
作者采用多阶段训练框架,旨在扩展大语言模型的代理式推理能力,从预训练阶段开始,扩展LongCat-Flash-Chat方案以纳入结构化代理式数据。该阶段解决长上下文建模效率和真实代理式轨迹稀缺的双重挑战。为管理长上下文需求,采用分阶段中等训练程序,逐步增加上下文长度,分配特定token预算至32K、128K和256K阶段。模型在强化学习前接触中等规模代理式数据以建立基础行为。为克服高质量代理式轨迹稀缺问题,构建混合数据合成流水线,从非结构化文本和可执行环境中提取数据。文本驱动合成从大规模语料库中挖掘隐式程序知识,通过文本过滤、工具提取和精炼将抽象工作流转化为显式多轮用户-代理交互。该过程通过分解式增强进一步优化,包括工具分解(迭代将参数隐藏到环境中)和推理分解(生成替代动作候选以将轨迹转化为多步决策过程)。环境驱动合成通过轻量级Python环境实现工具集并建模工具依赖为有向图,从图中采样有效工具执行路径,反向合成并验证系统提示,确保生成轨迹的正确性。还引入专门的规划中心数据增强策略,通过问题分解和候选选择将现有轨迹转化为结构化决策过程。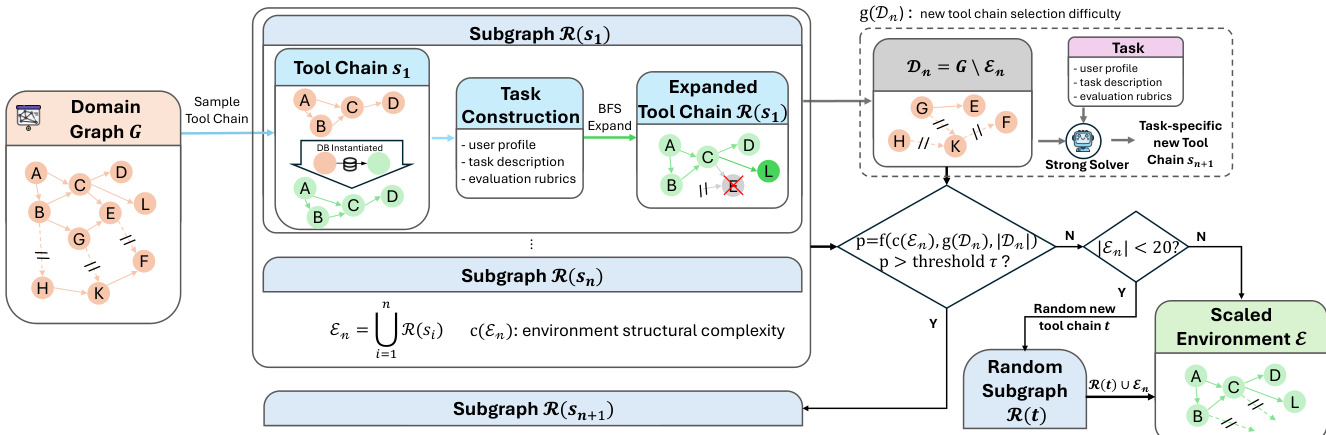
预训练后,模型进入可扩展强化学习(RL)阶段,以激发更强的推理能力。该阶段基于统一多领域后训练流水线,首先在共享框架下训练领域专用专家模型,然后整合为单一通用模型。RL框架旨在应对代理式训练的独特挑战,包括可扩展环境构建、高质量冷启动数据、良好校准的任务集,以及支持高吞吐、异步、长尾多轮 rollout 的专用基础设施需求。作者扩展其多版本异步训练系统DORA以支持此设置。系统核心为生产者-消费者架构(如框架图所示),包含RolloutManager、SampleQueue和Trainer,运行于不同节点并通过远程过程调用(RPC)协调。该架构实现全流式异步流水线,消除批处理障碍,最小化多轮 rollout 期间设备闲置。为解决长尾生成问题,系统支持多版本异步训练,不同模型版本的轨迹完成后立即入队,Trainer在条件满足时即可启动训练。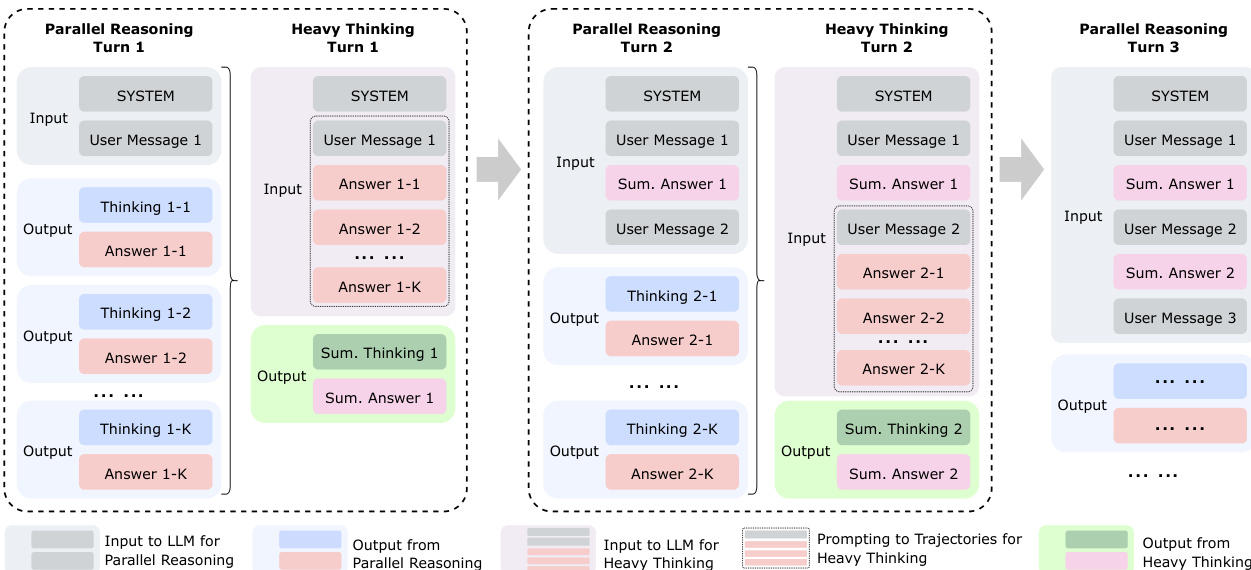
为扩展至大规模代理式训练,系统将RolloutManager分解为用于全局控制的Lightweight-RolloutManager和用于数据并行管理虚拟 rollout 组的多个RolloutControllers。该设计结合扩展的PyTorch RPC框架(提供CPU闲置感知远程函数调用),实现跨数千加速器高效部署大规模环境。对于LongCat-Flash-Thinking-2601等大模型,关键高效生成技术为Prefill-Decode(PD)解耦,将预取和解码工作负载分离至不同设备组,防止解码执行图被预取工作负载中断,保持多轮 rollout 期间高吞吐。为缓解KV缓存传输与重计算相关挑战,系统将KV缓存块分块异步传输,并引入驻留CPU的KV缓存,根据需要动态交换块,消除因设备内存不足导致的重计算开销。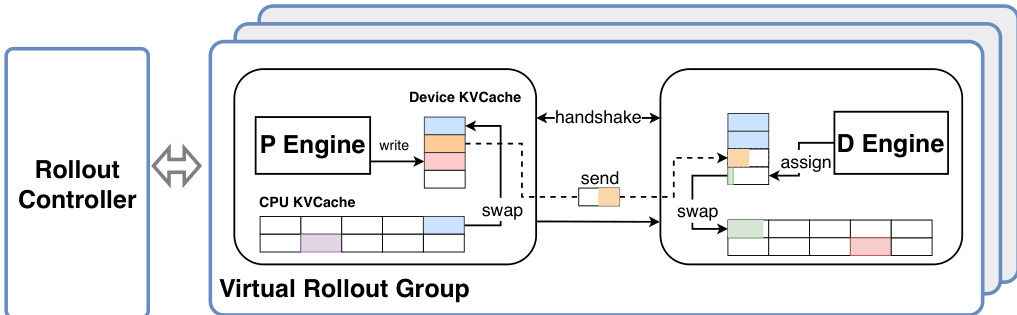
RL训练策略设计为稳定、高效且可扩展。作者采用Group Sequence Policy Optimization(GSPO)作为训练目标,为长时程代理式轨迹提供更稳定的序列级优化。采用课程学习策略,沿两个轴逐步增加任务难度:任务难度(由模型通过率量化)和能力要求(如基础工具调用或多步规划)。这使模型先习得可复用技能,再组合解决复杂问题。每个训练批次内应用动态预算分配,优先分配更高学习价值的任务,使用动态价值函数基于模型实时训练状态估算任务价值。该策略适应模型能力演进,确保最有信息量的任务获得更多 rollout 预算。引入自我验证作为辅助任务,模型评估自身策略轨迹,加速优化并提升生成性能。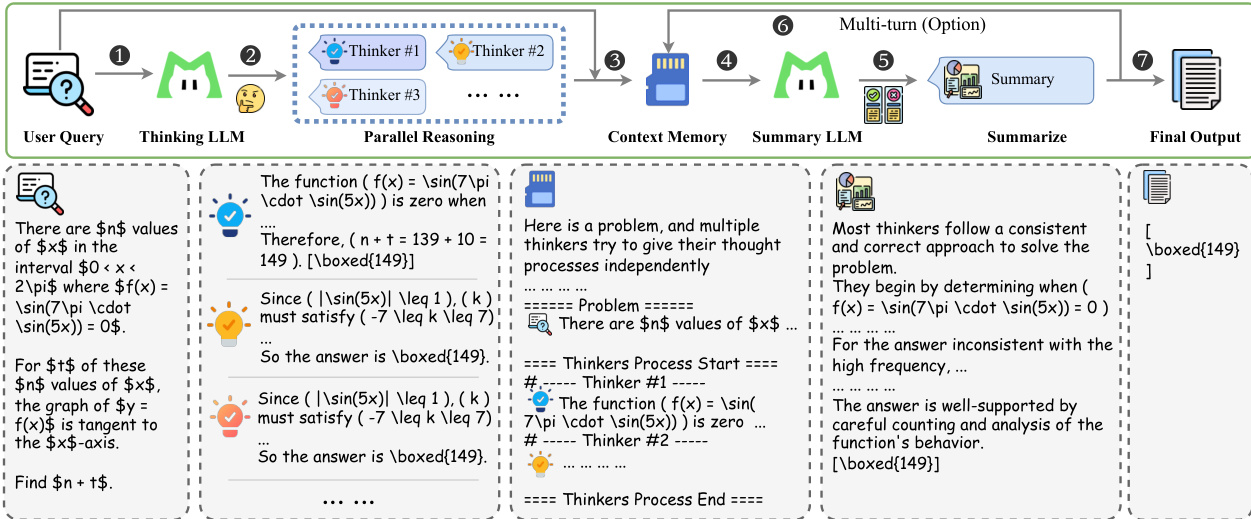
在代理式场景中,有效上下文管理至关重要。作者设计混合上下文管理策略,结合摘要式与丢弃式方法。当上下文窗口超过80K token预设限制时,模型执行摘要式压缩,将历史工具调用结果浓缩为简洁摘要。当交互超过最大回合数时,触发丢弃全部重置,使用初始化系统和用户提示重启生成。该混合策略根据上下文窗口和交互回合约束动态切换压缩与重置,在保留关键推理上下文与控制计算开销间取得良好平衡。对于扩展环境训练,采用多领域环境训练策略,在每个训练批次内联合优化多个领域。为保持训练稳定并防止领域不平衡,为不同数据类型和领域配置独立过采样比例,确保挑战性或低吞吐领域贡献足够样本而不阻塞流水线。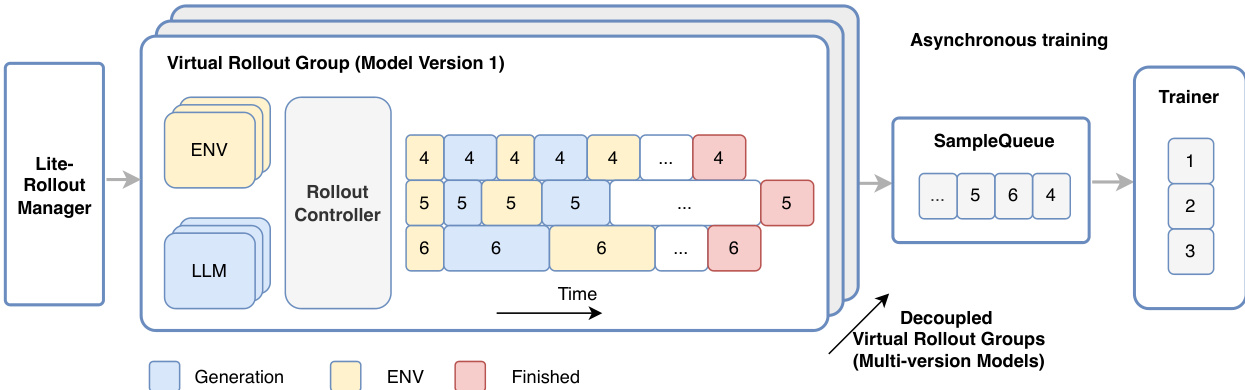
为提升鲁棒性,训练过程显式注入环境不完美性(如指令噪声和工具噪声),采用课程策略逐步增加噪声难度,确保模型在非理想条件下习得弹性行为。最后,作者提出测试时扩展框架“heavy thinking”,将计算分解为两阶段:并行推理与重思考。第一阶段,思考模型并行生成多个候选推理轨迹。第二阶段,摘要模型对这些轨迹进行反思推理,合成最终决策。该框架由上下文记忆模块存储消息历史,并通过特定提示模板组织并行轨迹供摘要模型使用。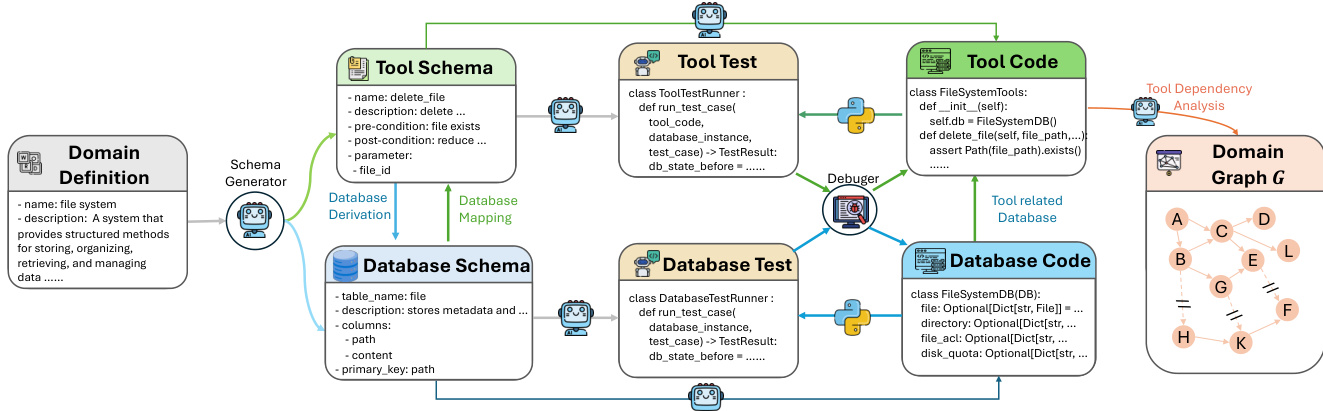
实验
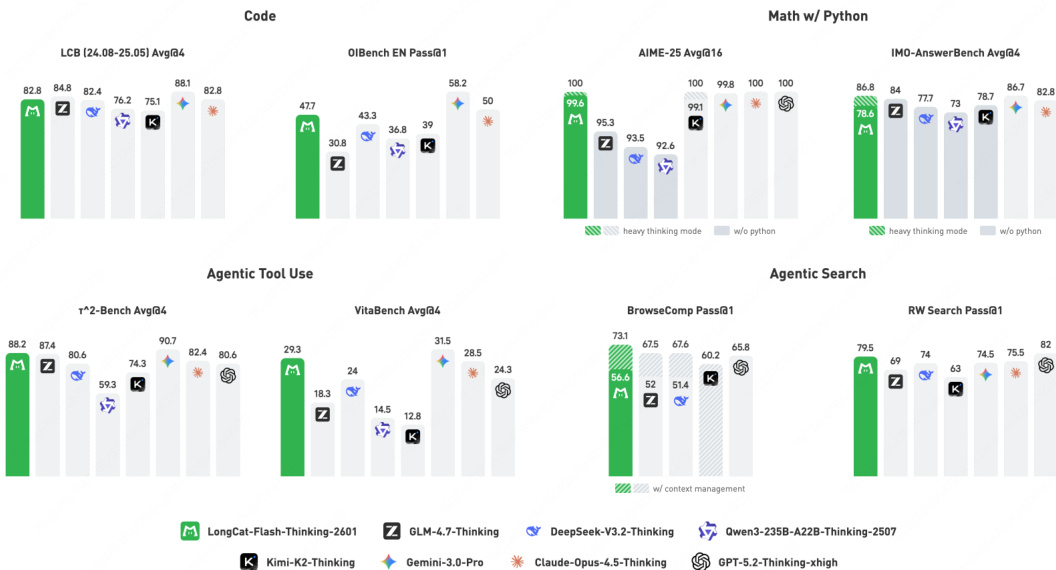
- 数学推理:在AIME-2025上获得满分,IMO-AnswerBench得分为86.8,AMO-Bench(EN/zh)达到开源SOTA,重模式下媲美顶级闭源模型。
- 代理式搜索:在BrowseComp(73.1)和BrowseComp-ZH(77.7)上设置SOTA(含上下文管理);RWSearch得分为79.5,仅次于GPT-5.2-Thinking。
- 代理式工具使用:在τ²-Bench、VitaBench和Random Complex Tasks上达到开源SOTA,展现强噪声鲁棒性和泛化能力。
- 通用问答:HLE文本子集得分为25.2,GPQA-Diamond(重模式)得分为85.2,接近开源SOTA。
- 编码:OIBench排名开源第一,OJBench排名第二,在LiveCodeBench和SWE-bench Verified上具竞争力;相比GLM-4.7,每题使用45K vs 57K tokens表现更优。
- 上下文管理:BrowseComp在80K token摘要阈值下性能最优(66.58% Pass@1)。
结果表明,LongCat-Flash-Thinking-2601在数学推理基准测试中达到最先进水平,包括AIME-25满分和IMO-AnswerBench领先得分,同时在代理式搜索、工具使用、通用问答和编码多项基准测试中展现强大能力。该模型在工具集成推理和代理式任务中持续超越或媲美领先开源与闭源模型,在标准和噪声增强基准测试中均表现优异。

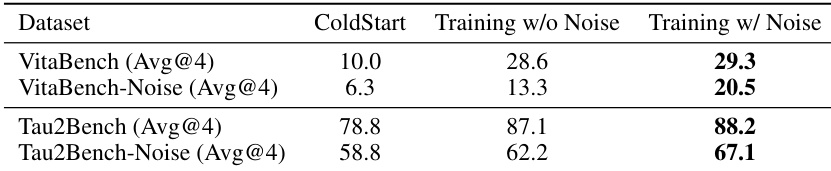
结果表明,带噪声训练在VitaBench和τ²-Bench上均提升性能,尤其在τ²-Bench上,分数从78.8提升至88.2。在噪声增强版本基准测试中性能亦提升,表明鲁棒性增强。
作者使用全面基准测试集评估LongCat-Flash-Thinking-2601在数学推理、代理式搜索、工具使用、通用推理和编码方面的能力。结果表明,LongCat-Flash-Thinking-2601在多数任务上达到开源模型最先进水平,尤其在数学推理和代理式搜索中表现突出,同时在工具集成推理中展现强大泛化与鲁棒性。