Command Palette
Search for a command to run...
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
Shijie Lian Bin Yu Xiaopeng Lin Laurence T. Yang Zhaolong Shen Changti Wu Yuzhuo Miao Cong Huang Kai Chen
摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型在机器人操作任务中展现出巨大潜力,但通常在面对新指令或复杂多任务场景时泛化能力有限。我们识别出当前训练范式中存在一个关键缺陷:以目标为导向的数据采集方式导致数据集出现偏差。在这些数据集中,仅凭视觉观察即可高度预测语言指令,导致指令与动作之间的条件互信息趋于消失,我们称这一现象为“信息坍缩”(Information Collapse)。结果,模型退化为仅依赖视觉的策略,忽略语言约束,在分布外(Out-of-Distribution, OOD)场景下表现失败。为解决这一问题,我们提出一种名为 BayesianVLA 的新框架,通过贝叶斯分解机制强制模型遵循语言指令。该框架引入可学习的隐式动作查询(Latent Action Queries),构建双分支架构,分别估计仅依赖视觉的先验分布 p(a∣v) 与语言条件下的后验分布 π(a∣v,ℓ)。随后,我们优化策略以最大化动作与指令之间的条件点互信息(Conditional Pointwise Mutual Information, PMI)。该目标有效惩罚了“视觉捷径”行为,并奖励那些能明确解释语言指令的动作。该方法无需额外数据收集,即可显著提升模型泛化能力。在 SimplerEnv 和 RoboCasa 多个基准上的大量实验表明,该方法取得了显著性能提升,尤其在具有挑战性的 OOD SimplerEnv 基准上实现了 11.3% 的准确率提升,充分验证了本方法在将语言稳健地映射至动作方面的有效性。
一句话总结
华中科技大学、中科智谷与合作者提出 BayesianVLA 框架,通过贝叶斯分解与潜在动作查询解决 VLA 模型忽略指令的问题,在无需新数据的情况下,使 SimplerEnv 上的 OOD 泛化能力提升 11.3%。
主要贡献
- 我们识别了 VLA 训练中的“信息坍缩”现象:在以目标驱动的数据集中,仅凭视觉信息即可预测语言指令,导致模型忽略语言并在 OOD 场景中失效。
- 我们提出 BayesianVLA,一种双分支框架,使用潜在动作查询分别建模仅视觉先验与语言条件后验,通过条件点互信息优化以强制显式指令对齐。
- BayesianVLA 在无需新数据的情况下达到最先进水平,包括在 SimplerEnv 上 OOD 性能提升 11.3%,并保留骨干 VLM 的纯文本对话能力。
引言
作者利用视觉-语言-动作(VLA)模型使机器人能够遵循自然语言指令,但发现一个关键缺陷:在目标驱动的数据集中,仅凭视觉观测即可预测指令,导致模型忽略语言并依赖“视觉捷径”,从而在分布外或模糊场景中泛化能力差。为解决此问题,他们提出 BayesianVLA,通过贝叶斯分解与可学习的潜在动作查询训练双分支策略——一个估计仅视觉先验,另一个估计语言条件后验——优化目标为最大化动作与指令之间的互信息。该方法无需新数据,显著提升 OOD 性能,同时保留模型核心语言理解能力,使其在真实部署中更鲁棒可靠。
方法
作者利用贝叶斯框架解决视觉-语言-动作(VLA)模型中的视觉捷径问题,其中由于目标驱动数据集中视觉到语言的确定性映射,指令与动作之间的条件互信息崩溃。为应对这一问题,他们提出最大化动作与指令之间的条件点互信息(PMI),其形式化为后验策略与仅视觉先验之间的对数似然比(LLR)。该目标源自信息论原则,鼓励模型学习仅凭视觉无法预测的、携带指令特定语义的动作表示。
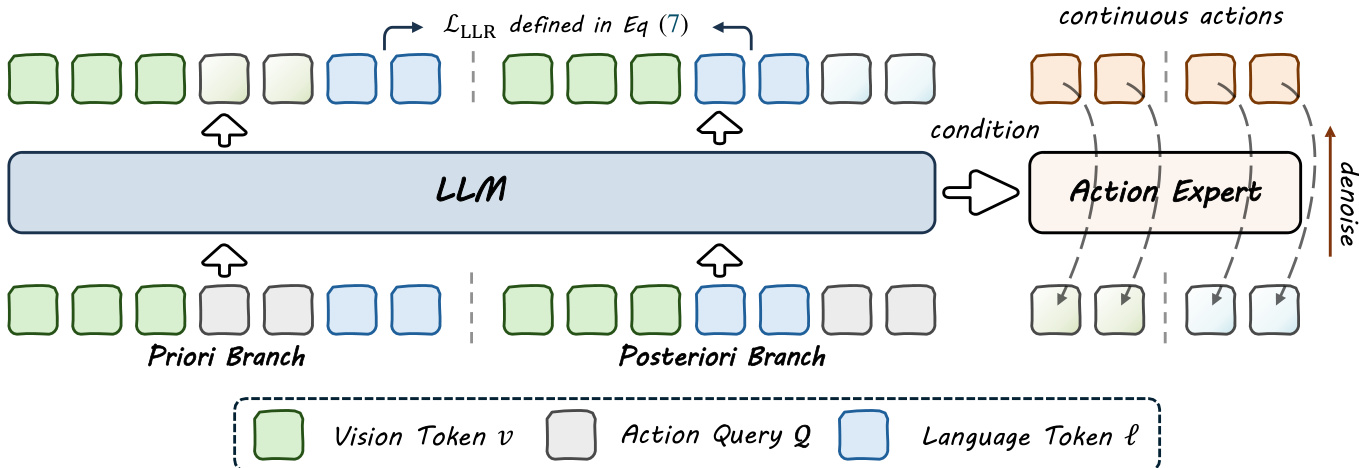
如下图所示,所提出的 BayesianVLA 框架通过共享单一大型语言模型(LLM)主干但为每个分支维护不同输入结构的双分支训练策略运行。核心创新在于使用潜在动作查询——即附加到输入序列中的可学习标记,作为 LLM 与连续动作头之间的专用瓶颈接口。该设计通过利用仅解码器模型的因果掩码,实现对信息流的精确控制,使查询根据其位置关注输入的不同子集。

在先验分支中,输入序列为 [v,Q,ℓ],其中 v 为视觉观测,Q 为动作查询集合,ℓ 为语言指令。由于因果注意力掩码,查询可关注视觉输入但不可关注语言指令,从而生成仅编码视觉依赖信息的隐藏状态 HQprior。这些特征通过流匹配损失 Lprior 预测动作 a,有效学习数据集固有的动作偏差 p(a∣v)。
在后验分支中,输入序列为 [v,ℓ,Q],允许查询同时关注视觉与语言输入。这产生编码视觉与语言完整上下文的隐藏状态 HQpost,用于通过主干流匹配损失 Lmain 预测专家动作 a。两个分支同时训练,共享相同的 LLM 权重。
为显式最大化 LLR 目标,框架计算两个分支中语言标记对数概率的差值。LLR 损失定义为 LLLR=logp(ℓ∣v,HQprior)−sg(logp(ℓ∣v)),其中停止梯度算子防止模型退化基础语言模型能力。该术语优化以强制动作表示携带可解释指令的信息。
总训练目标结合两个分支的动作预测损失与 LLR 正则化项:Ltotal=(1−λ)LFM(ψ;HQpost)+λLFM(ψ;HQprior)−βLLLR。动作解码器使用修正流匹配目标训练,其中扩散 Transformer 预测基于查询特征的动作轨迹速度场。推理时仅执行后验分支生成动作,确保相比标准 VLA 基线无额外计算开销。
实验
- 初步实验表明,标准 VLA 模型即使在目标驱动数据集上训练,也常学习仅视觉策略 p(a|v) 而非真正的语言条件策略 π(a|v,ℓ)。
- 在 RoboCasa(24 项任务)上,仅视觉模型成功率为 44.6%,语言条件基线为 47.8%,表明因视觉-任务相关性,模型对指令依赖极小。
- 在 LIBERO Goal 上,当场景映射至多个任务时,仅视觉模型成功率降至 9.8%(对比基线 98.0%),暴露其在无语言情况下无法解决歧义。
- 在 BridgeDataV2 上,仅视觉模型在训练损失上与完整模型相当(0.13 对比 0.08),但在 OOD SimplerEnv 上灾难性失败(接近 0%),证实其过拟合视觉捷径。
- BayesianVLA 在 SimplerEnv 上平均成功率达 66.5%(对比基线 55.2%),绝对增益 +11.3%,在“将胡萝卜放在盘子上”(+13.6%)和“将茄子放入黄色篮子”(+15.0%)等任务中表现优异。
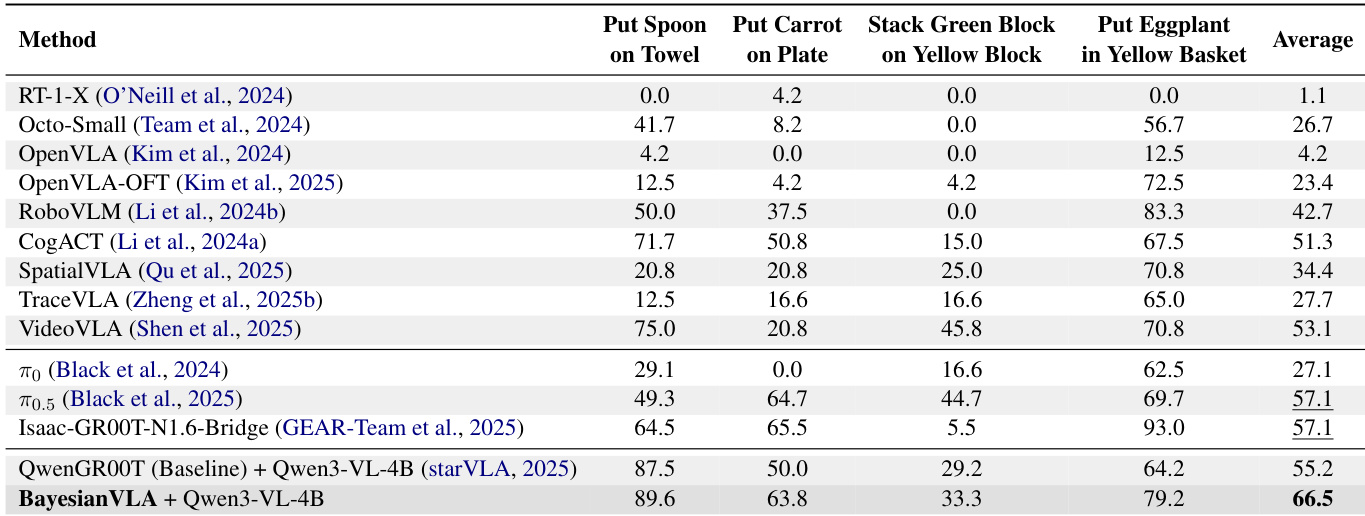
- 在 RoboCasa 上,BayesianVLA 达到 50.4% 平均成功率(对比基线 47.8%),超越所有竞争对手,尤其在模糊任务如“从餐垫到盘子的 PnP 新物体”中显著提升(70.0% 对比仅视觉 34.0%)。
- 消融实验确认贝叶斯分解驱动核心增益(+6.0% 超过仅动作查询),而潜在动作查询通过将 DiT 复杂度从 O(N²) 降至 O(K²) 提升效率。
- 未来工作包括扩展至更大模型(如 Qwen3VL-8B)、真实世界测试及扩展至 RoboTwin/LIBERO 基准。
作者使用 SimplerEnv 基准评估 BayesianVLA,其在 BridgeDataV2 和 Fractal 数据集上训练。结果表明,BayesianVLA 实现 66.5% 的最先进平均成功率,显著优于基线 QwenGR00T(55.2%)及其他强竞争对手,尤其在需精确物体操作的任务中表现突出。
作者使用 SimplerEnv 基准评估 BayesianVLA 与基线模型的性能,结果显示 BayesianVLA 实现 63.5% 的最先进平均成功率,比 QwenGR00T 基线高出 8.3 个百分点。这一提升在需精确物体操作的任务中尤为显著,如“将胡萝卜放在盘子上”和“将茄子放入黄色篮子”,BayesianVLA 在这些任务上相比基线取得显著增益。结果证实所提出的贝叶斯分解有效缓解视觉捷径,促使模型依赖语言指令而非仅视觉线索。

作者使用 RoboCasa 基准评估 VLA 模型,其中 VisionOnly 基线达到 44.7% 的高成功率,表明模型可不依赖语言指令表现良好,因视觉捷径存在。BayesianVLA 超越所有基线,实现 50.4% 的平均成功率,并在仅视觉策略失败的任务中(如“从餐垫到盘子的 PnP 新物体”)显著提升,证实该方法通过利用语言消歧有效缓解视觉捷径。