Command Palette
Search for a command to run...
推理时扩展验证:通过测试时评分标准引导的验证实现自演化深度研究Agent
推理时扩展验证:通过测试时评分标准引导的验证实现自演化深度研究Agent
Yuxuan Wan Tianqing Fang Zaitang Li Yintong Huo Wenxuan Wang Haitao Mi Dong Yu Michael R. Lyu
摘要
深度研究代理(Deep Research Agents, DRAs)的最新进展正在深刻变革自动化知识发现与问题求解范式。尽管现有多数研究集中于通过后训练(post-training)提升策略模型的能力,本文提出一种替代性范式:通过基于精心设计评估标准(rubrics)的迭代验证机制,实现代理自身能力的自我演化。该方法催生了推理阶段的可扩展验证(inference-time scaling),即代理通过评估自身生成的答案,获得迭代反馈并持续优化输出。我们基于自动生成的DRA失败分类体系(DRA Failure Taxonomy),系统性地将代理失败划分为五大类、十三小类,进而构建出相应的评估标准。在此基础上,我们提出DeepVerifier——一种基于rubrics的输出奖励验证器。该验证器利用验证过程与判断过程之间的不对称性,在元评估(meta-evaluation)F1得分上显著优于传统的“代理作为裁判”(agent-as-judge)与大型语言模型(LLM judge)基线方法,性能提升达12%至48%。为支持实际部署中的自我演化,DeepVerifier被设计为一个即插即用的测试时模块,在推理阶段无缝集成。该验证器生成基于rubrics的详细反馈,回传至代理以实现迭代式自举(bootstrapping),在无需额外训练的前提下持续优化响应质量。在具备强大闭源大模型支持的情况下,该测试时扩展策略在GAIA与XBench-DeepResearch的高难度子集上,分别实现了8%至11%的准确率提升。最后,为推动开源生态的发展,我们公开发布DeepVerifier-4K——一个经过精心筛选的监督微调数据集,包含4,646个高质量的代理执行步骤,专注于DRA验证任务。这些样本强调反思与自我批判,有助于开放模型逐步建立起稳健的验证能力。
一句话总结
来自香港中文大学、腾讯AI实验室及合作者的研究人员提出了DeepVerifier,这是一种基于评分标准的验证器,可通过迭代反馈在测试时实现深度研究代理的自我进化,在GAIA/XBench上比先前的评判模型提升12%-48%,准确率提高8%-11%,并开源数据集以推动社区研究。
主要贡献
- 我们引入了DeepVerifier,一种基于评分标准的验证模块,利用验证的不对称性在推理时自我改进深度研究代理,在GAIA的元评估F1分数上比代理作为评判者和LLM评判基线高出12%-48%。
- 我们从真实失败轨迹中构建了包含五大类和十三个子类的DRA失败分类法,使结构化反馈能够指导迭代优化而无需额外训练,在GAIA和XBench-DeepResearch子集上实现8%-11%的准确率提升。
- 我们发布了DeepVerifier-4K,一个包含4,646个示例的监督微调数据集,专注于反思与自我批判,使开源模型能够发展强大的验证能力,推动社区在DRA可靠性方面的更广泛进步。
引言
作者利用生成与验证答案之间的不对称性,在推理时改进深度研究代理(DRAs),以解决其因幻觉、API错误或推理缺陷而产生不可靠输出的问题。以往的测试时扩展方法——如并行展开或代理作为评判者系统——通常无法纠正持续性错误,或缺乏结构化反馈机制,尤其在复杂的多步骤DRA任务中。他们的主要贡献是DeepVerifier,一种即插即用的验证模块,使用包含13种DRA失败模式的分类法生成基于评分标准的反馈,使代理无需重新训练即可进行迭代自我优化。它在元评估F1分数上比基线评判者高出12–48%,在GAIA和XBench-DeepResearch上准确率提升8–11%。他们还发布了DeepVerifier-4K,一个包含4,646个示例的SFT数据集,以帮助开源模型发展强大的验证能力。
数据集

- 作者使用WebAggregatorQA构建DRA失败分类法,通过保留GAIA、BrowseComp和XBench-DeepSearch用于评估,确保无数据泄露。
- 他们使用Cognitive Kernel-Pro与Claude-3.7-Sonnet作为骨干,在WebAggregatorQA上运行,收集了90个不同任务中的2,997个代理行为(轨迹长度:2–156步;正确/错误比例:0.96),以压力测试多步推理、网页浏览和工具使用。
- 对于答案错误的轨迹,两名注释员独立通过将代理执行与人类参考轨迹对比,识别出555个错误点;每个错误点定位局部失败,如缺少证据或无效来源。注释员一致性平均为63.0%,最终错误点经过合并和去重。
- 分类法由两名经验丰富的AI研究人员迭代构建,从50个错误点开始聚类,然后在多轮中精炼标签以消除冗余并明确定义。最终结构包括五大类和十三个子类(如图3所示)。
- 主要失败类别:查找来源(最常见,例如错误证据或泛化搜索)、推理(过早结论、幻觉)、问题理解(目标漂移、误解)、操作错误(界面/格式错误)和达到最大步数(表明早期级联失败)。
- 注释指南详见附录A;该分类法用于指导模型调试和训练设计,但不直接用于训练模型本身。
方法
作者在DeepVerifier中采用三阶段多模块框架,旨在增强深度研究代理的验证和测试时扩展能力。整体架构如框架图所示,包括分解代理、验证代理和评判代理,每个代理在验证管道中扮演独特角色。过程始于代理生成未验证的答案及其对应轨迹。该轨迹随后传递给分解代理,后者启动结构化分析以识别潜在错误并制定针对性后续问题。
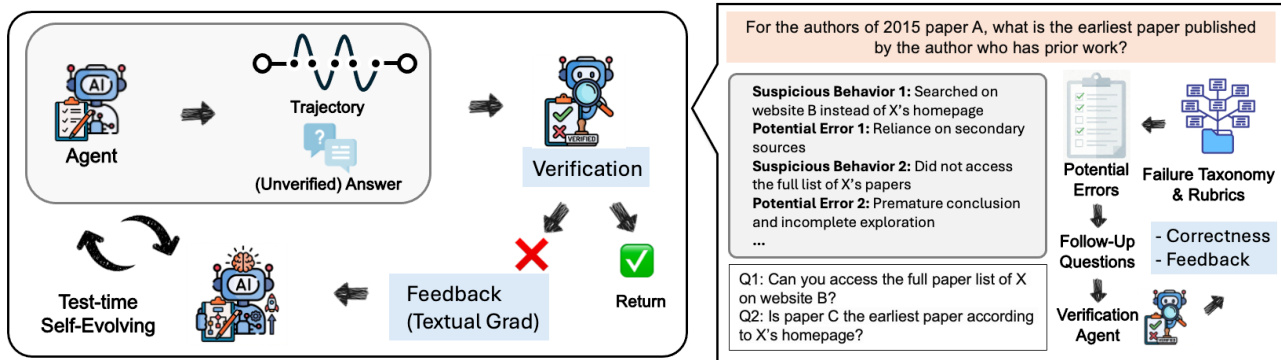
分解代理按三个顺序步骤运行。首先,它执行轨迹摘要,将代理的完整轨迹——通常超过820万token——压缩为紧凑的、按步骤索引的摘要。此摘要捕捉访问的来源及每步检索的具体信息(如事实、数字或引文),不包含解释性评论,确保下游模块能在有限上下文窗口内高效运行。其次,代理通过扫描摘要与预定义失败分类法对比,识别潜在错误。它生成结构化对〈行为〉⇒〈潜在错误 + 分类标签〉,每个附带简要理由,从而定位可能的失败点。第三,代理制定高杠杆后续问题,针对标记的漏洞。这些问题设计为可通过外部证据回答,旨在明确确认或反驳特定主张,实现聚焦验证。
随后,验证代理依次检索这些后续问题的答案。在实现中,作者使用CK-Pro代理,这是一个模块化多代理系统,主代理通过将任务分解为子任务并分配给专业子代理来协调流程。这些子代理与特定资源(如搜索引擎或文档阅读器)交互,并生成Python代码执行操作,确保在不同场景下的适应性。后续问题的答案随后传递给评判代理,后者评估原始未验证答案。评判代理生成简洁解释并分配1至4分,其中1分表示答案完全错误,2分表示大部分错误,3分表示大部分正确,4分表示完全正确。此评估结合轨迹摘要、潜在错误列表、后续问题及其对应答案。
该框架进一步通过自我进化循环支持测试时扩展。验证后,代理从评判代理接收反馈,包括重试任务并避免重复错误的可操作指令,以及在可用时提供正确答案的建议。此反馈使代理能迭代优化其方法,在多次尝试中提升表现。该过程重复直至获得满意答案或达到重试限制。
实验
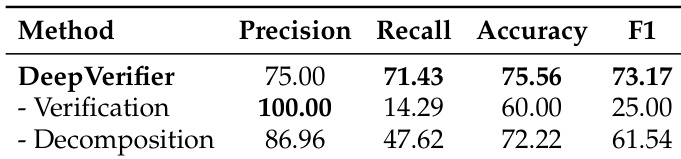
- DeepVerifier在DRA验证中有效,相比消融版本F1提升12%–48%,通过将验证分解为目标子问题以捕捉细微推理和事实错误,达到最高准确率。
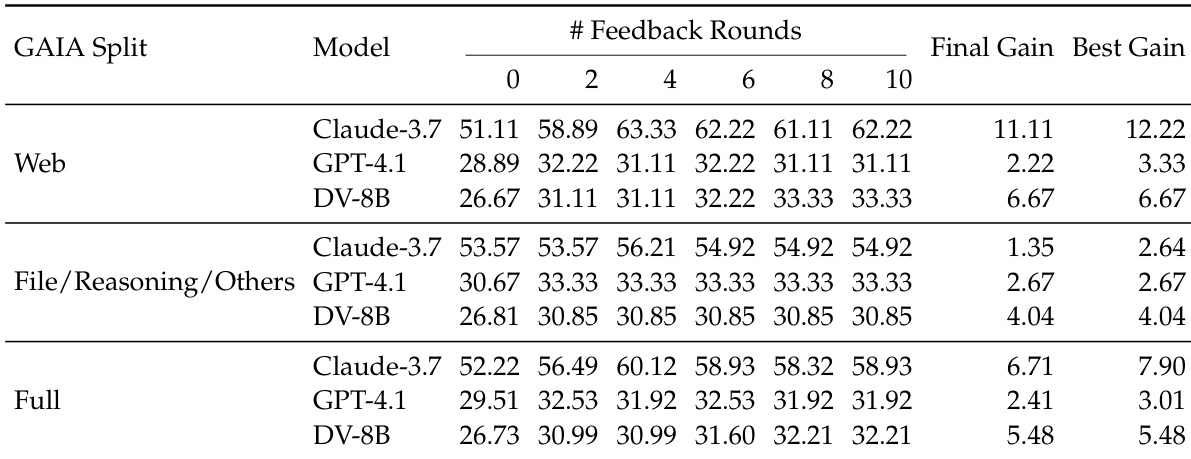
- 在GAIA-Full上使用Claude-3.7-Sonnet,DeepVerifier在4轮反馈后将准确率从52%提升至60.1%(+8%);GAIA-Web提升更大(52% → 63.5%),显示对网页检索任务的显著益处。
- 跨模型泛化:GPT-4.1从29.5%提升至32.5%,并保持扩展趋势;在XBench-DeepSearch(+6.0)和BrowseComp(+5.0)上也有效,证实跨数据集鲁棒性。
- 在DeepVerifier-4K上微调Qwen3-8B得到DeepVerifier-8B,在GAIA上10轮后达到32.2%准确率——比无反思基线高5.5%,证明反思能力可迁移至开源模型。
结果表明,DeepVerifier通过测试时扩展提升深度研究代理性能,准确率随反馈轮次提升,并在大多数模型的第四轮达到峰值。该方法在GAIA数据集上取得显著提升,尤其在基于网页的任务上,并泛化至其他模型和基准,展示迭代验证的鲁棒性和有效性。
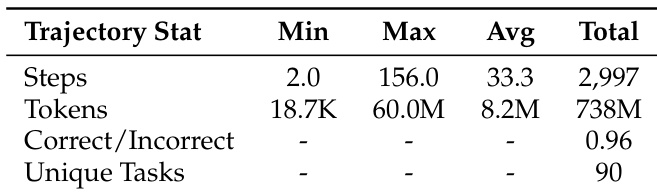
作者使用该表呈现实验中的轨迹统计,显示每任务平均步数为33.3,最大156.0,平均token数为820万,总计7.38亿token。数据显示系统处理90个独特任务,正确/错误比为0.96,表明代理表现具有较高准确率。
结果表明,DeepVerifier相比其消融版本实现了最高准确率和F1分数。移除验证模块导致完美精确率但低召回率和准确率,表明无法检测细微错误;移除分解模块导致召回率和准确率下降,因逐步验证无效。
结果表明,错误转正确率随反馈轮次急剧下降,第5轮降至0%;正确转错误率保持较低但持续存在,第5轮峰值为3.03%。这表明验证过程能早期有效纠正错误,但持续存在错误拒绝正确答案的风险,导致性能在第4轮左右达到峰值。

结果表明,DeepVerifier通过迭代反馈在多个数据集上提升性能,DeepSearch最终增益为3.0,最佳增益为6.0;BrowseComp最终增益为4.0,最佳增益为5.0。性能在反馈过程早期达到峰值,表明验证器在修正错误与错误拒绝正确答案之间的权衡导致后续轮次纠错能力下降。
