Command Palette
Search for a command to run...
OmniTransfer:面向时空视频迁移的统一框架
OmniTransfer:面向时空视频迁移的统一框架
摘要
视频相较于图像或文本能够传递更丰富的信息,能够同时捕捉空间与时间维度的动态变化。然而,现有的大多数视频定制化方法依赖于参考图像或特定任务的时间先验,未能充分挖掘视频固有的丰富时空信息,从而限制了视频生成的灵活性与泛化能力。为解决上述问题,我们提出 OmniTransfer——一种统一的时空视频迁移框架。该框架通过利用帧间多视角信息提升外观一致性,并借助时间线索实现细粒度的时间控制。为统一多种视频迁移任务,OmniTransfer 引入三项核心设计:任务感知的位置偏置(Task-aware Positional Bias),可自适应地利用参考视频信息,以优化时间对齐或增强外观一致性;参考与目标分支解耦的因果学习(Reference-decoupled Causal Learning),通过分离参考分支与目标分支,实现精准的参考信息迁移,同时提升计算效率;以及任务自适应的多模态对齐(Task-adaptive Multimodal Alignment),利用多模态语义引导,动态识别并应对不同任务需求。大量实验表明,OmniTransfer 在外观迁移(身份与风格)和时间迁移(摄像机运动与视频特效)方面均显著优于现有方法,且在动作迁移任务中无需依赖姿态信息即可达到与姿态引导方法相当的性能。该工作确立了一种灵活、高保真的视频生成新范式。
一句话总结
字节跳动智能创作实验室的研究人员提出了 OmniTransfer,这是一种统一的时空视频迁移框架,利用多视角和时序线索实现外观一致性与细粒度控制,在风格、身份、动作和相机效果迁移任务中优于先前方法,且无需依赖姿态或任务特定先验。
主要贡献
- OmniTransfer 提出了一种统一的时空视频迁移框架,克服了现有方法依赖静态参考或任务特定先验的局限,通过多帧视频线索实现外观与时序控制,适用于身份、风格、动作和相机效果等多种任务。
- 该框架整合了三个创新组件:任务感知位置偏置(用于自适应时空对齐)、参考解耦因果学习(实现无需全注意力机制的高效参考迁移)、任务自适应多模态对齐(利用 MLLM 引导的 MetaQueries 动态处理跨任务语义)。
- 在标准基准上评估表明,OmniTransfer 在外观与时序迁移质量上优于先前方法,在无需姿态输入的情况下可与姿态引导方法在动作迁移上媲美,并比全注意力基线减少 20% 运行时间。
引言
作者利用视频丰富的时空结构,克服了先前依赖静态图像或姿态/相机参数等任务特定先验方法的局限性,这些方法限制了灵活性与泛化能力。现有方法在统一外观与动作迁移方面表现不佳,常需微调或在现实场景下失败。OmniTransfer 引入三项核心创新:任务感知位置偏置(自适应对齐时序或空间线索)、参考解耦因果学习(实现无需复制的高效单向迁移)、任务自适应多模态对齐(利用多模态提示动态路由语义指导)。这些组件共同使单一模型可处理多样化的视频迁移任务(包括身份、风格、动作和相机运动),同时提升保真度、减少 20% 运行时间,并泛化至未见任务组合。
数据集

- 作者使用五个专用测试集评估时空视频迁移,每个测试集针对一个子任务。
- 身份迁移:50 个不同人物视频,每个配有两个提示以衡量身份一致性。
- 风格迁移:20 种未见过的视觉风格,每种用两个提示评估风格变化。
- 效果迁移:50 种从视觉特效网站获取的未见过视觉效果。
- 相机运动迁移:50 个专业拍摄视频,包含复杂相机轨迹。
- 动作迁移:50 个流行舞蹈视频,捕捉多样且细粒度的身体动作。
- 所有测试集均用于定性与定量评估,未提及训练或过滤——纯粹用于基准模型性能。
方法
作者以 Wan2.1 I2V 14B 扩散模型为基础架构,构建于其扩散 Transformer(DiT)模块之上,该模块结合自注意力与交叉注意力机制。模型输入为潜在表示 lt∈Rf×h×w×(2n+4),由沿通道维度拼接三部分构成:潜在噪声 zt、条件潜在 c 与二值掩码潜在 m。潜在噪声 zt 通过对 VAE 压缩视频特征 z 添加时间步 t 噪声获得;条件潜在 c 由编码条件图像 I 与零填充帧拼接生成;二值掩码潜在 m 用 1 标记保留帧,0 标记生成帧。每个 DiT 块内的自注意力采用 3D 旋转位置嵌入(RoPE),定义为 Attn(Rθ(Q),Rθ(K),V)=softmax(dRθ(Q)Rθ(K)⊤)V,其中 Q、K、V 是输入潜在的可学习投影,Rθ(⋅) 对查询与键应用 RoPE 旋转。交叉注意力将提示 p 的文本特征整合为 Attn(Q, Kp, Vp)。
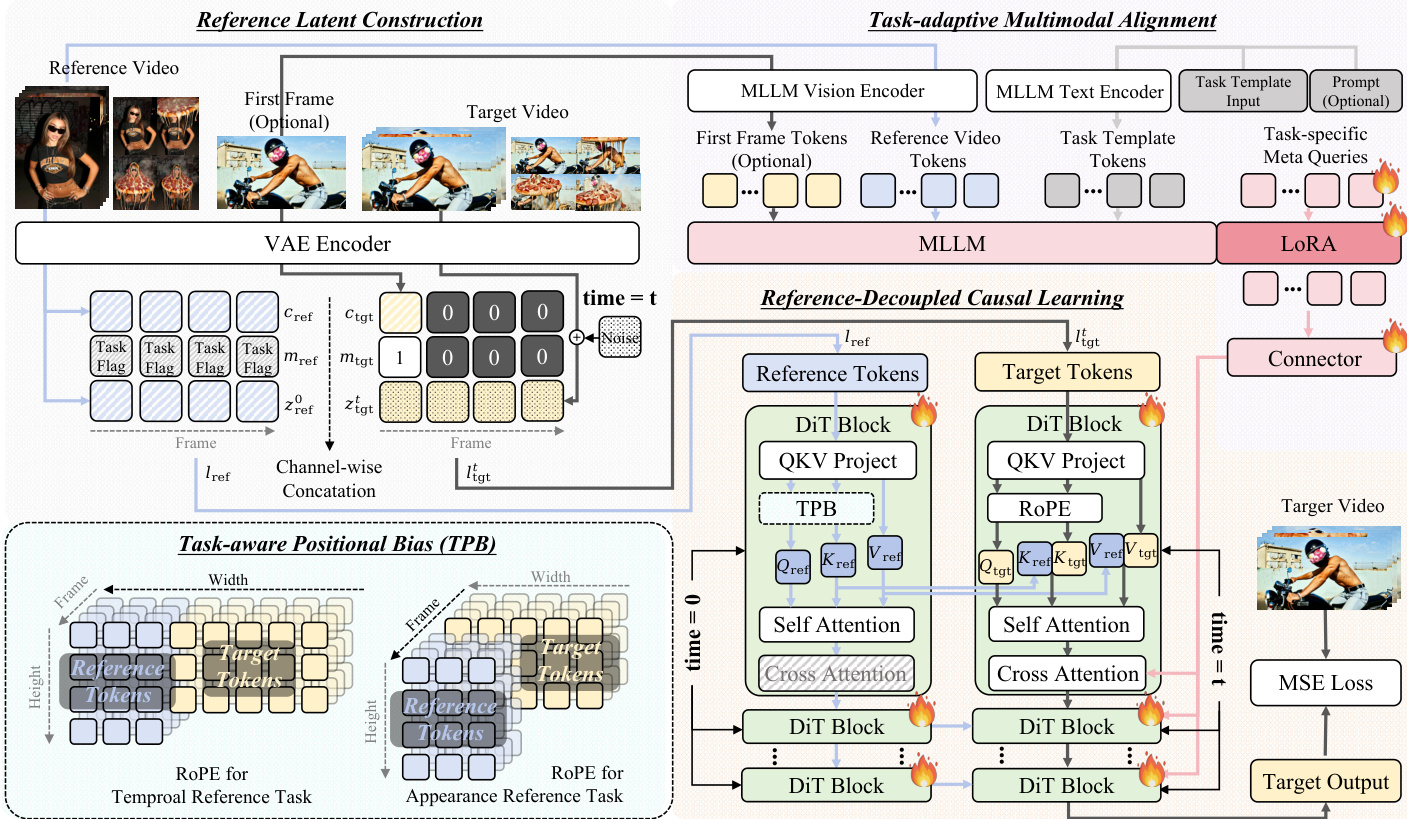
如下图所示,OmniTransfer 框架包含四个关键组件:参考潜在构建、任务感知位置偏置、参考解耦因果学习与任务自适应多模态对齐。流程始于参考潜在构建:参考视频与目标视频经 VAE 编码器生成潜在表示。参考视频潜在与任务特定标志及二值掩码结合形成参考潜在 lref,目标视频潜在类似处理形成 ltgt。这些潜在随后用于后续模块。
任务感知位置偏置(TPB)模块对参考视频潜在的 RoPE 引入偏移,以利用空间与时序上下文线索。对于时序参考任务,沿空间(宽度)维度偏移,偏移量等于目标视频宽度 wtgt,以利用空间上下文线索实现时序一致性。对于外观参考任务,沿时序维度偏移,偏移量等于目标视频帧数 f,以利用外观信息的时序传播。形式化表示为 Rθ∗(⋅)={Rθ(⋅,Δ=(0,wtgt,0)), 用于时序参考Rθ(⋅,Δ=(f,0,0)), 用于外观参考,其中 Δ=(ΔT,ΔW,ΔH) 表示时序、宽度与高度维度的偏移。

参考解耦因果学习模块将参考与目标分支分离,实现因果且高效的迁移。参考分支通过一系列 DiT 块处理参考潜在 lref,目标分支处理目标潜在 ltgt。目标分支的自注意力与交叉注意力机制设计为独立于参考分支,确保目标生成过程不受参考内部状态影响。此解耦实现更高效且因果的迁移,目标分支可仅基于提供的参考与提示生成目标视频。
任务自适应多模态对齐模块通过用多模态大语言模型(MLLM,具体为 Qwen-2.5-VL)表示替代原始 T5 特征,增强跨任务语义理解。MLLM 输入包括目标视频首帧标记、参考视频标记、模板标记与提示标记。为提取任务特定表示,作者引入一组专用于各任务的可学习标记。对于时序任务,这些标记聚合参考视频的时序线索与目标首帧内容,捕捉跨帧动态。对于外观任务,它们融合参考的身份或风格信息与提示标记的语义上下文。MLLM 通过 LoRA 微调实现参数高效适配,其输出经三层多层感知机(MLP)后仅注入目标分支。这确保目标分支的交叉注意力定义为 Attn(Qtgt, KMLLM, VMLLM),其中 KMLLM 与 VMLLM 由对齐的 MLLM 特征导出,从而增强任务级对齐而不干扰参考分支。
实验
- 通过三阶段流水线训练:先训练 DiT 块,再训练连接器对齐,最后联合微调(10K、2K、5K 步;学习率=1e-5,批次=16),使用自定义视频数据集进行时空迁移。
- 身份迁移:在 VSim-Arc/Cur/Glint 指标上优于 ConsisID、Phantom、Stand-in;保留精细面部细节(如痤疮),生成多样姿态同时保持跨帧身份一致。
- 风格迁移:在 CLIP-T、美学评分与 VCSD 上超越 StyleCrafter 与 StyleMaster;有效捕捉视频级风格,优于基于图像的基线。
- 效果迁移:在用户研究中(效果保真度、首帧一致性、视觉质量)优于 Wan 2.1 I2V 与 Seedance;证明复杂效果需视频参考。
- 相机运动迁移:在用户评估中优于 MotionClone 与 CamCloneMaster;独特复现电影与专业跟拍镜头,无需分辨率裁剪。
- 动作迁移:使用更小的 14B 模型在动作保真度上匹配 WanAnimate(28B);无需姿态引导即可保持外观,自然处理多人场景。
- 消融研究:完整模型(+TPB +RCL +TMA)提升动作迁移效果,减少任务混淆,缓解复制粘贴伪影,增强语义控制(如生成正确对象/姿态);RCL 同时加速推理 20%。
- 组合迁移:实现无缝多任务视频迁移(如身份+风格+动作),证明对未见任务组合的强大泛化能力。
结果表明,所提方法在风格迁移所有三项指标上优于 StyleCrafter 与 StyleMaster,取得视频 CSD(VCSD)、CLIP-T 与美学评分最高分。作者用这些定量结果证明其风格一致性与视觉质量优于现有文本到视频风格化方法。

作者将所提方法与 Wan2.1 I2V 和 Seedance 在效果迁移上对比,通过用户研究评估效果保真度、首帧一致性与整体视觉质量。结果表明,所提方法在三项指标上得分最高,优于基线。

结果表明,所提方法在图像一致性与质量上得分最高,分别为 3.88 与 3.45,优于 MimicMotion 与 WanAnimate。尽管 WanAnimate 动作保真度得分更高,所提方法在所有评估指标上表现具竞争力。

作者进行消融研究评估模型各组件影响。结果表明,添加 TPB 提升外观一致性与时序质量,添加 RCL 进一步增强两项指标。完整模型在外观与时序一致性上得分最高,推理时间略有增加。

作者将所提方法与 SOTA 方法在身份迁移上对比,使用人脸识别指标与 CLIP-T 得分。结果表明,所提方法在 VSim-Arc 与 VSim-Cur 得分最高,同时在 CLIP-T 对齐上优于其他方法,表明其身份保留与文本-视频对齐能力更优。
