Command Palette
Search for a command to run...
FutureOmni:基于多模态上下文的未来预测评估方法在多模态LLM中的应用
FutureOmni:基于多模态上下文的未来预测评估方法在多模态LLM中的应用
Qian Chen Jinlan Fu Changsong Li See-Kiong Ng Xipeng Qiu
摘要
尽管多模态大语言模型(Multimodal Large Language Models, MLLMs)展现出强大的全模态感知能力,但其基于音视频线索预测未来事件的能力仍鲜有研究,现有基准主要聚焦于对过去事件的回溯性理解。为填补这一空白,我们提出了FutureOmni——首个专为评估从音视频环境中进行全模态未来预测而设计的基准。该基准要求模型具备跨模态因果推理与时间推理能力,并能有效利用内部知识以预测未来事件。FutureOmni通过一种可扩展的、由大语言模型辅助并结合人工参与的流水线构建而成,包含919段视频及1,034个多项选择问答对,覆盖8个主要领域。在13个全模态模型和7个仅视频模型上的评估结果表明,当前系统在音视频未来预测任务中表现不佳,尤其在语音密集场景下更为明显,最佳模型Gemini 3 Flash的准确率仅为64.8%。为缓解这一局限,我们构建了一个包含7,000个样本的指令微调数据集,并提出一种名为全模态未来预测(Omni-Modal Future Forecasting, OFF)的训练策略。在FutureOmni以及多个主流音视频与仅视频基准上的评估显示,OFF策略显著提升了模型对未来事件的预测能力与泛化性能。我们已公开所有代码 (https://github.com/OpenMOSS/FutureOmni) 与数据集 (https://huggingface.co/datasets/OpenMOSS-Team/FutureOmni) ,以促进该领域的进一步研究。
一句话总结
复旦大学、上海创新研究院与新加坡国立大学的研究人员推出了 FutureOmni —— 首个面向音视频未来事件预测的基准测试,并提出 Omni-Modal Future Forecasting(OFF)训练策略,配合 7K 样本数据集,显著提升跨模态时序推理能力,在未来事件预测任务中表现大幅提升。
主要贡献
- 我们推出 FutureOmni,这是首个用于评估多模态大语言模型(MLLM)从音视频输入中预测未来事件的基准测试,涵盖 919 个视频和 1,034 组问答对,横跨 8 个领域,要求模型具备跨模态因果与时序推理能力。
- 在 20 个模型上的评估显示,即使是表现最佳的系统(如 Gemini 3 Flash)准确率也仅 64.8%,凸显当前全模态未来预测能力的显著局限,尤其在语音密集型场景中。
- 我们提出 Omni-Modal Future Forecasting(OFF)训练策略,配合 7K 样本的指令微调数据集,提升模型在 FutureOmni 及其他基准上的预测性能与泛化能力,注意力可视化和跨领域表现均佐证了这一效果。
引言
作者利用多模态大语言模型(MLLM)日益增强的能力,解决一个关键缺口:从音视频联合输入中预测未来事件,这在自动驾驶等现实场景中至关重要,因为必须融合声音与视觉以预判结果。此前的基准测试多聚焦于回溯推理或忽略音频,导致模型在跨模态因果预测(尤其语音密集场景)中未被充分测试。作者的主要贡献是 FutureOmni —— 首个面向全模态未来预测的基准测试,配合 7K 样本指令微调数据集和 Omni-Modal Future Forecasting(OFF)训练策略,显著提升模型性能与跨领域泛化能力。
数据集

作者使用名为 FutureOmni 的精选数据集,基于 YouTube 视频构建,用于评估多模态未来事件预测。其组成与使用方式如下:
-
数据集组成与来源:
作者从约 18K 个 YouTube 视频(30 秒–20 分钟)出发,根据视觉与音频标准筛选,剔除场景变化低(帧间相似度 >70%)或音视频对齐弱(通过 UGCVideoCaptionier 语义差距分析)的视频,最终保留 9K 视频。最终数据集包含 919 个高质量视频和 1,034 组问答对。 -
关键子集详情:
- 规模:919 个视频,1,034 组问答对。
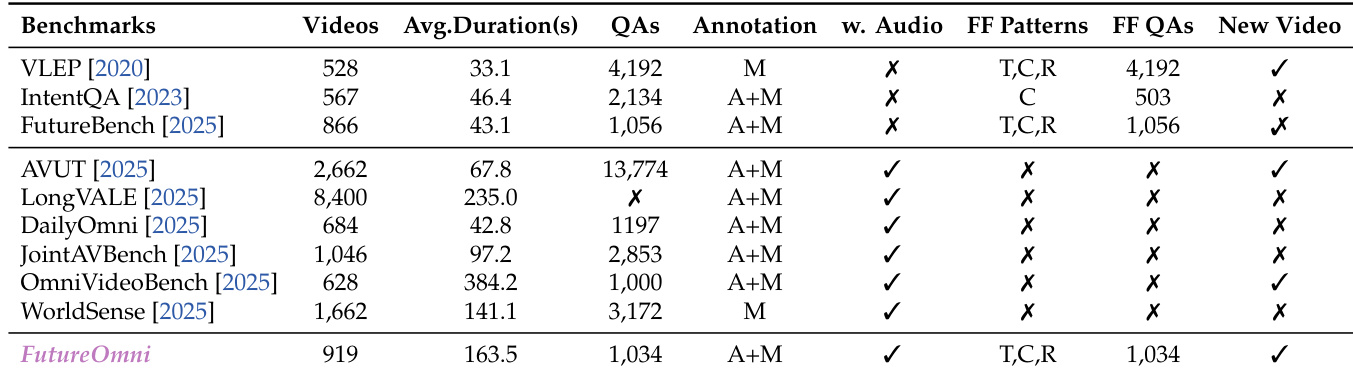
- 时长:平均 163.5 秒 —— 长于 VLEP(33.1 秒)或 FutureBench(43.1 秒)。
- 标注:100% 聚焦未来预测(对比 WorldSense/DailyOmni 的回溯任务)。
- 推理类型:覆盖主题蒙太奇(T)、因果(C)、常规序列(R)—— 不同于仅限单一逻辑类型的基准测试。
- 类别:8 个主要组别(如卡通、教育、应急、监控、日常生活、电影),含 21 个细粒度子类以确保领域多样性。
-
数据使用方式:
- 训练/评估使用完整 919 视频集与 1,034 组问答对。
- 问答对目标为跨模态因果推理 —— 前提与结论事件必须整合音频与视频,要求高层推理,避免常识或描述性关联。
- 每组问答包含精确时间戳、模态标签和推理依据,确保挑战性与非显而易见的关联。
-
处理与元数据:
- 视频通过帧相似度与字幕差距指标筛选场景动态与音频依赖性。
- 标注遵循严格输出格式:
has_causal: [模态] to [模态],含起止时间与事件描述。 - 元数据包含每题关键模态(视觉/音频/两者)及正确答案的详细推理依据。
- 评估提示呈现视频帧+音频,要求模型从多个选项中选择正确未来事件 —— 回答应为单个字母(A–E)。
方法
作者提出一套完整的音视频时序定位与因果推理框架,分阶段整合多模态输入,构建丰富、基于事件的时间线。整体流程始于音频协调的视频筛选,视频根据领域相关性与动态场景协调性过滤,确保输入数据在语义与时间上连贯。初始过滤步骤利用精选视频领域列表(如监控、日常生活、教育、应急场景)确保多样性与现实适用性。过滤后的视频进入音视频时序定位与校准模块,通过定位提示识别剧情相关事件并生成 MM:SS 格式精确时间戳。这一步骤对从静态或琐碎背景中隔离有意义事件至关重要,从而建立密集时间线。
如下图所示,定位过程包含时间边界校验机制,以验证识别事件时长的精确性。通过计算每个事件起止点的梅尔频率倒谱系数(MFCC),若 MFCC 差值超过预设阈值 2.0(表明声学不连续性与有意义事件边界对齐),则确认边界有效。边界验证后,系统通过音频填充步骤丰富时序片段:使用 Gemini 2.5 Flash 识别并标注与视觉内容同步的特定声学线索(如对话、音效、背景音乐),确保重要音频事件与视觉动作一同捕捉,增强时间线的多模态丰富性。
下一阶段为音视频问答构建,从连续事件中提取逻辑因果对。如框架图所示,该过程包含两个关键组件:因果对发现与双阶段验证。在因果对发现中,DeepSeek-V3.2 分析相邻事件片段,严格限制前提与目标事件间时间间隔不超过 30 秒。模型被指示判断后续事件是否为前一事件的直接逻辑结果,输出三部分:前提事件、目标事件及弥合因果间隙的推理依据。为显式挖掘由声学线索驱动的配对,模型分配 0 至 2 分的贡献评分(0 表示无影响,1 表示装饰性,2 表示因果性),并按语音、声音或音乐类别分类音频因素。
问答构建阶段引入四种新型干扰项,以严格评估多模态推理能力:仅视觉感知、仅音频感知、延迟型、逆因果型。这些干扰项旨在挑战未能整合听觉线索、过度依赖音频转录、缺乏时间精确性或误解时间方向的模型。框架确保候选问答提交至 GPT-4o 进行自动化逻辑验证,再经人工复核以消除歧义、保证数据质量。
最后,作者整理高质量指令微调数据集 FutureOmni-7K,并提出 Omni-Modal Future Forecasting 方法。该方法将数据构建流程中提取的推理依据整合至每个训练实例,明确展示特定未来事件为何从音视频前提中推导而来。通过不仅教授模型预测结果,更内化未来预测的推理逻辑,该框架旨在弥补当前 MLLM 在全模态未来预测能力上的缺口。整个流程旨在增强模型跨模态与时序推理能力,确保在复杂现实场景中稳健且可泛化的性能。
实验
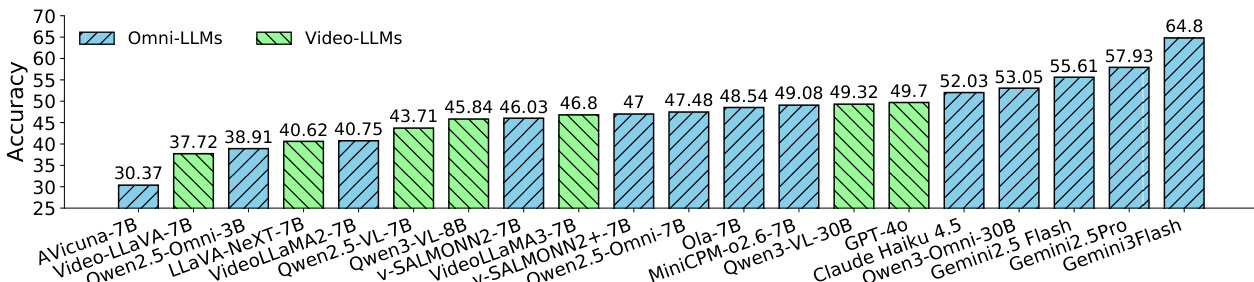
- 在 FutureOmni 上评估 20 个 MLLM,包括开源音视频、纯视频及专有模型;专有模型(Gemini 2.5 Pro、Gemini 3 Flash)平均准确率约 61%,优于最佳开源 Omni-LLM(Qwen3-Omni,53%)。
- 纯视频模型表现劣于 Omni-LLM(如 GPT-4o 为 49.70%),证实音视频融合对未来事件预测至关重要。
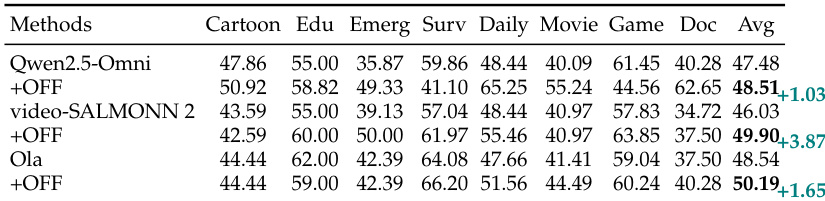
- 领域表现各异:游戏/日常生活(如 Qwen3-Omni 在游戏类 62.65%)优于纪录片/应急(平均 20–40%),因复杂叙述或混乱线索。
- 观察到“上下文冷启动”现象:所有模型在最短视频上表现最差(如 Qwen3-Omni 在 <1 分钟视频上为 34.90%),在 2–4 分钟时达到峰值。
- 语音是最难模态(Qwen3-Omni:47.99% vs. 音乐 57.54%),凸显语言-音视频对齐需求。
- 模态消融实验证实 A+V 协同至关重要:Qwen2.5-Omni 剥离任一模态后准确率下降约 5%;字幕/字幕表现劣于原始音频。
- 错误分析(Gemini 3 Flash)显示 51.6% 错误源于视频感知,30.8% 源于音视频推理失败,仅 2.5% 源于知识缺口。
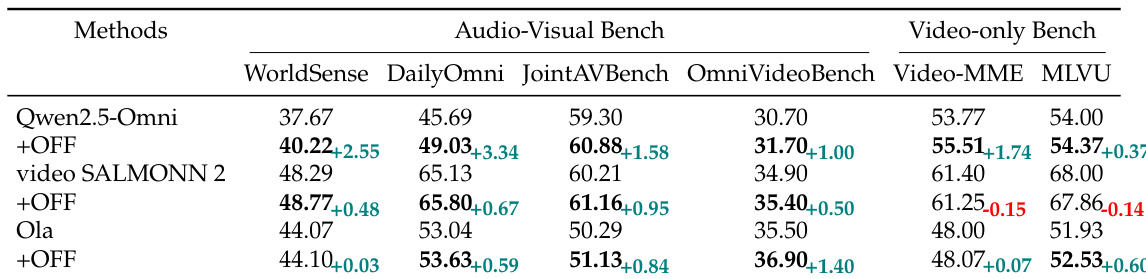
- 在 FutureOmni-7K 上微调提升性能:video-SALMONN 2 整体 +3.87%;Qwen2.5-Omni 在语音任务上提升约 10%。
- 微调模型在跨领域基准(WorldSense、DailyOmni、Video-MME、MLVU)上泛化良好,如 Qwen2.5-Omni 在 WorldSense 上 +2.55%,在 Video-MME 上 +1.74%。
- 注意力可视化显示训练后模型在 Transformer 各层更关注视频与音频关键帧,支持跨模态推理。
作者使用 FutureOmni-7K 数据集评估指令微调对开源全模态模型的影响,显示微调在多个基准上带来持续性能提升。结果表明,微调模型在具挑战性的语音类别中取得显著增益,并在音视频与纯视频任务中展现出增强的泛化能力,暗示未来预测训练可提升跨模态推理与视觉理解能力。
作者使用 FutureOmni 评估多模态模型在各类基准上的表现,突出其独特特性,如平均视频时长更长、包含音视频标注。结果显示,FutureOmni 以更多问题数量与聚焦未来预测脱颖而出,区别于强调动作识别或通用问答的其他基准。
作者在 FutureOmni 基准上评估开源与专有多模态模型,结果显示专有模型(如 Gemini 3 Flash)平均准确率更高(61%),优于最佳开源模型 Qwen2.5-Omni(47.48%)。在 FutureOmni-7K 上微调模型带来显著提升,尤其在语音类别,并增强在各类音视频与纯视频基准上的泛化能力。
作者在 FutureOmni 基准上评估一系列开源与专有多模态模型,结果显示专有模型(如 Gemini 3 Flash)平均准确率最高(64.80%),优于开源模型(如 Qwen3-Omni 53.05%)。表格显示纯视频模型普遍表现劣于音视频模型,最强纯视频模型 GPT-4o 得分为 49.70%,而最佳音视频模型 Gemini 3 Flash 达 64.80%。

作者使用基准测试评估各类多模态大语言模型在未来事件预测上的表现,比较开源与专有模型在音视频与纯视频设置下的表现。结果显示专有 Omni-LLM 准确率高于开源模型,且同时使用音频与视频输入的模型优于仅使用单一模态的模型,凸显多模态融合的重要性。