Command Palette
Search for a command to run...
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力
摘要
扩散型大语言模型(Diffusion Large Language Models, dLLMs)打破了传统大语言模型(LLMs)固有的从左到右生成约束,实现了任意顺序的标记(token)生成。直观上,这种灵活性意味着其解空间严格包含了固定自回归路径的解空间,理论上为数学推理、编程等通用任务解锁了更优越的推理潜力。因此,已有大量研究尝试借助强化学习(Reinforcement Learning, RL)来激发dLLMs的推理能力。然而,在本文中,我们揭示了一个反直觉的现实:当前形式下的任意顺序生成,实际上反而缩小而非拓展了dLLMs的推理边界。我们发现,dLLMs倾向于利用这种顺序灵活性,主动规避那些对探索至关重要的高不确定性token,从而导致解空间过早坍缩。这一发现挑战了现有dLLM强化学习方法的基本前提——这些方法往往投入大量复杂性(如处理组合式生成轨迹、应对不可计算的似然函数等)以维持所谓的“顺序灵活性”。我们进一步证明,通过主动放弃任意顺序生成的自由,转而采用标准的组相对策略优化(Group Relative Policy Optimization, GRPO),反而能更有效地激发dLLMs的推理能力。我们提出的方案——JustGRPO,虽极为简洁,却表现出令人惊喜的有效性(例如在GSM8K基准上达到89.1%的准确率),同时完全保留了dLLMs原有的并行解码能力。项目主页:https://nzl-thu.github.io/the-flexibility-trap
一句话总结
清华大学与阿里巴巴集团的研究人员揭示,扩散式大语言模型(dLLMs)中的任意顺序生成机制,虽然理论上更具扩展性,却因绕过高不确定性逻辑词而意外压缩了推理潜力。他们提出 JustGRPO —— 一种极简的强化学习方法,采用标准自回归训练,在保持并行解码能力的同时显著提升性能(例如在 GSM8K 上达到 89.1%)。
主要贡献
- 尽管扩散式大语言模型的任意顺序生成在理论上更具扩展性,但其反而因允许模型绕过对探索多样化解题路径至关重要的高不确定性词,从而压缩了推理潜力(通过 GSM8K 和 MATH 等基准上的 Pass@k 指标衡量)。
- 论文揭示,这种“灵活性陷阱”源于熵退化:模型优先选择低熵词,导致推理路径在被探索前即被压缩,而自回归解码则迫使模型在关键决策点直面不确定性。
- 为应对该问题,作者提出 JustGRPO —— 一种极简方法,使用组相对策略优化(Group Relative Policy Optimization)在标准自回归顺序下训练 dLLMs,取得优异结果(例如 GSM8K 上达 89.1%),同时保留推理时的并行解码能力,无需复杂的扩散专用 RL 适配。
引言
作者利用理论上支持任意词生成顺序的扩散语言模型(dLLMs),挑战“灵活性提升推理能力”的假设。先前工作假设任意顺序解码可解锁更丰富的推理路径,从而设计出复杂的强化学习(RL)方法以处理组合轨迹和不可计算似然 —— 但这些方法常依赖不稳定近似。作者揭示,反直觉的是,任意顺序会使模型绕过探索多样化推理路径所必需的高不确定性词,过早压缩解空间。其主要贡献 JustGRPO 放弃任意顺序复杂性,采用标准自回归 RL(组相对策略优化)训练 dLLMs,取得优异结果(如 GSM8K 上 89.1%),同时保留推理时的并行解码能力。
数据集

- 作者使用数学推理数据集的官方训练划分,遵循先前工作(Zhao 等,2025;Ou 等,2025)的标准协议。
- 对于代码生成,采用 AceCoder-87K(Zeng 等,2025),然后使用 DiffuCoder 流水线(Gong 等,2025)筛选出 21K 个包含可验证单元测试的挑战性样本。
- 数据直接作为训练输入,未进一步调整混合比例或裁剪;除所述筛选外,未提及元数据构建或额外预处理。
方法
作者采用基于扩散的语言建模框架,其核心机制通过掩码扩散过程运行。该模型称为掩码扩散模型(MDM),通过迭代去噪部分掩码输入状态 xt 生成序列,xt 初始化自完全掩码序列。该过程由连续时间变量 t∈[0,1] 控制,表示掩码比例。在前向过程中,干净序列 x0 中的每个词以概率 t 独立被掩码,得到分布 q(xtk∣x0k),该分布要么保留原词,要么替换为 [MASK] 词。与传统高斯扩散模型不同,MDMs 直接预测掩码位置的干净词。神经网络 pθ(x0∣xt) 估计原始词分布,模型通过最小化负证据下界训练,简化为对掩码词的加权交叉熵损失。
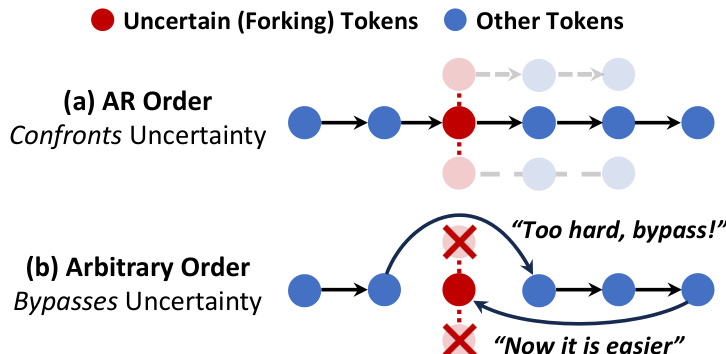
如图所示,模型的生成过程可约束为自回归(AR)顺序(从左到右逐词生成),或任意顺序(非顺序生成)。AR 顺序通过结构化、顺序生成直面不确定性,有利于推理任务;而任意顺序允许非顺序生成绕过不确定性,可能导致次优结果(如“太难,跳过!”和“现在容易了”注释所示)。这一区别突显生成顺序对模型性能的重要性。
为弥合扩散模型的序列级去噪架构与自回归策略框架间的差距,作者提出 JustGRPO 方法。该方法在强化学习阶段明确放弃任意顺序生成,将扩散语言模型转化为明确定义的自回归策略 πθAR。自回归策略通过构建输入状态 x~t 定义,其中过去词可见,未来词被掩码。给定历史 o<t 的下一词 ot 的概率定义为模型在对应位置 logits 的 softmax。该公式允许直接将标准组相对策略优化(GRPO)应用于扩散语言模型。GRPO 目标最大化带 KL 正则项的裁剪代理函数,其中优势通过组统计标准化奖励计算。该方法使模型在保持扩散模型推理速度的同时,获得自回归模型的推理深度。
实验
- 通过 GSM8K、MATH500、HumanEval、MBPP 上的 Pass@k 评估 dLLMs(LLaDA-Instruct、Dream-Instruct、LLaDA 1.5)的推理潜力:AR 解码在 k 增大时表现优于任意顺序,揭示更广的解空间覆盖(例如 k=1024 时 AR 多解决 21.3% 的 HumanEval 问题)。
- 识别任意顺序中的“熵退化”:绕过高熵逻辑词(如“因此”、“因为”)将推理路径压缩为低熵、模式匹配轨迹,减少探索。
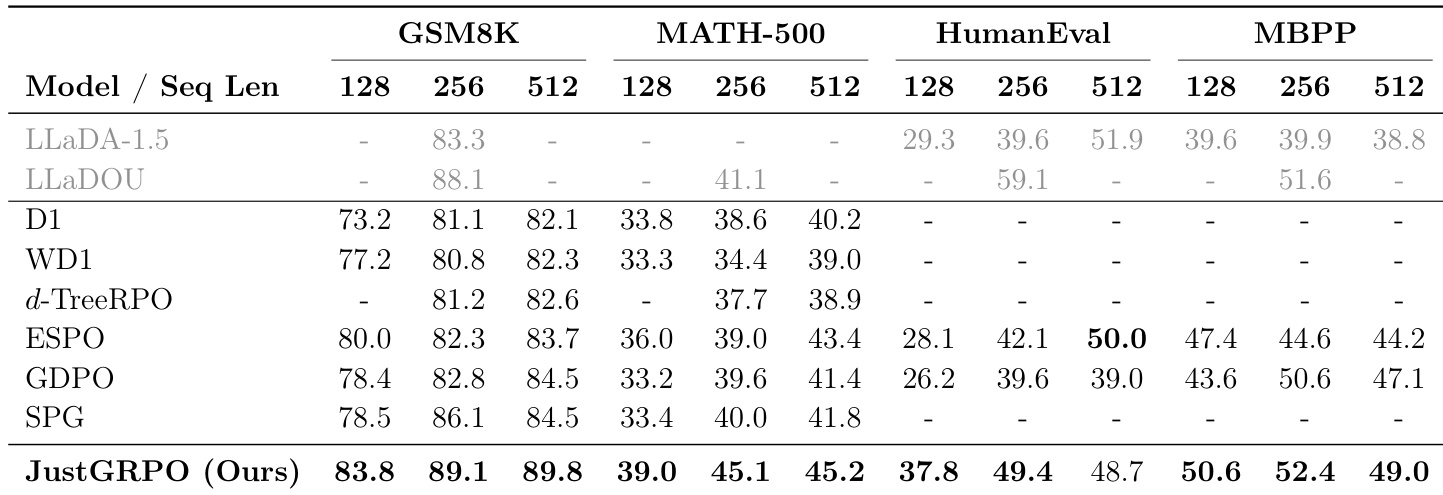
- 引入 JustGRPO:在 LLaDA-Instruct 上强制 AR 顺序训练,取得最先进结果 —— GSM8K 上 89.1%(比 SPG ↑3.0%),MATH-500 上提升 6.1%(优于 ESPO)— 且在不同序列长度(128、256、512)上均保持稳定增益。
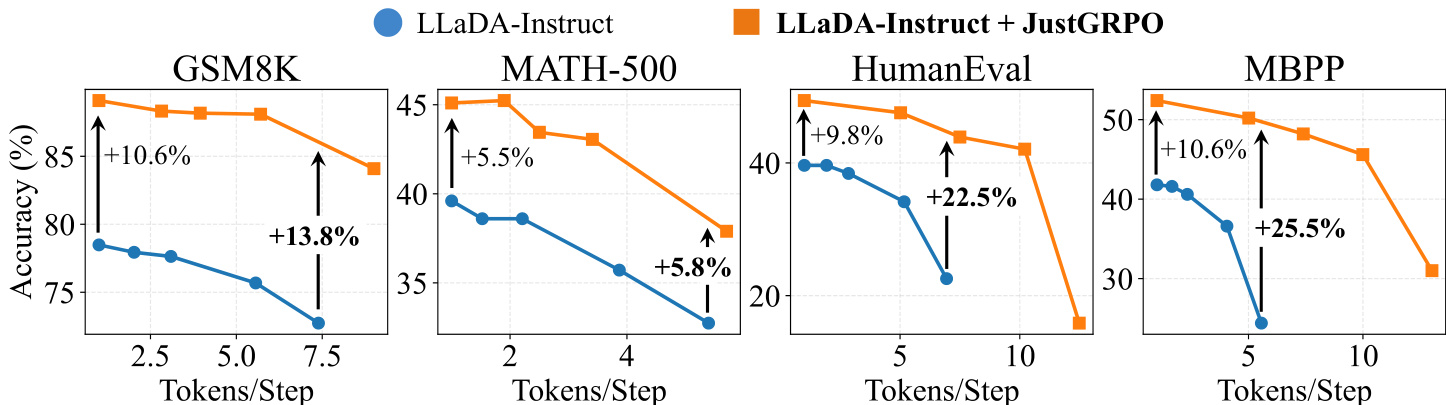
- JustGRPO 保留并行解码能力:在 EB 采样器下,准确率随并行度提升(例如 MBPP 上 ~5 词/步时 +25.5%,1 词/步时 +10.6%),表明推理流形稳健。
- 消融实验确认发现:更小块大小(更接近 AR)提升 Pass@k;更高温度有助于任意顺序但无法匹敌 AR;先进采样器与 AR 高相关(0.970)但仍表现较差。
- 训练效率:JustGRPO 在准确率-时钟时间权衡上优于基于近似的 ESPO;将梯度限制于前 25% 高熵词可加速收敛而不损失性能。
作者使用 JustGRPO 在强化学习阶段以自回归约束训练扩散语言模型,在多个推理与编码基准上取得最先进性能。结果表明该方法持续优于为任意顺序解码设计的方法,在 GSM8K、MATH-500、HumanEval 和 MBPP 上显著提升准确率,同时保留模型推理时的并行解码能力。
作者使用 Pass@k 衡量推理潜力,表明尽管任意顺序在 k=1 时表现具竞争力,但 AR 顺序在样本数增加时表现出显著更强的扩展性。结果表明 JustGRPO 在所有基准上均达到最先进性能,优于先前方法(GSM8K、MATH-500、HumanEval 和 MBPP),且在不同生成长度下保持稳定增益。
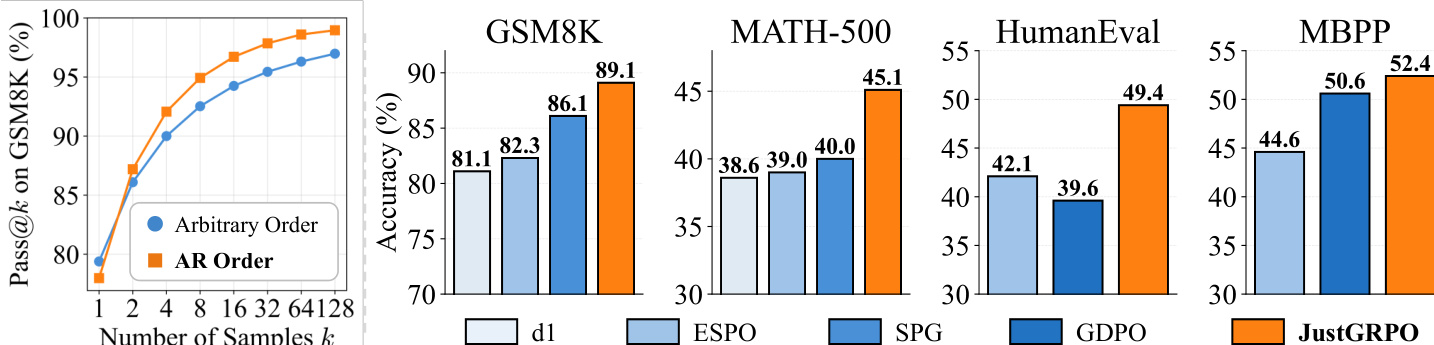
作者使用系统级比较评估 JustGRPO 与现有强化学习方法在推理与编码基准上的性能。结果表明 JustGRPO 在所有任务和序列长度上均达到最先进性能,优于 SPG 和 ESPO 等先前方法,尤其在 GSM8K 和 MATH-500 上表现突出,表明训练时强制自回归顺序可增强推理能力。
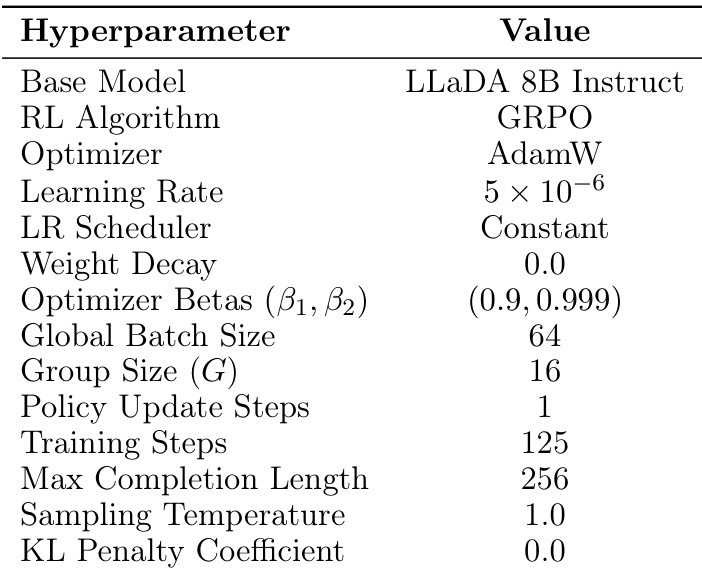
作者使用 GRPO 算法,以 LLaDA 8B Instruct 为基模型,训练 125 步,学习率恒定为 5 × 10⁻⁶,组大小为 16。模型在采样温度为 1.0 且无 KL 惩罚时表现优异,表明训练期间精确似然计算有效,尽管计算成本更高。