Command Palette
Search for a command to run...
Memory-V2V:通过记忆增强视频到视频扩散模型
Memory-V2V:通过记忆增强视频到视频扩散模型
Dohun Lee Chun-Hao Paul Huang Xuelin Chen Jong Chul Ye Duygu Ceylan Hyeonho Jeong
摘要
近期基于扩散机制的视频到视频生成模型在修改用户提供的视频内容方面取得了显著进展,能够实现外观、运动或摄像机运动等方面的编辑。然而,在现实场景中的视频编辑通常是一个迭代过程,用户需通过多轮交互不断优化结果。在多轮编辑的设定下,现有视频编辑方法难以保证连续编辑之间的跨一致性。本文首次系统性地提出了多轮视频编辑中跨一致性问题的解决方案,并提出 Memory-V2V——一种简单而高效的框架,通过引入显式记忆机制对现有视频到视频模型进行增强。Memory-V2V 利用外部缓存中已编辑过的视频作为记忆库,结合精准的检索策略与动态标记化方法,使当前编辑步骤能够基于先前的编辑结果进行条件化建模。为进一步减少冗余信息并降低计算开销,我们在 DiT 主干网络中引入了一种可学习的标记压缩模块,该模块能够在保留关键视觉线索的同时压缩冗余的条件标记,整体实现约 30% 的推理加速。我们在具有挑战性的任务上对 Memory-V2V 进行了验证,包括视频新视角合成与文本条件下的长视频编辑。大量实验表明,Memory-V2V 在保持或提升任务特定性能的同时,显著提升了多轮编辑结果之间的跨一致性,且计算开销极低。项目主页:https://dohunlee1.github.io/MemoryV2V
一句话总结
Adobe Research 与 KAIST 的研究人员提出了 Memory-V2V,这是一种通过显式记忆增强视频到视频扩散模型的框架,支持迭代编辑。该框架采用动态分词和可学习压缩器,在保持跨编辑一致性的同时,将新视角合成和长视频编辑等任务的推理速度提升 30%。
主要贡献
- Memory-V2V 提出了首个支持跨编辑一致性的多轮视频编辑框架,通过为扩散模型添加显式视觉记忆,解决用户在多次交互中逐步优化输出的实际需求,确保连续编辑间的视觉一致性。
- 该方法在 DiT 主干中引入任务特定检索、动态分词和可学习分词压缩器,使当前编辑能以先前结果为条件,同时通过自适应压缩不相关分词将计算开销降低 30%。
- 在视频新视角合成和文本引导的长视频编辑任务上评估,Memory-V2V 在跨迭代一致性上超越现有最先进基线,同时保持或提升任务特定质量,且额外成本极低。
引言
作者利用现有的视频到视频扩散模型,解决用户在多轮交互中逐步优化输出的实际视频编辑需求。以往方法在合成新视角或编辑长视频时,无法保持跨编辑的一致性,因为缺乏回忆并匹配先前生成结果的机制。Memory-V2V 通过从外部缓存中检索相关历史编辑、基于相关性动态分词,并在 DiT 主干中压缩冗余分词,将计算量减少 30% 的同时保持视觉保真度。这使得多轮编辑在不牺牲速度或质量的前提下实现一致性,推动了实用、具备记忆能力的视频工具的发展。
数据集

-
作者通过扩展 Señorita-2M 中的短片段构建长视频编辑数据集,该数据集提供 33 帧的稳定局部编辑对。每个片段通过 FramePack 扩展 200 帧,形成 233 帧序列用于训练。
-
扩展的 200 帧在训练期间作为记忆。每轮迭代中,模型从该扩展部分随机采样片段,以历史上下文为条件,实现长时域编辑。
-
对于位置编码,他们使用 RoPE 与分层时间索引:目标帧索引为 0 至 T−1,紧邻前一段为 T 至 2T−1,其余记忆段为 2T 至 3T−1。这在保留近期上下文连续性的同时,纳入更广泛的历史信息。
-
为解决训练与推理的差异,他们在推理阶段反转记忆帧的 RoPE 索引顺序。这使位置结构与训练对齐,确保记忆帧在训练(时间顺序)与推理(逆时间顺序)期间的索引一致性。
-
该数据集支持 Memory-V2V 的高效训练,将 FLOPs 和延迟降低超过 90%,同时随记忆视频数量扩展表现良好。
方法
Memory-V2V 框架旨在通过混合检索与压缩策略维持跨编辑一致性,实现多轮视频编辑。如框架图所示,其整体架构基于预训练的视频到视频扩散模型(如用于新视角合成的 ReCamMaster 或用于文本引导编辑的 LucyEdit),并引入机制以高效整合先前编辑历史。在每轮编辑迭代中,模型基于当前输入和从外部缓存中检索的相关历史视频生成新视频。该缓存存储先前生成视频的潜在表示,按相机轨迹(用于新视角合成)或源视频片段(用于文本引导编辑)索引。检索过程确保仅考虑最相关的历史视频,缓解因不断增长的历史条件带来的计算负担。
该框架的核心在于其动态分词与自适应分词合并组件。在视频新视角合成中,相关性由 VideoFOV 检索算法确定,该算法量化目标相机轨迹与缓存视频视场(FOV)之间的几何重叠。通过在首个相机位置中心的单位球面上采样点,并确定每帧投影图像边界内的可见性实现。视频级 FOV 是所有帧级 FOV 的并集,使用两种互补相似性度量——重叠与包含——计算最终相关性得分。检索前 k 个最相关视频,并使用不同时空压缩因子的可学习分词器进行动态分词。具体而言,用户输入视频使用 1×2×2 卷积核分词,前 3 个最相关检索视频使用 1×4×4 卷积核,其余视频使用 1×8×8 卷积核。这种自适应分词策略高效分配分词预算,为最相关视频保留细粒度细节,同时控制总分词数。
为进一步提高计算效率,框架采用自适应分词合并。该策略利用 DiT 注意力图固有的稀疏性,仅少数分词对输出有实质贡献。通过计算每帧对目标查询的最大注意力响应来估计其响应性。响应性得分低的帧被视为包含冗余信息,使用可学习卷积算子进行合并。合并在 DiT 架构的特定位置(第 10 块和第 20 块)执行,此时响应性得分已稳定,确保关键上下文保留的同时减少冗余。该方法避免了完全丢弃低重要性分词导致的性能下降。
对于文本引导的长视频编辑,框架通过将任务重新定义为迭代过程扩展多轮编辑范式。给定长输入视频,将其划分为符合基础模型时间上下文的较短片段。在编辑每个片段时,模型根据对应源视频片段的相似性(使用 DINOv2 嵌入)从缓存中检索最相关的先前编辑片段。检索到的视频随后进行动态分词并应用自适应分词合并。编辑后的片段拼接形成最终输出视频。该方法确保整个长视频的一致性,如在所有片段中一致添加相同对象或变换特定元素所示。
该框架还解决了多轮编辑中的位置编码挑战。为防止生成视频超出训练时域或条件集扩展时的时间漂移和不一致,采用分层 RoPE(旋转位置嵌入)设计。目标、用户输入和记忆视频被分配不重叠的时间 RoPE 索引范围。混合训练策略(包括对记忆分词的高斯噪声扰动和对用户输入分词的 RoPE 丢弃)用于确保模型在推理期间能正确解释和利用此分层结构。此外,通过每视频嵌入相机轨迹使相机条件显式化,使模型能处理异构视角并提升视角推理能力。
实验
- 在多轮新视角合成中评估上下文编码器:Video VAE 在跨代外观一致性上优于 CUT3R 和 LVSM;被采用为 Memory-V2V。
- 在 40 个视频上,Memory-V2V 在跨迭代一致性(MEt3R)和视觉质量(VBench)上超越 ReCamMaster(Ind/AR)和 TrajectoryCrafter,保持相机准确性并优于基于 CUT3R/LVSM 的变体。
- 在 50 个长视频(Señorita)上,Memory-V2V 在视觉质量和跨帧一致性(DINO/CLIP)上超越 LucyEdit(Ind/FIFO),实现 200+ 帧的连贯编辑。
- 消融实验证实,动态分词 + 检索提升长期一致性(如第 1 至第 5 代),而自适应分词合并将 FLOPs/延迟降低 30% 且无质量损失;合并优于丢弃,在运动连续性上表现更佳。
- 动态分词相比均匀分词将 FLOPs/延迟降低 >90%;自适应合并进一步节省 30%,使推理时间与单视频合成相当。
- Memory-V2V 在多镜头视频上表现不佳,因场景切换和不完美的合成训练扩展累积伪影;未来工作包括多镜头训练和扩散蒸馏集成。
结果表明,随着块距离增加,跨块一致性提升,如从 Block 1 与 2–30 到 Block 21 与 22–30 的 Pearson 相关性、Spearman 相关性和 Bottom-k 重叠值更高所示。这表明模型在更长时间间隔内保持更强的语义一致性。

结果表明,结合动态分词与视频检索显著提升主体一致性,而添加自适应分词合并进一步增强该指标,且不降低美学或成像质量。完整模型(包含所有组件)实现最高一致性和运动平滑度,证明所提记忆管理策略的有效性。
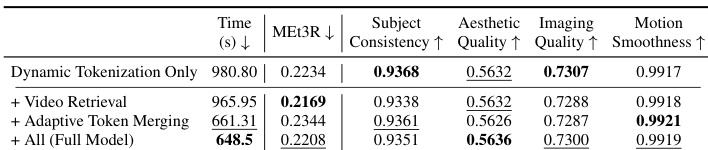
结果表明,自适应分词合并显著降低计算成本,模型相比无合并版本实现超过 30% 的 FLOPs 和延迟降低。作者使用该技术在条件依赖大量记忆视频时仍保持效率,使推理时间与单视频合成相当。
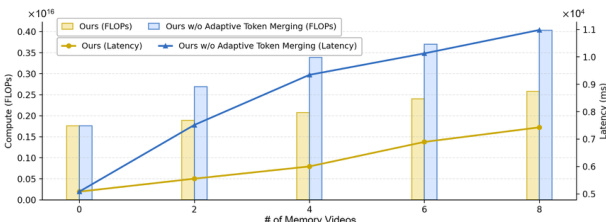
结果表明,Memory-V2V 在多视角一致性、相机准确性和视觉质量指标上持续优于所有基线,尤其在跨迭代一致性和视觉保真度上表现最佳。相比 ReCamMaster 和 TrajCrafter,该模型在保持多代一致性的同时,更好地保留运动和外观质量。
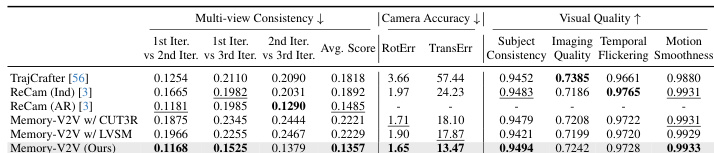
结果表明,Memory-V2V 在所有指标上均优于 LucyEdit 的两种变体,在背景一致性、美学质量、成像质量、时间闪烁和运动平滑度上取得最高分。它还通过更高的 DINO 和 CLIP 相似性值展示出更优的跨帧一致性,表明其在长视频编辑中更具连贯性和视觉一致性。
