Command Palette
Search for a command to run...
学习测试时发现
学习测试时发现
摘要
我们如何利用人工智能来为科学问题发现新的最先进解决方案?以往在测试时扩展(test-time scaling)方面的研究,例如 AlphaEvolve,通过向冻结的大型语言模型(LLM)提出提示来进行搜索。而我们则在测试时执行强化学习,使 LLM 能够持续训练,但此时的训练过程将基于与具体测试问题相关的经验。这种持续学习形式具有特殊性,因为其目标是产出一个卓越的解决方案,而非平均意义上生成多个较优解;同时,其目标是解决当前特定问题,而非实现对其他问题的泛化。因此,我们的学习目标与搜索子程序均被设计为优先关注最具潜力的解决方案。我们将该方法称为“测试时训练以发现”(Test-Time Training to Discover,简称 TTT-Discover)。沿袭先前研究的思路,我们聚焦于具有连续奖励信号的问题。我们在数学、GPU 内核工程、算法设计以及生物学等多个领域尝试了各类问题,并报告了所有问题的实验结果。TTT-Discover 在几乎所有问题上均达到了新的最先进水平:(i)解决 Erdős 的最小重叠问题及一个自相关不等式问题;(ii)在 GPU 模式内核竞赛中取得突破,性能比此前最优方法快达数倍;(iii)在过往 AtCoder 算法竞赛问题上实现超越;(iv)在单细胞数据分析中的去噪问题上取得显著进展。所有解决方案均经过领域专家或赛事组织方的评审。我们的所有成果均基于开源模型 OpenAI gpt-oss-120b 完成,且相关代码已公开,可被复现。这与以往最先进结果依赖闭源前沿模型的情况形成鲜明对比。本研究的测试时训练运行基于 Thinking Machines 公司推出的 Tinker API 实现,每个问题的运行成本仅需数百美元。
一句话总结
斯坦福大学、NVIDIA 及其合作者提出 TTT-Discover,这是一种测试时训练方法,使大语言模型(LLM)能够通过强化学习在单个问题上持续学习,在数学、GPU 内核、算法和生物学等多个领域超越以往的冻结模型方法——使用开源模型和低成本计算即可实现。
主要贡献
- TTT-Discover 引入了面向科学发现的测试时强化学习,使大语言模型能够在推理过程中调整自身参数以解决单个难题——不同于以往依赖冻结模型的搜索方法——通过定制的学习目标优先选择最有前景的解决方案。
- 该方法在多个领域实现了最先进的结果,包括数学(Erdős 最小重叠问题、自相关不等式)、GPU 内核工程(比现有技术快 2 倍)、算法设计(AtCoder)和生物学(单细胞去噪),所有解决方案均经领域专家或竞赛组织者验证。
- 所有结果均可使用开源模型 OpenAI gpt-oss-120b 和公开代码复现,通过 Tinker API 每个问题仅需数百美元成本,而以往最先进的方法依赖闭源专有模型。
引言
作者利用测试时强化学习,使大语言模型在解决特定科学问题时能够持续改进——而非依赖静态提示或进化搜索。这种方法之所以重要,是因为许多发现任务需要超越现有知识的全新解决方案,而从训练数据泛化的方法往往失效。以往方法(如 AlphaEvolve)使用手工启发式方法在冻结模型上搜索解空间,限制了模型内化新策略的能力。TTT-Discover 的关键贡献是一个定制的 RL 框架,针对每个问题优化一个高奖励解,使用熵目标和 PUCT 基础搜索来优先选择有前景的候选解。它在数学、GPU 内核设计、算法竞赛和生物学等多个领域均实现最先进的结果——全部使用开源模型和低成本——在相同条件下优于同期方法如 ThetaEvolve。

数据集

作者使用 OpenProblems 基准进行单细胞 RNA-seq 去噪,包含三个数据集:PBMC、Pancreas 和 Tabula Muris Senis Lung,按规模排序。他们在 Pancreas 数据集上训练策略,并在 PBMC 和 Tabula Muris Senis Lung 数据集上评估最终性能,使用二项采样创建的保留测试集模拟真实值。
关键处理步骤包括:
- 将输入矩阵转换为 float64 并保留原始文库大小用于逆归一化。
- 应用方差稳定变换(如 Anscombe)和文库大小归一化。
- 选择高变基因(HVGs)以降低维度。
- 在插补后重新归一化以保持随机特性。
去噪任务使用两个指标评估算法:对数归一化空间中的均方误差(主要奖励)和泊松负对数似然(约束)。若算法超过 400 秒或违反泊松分数约束,则会被惩罚。
作者将他们的方法与 MAGIC(当前最优)、ALRA、OpenEvolve 和 Best-of-25600 进行比较,使用相同的评估框架确保公平比较。
方法
所提出方法 TTT-Discover 的框架旨在通过利用大语言模型(LLM)策略在测试时解决发现问题,通过在线学习和战略状态重用迭代改进解决方案。整体架构运行在强化学习(RL)范式内,其中策略 πθ 在其自身搜索尝试累积的缓冲区 Hi 上训练,从而在发现过程中实现持续改进。该方法从初始状态 si 开始,该状态从缓冲区 Hi 中采样,采样使用重用启发式,优先选择高奖励解同时保持探索。策略随后生成动作 ai∼πθ(⋅∣d,si,ci),其中 d 是问题描述,ci 是从先前动作导出的上下文(若适用)。环境转换到新状态 si′=T(ai),并评估奖励 ri=R(si′)。该尝试被添加到缓冲区 Hi+1,策略权重 θi 使用专用训练目标更新。
核心创新在于训练目标和重用启发式的设计。训练目标是一个熵效用目标 Jβ(θ),其定义为通过基于奖励指数缩放温度参数 β(s) 重加权策略梯度更新,以优先选择导致高奖励的动作。该目标表述为 Jβ(θ)=Es∼reuse(H)[logEa∼πθ(⋅∣s)[eβ(s)R(s,a)]],梯度更新为 ∇θJβ(θ)=Es∼reuse(H)[wβ(s)(a)∇θlogπθ(a∣s)],其中 wβ(s)(a) 是归一化指数权重。为确保稳定性和适应性,β(s) 根据每个初始状态自适应设置,通过约束原始策略与熵权重诱导的倾斜分布之间的 KL 散度,确保更新不会偏离当前策略太远。
重用启发式受 PUCT(策略、不确定性与树搜索)算法启发,适用于从先前发现的解决方案缓冲区中选择状态。缓冲区 Hi 中的每个状态 s 由 PUCT 启发式规则评分:score(s)=Q(s)+c⋅scale⋅P(s)⋅1+T/(1+n(s))。这里,Q(s) 表示当 s 作为初始状态时从任何子状态获得的最大奖励,捕捉状态的乐观潜力。P(s) 是基于线性排名的先验,偏向高奖励状态,而探索奖励项 1+T/(1+n(s)) 通过降低频繁选择状态的分数来抑制过度利用。此机制确保在利用有前景状态和探索访问较少状态之间取得平衡,这对发现新解决方案至关重要。
该方法在算法 1 中实例化,概述了测试时训练过程。它用空解初始化缓冲区,迭代采样初始状态和上下文,生成动作,转换到新状态,评估奖励,更新缓冲区,并训练策略。与标准 RL 的关键区别在于目标:TTT-Discover 不优化平均性能,而是优化最大奖励,这与寻找一个超越当前最佳状态的目标一致。这是通过熵目标实现的,该目标有效地将焦点从期望奖励转移到实现高奖励结果的概率。该目标与基于 PUCT 的重用启发式相结合,使该方法能高效探索解空间,通过重用先前解扩展有效视野,并发现显著改进。
实验
- 使用 Tinker 上的 gpt-oss-120b(50 步,每步 512 次 rollout),TTT-Discover 在 Erdős 最小重叠问题(界值 0.380876,超越 AlphaEvolve 的 0.380924)和第一自相关不等式(C₁ ≤ 1.50286)上创下新纪录,分别使用不对称的 600 段和 30,000 段阶梯函数;优于 Best-of-25600 和 OpenEvolve 基线。
- 在自相关不等式 C₂ 上,TTT-Discover 达到 0.959(对比 AlphaEvolve 的 0.961);在圆堆积(n=26,32)上,与 Qwen3-8B 匹配已知最佳结果,但无改进。
- 在 GPU 内核工程(TriMul)中,TTT-Discover 内核在 H100、A100、B200、MI300X 上比顶尖人类提交快 15–50%;融合操作,使用 FP16 + cuBLAS/rocBLAS;MLA-Decode 内核在 MI300X 上表现逊于人类顶尖提交。
- 在 AtCoder 启发式竞赛中,TTT-Discover 在 ahc039(从 ALE-Agent 第 5 名解出发)和 ahc058(从零开始)中均获第一名,优于 ALE-Agent 和 ShinkaEvolve,尽管使用更小的模型预算。
- 在单细胞去噪(OpenProblems)中,TTT-Discover 在 Pancreas 数据集上改进了 MAGIC 基线的 MSE,并泛化到 pbmc/tabula;添加基因自适应变换、SVD 精炼、对数空间抛光。
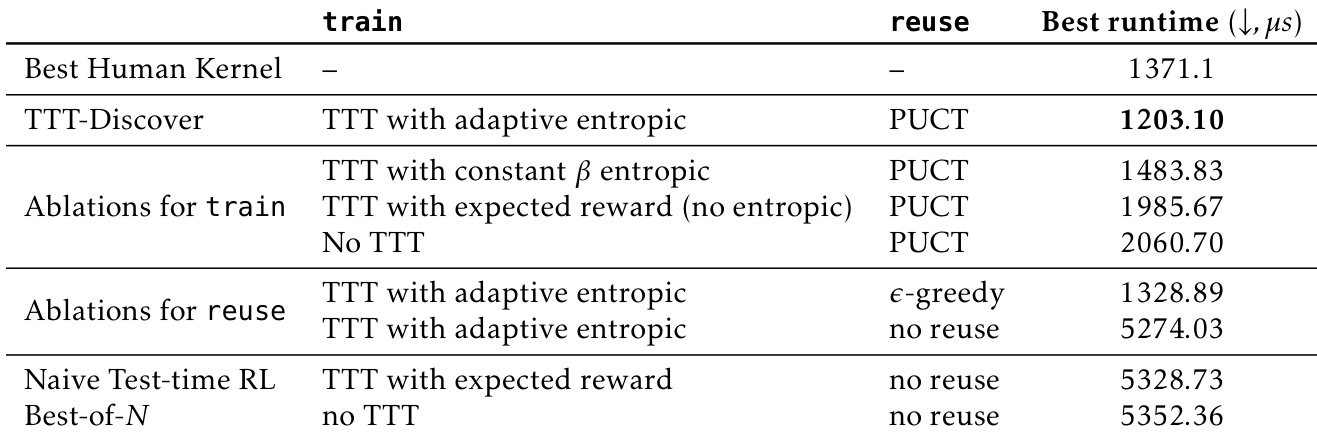
- 消融实验显示,完整 TTT-Discover(熵目标 + PUCT 重用)至关重要;固定 β、无熵目标或无重用会降低性能;Best-of-25600 基线改进 Erdős 界值但未在所有任务中一致提升。
作者使用 TTT-Discover 与自适应熵目标和 PUCT 重用,在 TriMul 内核优化任务中实现最佳运行时间为 1203.10 微秒。消融实验表明,移除熵目标或重用方法会显著降低性能,而完整 TTT-Discover 设置优于朴素 RL 和 Best-of-N 基线。
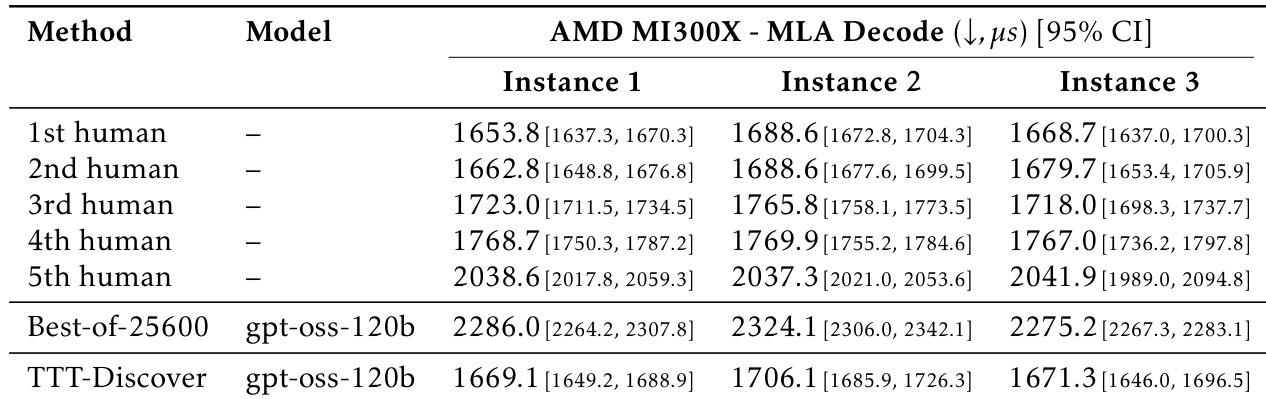
结果显示,TTT-Discover 在 AMD MI300X 上的平均运行时间为 1669.1 微秒,优于最佳人类提交(2038.6 微秒)和 Best-of-25600 基线(2286.0 微秒)。该方法在所有三个实例中表现一致,95% 置信区间表明其相对于人类和基线结果有统计学显著改进。
结果显示,TTT-Discover 使用 Qwen3-8B 在 n=26 和 n=32 的圆堆积任务上与 AlphaEvolve V2 和 ShinkaEvolve 表现相同,匹配已知最佳结果但无改进。
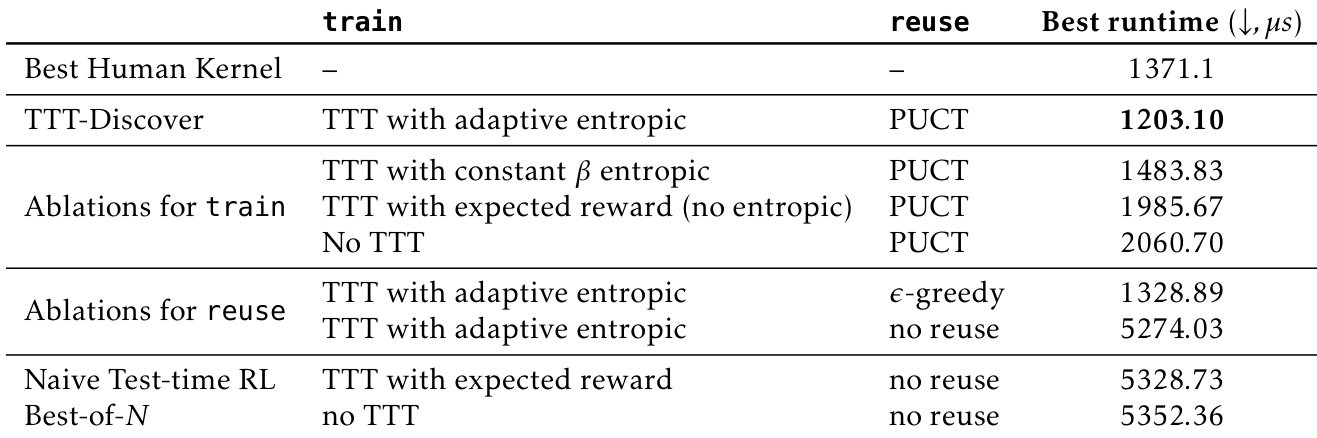
结果显示,TTT-Discover 在几何(ahc039)和调度(ahc058)竞赛中均获得最高分,优于所有人类提交和先前 AI 基线。在几何中,TTT-Discover 得分 567,062,超越最高人类得分 566,997;在调度中,得分为 848,414,228,超过最佳人类得分 847,674,723。

结果显示,TTT-Discover 在 TriMul 竞赛中所有 GPU 类型上均实现最先进的性能,平均优于最佳人类提交超过 15%。该方法生成的内核比现有的人类和 AI 基线显著更快,H100 上的最佳内核运行时间为 1161.2 微秒,比顶尖人类结果快 22%。