Command Palette
Search for a command to run...
基于表征自编码器的文本到图像扩散Transformer的扩展
基于表征自编码器的文本到图像扩散Transformer的扩展
Shengbang Tong Boyang Zheng Ziteng Wang Bingda Tang Nanye Ma Ellis Brown Jihan Yang Rob Fergus Yann LeCun Saining Xie
摘要
表示自编码器(Representation Autoencoders, RAEs)在ImageNet图像扩散建模中展现出显著优势,其关键在于在高维语义潜在空间中进行训练。本文研究了该框架是否能够扩展至大规模、自由形式的文本到图像(Text-to-Image, T2I)生成任务。我们首先在冻结的表示编码器(SigLIP-2)基础上,将RAE解码器扩展至ImageNet之外的领域,通过在网页数据、合成数据以及文本渲染数据上进行训练,发现尽管规模扩大提升了整体生成保真度,但针对特定领域(如文本生成)而言,数据组成的针对性设计至关重要。随后,我们对最初为ImageNet设计的RAE架构选择进行了严格的压力测试。分析结果表明,随着模型规模的扩大,框架可被显著简化:尽管与维度相关的噪声调度机制仍至关重要,但诸如宽扩散头(wide diffusion heads)和噪声增强解码等复杂结构在大规模下带来的收益微乎其微。基于这一简化的框架,我们系统地对比了RAE与当前最先进的FLUX VAE模型,在扩散Transformer模型参数量从0.5B到9.8B的不同规模下的表现。实验结果显示,RAEs在所有模型规模下均在预训练阶段持续优于VAEs。进一步在高质量数据集上进行微调时,基于VAE的模型在64个训练周期后出现灾难性过拟合,而RAE模型则在256个周期内保持稳定,并始终取得更优的生成性能。在所有实验中,基于RAE的扩散模型均展现出更快的收敛速度与更优的生成质量,证明RAE在大规模T2I生成任务中是一种更简洁、更强大的基础架构,优于传统VAE。此外,由于视觉理解与生成均可在共享的表示空间中进行,该多模态模型能够直接对生成的潜在表示进行推理,从而为统一模型开辟了新的可能性。
一句话总结
纽约大学的研究人员提出了表示自编码器(RAE),作为文本到图像扩散模型中变分自编码器(VAE)的更简单、更具扩展性的替代方案。RAE通过利用共享潜在空间实现统一的视觉-语言推理,在不同模型规模下展现出更优的稳定性、更快的收敛速度和更高的保真度。
主要贡献
- RAE通过在包括网络数据、合成数据和文本渲染来源的多样化数据上训练解码器,有效扩展到文本到图像生成任务,揭示了有针对性的数据组合(而不仅仅是规模)对于重建精细文本细节至关重要。
- 在十亿参数规模下,RAE简化了扩散模型设计:维度相关的噪声调度仍至关重要,但诸如宽扩散头和噪声增强解码等架构复杂性带来的收益微乎其微,从而实现更高效的训练。
- 在0.5B至9.8B参数的DiT模型中,RAE在预训练速度和质量上优于FLUX VAE,避免微调期间的灾难性过拟合,并通过在共享语义潜在空间中运行实现统一的多模态推理。
引言
作者利用表示自编码器(RAE)将基于扩散的文本到图像生成扩展到受控的ImageNet设置之外,使用SigLIP-2等冻结编码器生成的高维语义潜在表示。以往工作依赖于将图像压缩到低维空间的VAE,牺牲了语义丰富性,且通常需要复杂的架构调整才能扩展——但仍面临收敛缓慢和微调期间过拟合的问题。作者表明,RAE消除了此类复杂性的需求:在大规模下,仅维度感知的噪声调度仍至关重要,而其他设计元素(如宽扩散头)收益递减。其关键贡献是证明RAE在不同模型规模(0.5B–9.8B参数)下始终优于最先进的VAE,收敛更快、抵抗过拟合,并通过允许理解和生成在相同潜在空间中运行实现统一的多模态模型——为潜在空间推理和测试时扩展开辟了路径。
方法
作者利用表示感知编码器(RAE)框架,在共享的高维潜在空间中实现统一的文本到图像(T2I)生成和视觉理解。整体架构包含两个主要阶段:解码器训练和统一模型训练。在解码器训练阶段,基于ViT的解码器被训练以从冻结表示编码器生成的语义标记中重建图像。编码器(具体为SigLIP-2 So400M,块大小为14)处理输入图像 x∈R3×224×224,生成 N=16×16 个标记,每个标记的通道维度 d=1152。解码器使用结合 ℓ1、LPIPS、对抗性和Gram损失的复合目标进行训练,以确保高保真重建。训练数据包括网络规模、合成和文本特定图像的多样化混合,数据集构成显著影响重建质量,尤其是文本部分。
如下图所示,统一模型训练阶段将训练好的RAE解码器与扩散Transformer和自回归模型集成。自回归模型以预训练语言模型(LLM)初始化,处理文本提示和一系列可学习查询标记以生成条件信号。这些信号通过两层MLP连接器投影到DiT模型空间。基于LightningDiT的DiT模型直接学习高维语义表示的分布,而不操作压缩的VAE空间。推理时,DiT根据查询标记生成特征,然后传递给RAE解码器渲染为像素空间。
扩散Transformer的训练采用流匹配目标,模型预测扩散过程的速度。该设置的关键组件是维度依赖的噪声调度,其根据有效数据维度 m=N×d 重新缩放扩散时间步长。这种调整对于高维潜在空间中的收敛至关重要,如应用该调整后GenEval和DPG-Bench分数的显著提升所证明。统一模型还支持视觉指令微调,其中独立的两层MLP投影器将视觉标记映射到LLM的嵌入空间,实现视觉和文本模态的直接交互。
RAE框架的一个关键优势是能够在潜在空间中直接执行测试时扩展。这通过潜在测试时扩展(TTS)实现,其中LLM作为其自身生成的验证器。采用两种验证器指标:提示置信度(衡量生成潜在表示中提示的标记级置信度)和答案logits(使用“是/否”查询评估生成图像与提示的对齐度)。对这些验证器应用best-of-N选择策略可一致提升生成质量,表明模型无需渲染像素即可评估和增强其输出。这种共享表示使模型能在语义空间中验证自身输出,凸显框架的效率和一致性。
实验
- 噪声增强解码在早期训练阶段(约15k步前)提供收益,但到120k步时变得微不足道,仅作为临时正则化手段。
- DiT^DH的宽去噪头在0.5B规模下带来+11.2 GenEval,但在2.4B+规模时饱和,因为骨干宽度自然超过潜在维度;标准DiT足以满足大型T2I模型。
- RAE(SigLIP-2)在DiT规模(0.5B–9.8B)和LLM规模(1.5B–7B)上始终优于FLUX VAE,在GenEval上收敛速度快4.0倍,在DPG-Bench上快4.6倍。
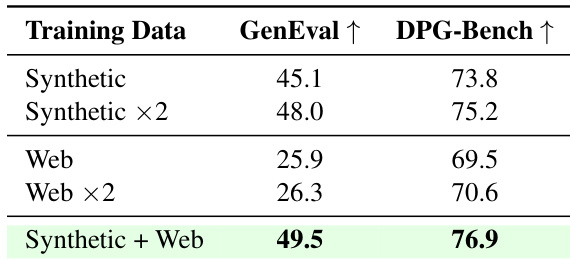
- 合成数据+网络数据(49.5 GenEval)优于双倍合成数据(48.0),表明互补来源带来协同增益,而不仅仅是数据量增加。
- 基于RAE的模型在微调期间抵抗过拟合:VAE损失在64个epoch后崩溃,而RAE损失保持稳定;RAE甚至在512个epoch后仍保持性能。
- RAE的优势在仅DiT微调和所有模型规模下均成立,且随着规模增大优势扩大(例如9.8B时79.4 vs 78.2 GenEval)。
- 使用OpenSSL ViT-L作为RAE编码器略逊于SigLIP-2,但仍优于FLUX VAE,证实RAE对编码器选择的鲁棒性。
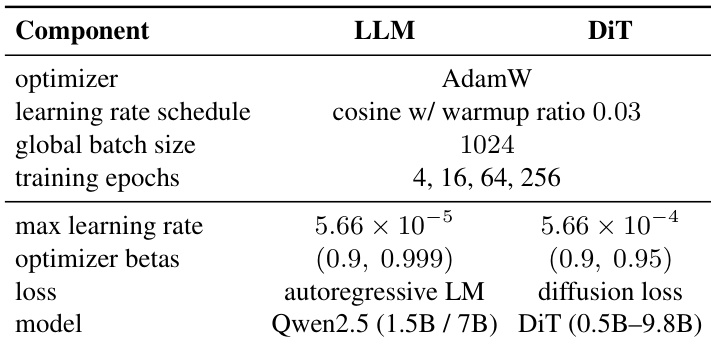
作者为LLM和DiT组件使用一致的训练设置:LLM使用AdamW和余弦学习率调度训练,DiT使用扩散损失和更高学习率。训练进行4、16、64和256个epoch,全局批大小为1024,模型包括Qwen2.5 1.5B和7B LLM,搭配从0.5B到9.8B参数的DiT变体。
作者比较了文本到图像扩散训练期间在潜在空间中应用平移增强的影响。结果表明,应用平移增强显著提升性能,GenEval从23.6提升至49.6,DPG-Bench从54.8提升至76.8,表明平移增强同时提升了生成质量和与人类偏好的对齐度。

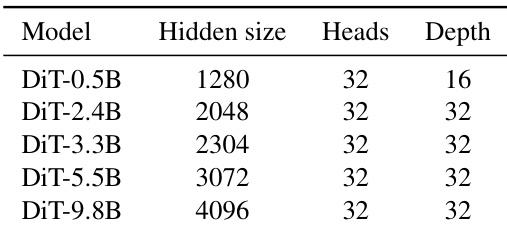
作者比较了不同规模的DiT变体,表明随着模型规模增加,隐藏维度显著增长,而头数和深度保持不变。这表明扩展DiT模型主要涉及增加隐藏维度,而非改变架构深度或注意力头数。
结果表明,结合合成和网络数据获得最高性能,GenEval得分为49.5,DPG-Bench得分为76.9,优于任一单一数据类型或双倍合成数据。这表明互补数据来源带来协同效益,而非单纯增加数据量。
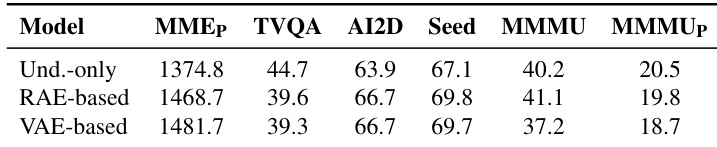
作者比较了基于RAE和基于VAE的模型在多个评估指标上的表现,显示RAE模型在所有任务中均优于VAE模型,仅TVQA任务中VAE模型略高。RAE模型在微调期间也表现出更强的稳定性,长期训练后仍保持性能,而VAE模型迅速过拟合。