Command Palette
Search for a command to run...
TwinBrainVLA:通过非对称Transformer混合模型释放通用VLM在具身任务中的潜力
TwinBrainVLA:通过非对称Transformer混合模型释放通用VLM在具身任务中的潜力
摘要
标准的视觉-语言-动作(Vision-Language-Action, VLA)模型通常通过对一个统一的视觉-语言模型(Vision-Language Model, VLM)主干网络进行微调,以显式地实现机器人控制。然而,这种范式在保持高层级的通用语义理解能力与学习低层级、细粒度的感知-运动技能之间产生关键矛盾,常常导致模型“灾难性遗忘”其开放世界下的泛化能力。为解决这一冲突,我们提出一种新型架构——TwinBrainVLA,该架构通过协同一个保留通用语义理解能力的通用型VLM与一个专注于具身本体感知的专用型VLM,实现联合机器人控制。TwinBrainVLA 采用一种新颖的非对称混合Transformer(Asymmetric Mixture-of-Transformers, AsyMoT)机制,将一个冻结的“左脑”(Left Brain)与一个可训练的“右脑”(Right Brain)进行协同。其中,“左脑”保留强大的通用视觉推理能力,而“右脑”则专注于具身感知任务。该设计使“右脑”能够动态地从冻结的“左脑”中查询语义知识,并将其与本体感知状态融合,为一个基于流匹配(Flow-Matching)的动作专家模型提供丰富的条件输入,从而生成高精度的连续控制指令。在 SimplerEnv 和 RoboCasa 基准测试上的大量实验表明,TwinBrainVLA 在操作性能上显著优于当前最先进的基线方法,同时明确保留了预训练VLM所具备的全面视觉理解能力,为构建兼具高层语义理解与底层物理灵巧性的通用机器人提供了极具前景的新方向。
一句话总结
来自哈工大、中智协创及合作者的研究人员提出了TwinBrainVLA,一种采用AsyMoT机制融合冻结语义理解与可训练本体感知的双脑VLA架构,使机器人在掌握精确控制的同时不遗忘开放世界视觉能力,已在SimplerEnv和RoboCasa上验证。
主要贡献
- TwinBrainVLA引入了一种双流VLA架构,将通用语义理解(冻结的左脑)与具身感知(可训练的右脑)解耦,解决了为机器人控制微调单体VLM时引发的灾难性遗忘问题。
- 采用非对称混合Transformer(AsyMoT)机制,实现两个VLM路径之间的动态跨流注意力,使右脑能将本体状态与左脑的语义知识融合,从而生成精确动作。
- 在SimplerEnv和RoboCasa上评估,TwinBrainVLA在操作任务中优于当前最先进的基线模型,同时保留预训练VLM的开放世界视觉理解能力,验证了其在通用机器人控制中的有效性。
引言
作者利用双脑架构解决视觉-语言-动作(VLA)模型中的核心矛盾:在保留通用语义理解与获取精确感知运动控制之间的权衡。以往VLA方法通过微调单个VLM主干网络实现机器人控制,常导致开放世界能力的灾难性遗忘——削弱了其本意要利用的泛化能力。TwinBrainVLA引入一种非对称设计:冻结的“左脑”负责语义推理,可训练的“右脑”负责具身感知,并通过新颖的非对称混合Transformer(AsyMoT)机制融合。这使得系统能生成精确的连续动作,同时明确保留预训练VLM广泛的视觉与语言理解能力,在SimplerEnv和RoboCasa基准测试中得到验证。
方法
作者采用双流架构,将高层语义推理与细粒度感知运动控制分离,解决具身任务中视觉-语言模型的灾难性遗忘问题。该框架名为TwinBrainVLA,包含两个独立路径:冻结的“左脑”与可训练的“右脑”,通过新颖的非对称混合Transformer(AsyMoT)机制交互。左脑作为通用专家,保留开放世界的视觉-语言知识;右脑专精具身运动控制,整合视觉、文本与本体感知输入。这种分离使模型在保持通用语义能力的同时,允许控制流针对特定机器人任务进行适应而不受干扰。
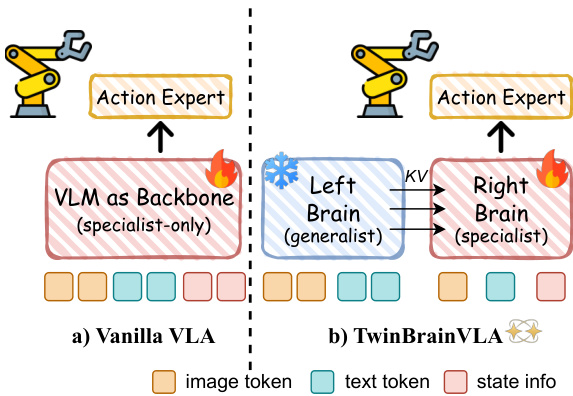
如下图所示,TwinBrainVLA的整体架构采用非对称双流设计。左脑仅处理视觉和文本输入,接收来自视觉编码器V(I)和文本分词器T(T)的图像与文本标记序列。该流在训练期间保持冻结,确保其预训练语义知识得以保留。相比之下,右脑处理包含视觉标记、文本标记及机器人本体状态s投影的多模态输入序列,该投影由轻量级MLP状态编码器ϕ编码。此设计使右脑能基于机器人的物理构型进行推理,这是闭环控制的关键要求。
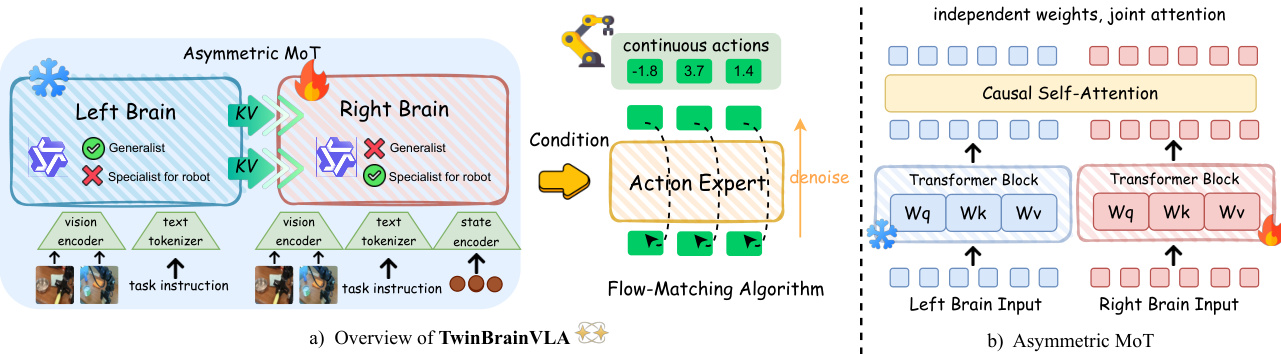
核心创新在于AsyMoT机制,它使右脑能够关注左脑冻结的键值(KV)对,同时保持自身可训练参数。在每一层中,左脑使用其冻结的自注意力机制独立计算隐藏状态。右脑则采用非对称联合注意力机制,其查询QR关注由左脑KV对(应用stop-gradient)和自身KV对拼接而成的键值集合。这种非对称流确保右脑可利用左脑的高层语义特征而不破坏它们,建立严格层级结构:左脑作为稳定的语义锚点。
右脑的最终隐藏状态HRfinal被传递至动作专家,生成连续机器人动作。动作专家采用Diffusion Transformer(DiT)架构,通过流匹配目标训练。它作为条件解码器,对噪声动作轨迹进行去噪,以右脑表征为条件。流匹配损失定义为DiT预测向量场与从标准高斯先验到真实动作分布的直线目标向量场之间的期望平方误差。推理时,通过求解对应的常微分方程合成动作。
训练策略旨在保留左脑的通用能力。总损失仅为流匹配损失,最小化生成动作与真实动作之间的差异。优化受非对称更新规则约束:梯度在AsyMoT融合层被阻断,防止反向传播进入左脑参数。这确保右脑与状态编码器可专注于控制动力学,而冻结的左脑隐式保护模型的通用语义先验。
实验
- 在SimplerEnv和RoboCasa模拟基准上使用16× H100 GPU评估TwinBrainVLA,训练遵循starVLA框架默认协议以确保公平比较。
- 在SimplerEnv的WidowX机器人上,TwinBrainVLA(Qwen3-VL-4B-Instruct)在4项任务中取得62.0%成功率,超越Isaac-GR00T-N1.6(57.1%)达+4.9%,验证了非对称双脑设计。
- 在RoboCasa GR1桌面基准(24项任务)中,TwinBrainVLA(Qwen3-VL-4B-Instruct)达到54.6% Avg@50成功率,优于Isaac-GR00T-N1.6(47.6%)+7.0%、QwenGR00T(47.8%)+6.8%、QwenPI(43.9%)+10.7%。
- 模型在OXE数据集的Bridge-V2和Fractal子集上训练;使用AdamW优化器,40k步,学习率1e-5,DeepSpeed ZeRO-2及梯度裁剪;支持Qwen2.5-VL-3B和Qwen3-VL-4B主干。
作者使用基于Qwen3-VL-4B-Instruct的TwinBrainVLA在RoboCasa GR1桌面基准上取得54.6%的最高平均成功率,优于所有基线模型(包括Isaac-GR00T-N1.6)7.0个百分点。结果表明,非对称双脑架构在复杂桌面操作任务中优于使用相同数据集和主干训练的模型。
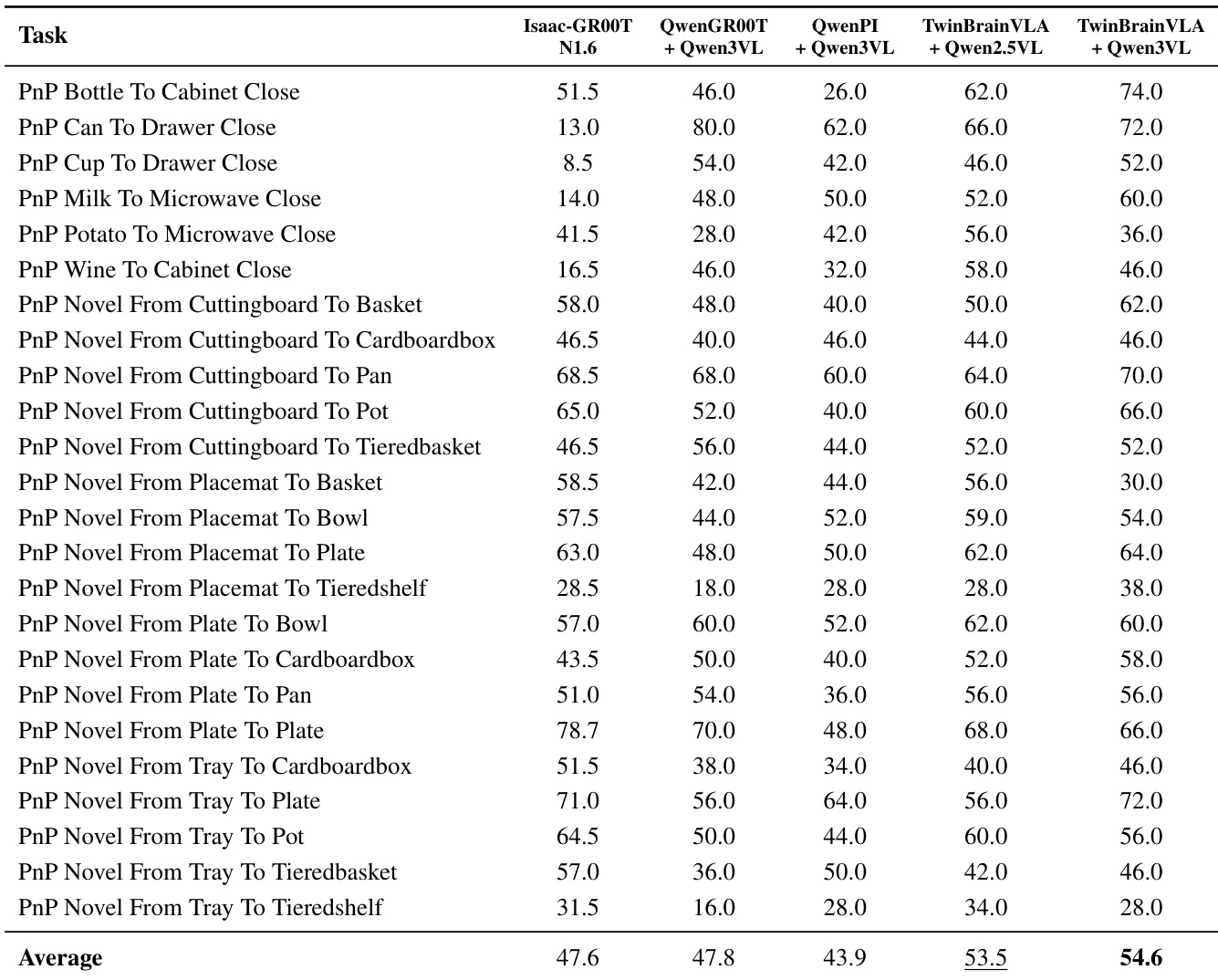
作者使用基于Qwen2.5-VL-3B-Instruct和Qwen3-VL-4B-Instruct主干的TwinBrainVLA在SimplerEnv上评估性能,分别取得58.4%和62.0%的成功率,达到当前最优结果。结果表明,TwinBrainVLA平均超越最强基线Isaac-GR00T-N1.6达+4.9%,证明其非对称双脑架构在结合高层语义理解与低层机器人控制方面的有效性。