Command Palette
Search for a command to run...
LightOnOCR:一种10亿参数的端到端多语言视觉-语言模型,实现最先进的OCR性能
LightOnOCR:一种10亿参数的端到端多语言视觉-语言模型,实现最先进的OCR性能
Said Taghadouini Adrien Cavaillès Baptiste Aubertin
摘要
我们提出 LightOnOCR-2-1B,这是一个参数量为10亿的端到端多语言视觉-语言模型,能够将文档图像(如PDF文件)直接转换为结构清晰、语序自然的文本,无需依赖脆弱的OCR处理流程。该模型在大规模、高质量的蒸馏数据集上进行训练,数据集覆盖了大量扫描文档、法语文档以及科学类PDF,使其在OlmOCR-Bench基准测试中达到当前最优性能,同时模型体积仅为此前表现最佳模型的1/9,推理速度显著更快。我们进一步扩展了输出格式,支持预测嵌入图像的归一化边界框,通过“续训”策略在预训练阶段引入定位能力,并利用基于IoU的奖励机制,通过RLVR(强化学习视觉推理)进行优化。最后,我们通过检查点平均与任务算术合并(task-arithmetic merging)方法提升了模型的鲁棒性。我们已将模型检查点以Apache 2.0许可证开源发布,并分别以各自许可协议公开了训练数据集及LightOnOCR-bbox-bench评估基准。
一句话总结
LightOn 研究人员推出了 LightOnOCR-2-1B,这是一款紧凑的 10 亿参数多语言视觉-语言模型,可直接从文档图像中提取干净、有序的文本,在性能上超越更大模型,同时通过 RLVR 增加图像定位能力,并通过检查点合并提升鲁棒性,模型与基准测试已开源。
主要贡献
- LightOnOCR-2-1B 是一款紧凑的 10 亿参数端到端多语言视觉-语言模型,在 OlmOCR-Bench 上实现了最先进的 OCR 性能,超越了规模达 90 亿参数的模型,同时体积缩小 9 倍且速度显著更快。
- 该模型在 2.5 倍更大、高质量的蒸馏数据集上训练,增强对扫描件、法语文档和科学 PDF 的覆盖,并采用更高分辨率输入与数据增强,以提升鲁棒性和版式保真度。
- 它在预训练阶段引入坐标监督进行图像边界框预测,并通过 IoU 奖励进行 RLVR 优化,在新的 LightOnOCR-bbox-bench 上验证有效;同时通过检查点平均与任务算术合并提升可靠性。
引言
作者利用紧凑的 10 亿参数端到端视觉-语言模型解决文档 OCR 问题,无需依赖脆弱的多阶段流水线,应对现实挑战如模糊阅读顺序、密集科学符号和噪声扫描图像。先前系统依赖复杂、组件耦合的工作流,适应成本高且在领域迁移时表现脆弱。LightOnOCR-2-1B 在 OlmOCR-Bench 上达到最先进水平,同时比先前模型小 9 倍、更快,得益于 2.5 倍更大、高质量的训练数据混合,增强对法语和科学文档的覆盖、更高分辨率输入及 RLVR 引导的优化。它还通过预测边界框扩展 OCR 功能以支持图像定位,训练采用坐标监督和基于 IoU 的奖励,并引入新基准(LightOnOCR-bbox-bench)及轻量级权重空间技术,以控制 OCR 与边界框的权衡。
数据集

-
作者使用通过蒸馏构建的大规模 OCR 训练语料库,其中强大的视觉-语言模型从渲染的 PDF 页面生成转录文本。LightOnOCR-1 使用 Qwen2-VL-72B-Instruct 作为教师模型在 PDFA 数据集上训练;LightOnOCR-2-1B 升级教师模型为 Qwen3-VL-235B-A22B-Instruct,以提升数学保真度并减少伪影。
-
LightOnOCR-2-1B 数据集结合了来自多个来源的教师标注页面,包括扫描文档以增强鲁棒性,以及用于版式多样性的辅助数据。包含由 GPT-4o 标注的裁剪区域(段落、标题、摘要)、空白页样例以抑制幻觉,以及通过 nvpdftex 流程从 arXiv 获取的 TeX 衍生监督。添加公开 OCR 数据集以增加多样性。
-
训练数据标准化为统一格式:去除杂乱 Markdown、水印和格式漂移;空白页和嵌入图像映射为固定目标;应用去重与重复过滤。LaTeX 验证与 KaTeX 兼容性,并记录元数据(如未解析引用、转换状态)以指导过滤。
-
nvpdftex 流程将 arXiv TeX 源码编译为像素对齐的(图像、标记、边界框)三元组,比先前方法提升对齐精度。这些 arXiv 边界框支持 RLVR 实验,但不用于主预训练。该流程也用于构建 LightOnOCR-bbox-bench 基准,使用 290 个手动审查的 OlmOCR-Bench 样本和 565 个自动标注的 arXiv 页面评估图像定位。
-
训练时,作者按选定比例混合数据子集,以可控速率重新注入空白页样例。边界框标注虽从主 OCR 目标中移除,但仍保留并重新格式化为边界框添加任务的独立信号。PDFA 衍生子集按匹配许可证发布为 lightonai/LightOnOCR-mix-0126;标准化边界框数据发布为 lightonai/LightOnOCR-bbox-mix-0126。
方法
作者为 LightOnOCR 采用模块化视觉-语言架构,设计为无需在推理时使用任务特定提示即可执行光学字符识别。框架包含三个主要组件:视觉编码器、多模态投影器和语言模型解码器。视觉编码器基于原生分辨率视觉 Transformer,初始化自预训练的 Mistral-Small-3.1 视觉编码器权重。该选择使模型能处理可变图像尺寸并保留空间结构,对处理具有不同宽高比和精细排版细节的文档至关重要。
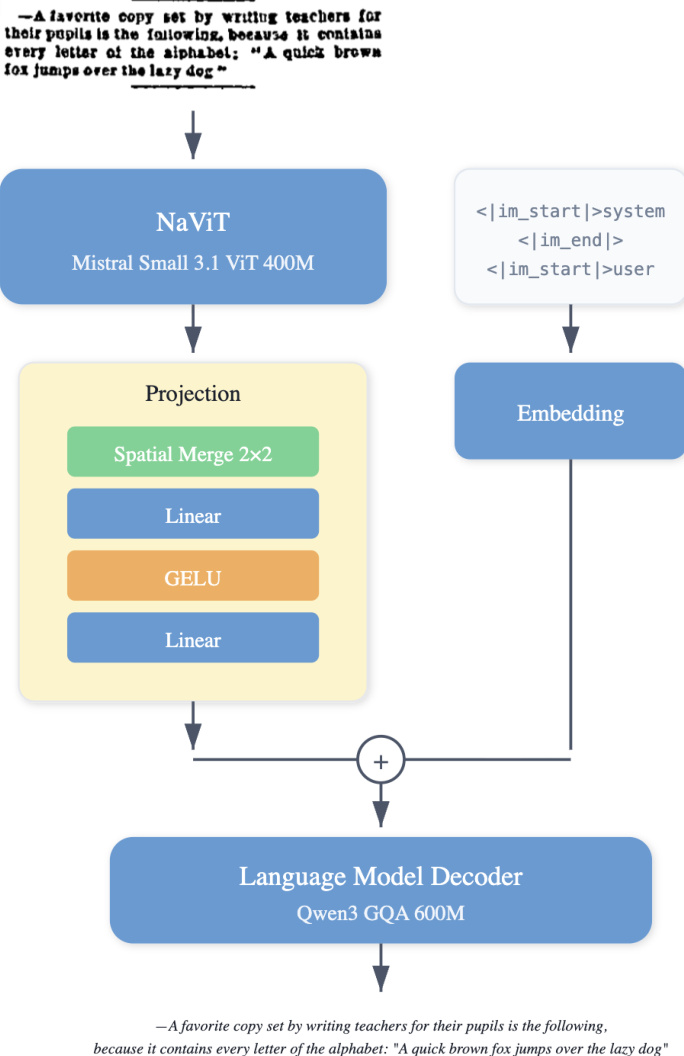
如图所示,视觉编码器处理输入图像并输出视觉标记序列。为管理序列长度并连接视觉与语言模态,采用两层带 GELU 激活的 MLP 作为多模态投影器。投影前应用空间合并因子 2,将 2×2 块分组,视觉标记数量减少 4 倍。此步骤确保高分辨率输入下总标记数可控,同时保留足够空间粒度。投影器随机初始化并从头训练。
语言模型解码器初始化自预训练的 Qwen3 模型。它生成单个线性化页面表示,保留阅读顺序,并为非文本元素(如图像占位符)输出结构化标记。为简化模态间接口,解码器基于单个连续视觉标记块(空间合并后)后接文本标记进行条件化,无需图像中断和图像结束标记。该设计实现紧凑的端到端视觉-语言模型,跨数据集保持一致生成格式。
模型从强大的预训练组件初始化,使 LightOnOCR 继承稳健的视觉表示和多语言语言建模能力,降低训练成本并有效迁移到 OCR 任务。LightOnOCR-2 通过数据和训练方案更新进一步增强架构,包括扩展预训练混合、提升监督质量、增加最大长边分辨率。此外,训练图像定位变体通过扩展输出格式加入归一化坐标以预测嵌入图像的边界框,并使用基于 IoU 奖励的强化学习优化。训练过程还结合轻量级权重空间技术,如检查点平均和任务算术合并,以结合互补增益并控制 OCR 质量与定位精度的权衡。
实验
- 在经过筛选并增强的 OCR 语料库上预训练,使用 AdamW 优化器在 96 张 H100 GPU 上训练;在 6144 标记序列长度下实现高效训练。
- 应用 RLVR 与 GRPO 优化 OCR 和边界框定位,使用可验证奖励;通过 KL 正则化和多轮采样提升性能。
- LightOnOCR-2-1B 在 OlmOCR-Bench 上(不含页眉/页脚)取得 83.2 ± 0.9 分,尽管仅 10 亿参数,仍优于更大模型;在 ArXiv、数学扫描和表格上表现显著提升。
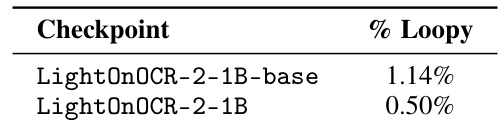
- RLVR 减少重复循环并提升 OCR 质量;边界框预测引入轻微 OCR 下降,可通过任务算术合并(α≈0.1)恢复,平衡 OCR 与 IoU=0.677。
- 在 LightOnOCR-bbox-bench 上,LightOnOCR-2-1B-bbox 在 [email protected] 和计数准确率上超越 9B 基线,同时匹配平均 IoU,证明紧凑模型在定位任务中的有效性。
- 在 H100 上实现端到端基线中最高的推理吞吐量(页/秒),支持可扩展文档处理。
- 将词汇量修剪至 32k 标记,提升拉丁文脚本速度 11.6%,保留 96% 基础 OCR 性能,但使中文等非拉丁文脚本标记数膨胀 3 倍。
- 模型在印刷科学 PDF、多栏版式和拉丁文文档上表现优异;在非拉丁文脚本和手写文本上受限,因训练数据偏差。
- 在 OmniDocBench v1.0 上评估,显示在其规模类别中表现强劲,尤其在 EN/ZH 文档的阅读顺序和版式保真度方面。
- RLVR 明确奖励页眉/页脚存在,导致在原始 OlmOCR-Bench 页眉/页脚指标下得分下降(该指标奖励抑制),与完整页面转录目标不一致。
结果表明,LightOnOCR-2-1B 在 OlmOCR-Bench 上取得最高综合得分,尽管仅 10 亿参数,仍优于更大模型,在文本编辑和表格准确性方面显著提升。该模型在定位任务中也表现强劲,在图像检测基准上实现高 F1 分数和计数准确率,同时保持高效推理吞吐量。
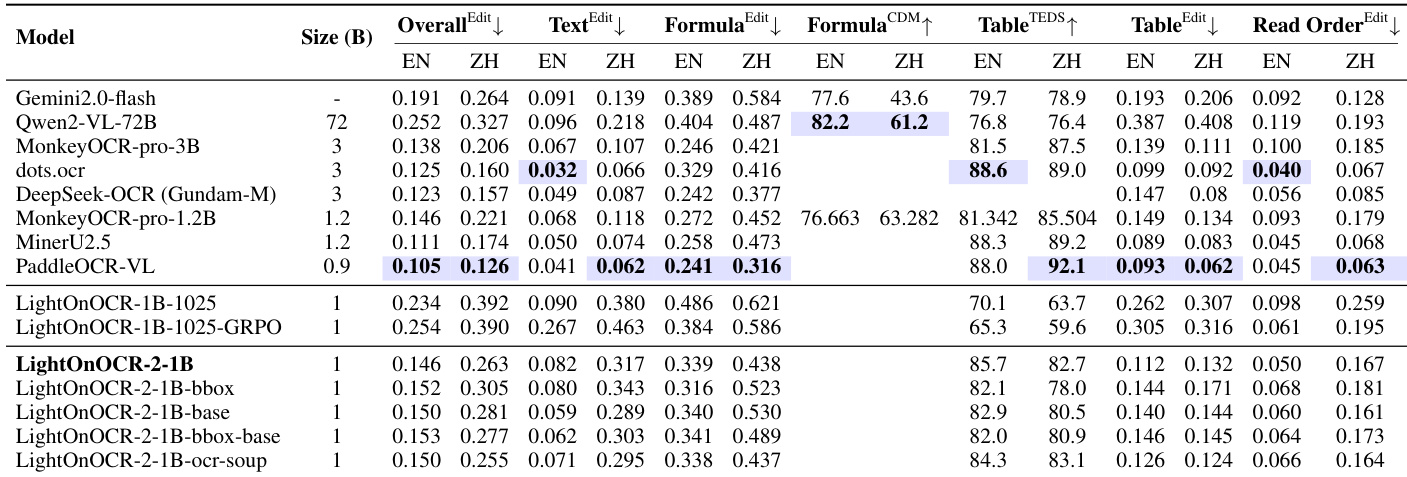
结果表明,LightOnOCR-2-1B-bbox 在 OlmOCR 和 arXiv 子集上均比 Chandra-9B 实现更高的 F₁@0.5 和计数准确率,同时保持相当的平均 IoU,表明其在图像存在检测与数量统计方面更优,且定位准确。

结果表明,应用 RLVR 减少了 LightOnOCR-2-1B 的循环生成比例,基础检查点输出循环比例为 1.14%,RLVR 优化版本降至 0.50%。这表明强化学习过程有效缓解了模型输出中的重复循环。
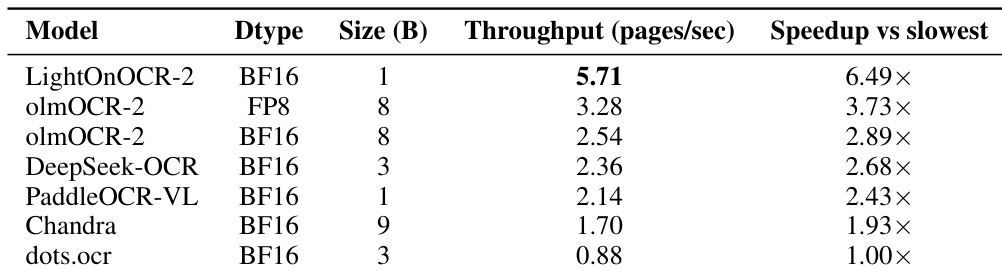
结果表明,LightOnOCR-2 实现每秒 5.71 页的吞吐量,显著优于 olmOCR-2 和 Chandra,后两者分别实现每秒 3.28 和 1.70 页,证明其在单张 NVIDIA H100 GPU 上的卓越推理效率。
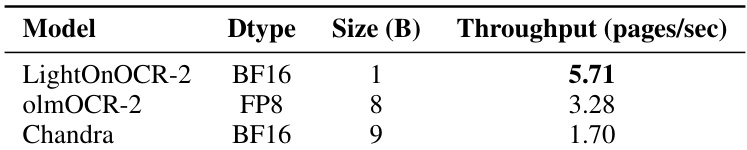
作者评估了 LightOnOCR-2 的推理吞吐量,并与其他端到端 OCR 模型比较,报告 LightOnOCR-2 实现每秒 5.71 页的吞吐量,比对比中最慢模型快 6.49 倍。这表明 LightOnOCR-2 提供比大型端到端基线高得多的吞吐量,适用于高容量文档处理。