Command Palette
Search for a command to run...
沙箱中的LLM激发通用代理智能
沙箱中的LLM激发通用代理智能
Daixuan Cheng Shaohan Huang Yuxian Gu Huatong Song Guoxin Chen Li Dong Wayne Xin Zhao Ji-Rong Wen Furu Wei
摘要
我们提出 LLM-in-Sandbox,使大型语言模型(LLMs)能够在代码沙箱(即虚拟计算机环境)中进行探索,从而在非代码领域激发通用智能。我们首先证明,无需额外训练,强大的大型语言模型已具备将代码沙箱用于非代码任务的泛化能力。例如,模型能够自发地访问外部资源以获取新知识,利用文件系统处理长上下文,以及执行脚本以满足格式要求。进一步地,我们展示了通过基于 LLM-in-Sandbox 的强化学习(LLM-in-Sandbox-RL)可有效增强这些代理式能力,该方法仅使用非代理性数据即可训练模型完成沙箱环境中的探索任务。实验表明,无论是在无需训练还是事后微调的设置下,LLM-in-Sandbox 均展现出在数学、物理、化学、生物医学、长文本理解以及指令遵循等多个领域的稳健泛化性能。最后,我们从计算效率与系统架构两个维度分析了 LLM-in-Sandbox 的性能表现,并将其开源为一个 Python 包,以促进其在真实场景中的部署与应用。
一句话总结
来自中国人民大学、微软研究院和清华大学的研究人员提出了 LLM-in-Sandbox,使大语言模型(LLM)能够自主使用代码沙箱完成非代码任务——通过强化学习(无需代理数据)增强推理能力——在科学、长上下文和指令跟随任务中取得显著提升,并支持开源部署。
主要贡献
- LLM-in-Sandbox 使大语言模型无需额外训练即可利用虚拟代码沙箱处理非代码任务,自发使用文件系统、外部资源和脚本执行解决数学、科学和长上下文理解等领域的问题。
- 作者引入 LLM-in-Sandbox 强化学习,仅使用非代理数据训练模型以提升沙箱探索能力,同时在代理模式和普通模式下提升性能,并泛化至域外任务。
- 该系统在长上下文任务中最多可减少 8 倍的 token 使用量,保持有竞争力的吞吐量,并作为兼容主流推理后端的 Python 包开源,支持实际部署。
引言
作者利用代码沙箱——一个虚拟计算机环境——解锁大语言模型(LLM)的通用代理智能,使其无需任务特定训练即可处理数学、科学和长上下文推理等非代码任务。以往方法常将 LLM 视为静态文本生成器或将工具使用限制在预定义 API,未能充分利用计算环境的全面灵活性。作者的主要贡献是 LLM-in-Sandbox,赋予模型对外部资源、文件系统和代码执行的开放访问权限,以及 LLM-in-Sandbox-RL——一种仅使用通用非代理数据训练模型掌握沙箱探索的强化学习方法——在多个领域提升性能,同时减少 token 使用量,并通过开源 Python 包支持实际部署。
数据集

作者使用六个多样化的非代码评估基准,每个基准针对特定领域和评估方法:
-
数学:30 道 AIME25 题目(奥林匹克级别),每题重复 16 次。提示包含逐步推理和框出的最终答案。使用 Math-Verify(HuggingFace,2025)评估。
-
物理:650 道 UGPhysics 题目(13 个本科科目,每科 50 题)。使用 LLM 评判器评估(Qwen3-30B-A3B-Instruct-2507,Yang 等,2025a)。
-
化学:450 道 ChemBench 题目(9 个子领域,每领域 50 题)。通过精确匹配评估。
-
生物医学:500 道基于文本的 MedXpertQA 多选题。通过精确匹配评估。
-
长上下文理解:100 道 AA-LCR 题目,需多文档推理(每组文档平均 100K token)。每题重复 4 次。文档存储于沙箱 /testbed/documents/。使用基于 LLM 的检查器评估(Qwen3-235B-A22B-Instruct-2507,Yang 等,2025a)。
-
指令跟随:300 道单轮 IFBench 题目,涵盖 58 个约束条件。使用官方代码在宽松模式下评估以处理格式变化。
-
软件工程:500 道经验证的 SWE-bench 任务(代码生成、调试、理解)。使用官方基于规则的脚本评估。使用 R2E-Gym 沙箱和第 2.2 节的 OpenHands 风格提示及工具集。
为分析沙箱能力,作者通过 Python 和 bash 代码块的模式匹配对模型行为进行分类。能力使用率 =(匹配到模式的轮次)/(总轮次)。分类规则详见表 15。
方法
作者利用代码沙箱环境,使大语言模型(LLM)通过交互式多轮推理和行动循环执行通用任务。该框架基于一个轻量级通用沙箱构建,其实现为基于 Ubuntu 的 Docker 容器,为模型提供终端访问和完整系统功能,同时确保与主机系统隔离。该环境配备最小工具集以实现核心计算功能:executeBASH 用于执行任意终端命令,str_replace_editor 用于文件操作,submit 用于标记任务完成。沙箱设计强调通用性和可扩展性,维持约 1.1 GB 的固定占用空间,相比之下特定任务环境可能需要高达 6 TB 存储,从而实现高效的规模化推理和训练。
LLM-in-Sandbox 工作流扩展了 ReAct 框架,模型根据任务提示和环境反馈迭代生成工具调用。如算法 1 所示,流程始于沙箱配置,随后进入循环:模型生成工具调用,在沙箱内执行,并接收观察结果。此交互持续至模型调用 submit 或达到最大轮次限制。该工作流通过利用沙箱文件系统支持灵活的输入/输出处理:输入可通过提示或 /testbed/documents/ 目录中的文件提供,输出定向至指定位置(如 /testbed/answer.txt),确保探索与最终结果的清晰分离。
为训练 LLM 有效利用沙箱,作者提出 LLM-in-Sandbox-RL——一种结合沙箱训练与通用领域数据的强化学习方法。训练数据包括来自百科、小说、学术考试和社交媒体等多样领域的上下文任务,每项实例包含背景材料和任务目标。沙箱配置将这些上下文存储为文件,采用增加任务难度的策略,如将多文档上下文拆分为单独文件,或为单文件上下文添加干扰项。此设置鼓励模型主动探索环境以定位相关信息,自然学会利用其能力。
任务设置包括采样一个任务作为测试任务,使用先前相关任务作为提示中的上下文示例。模型被指示将最终答案写入指定输出文件(如 /testbed/answer.txt),完成后提取结果。RL 训练框架采用基于结果的奖励,关键区别在于轨迹生成发生在 LLM-in-Sandbox 模式下,使模型能从沙箱交互中学习。系统提示引导模型使用计算工具,通过程序执行推导答案,并在安全隔离环境中自由探索。提示明确指定工作目录、输入输出路径,并包含重要注意事项和鼓励方法,确保与沙箱工具的正确交互。
实验
- LLM-in-Sandbox 在通用领域(数学、物理、化学、生物医学、长上下文、指令跟随)中提升性能,Qwen3-Coder 在数学任务上提升高达 +24.2%;较弱模型如 Qwen3-4B-Instruct 无收益或表现下降。
- 强模型有效利用沙箱能力:计算(数学中 43.4%)、外部资源(化学中 18.4%)、文件管理(长上下文中较高);弱模型使用率低(<3%)且探索效率低下。
- 将长上下文文档存储于沙箱(而非提示中)提升 Claude、DeepSeek 和 Kimi 的性能;Qwen3-4B 表现更差,表明需训练文件导航能力。
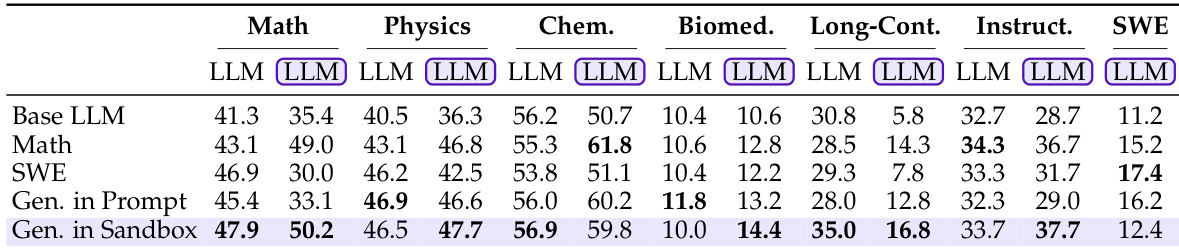
- LLM-in-Sandbox-RL 训练在领域、模型规模和推理模式间泛化:Qwen3-4B 在生物医学中从 10.0 提升至 14.4,在指令跟随中从 33.7 提升至 37.7;即使 LLM 模式也受益于迁移的推理模式。
- 使用置于沙箱(而非提示)的上下文进行训练带来更优泛化,因主动探索增强能力利用。
- 训练后,模型沙箱使用率增加(外部资源、文件操作、计算),轮次减少(Qwen3-4B 从 23.7 降至 7.0),而普通 LLM 输出获得结构化组织和验证行为。
- 计算上,LLM-in-Sandbox 在长上下文任务中最多减少 8 倍 token 使用量,平均总 token 为 LLM 模式的 0.5–0.8 倍;环境 token(37–51%)处理速度快,实现有竞争力的吞吐量(MiniMax 最高提速 2.2 倍)。
- 基础设施轻量:单个约 1.1GB Docker 镜像,每个沙箱空闲约 50MB / 峰值约 200MB 内存;512 个并发沙箱仅占用 2TB 系统内存的 5%。
- LLM-in-Sandbox 支持非文本输出:通过自主工具安装和执行生成交互式地图(.html)、海报(.png/.svg)、视频(.mp4)和音乐(.wav/.mid),展示超越文本生成的跨模态和文件级能力。
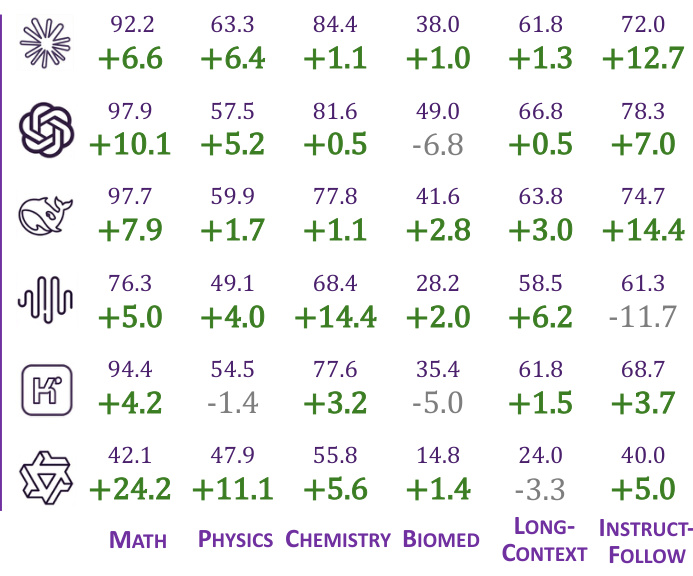
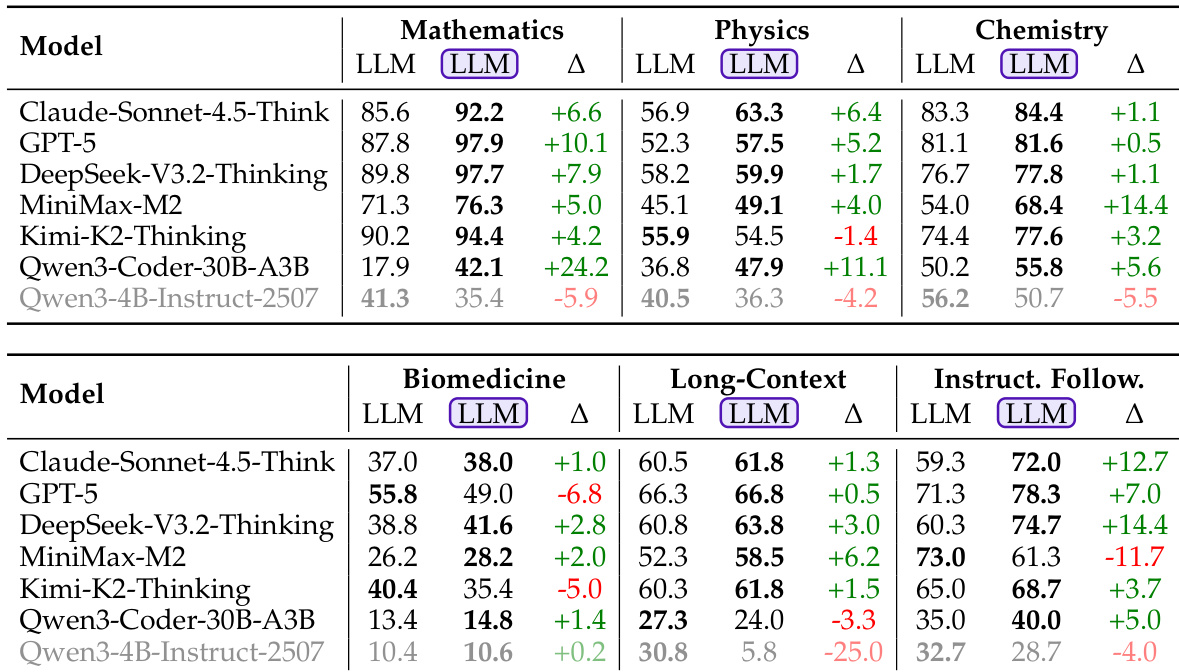
结果表明,与普通 LLM 生成相比,LLM-in-Sandbox 在大多数领域显著提升性能,数学(+24.2%)和指令跟随(+14.4%)提升最大。然而,Qwen3-4B-Instruct 模型在多数领域表现更差,表明较弱模型无法有效利用沙箱环境。
作者为每个模型使用不同的推理配置,包括温度、top-p、min-p、top-k、重复惩罚和后端的变化。配置针对每个模型的规格定制,部分模型使用基于 API 的后端,其他使用 SGLang 或 vLLM,每轮最大生成长度限制为 65,536 token,但 Claude-Sonnet-4.5-Think 因 API 限制限制为 64,000 token。
结果表明,与普通 LLM 生成相比,LLM-in-Sandbox 在大多数领域持续提升性能,数学和长上下文任务提升最显著。强模型提升尤为明显,而较弱模型如 Qwen3-4B-Instruct 收益甚微或无收益。
结果表明,强代理模型在所有评估领域中一致受益于 LLM-in-Sandbox,性能提升范围从 +1.0% 到 +24.2%。然而,较弱模型如 Qwen3-4B-Instruct-2507 在长上下文和化学任务中表现显著下降,表明有效利用沙箱取决于模型的固有能力。
结果表明,LLM-in-Sandbox-RL 训练显著改善强模型和弱模型的推理模式,增加普通 LLM 模式输出中的验证和结构化组织使用。Qwen3-Coder-30B-A3B 模型在验证方面小幅提升(0.77 至 0.88),结构化方面大幅提升(10.30 至 16.12);Qwen3-4B-Instruct-2507 模型在两项指标上均显著提升,验证从 20.22 升至 36.91,结构从 19.13 升至 20.64。
