Command Palette
Search for a command to run...
面向具身世界的视频生成模型再思考
面向具身世界的视频生成模型再思考
Yufan Deng Zilin Pan Hongyu Zhang Xiaojie Li Ruoqing Hu Yufei Ding Yiming Zou Yan Zeng Daquan Zhou
摘要
视频生成模型在推动具身智能发展方面取得了显著进展,为生成涵盖物理世界中感知、推理与动作多样性的机器人数据开辟了新可能。然而,合成能够准确反映真实机器人交互的高质量视频仍面临挑战,且缺乏标准化的评估基准,限制了模型间的公平比较与技术进步。为填补这一空白,我们提出一个全面的机器人基准测试体系——RBench,旨在评估面向机器人任务的视频生成能力,涵盖五个任务领域与四种不同形态(embodiment)。该基准通过可复现的子指标,系统评估任务层面的正确性与视觉保真度,包括结构一致性、物理合理性以及动作完整性。对25个代表性模型的评估揭示了现有方法在生成具有物理真实感的机器人行为方面存在显著缺陷。此外,RBench与人工评估之间达到了0.96的斯皮尔曼等级相关系数,验证了其评估有效性。尽管RBench为识别这些缺陷提供了关键工具,但要实现真正的物理真实性,必须超越评估本身,着力解决高质量训练数据严重短缺的核心问题。基于上述洞察,我们提出了一套优化的四阶段数据构建流程,最终形成RoVid-X——目前规模最大的开源机器人视频生成数据集,包含400万条标注视频片段,覆盖数千种任务,并配备全面的物理属性标注。这一评估体系与高质量数据集协同构建的生态系统,为视频生成模型的严谨评估与可扩展训练奠定了坚实基础,将有力推动具身人工智能向通用智能的演进。
一句话总结
北京大学与字节跳动Seed的研究人员推出了RBench——首个全面的机器人视频生成基准,以及大规模标注数据集RoVid-X,通过评估25个模型并支持可扩展训练,填补物理真实性方面的差距,推动具身智能发展。
主要贡献
- 我们推出了RBench,这是首个全面的机器人视频生成基准,评估了25个模型在五个任务领域和四种机器人形态下的表现,使用可复现的指标衡量任务正确性与物理合理性,与人类判断的相关性高达0.96(Spearman相关系数)。
- 我们的评估表明,当前视频基础模型在生成物理真实的机器人行为方面存在困难,暴露出动作完整性与结构一致性方面的关键缺陷,阻碍其在具身智能应用中的使用。
- 我们发布了RoVid-X——目前最大的开源机器人视频数据集,包含400万段标注视频片段,并附有物理属性标注,通过四阶段流水线构建,旨在支持可扩展训练并提升具身视频模型的泛化能力。
引言
作者利用视频生成领域的最新进展,解决具身智能中对真实、任务对齐的机器人视频合成日益增长的需求。尽管视频模型在模拟机器人行为和减少对昂贵遥操作数据的依赖方面展现出潜力,但先前的基准未能评估物理合理性和任务完成度——导致对不真实输出给出误导性高分。为此,他们引入RBench——一个包含650个样本的新基准,涵盖五个任务和四种机器人类型,使用自动化指标评估结构一致性、物理合理性和动作完整性,并经人类判断验证其与0.96的Spearman相关性。他们还发布了RoVid-X——一个包含400万段视频片段的数据集,通过四阶段流水线构建,富含物理标注与多样化的机器人-任务覆盖,以解决高质量训练数据的稀缺问题。RBench与RoVid-X共同构成一个统一生态系统,用于严格评估和训练面向具身智能的视频模型。
数据集

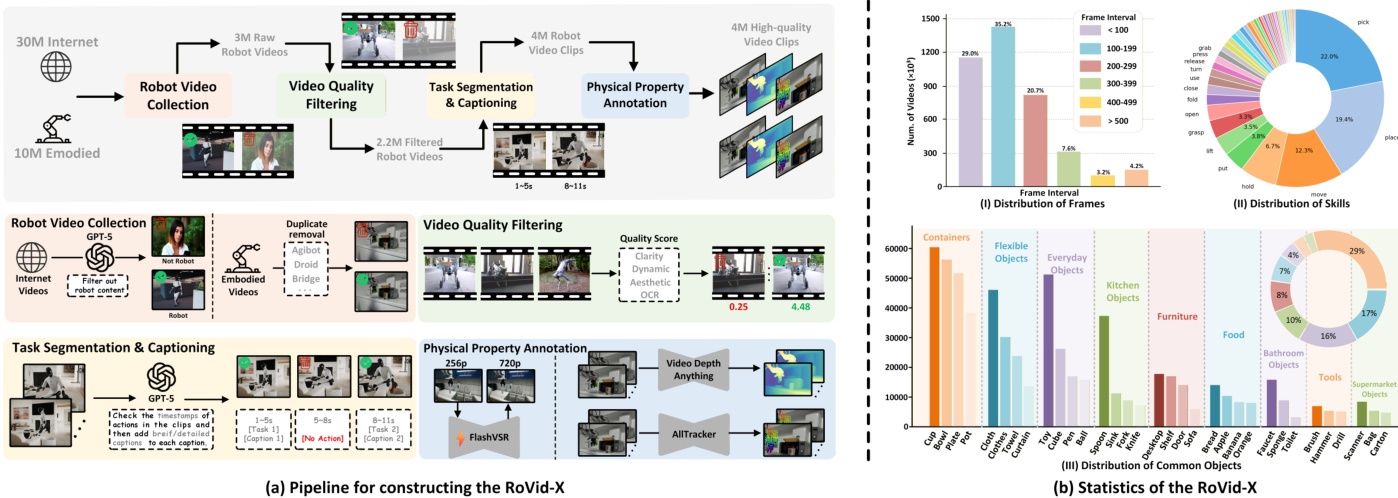
作者使用RoVid-X——一个包含400万段视频片段的大规模机器人视频数据集,用于训练和评估面向具身智能的视频生成模型。该数据集基于互联网公开视频及20多个开源具身数据集构建,通过四阶段流水线进行过滤与增强:
- 收集:从公共平台和开源数据集中收集原始视频,覆盖多样化的机器人与任务。GPT-5过滤掉无关或低质量片段,保留约300万候选片段。
- 质量过滤:按场景分割视频,根据清晰度、运动、美感和OCR评分,仅保留高分片段。
- 任务分割与字幕生成:视频理解模型按动作分割片段,标注起止时间并生成标准化字幕,描述主体、对象与操作(如“右臂抓取箱子”)。
- 物理标注:FlashVSR提升分辨率;AllTracker添加光流;Video Depth Anything生成深度图——所有步骤旨在强化物理真实性和空间一致性。
为评估,作者构建了RBench基准,包含650个样本,涵盖5类任务(常规操作、长时规划、多实体协作、空间关系、视觉推理)和4种机器人形态(双臂、人形、单臂、四足)。每个样本包含经验证的关键帧和重新设计的提示,避免训练集重叠。记录对象、形态和视角(第一/第三人称)等元数据,以便细粒度分析。
模型通过I2V生成进行评估,提示源自基准样本。商业、开源及机器人专用模型在标准分辨率(多为720p或1080p)和帧率(16–30 fps)下生成视频,时长通常为4–8秒。作者通过确保评估视频不包含于训练数据,并使用人工标注者验证提示逻辑与图像准确性,避免内容重叠。
方法
作者提出了一套全面的机器人视频生成评估框架,围绕任务完成度与视觉质量双轴评估。整体架构如框架图所示,整合自动化指标与多模态大语言模型(MLLM)评估,以评估生成视频的机器人特定标准。评估流程始于RoVid-X数据集的构建,该数据集通过多阶段流程从网络视频中提取,包含机器人视频收集、质量过滤与物理属性标注,作为评估视频生成模型的基础。
评估框架分为两个主要部分:任务完成度与视觉质量。对于任务完成度,作者使用MLLM评估物理语义合理性与任务遵循度。过程包括向MLLM提供上下文信息——如视频视角、高层内容描述、机器人操作器与操作对象身份——以及由原始指令生成的二元验证问题序列。这些问题结构化地反映因果与时间依赖性,由问题链构造器生成。MLLM随后评估按时间顺序排列的 3×2 网格视频帧,判断每个推理步骤的成功性,并评估机器人与对象在序列中的稳定性、一致性与物理合理性。这种两部分提示设计确保评估过程结构化且可解释。
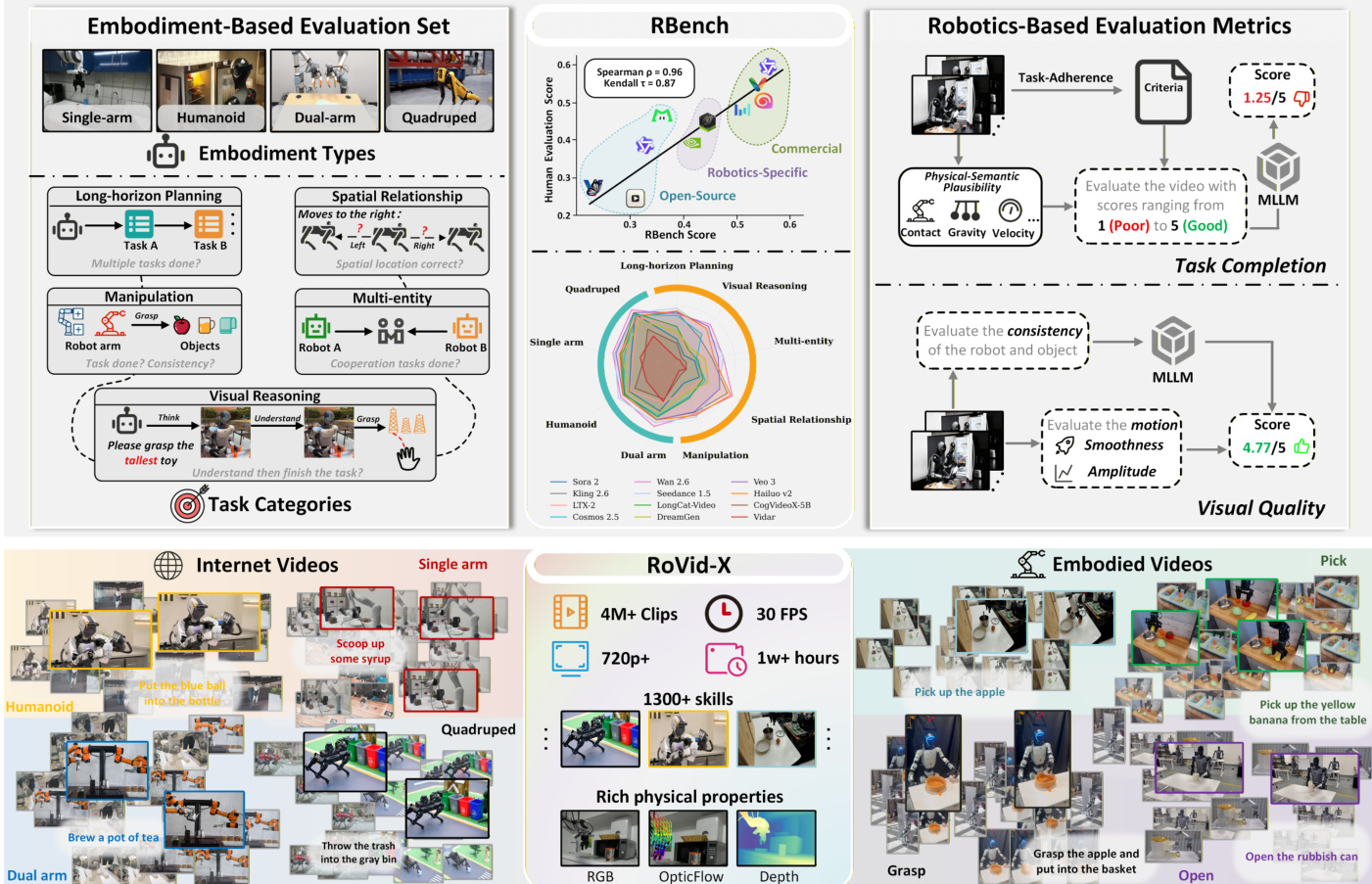
对于视觉质量,框架整合了一套自动化指标,旨在捕捉运动幅度与运动平滑度。运动幅度评分(MAS)用于衡量机器人可感知的动态行为,同时补偿相机运动。该过程使用GroundingDINO定位机器人,通过SAM2获得时序稳定的分割掩码,并使用CoTracker在机器人掩码内跟踪密集关键点网格。计算这些跟踪点的帧级位移并按视频对角线归一化。为补偿相机引起的运动,通过在反向机器人掩码上应用相同跟踪程序获得背景运动估计。随后应用软零策略,确保仅考虑超出背景漂移的运动,最终将补偿位移裁剪并平均,得出MAS。
运动平滑度评分(MSS)评估运动的时间连续性与自然性,旨在检测帧级不连续性与运动模糊伪影。该指标基于VMBench中的运动平滑度原则,使用Q-Align美学质量评分估计时间一致性。对于每个视频,通过滑动窗口处理帧序列以获得每帧质量评分序列,并测量相邻帧差异的幅度。使用基于运动幅度值的自适应阈值函数检测异常时间变化,确保阈值对视频运动强度敏感。超出该阈值的帧被标记为时间异常,最终MSS计算为序列中“正常”帧的比例。该方法有效捕捉低级时间伪影与高级运动模糊,提供稳健的运动质量度量。
实验
- 在RBench上评估了25个最先进的视频生成模型(闭源与开源),用于机器人任务视频生成,该基准整合五个细粒度指标:物理语义合理性、任务遵循一致性、运动幅度、机器人主体稳定性与运动平滑度。
- 闭源模型占优:Wan 2.6排名首位(0.607),Seedance 1.5 Pro排名第二,超越Wan 2.2等开源模型,凸显物理基础生成能力的差距。
- 像Sora v2 Pro等模型排名较低(第17位,0.362),揭示媒体模拟差距:视觉平滑模型缺乏物理保真度和精确运动控制,难以胜任具身任务。
- 迭代扩展提升物理推理能力:Wan 2.1(0.399)到Wan 2.6(0.607)及Seedance 1.0到1.5 Pro显著提升,表明扩展增强物理理解。
- 机器人专用模型Cosmos 2.5优于更大规模开源模型,证明领域数据提升鲁棒性,而过度专用模型(Vidar、UnifoLM)排名最低,强调泛化世界知识的必要性。
- 认知与操作差距依然存在:顶级模型(如Wan 2.6)在视觉推理(0.531)和精细操作任务上得分低于粗粒度移动任务。
- 使用RoVid-X数据集微调(基于Wan2.1/2.2)在五个任务领域和四种形态下均提升性能,验证其有效性。
- 定性分析(图5)显示,像Wan 2.5等模型在长时规划中表现优异,而其他模型在任务序列、对象识别或物理合理性方面失败(如LongCat-Video引入不真实的人类干预)。
- 人类偏好评分与RBench评分强相关,证实指标有效性。
作者使用定量评估框架评估视频生成模型的物理合理性与任务遵循度,结果显示Hailuo和Wan2.5等模型获得高平均分,表明其在生成物理一致且任务合规视频方面表现强劲。分析显示,尽管部分模型平均分高,但其在不同指标上表现差异显著,凸显其处理复杂机器人任务能力的不均衡。
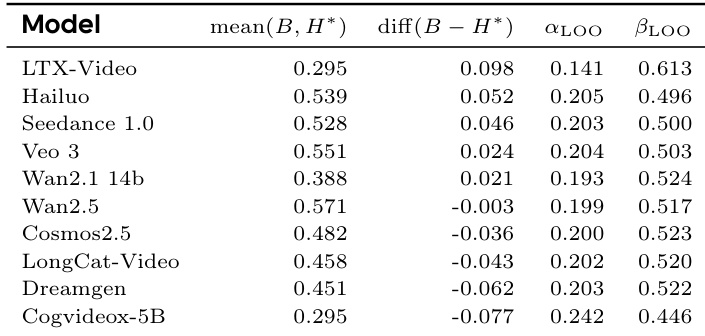
作者使用综合基准评估视频生成模型在机器人任务上的表现,聚焦任务完成度与视觉质量,通过物理语义合理性、任务遵循一致性与运动平滑度等指标。结果显示,闭源模型(尤其是Wan 2.6)优于开源及机器人专用模型,Wan 2.6在多数指标上获得最高分,表明其在物理推理与任务执行能力上存在显著性能差距。
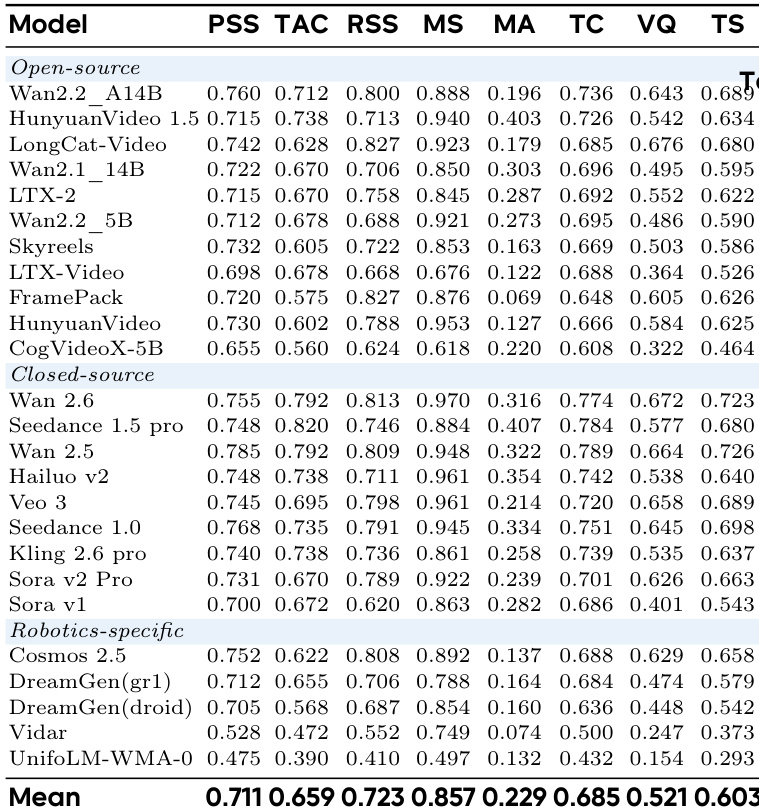
作者使用综合基准评估视频生成模型在机器人任务上的表现,聚焦任务完成度与视觉质量,通过物理语义合理性、任务遵循一致性与运动平滑度等指标。结果显示,闭源模型总体优于开源及机器人专用模型,Wan 2.5在多数指标上获得最高分,表明模型迭代与物理推理能力之间存在强相关性。
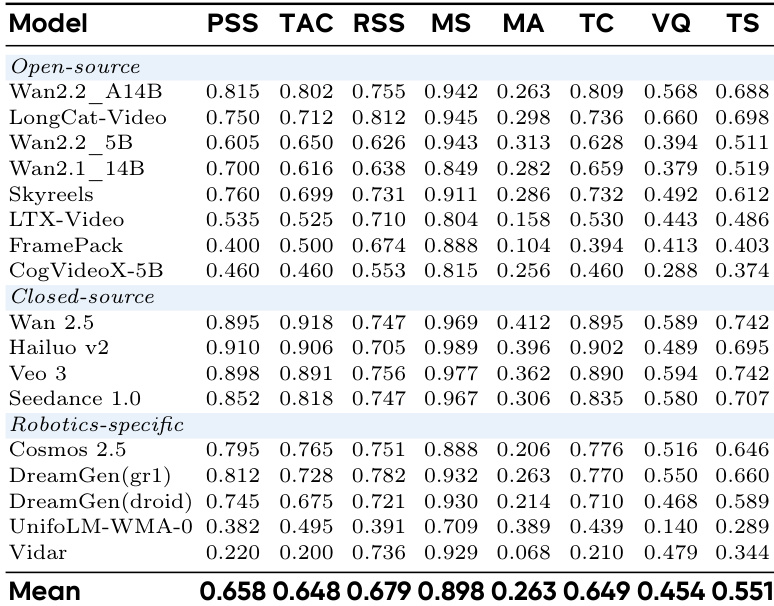
作者使用综合基准评估视频生成模型在机器人任务上的表现,同时关注任务完成度与视觉质量。结果显示,闭源模型(尤其是Wan 2.6)在所有指标上均优于开源及机器人专用模型,Wan 2.6在任务完成度与视觉质量上获得最高分,表明其在物理推理与运动保真度方面存在显著性能差距。
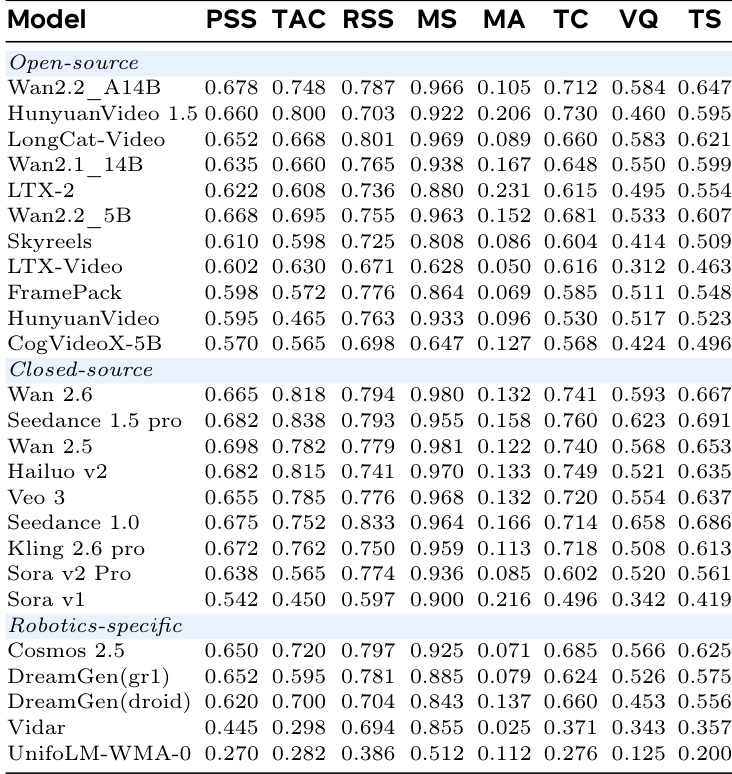
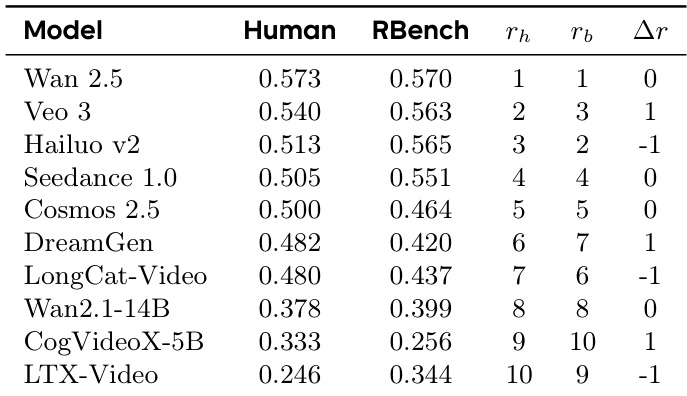
作者通过人类评估与自动化基准(RBench)评估模型性能,结果显示Wan 2.5在两种评估中均获得最高分,紧随其后的是Veo 3和Hailuo v2。人类与RBench评估的排名基本一致,仅模型相对顺序存在微小差异,表明两种评估方法高度相关。