Command Palette
Search for a command to run...
Paper2Rebuttal:一种用于透明化作者回复辅助的多智能体框架
Paper2Rebuttal:一种用于透明化作者回复辅助的多智能体框架
Qianli Ma Chang Guo Zhiheng Tian Siyu Wang Jipeng Xiao Yuanhao Yue Zhipeng Zhang
摘要
撰写有效的反驳意见是一项高风险任务,不仅需要语言表达的流利性,更要求对审稿人意图与论文细节之间实现精准匹配。当前的解决方案通常将该任务视为直接的文本生成问题,因而普遍存在幻觉、遗漏审稿意见以及缺乏可验证依据等缺陷。为克服这些局限,我们提出 RebuttalAgent——首个将反驳生成重构为以证据为中心的规划任务的多智能体框架。该系统将复杂的审稿意见分解为基本关切点,并通过融合压缩摘要与高保真原文内容,动态构建混合上下文,同时集成自主且按需触发的外部文献检索模块,以解决依赖外部文献支持的疑难问题。在正式撰写反驳文本之前,RebuttalAgent先生成可审查的回应规划,确保每一项论点均明确基于内部证据或外部文献。我们在所提出的 RebuttalBench 基准上验证了该方法,结果表明,我们的流水线在覆盖度、忠实度与策略一致性方面均显著优于现有强基线模型,为同行评审过程提供了一种透明且可控的智能辅助工具。代码将公开发布。
一句话总结
上海交通大学的研究人员提出了 REBUTTALAGENT,这是一个将反驳写作视为基于证据规划的多智能体框架,通过动态整合内部摘要与外部搜索,确保回应有据可依、忠实于原文,在 REBUTTALBENCH 基准测试中优于基线方法,用于辅助同行评审。
主要贡献
- REBUTTALAGENT 将反驳生成重构为以证据为中心的规划任务,采用多智能体系统将审稿人反馈分解为原子化关切点,并从内部稿件段落和外部文献构建混合上下文,确保可验证的依据。
- 该框架引入“先验证后撰写”工作流,结合人工介入检查点,在起草前实现战略规划和全局一致性校验,从而减少幻觉并提升对原文的忠实度。
- 在提出的 REBUTTALBENCH 基准上评估,该系统在覆盖度、可追溯性和论证连贯性方面优于直接生成和聊天式大语言模型基线,为高风险同行评审提供透明、作者可控的工具。
引言
作者利用多智能体框架,将反驳写作从自由文本生成任务转变为结构化、以证据驱动的规划过程。先前方法——无论是微调的大语言模型还是交互式聊天界面——在幻觉、缺乏可追溯性以及不透明的工作流方面存在困难,这些工作流掩盖了诸如关切解析和证据检索等关键推理步骤。REBUTTALAGENT 通过将审稿人反馈分解为原子化关切点、动态构建混合内部/外部证据上下文、并强制执行“先验证后撰写”管道(含人工介入检查点)来解决这些问题,确保每个回应都有据可依、一致且可审计,显著优于现有方法在覆盖度、忠实度和战略连贯性方面的表现。
数据集

作者使用 REBUTTALBENCH,这是一个从真实 ICLR OpenReview 同行评审线程派生的专用基准,用于评估反驳生成系统。该数据集由两大部分组成:
-
REBUTTALBENCH-CORPUS(9.3K 对):
- 来源:RE² 数据集(Zhang 等,2025)的 ICLR 2023 子集。
- 筛选:仅保留具有明确审稿人后续信号的线程;剔除模糊案例。
- 结构:每条记录包含初始审稿人批评、作者反驳及审稿人后续反应,用于将样本分类为“正面”(关切已解决)或“负面”(关切未解决)。
- 用途:作为广泛评估池,用于分析与模型调优。
-
REBUTTALBENCH-CHALLENGE(20 篇论文):
- 构建:选取 20 篇拥有超过 100 名审稿人且已解决/未解决关切点高度多样化的论文。
- 目的:形成紧凑、具挑战性的基准,用于标准化比较反驳质量。
评估框架:
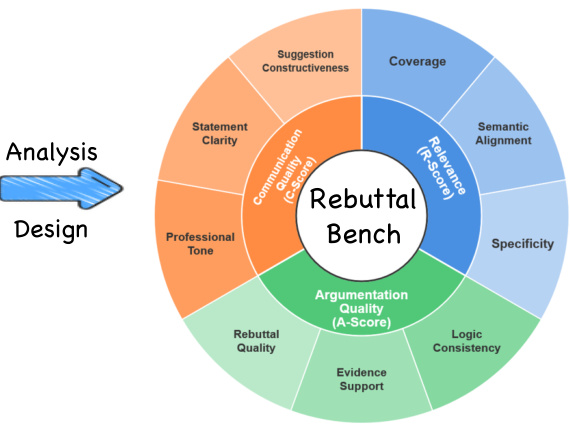
- 分数为三个维度的加权组合:相关性(R)、论证性(A)和沟通性(C),每个维度分为三个子项(共 9 项)。
- R1–R3:覆盖度、语义对齐、具体性。
- A1–A3:逻辑一致性、证据支持、回应参与度。
- C1–C3:专业语气、清晰度、建设性。
- 分层:数据按可靠性分层:
- 第一层(黄金):客观分数变化或明确修订声明。
- 第二层(高置信度):无分数变化但大语言模型情感置信度 ≥0.7。
- 第三层(中置信度):中等置信度(0.4 < 置信度 < 0.7)。
- 基线协议:多轮反驳生成,使用固定提示、论文文本和前轮摘要;每轮输出限制在 200 字以内。
处理与模型训练中的使用:
- 作者未在 REBUTTALBENCH 上训练;该数据集仅用于评估。
- 训练数据(此处未描述)是独立的;REBUTTALBENCH 测试模型在生成事实依据充分、战略细微且符合审稿人期望的反驳方面的表现。
- 元数据包括审稿人后续信号、层级标签和组件分数,支持超越流畅性的细粒度分析。
方法
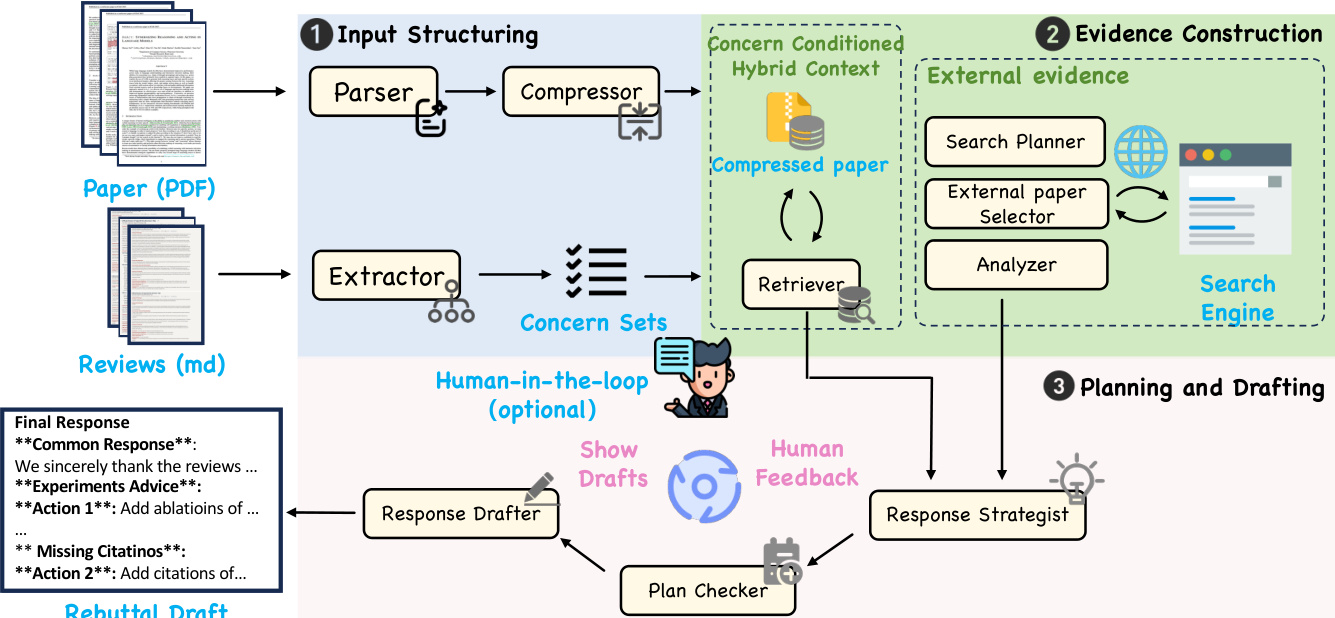
作者利用多智能体框架 RebuttalAgent,旨在将反驳过程转变为结构化且可检查的工作流。系统通过管道运行,将复杂推理分解为专业智能体和轻量级检查器,如框架图所示。该架构暴露关键决策点,允许作者保留对反驳战略立场和最终措辞的完全责任。
管道始于输入结构化,其中原始稿件和审稿意见被提炼为优化下游推理的浓缩表示。解析智能体将稿件 PDF 转换为段落索引格式,以保持结构完整性。压缩智能体随后将这些段落浓缩为保留关键技术陈述和实验结果的简洁表示,作为后续模块的导航锚点。为确保保真度,一致性检查器验证每个浓缩单元与其来源的对应关系,若检测到遗漏主张或语义漂移则触发重新处理。同时,提取智能体将原始审稿反馈解析为离散且可处理的原子化关切点,通过分组相关子问题并分配初步类别来组织批评。覆盖检查器验证输出是否保留意图和适当粒度,确保实质性要点保持独立而不被过度分割或错误合并。最终生成的原子化关切点结构列表构成证据收集和回应规划的基础单元。
在输入结构化之后,系统进入证据构建阶段。对于每个原子化关切点,系统通过在压缩稿件表示中搜索识别最相关部分。它选择性扩展这些焦点,通过检索对应原始文本替换特定浓缩单元,同时保留文档其余部分的摘要形式。这产生一个原子化关切点条件下的混合上下文,结合压缩视图的效率与原始文本的精确性,使系统能够使用精确引用和详细证据支持其推理,而不至于压垮上下文窗口。当内部数据不足时,系统通过外部支持增强证据包。搜索规划器制定有针对性的搜索策略,检索步骤通过学术搜索工具收集候选论文。筛选智能体过滤这些候选者以确保相关性和实用性,管道最终将选定作品解析为结构化证据简报,突出关键主张和实验对比,便于引用。
最后阶段涉及规划与起草。系统实施一种分叉式推理策略,严格区分解释性辩护与必要干预。对于可通过现有数据解决的关切,策略智能体直接从混合上下文中合成论点并锚定在稿件文本中。当系统检测到需要新实验或基线时,它明确抑制结果生成,转而产生具体行动项作为建议。该设计通过强制结构暂停防止结果捏造,作者必须验证或执行建议任务。由此产生的计划作为交互式人工介入检查点,允许作者主动优化战略逻辑。仅在作者验证这些战略决策后,起草智能体才将计划转化为最终回应,确保每个主张都基于现实。可选地,起草者还可从已验证计划生成提交风格的反驳草稿,将任何尚未进行的实验呈现为明确占位符。
实验
- 在 RebuttalBench 上使用 0–5 分制(涵盖相关性、论证性和沟通质量)评估 REBUTTALAGENT 与 SOTA 大语言模型(GPT-5-mini、Grok-4.1-fast、Gemini-3-Flash、DeepSeekV3.2)的对比表现;REBUTTALAGENT 在所有维度上持续优于基线,相关性提升最大(DeepSeekV3.2 +0.78,GPT5-mini +1.33)和论证性(+0.63),沟通性提升较小但一致。
- 提升源于结构化管道(关切分解、证据合成、规划),而非模型容量——即使使用相同基础模型,也显示出持续改进;较弱基础模型(如 GPT5-mini)相对提升更大(平均 +0.55),强模型(Gemini-3-Flash:+0.33)提升较小,表明任务结构化可补偿生成能力的不足。
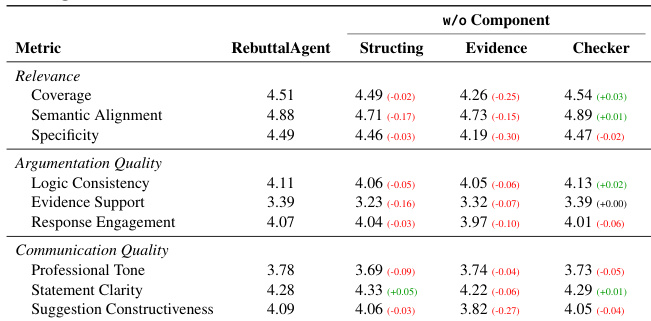
- 消融研究表明证据构建最关键——移除后相关性和沟通性下降最大(覆盖度:4.51 → 4.26;建设性:4.09 → 3.82);输入结构化和检查器贡献较小但可测量,确认模块互补性。
- 案例研究显示 REBUTTALAGENT 输出包含明确行动项、证据关联澄清和范围限定待办清单,通过在起草前揭示可验证交付物减少幻觉和过度承诺,而基线大语言模型则生成无依据的叙述。
- 系统在真实审稿人查询(如理论清晰度、指标有效性)上验证,生成结构化反驳策略与具体交付物(修订命题、实证图、新引理)及可行待办清单,无需新训练或大规模数据收集。
作者使用结构化管道通过将任务分解为关切结构化、证据构建和验证来提高反驳质量。结果表明 RebuttalAgent 在所有评估维度上持续优于基线模型,相关性和论证质量提升最大,沟通质量提升较小但一致。
作者使用结构化智能体框架 RebuttalAgent,通过将任务分解为关切结构化、证据构建和验证来改进反驳回应。结果表明 RebuttalAgent 在所有评估维度上持续优于强大的闭源大语言模型,相关性和论证质量提升最大,表明系统推理和证据组织比原始模型能力更为关键。
