Command Palette
Search for a command to run...
Cosmos Policy:针对视觉运动控制与规划微调视频模型
Cosmos Policy:针对视觉运动控制与规划微调视频模型
摘要
近期的视频生成模型展现出捕捉复杂物理交互与场景随时间演变的惊人能力。为利用其时空先验知识,机器人领域的研究工作已尝试将视频模型应用于策略学习,但通常需要多阶段的微调以及新增的架构组件来生成动作,从而引入了显著的复杂性。在本工作中,我们提出 Cosmos Policy,一种简单而高效的方法:仅通过在目标平台采集的机器人示范数据上进行单阶段微调,即可将大型预训练视频模型(Cosmos-Predict2)转化为有效的机器人策略,且无需任何架构修改。Cosmos Policy 直接在视频模型的潜在扩散过程中生成编码为潜在帧的机器人动作,充分借助模型的预训练先验知识和核心学习算法,以捕捉复杂的动作分布。此外,Cosmos Policy 还能生成未来的状态图像和价值(预期累积奖励),这些同样以潜在帧的形式编码,从而支持在测试阶段进行高成功率的动作轨迹规划。在评估中,Cosmos Policy 在 LIBERO 和 RoboCasa 模拟基准测试中分别取得了 98.5% 和 67.1% 的平均成功率,达到当前最先进水平;在具有挑战性的真实世界双臂操作任务中,其平均得分亦位居榜首,显著优于从零开始训练的强大多扩散策略、基于视频模型的策略,以及在相同机器人示范数据上微调的最先进视觉-语言-动作模型。此外,借助策略回放数据,Cosmos Policy 可以通过经验学习不断优化其世界模型与价值函数,并结合模型规划机制,在复杂任务中进一步提升成功率。相关代码、模型及训练数据已开源,详见:https://research.nvidia.com/labs/dir/cosmos-policy/
一句话总结
NVIDIA 和斯坦福大学的研究人员提出了 Cosmos Policy,该策略通过对 Cosmos-Predict2-2B 进行单阶段微调,无需修改架构即可生成动作、未来状态和价值作为潜在帧,在仿真和真实世界的双臂任务中实现了最先进性能。
主要贡献
- Cosmos Policy 通过在机器人演示数据上进行单阶段微调,将预训练的视频模型 Cosmos-Predict2 适配为机器人策略,无需修改架构,直接在模型的扩散过程中将动作编码为潜在帧,从而利用其时空先验。
- 它联合预测机器人动作、未来状态图像和预期累积奖励作为潜在帧,通过最佳-N采样在测试时进行规划,选择高价值动作轨迹,从而提升仿真和真实世界双臂操作的任务成功率。
- 在 LIBERO(平均成功率 98.5%)、RoboCasa(平均成功率 67.1%)基准和真实任务(平均成功率 93.6%)上评估,其性能优于扩散策略、基于视频的策略和微调的视觉-语言-动作模型,并通过基于模型的规划和经验驱动的优化进一步提升。
引言
作者利用预训练的视频生成模型——其捕捉了时空动态和隐式物理特性——构建机器人策略,且无需修改模型架构。以往方法要么需要多阶段训练并定制动作模块,要么从头训练统一模型,从而未能利用预训练视频先验。Cosmos Policy 在单阶段内微调单一视频模型,联合生成机器人动作、未来状态和价值预测——全部编码为潜在帧——从而支持直接控制和基于模型的规划(通过最佳-N采样)。它在仿真和真实世界的双臂任务中实现了最先进性能,并通过经验驱动的世界模型和价值函数优化进一步提升。
数据集

-
作者使用三个不同的数据集:LIBERO(仿真)、RoboCasa(仿真)和 ALOHA(真实世界),每个数据集针对不同的机器人操作挑战。
-
LIBERO 包含四个任务套件(空间、物体、目标、长序列),共 500 个演示(10 个任务 × 50 个演示)。策略训练仅使用成功演示;世界模型和价值函数训练使用所有演示,无论是否经过筛选。
-
RoboCasa 包含 24 个厨房任务,每个任务有 50 个人类遥操作演示。作者仅在每个任务的这 50 个人类演示上训练,以评估数据效率,策略训练时筛选失败案例,但世界模型/价值函数训练保留所有演示。
-
ALOHA 包含四个双臂真实任务:“将 X 放在盘子上”(80 个演示)、“叠衣服”(15 个演示)、“将糖果放入碗中”(45 个演示)和“将糖果放入密封袋”(45 个演示)。策略接收本体感知、三视角图像和任务描述,输出 50 步动作块。
-
所有评估均使用固定初始状态以确保公平比较。LIBERO 结果平均 6000 次试验(3 个种子 × 10 个任务 × 50 次试验);RoboCasa 平均 3600 次试验(24 个任务 × 5 个场景 × 10 次试验 × 3 个种子);ALOHA 在所有任务中使用 101 次试验。
-
作者将 ALOHA 的控制频率从 50 Hz 降低至 25 Hz 以提高效率。未提及裁剪;元数据包括任务描述、相机图像和关节状态。训练划分遵循基准协议,未描述额外数据混合或增强。
方法
作者以预训练的 Cosmos-Predict2-2B-Video2World 模型为基础,该模型是一个潜在视频扩散模型,用于构建 Cosmos Policy。该模型基于扩散 Transformer 架构初始化,操作由 Wan2.1 时空 VAE 令牌器编码的连续标记。去噪器网络 Dθ 的核心训练目标被公式化为 EDM 去噪得分匹配问题,网络学习从被噪声 n 污染的版本 x0+n 中恢复干净的 VAE 编码图像序列 x0,条件为文本描述 c 和噪声水平 σ。网络通过交叉注意力条件化文本,通过自适应层归一化条件化噪声水平。Wan2.1 令牌器将大小为 (1+T)×H×W×3 的视频序列压缩为大小为 (1+T′)×H′×W′×16 的潜在序列,其中 T′=T/4,H′=H/8,W′=W/8。第一帧未进行时间压缩以允许基于单张输入图像进行条件化,且条件掩码确保该初始帧在训练期间保持干净。
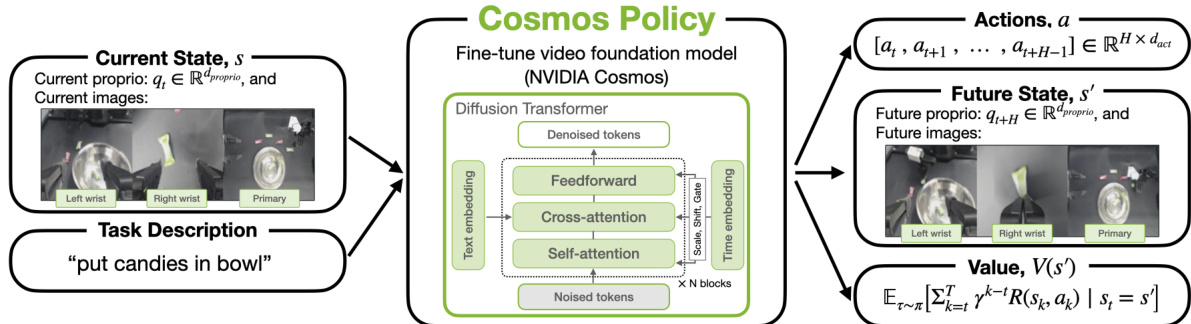
为了将此视频模型适配用于机器人控制,作者引入了一种称为潜在帧注入的新机制,允许模型在不修改架构的情况下整合新模态。该过程涉及将额外的潜在帧直接插入视频模型的潜在扩散序列中。对于具有多个相机视角和机器人特定数据的机器人平台,潜在序列结构包括图像帧和非图像模态。例如,在配备两个第三人称相机和一个腕部相机的设置中,序列包含 11 个潜在帧:空白占位符、机器人本体感知、腕部相机图像、第一个第三人称相机图像、第二个第三人称相机图像、动作块、未来机器人本体感知、未来腕部相机图像、未来第一个第三人称相机图像、未来第二个第三人称相机图像和未来状态价值。新模态——机器人本体感知、动作块和状态价值——通过用归一化并重复的相应模态数据填充每个 H′×W′×C′ 潜在体积来编码为潜在帧。序列中模态的顺序表示 (s,a,s′,V(s′)),从而实现从左到右的自回归解码动作、未来状态和未来状态价值。
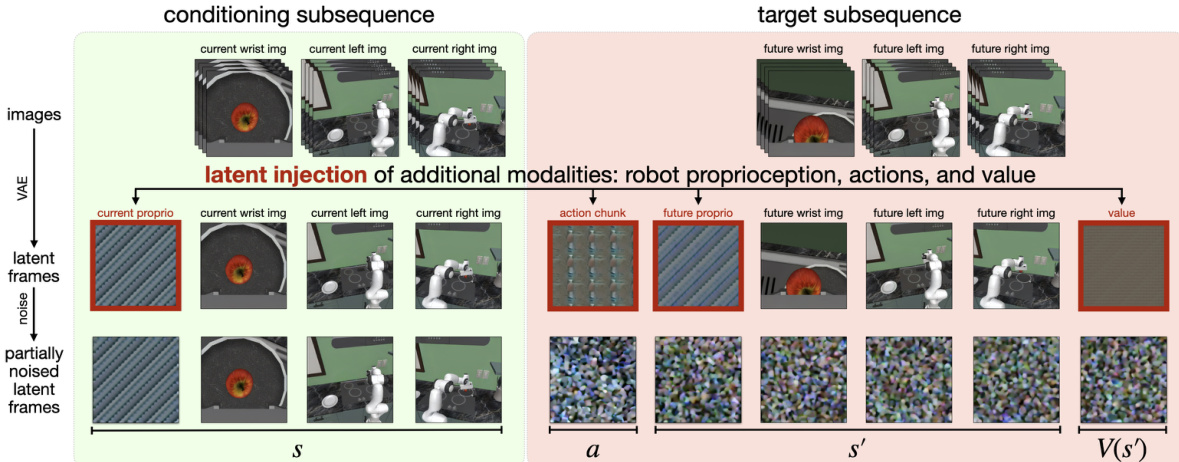
模型在机器人数据上训练,联合学习策略、世界模型和价值函数。在每个训练步骤中,采样一批 (s,a,s′,V(s′)) 元组。一半批次从专家演示中抽取以训练策略,学习预测联合分布 p(a,s′,V(s′)∣s)。另一半从 rollout 数据集中采样,并拆分以训练世界模型 p(s′,V(s′)∣s,a) 和价值函数 p(V(s′)∣s,a,s′)。条件方案(决定潜在序列中哪些部分用作输入、哪些部分作为目标)决定了正在训练的函数。策略和世界模型训练涉及辅助目标,可提升性能。在初始训练中,价值函数预测以完整潜在前缀 (s,a,s′) 为条件。但在基于 rollout 数据微调时,可通过输入掩码使价值生成以 (s,a,s′) 的子集为条件,从而使价值函数能够表示状态价值 V(s′) 或状态-动作价值 Q(s,a)。

作者还修改了训练和推理期间使用的噪声分布,以提高动作预测的准确性。基础模型的对数正态噪声分布将训练权重集中在较低噪声水平,不足以满足机器人所需的精确动作生成。为此,他们使用混合对数正态-均匀分布,赋予较高噪声水平更大权重。这通过以 0.7 的概率从原始对数正态分布采样、以 0.3 的概率从 [1.0, 85.0] 的均匀分布采样来实现。在推理时,他们设置更高的噪声水平下界 σmin=4,以避免极低噪声水平下的低信噪比,这在经验上提高了动作、未来状态和价值的预测准确性。
实验
- Cosmos Policy 在 LIBERO(成功率 98.5%)、RoboCasa(仅 50 个演示下成功率 67.1%)和真实世界 ALOHA 任务(四个任务中总体得分最高)上优于最先进的模仿学习方法,尽管使用的训练样本少于大多数对比方法。
- 消融研究证实,辅助训练目标(联合预测动作、下一状态和价值)和视频模型先验至关重要:移除它们分别导致成功率绝对下降 1.5% 和 3.9%;从头训练会产生生硬、不安全的动作,并在“叠衣服”任务中得分降低 18.7 分。
- 通过使用精炼的世界模型和 V(s’) 价值函数进行基于模型的规划,Cosmos Policy 在具有挑战性的 ALOHA 任务(“将糖果放入碗中”和“将糖果放入密封袋”)上平均得分提升 12.5 分,优于基于模型无关 Q(s,a) 的规划变体,因其更好地利用了学习到的动力学。
- 规划在 8 个 H100 GPU 上每动作需 4.9 秒,限制了实时适用性;通过仅使用 1 步去噪,推理延迟可降至每动作块 0.16 秒,成功率仅下降 0.5%。
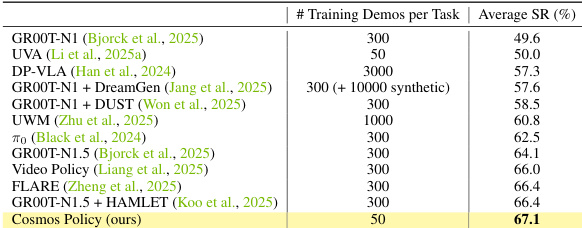
结果表明,Cosmos Policy 在 RoboCasa 基准的 24 个厨房操作任务中实现了 67.1% 的最高平均成功率,优于所有对比方法,同时使用的训练演示显著更少(每个任务 50 个)。作者利用此结果证明,他们的方法在高效数据使用的多任务操作性能上建立了新的最先进水平。
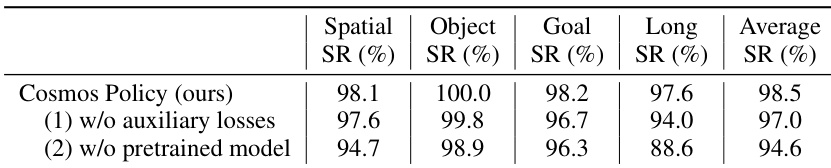
作者使用该表评估辅助损失和预训练模型对 Cosmos Policy 性能的影响。结果表明,移除辅助损失会导致平均成功率下降 1.5%,而无预训练模型训练会导致下降 3.9%,表明两个组件对最佳性能均至关重要。
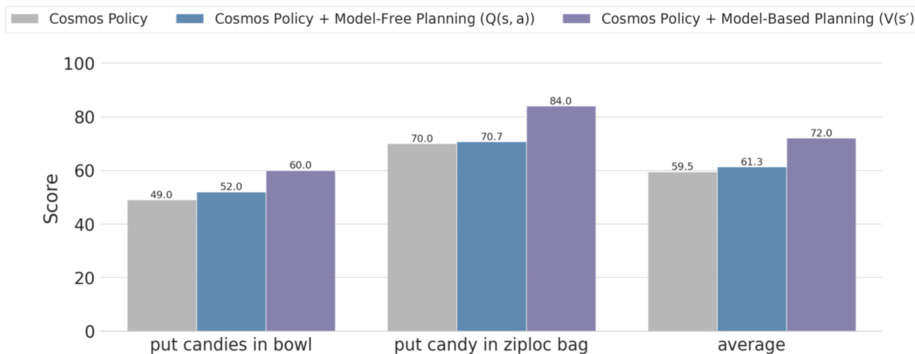
作者在具有挑战性的 ALOHA 机器人任务上评估了 Cosmos Policy 与基于模型的规划,比较使用状态价值函数 V(s′) 的基于模型规划与使用 Q 值函数 Q(s,a) 的无模型规划。结果表明,使用 V(s′) 的基于模型规划得分高于基础策略和无模型变体,平均得分为 84.0,而无模型规划为 70.7。
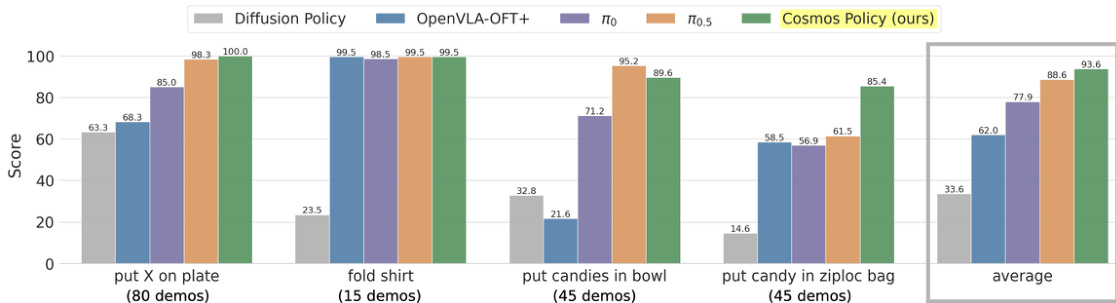
结果表明,Cosmos Policy 在所有四个 ALOHA 机器人任务中实现了最高的平均得分,优于所有对比方法中的三个任务。它在四个任务中获得 93.6 的最高总体得分,显著超越 Diffusion Policy 和 OpenVLA-OFT+ 在“叠衣服”和“将糖果放入密封袋”任务中的表现,同时在其他两个任务中也表现强劲。
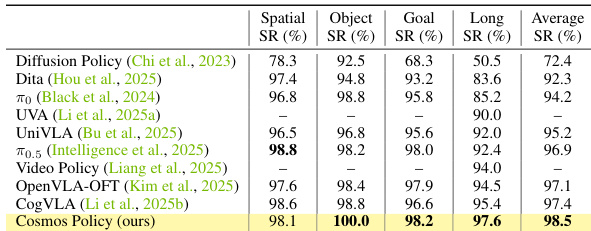
结果表明,Cosmos Policy 在 LIBERO 基准的所有任务中实现了 98.5% 的最高平均成功率,优于所有对比方法,包括 Diffusion Policy、Dita 和 UVA,尤其在物体和目标 SR 指标上表现强劲。作者使用此表证明 Cosmos Policy 在多任务操作的模仿学习中树立了新的最先进水平。