Command Palette
Search for a command to run...
HERMES:将KV缓存作为分层内存以实现高效的流式视频理解
HERMES:将KV缓存作为分层内存以实现高效的流式视频理解
Haowei Zhang Shudong Yang Jinlan Fu See-Kiong Ng Xipeng Qiu
摘要
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在离线视频理解任务中取得了显著进展。然而,将这些能力拓展至流式视频输入仍面临挑战,现有模型难以在保持稳定理解性能、实现实时响应以及控制低GPU内存开销之间取得平衡。为解决这一难题,我们提出HERMES——一种无需训练的新型架构,可实现对视频流的实时、精准理解。基于对注意力机制的深入分析,我们首次将键值缓存(KV cache)建模为一种分层记忆框架,能够以多粒度方式封装视频信息。在推理阶段,HERMES通过复用紧凑的KV缓存,实现了在资源受限条件下的高效流式理解。值得注意的是,HERMES在用户查询到达时无需引入额外计算,从而保障了连续视频流交互中的实时响应能力,其首 token 生成时间(TTFT)相比现有最先进方法提升达10倍。即使在视频帧采样率降低高达68%的情况下,HERMES在所有基准测试中仍保持卓越或相当的准确率,尤其在流式视频数据集上最高实现11.4%的性能提升。
一句话总结
复旦大学、上海创新研究院与新加坡国立大学的张华伟等人提出了 HERMES,这是一种无需训练的架构,通过分层 KV 缓存重用实现高效实时视频流理解,在保持内存效率的同时,相比先前方法实现了 10 倍更快的首令牌时间(TTFT)和最高 11.4% 的准确率提升。
主要贡献
- HERMES 引入了一种无需训练的架构,通过将 KV 缓存重新解释为分层内存系统(涵盖感官、工作和长期记忆粒度),在资源受限条件下实现稳定的推理,适用于流式视频理解。
- 通过重用紧凑且分层管理的 KV 缓存,HERMES 相比均匀采样最多减少 68% 的视频令牌,同时实现同等或更优的准确率,包括在流式基准测试中最高 11.4% 的提升。
- HERMES 在查询时无需额外计算,保证实时响应,相比先前无需训练的方法实现 10 倍更快的首令牌时间(TTFT),并在长视频流中维持恒定的 GPU 内存使用。
引言
作者利用 Transformer 键值(KV)缓存的固有结构,将其视为分层内存系统(感官、工作和长期记忆),从而在无需重新训练的情况下实现高效实时的流式视频理解。先前方法要么依赖引入延迟的外部内存系统,要么缺乏细粒度、可解释的缓存管理,因而不适合不可预测的流式输入。HERMES 的主要贡献是一种无需训练、即插即用的框架,在推理过程中重用紧凑且分层管理的 KV 缓存,实现最高 10 倍的首令牌时间加速和 68% 的令牌减少,且无需额外计算,同时在流式基准测试中达到或超越准确率。
数据集

作者使用流式与离线视频理解基准测试的组合,评估模型的时间推理与实时推理能力。数据集组成与用途如下:
-
流式基准测试(用于评估实时与回溯任务):
- StreamingBench(实时视觉理解子集):500 个视频,涵盖 10 项任务(如物体感知、因果推理)的 2,500 个多选题。仅使用此子集。
- OVO-Bench:644 个视频,涵盖 12 项任务的约 2,800 个细粒度多选问答对。作者仅使用实时感知与回溯子集,排除前向主动响应。
- RVS-Ego & RVS-Movie:10 个第一人称视频(来自 Ego4D)+ 22 个电影片段(来自 MovieNet),总计 21+ 小时连续视频。专为实时流式评估设计。
-
离线基准测试(用于评估时间理解与多模态推理):
- MVBench:20 项时间任务(如动作序列、移动方向),源自静态到动态转换。数据来源包括 NTU RGB+D 和 Perception 数据集。
- Egoschema:来自 Ego4D 第一人称视频的 5,000+ 多选问答对,专为长视频理解设计。
- VideoMME:涵盖 6 个领域的 900 个视频,2,700 个问答对,需多模态输入(视频、字幕、音频)。
-
处理与使用:
- 模型通过滑动窗口(如 10,000 个视频令牌)处理视频以管理长序列。
- 令牌压缩由局部与全局提示指导,取决于对话历史是否存在。
- 对于流式任务,模型聚焦实时感知与回溯;排除主动响应。
- 所有基准仅用于评估——无训练数据源自这些基准。
- 元数据包括任务类型(MC/OE)、视频来源与子集标识(如 rt/bw),用于结构化分析。
方法
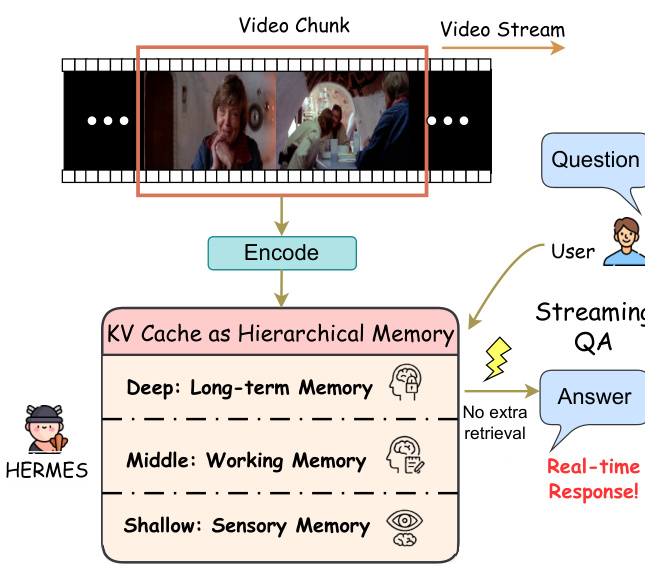
作者提出了 HERMES,一种无需训练的框架,旨在提升多模态大语言模型(MLLM)在流式视频理解场景中的内存效率。HERMES 的核心是分层 KV 缓存架构,通过在模型不同层组织内存,反映不同的认知功能。如下图所示,KV 缓存被划分为三层:浅层作为感官记忆,中层作为工作记忆,深层作为长期记忆。这种分层结构使模型能够保持紧凑但语义丰富的视频流表示。
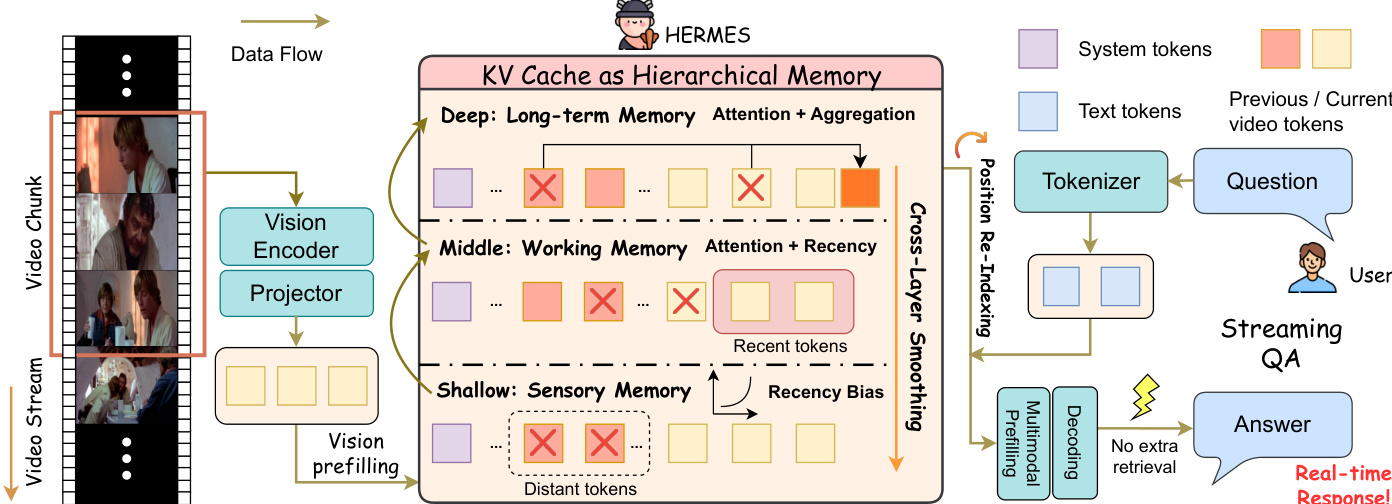
分层 KV 缓存管理策略在各层以不同方式计算令牌重要性分数,以反映其不同角色。在表现出强近因偏好的浅层,令牌重要性使用基于当前位置时间距离的指数遗忘曲线建模,捕捉感官记忆特征。在作为长期记忆的深层,令牌重要性直接从注意力权重推导,使用通用引导提示作为伪查询以处理流式场景。对于连接近因与长期关注的中层,重要性通过层依赖插值权重对近因分数与注意力权重进行插值计算。
为解决各层独立令牌驱逐可能引发的不一致性,HERMES 采用跨层内存平滑机制。该机制将重要性信号从深层传播并平滑至浅层,确保同一物理缓存索引的令牌更一致地保留。平滑后的重要性分数用于执行 Top-K 选择,维持每层固定内存预算。被驱逐的令牌聚合为每层一个摘要令牌,紧凑编码长期信息并保留在 KV 缓存中。
位置重索引用于稳定推理,因为持续累积的流式输入可能导致位置索引超出模型支持的最大范围。该过程将位置索引重新映射至内存预算内的连续范围。实现两种策略:懒惰重索引(仅在索引接近限制时触发)与急切重索引(每压缩步骤执行)。下图展示了 1D RoPE 与 3D M-RoPE 的重索引细节,显示保留的视频令牌在固定系统前缀后以左紧凑方式重新索引,并对缓存键状态应用基于差值的旋转校正以保持注意力正确性。
实验
- 使用 Qwen2.5-VL-7B 与 4K 令牌,HERMES 在 StreamingBench(79.44%)与 OVO-Bench(59.21%)上达到最先进水平,优于基础模型 6.13–6.93%,并超越所有 7B 规模开源模型。
- 在开放式的 RVS 基准测试中,HERMES 相比基础模型最高提升 11.4% 准确率,通过 GPT-3.5-turbo 评估展示其优越的细粒度时空理解能力。
- 在离线任务中,HERMES 在 LLaVA-OV-7B 上超越基础模型在 Egoschema(60.29%)与 VideoMME(58.85%)的表现,在 MVBench 上持平(56.92% vs 57.02%)。
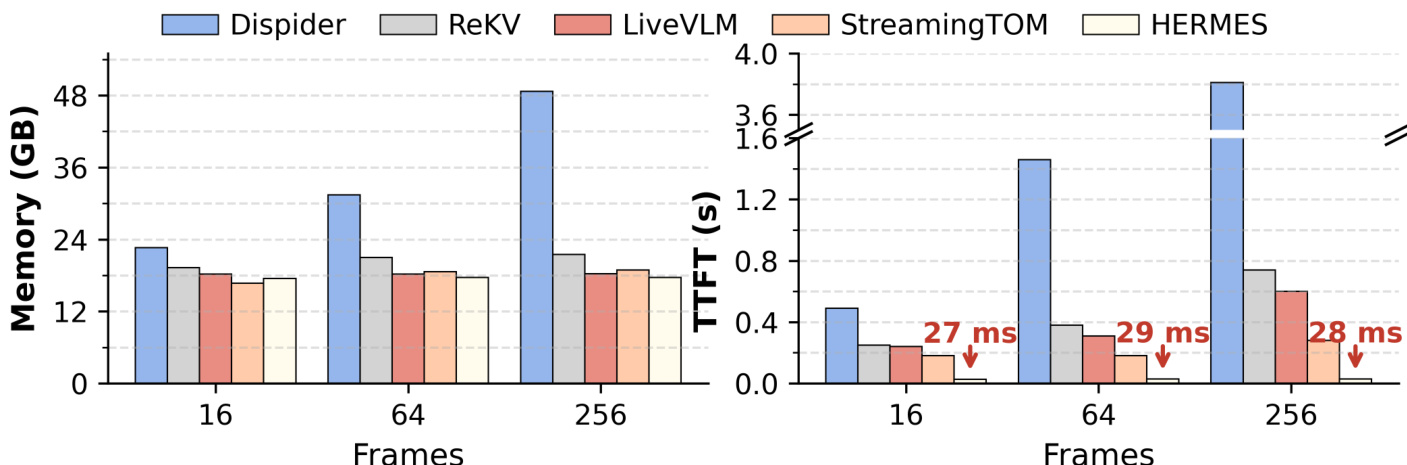
- 效率测试显示 HERMES 维持稳定内存与延迟,在 256 帧设置下比先前最先进方法快 10 倍 TTFT,且峰值内存比 LiveVLM 低 1.04 倍。
- 消融实验确认 4K 内存预算最优,跨层平滑至关重要,深层摘要令牌增强 VideoMME 的长期保留能力。
- 案例研究验证 HERMES 在流式视频场景中优于 LLaVA-OV-7B 的时空推理能力。
作者使用 HERMES 增强 LLaVA-OV-7B 在离线视频理解任务中的表现,特别是在长视频上。结果显示 HERMES 在 VideoMME 上平均准确率达 58.44%,优于基础模型 1.77%,并在长视频片段上表现优于基础模型。
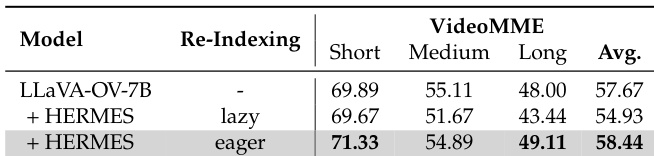
作者使用 HERMES 增强 LLaVA-OV-7B 在离线视频基准测试中的表现,在长视频上取得显著准确率提升,得分为 49.11%,优于基础模型的 48.00%。结果表明 HERMES 在所有视频长度类别中均持续优于基础模型,长视频提升最大,证明其在保留与利用长期视觉信息方面的有效性。
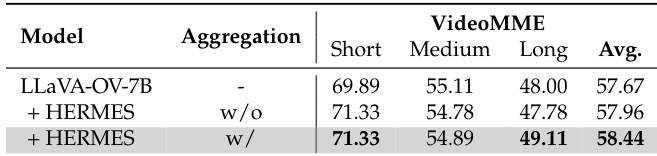
作者使用 HERMES 评估其在离线视频基准测试(包括 MVBench、Egoschema 和 VideoMME)上的表现,这些数据集具有不同持续时间、视频数量与问答对。结果显示 HERMES 在这些数据集上表现具有竞争力,在 MVBench 上准确率与基础模型相当,在长视频数据集 Egoschema 和 VideoMME 上显著提升。

结果表明,随着输入帧数增加,HERMES 维持稳定的 GPU 内存使用与首令牌时间,而其他方法如 All Frames 和 ReKV 出现显著内存增长与延迟峰值,All Frames 在高帧数时触发 CPU 卸载。HERMES 相比先前最先进方法实现 10 倍首令牌时间加速,展示其在实时流式场景中的卓越效率。
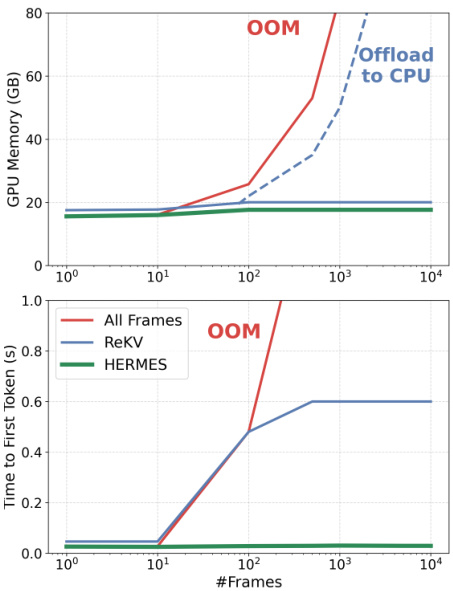
作者使用提供的效率分析比较 HERMES 与其他流式方法,显示 HERMES 在输入帧数增加时维持稳定内存使用并显著减少首令牌时间(TTFT)。结果表明,在 256 帧设置下,HERMES 相比 StreamingTOM 实现 10 倍 TTFT 加速,相比 LiveVLM 减少 1.04 倍峰值内存使用。