Command Palette
Search for a command to run...
LongSpeech:一个用于长语音转录、翻译与理解的可扩展基准
LongSpeech:一个用于长语音转录、翻译与理解的可扩展基准
Fei Yang Xuanfan Ni Renyi Yang Jiahui Geng Qing Li Chenyang Lyu Yichao Du Longyue Wang Weihua Luo Kaifu Zhang
摘要
近年来,语音-语言模型在短时、片段级的语音任务中取得了显著成功。然而,现实世界的应用场景,如会议转录、口语文档理解和对话分析,需要具备处理长时音频并进行推理的鲁棒模型。在本工作中,我们提出了 LongSpeech,这是一个大规模且可扩展的基准测试,旨在评估和提升语音模型在长时音频处理方面的能力。LongSpeech 包含超过 100,000 个语音片段,每个片段约 10 分钟,涵盖丰富的标注信息,包括自动语音识别 (ASR)、语音翻译、摘要、语言检测、说话人计数、内容分离和问答。我们介绍了一种可复现的 pipeline,用于从多种来源构建长时语音基准,以支持未来的扩展。我们对当前最先进模型的初步实验揭示了显著的性能差距:模型往往专注于单一任务而牺牲其他任务,且在高层推理方面表现不佳。这些发现凸显了该基准测试的挑战性。我们的基准测试将向研究社区公开。主要术语说明:* LongSpeech: 保留英文,作为专有名词。* ASR: 自动语音识别 (Automatic Speech Recognition) 的通用缩写。* pipeline: 保留英文,符合科技领域习惯。
一句话总结
作者提出了 LongSpeech,这是一个可扩展的基准,包含超过 100,000 个时长约 10 分钟的语音片段,标注了转录、翻译和理解任务,并附带可复现的构建流程。初步实验显示,针对会议转录等现实应用的高级推理方面,最先进模型存在显著的性能差距。
核心贡献
- 该工作提出了 LongSpeech,这是一个大规模基准,包含超过 100,000 个时长约 10 分钟的语音片段,针对 ASR 和摘要等任务具有丰富的标注。该数据集旨在评估和提升语音模型在多个领域长音频方面的能力。
- 引入了一种从多样化来源构建长语音基准的可复现流程,以支持未来的扩展。该方法促进了后续研究中对基准构建过程的复制和扩展。
- 使用最先进模型进行的实验揭示了显著的性能差距,特别是在摘要和时间定位等高级推理任务中。这些发现验证了基准的挑战性,并突出了当前模型在维持长音频流上下文能力方面的关键差距。
引言
高级音频语言模型在处理现实任务中的扩展音频流时面临重大挑战。现有系统通常在转录等核心功能与摘要或时间定位等高级推理任务之间存在权衡。为了弥补这些不足,作者引入了 LongSpeech。这个大规模基准作为一个可扩展的评估平台,旨在测试和提升长语音中的转录、翻译和理解能力。
数据集
-
数据集组成和来源
- 作者利用超过 100,000 个语音片段构建 LongSpeech,每个片段时长约 10 分钟。
- 来源包括 LibriSpeech、TED-LIUM v3、SPGISpeech、Vox-Populi、CommonVoice、AISHELL-2、IWSLT 以及自定义电影对话语料库。
- 这些语料库涵盖了研究许可下的多样化领域、说话人和语言。
-
整理和处理细节
- LibriSpeech 和 SPGISpeech 数据按说话人和章节分组,顺序拼接以达到约 600 秒。
- CommonVoice 片段利用基于嵌入的选择和 FAISS 聚类来分组语义相似的内容。
- VoxPopuli 和 AISHELL-2 优先考虑监督多说话人片段,同时过滤掉短语句。
- 电影语料库使用文本转语音合成以确保说话人和性别分布的多样性。
- 真实转录来自原始数据集或高质量生成模型。
- 说话人计数和语言检测的元数据从语料库级标注中推断得出。
-
模型训练和划分
- 该基准评估了八项任务,包括 ASR、翻译、摘要和问答。
- 数据按照 7:1.5:1.5 的比例划分为训练集、开发集和测试集。
- 最终划分聚合了所有任务的示例以确保全面的代表性。
- 总集包含 142,200 个训练示例、30,100 个开发示例和 30,100 个测试示例。
实验
该研究使用标准指标评估了多个基础音频语言模型,涵盖核心语音任务和高级理解基准。结果显示存在显著的性能差距,模型在翻译等领域表现出专业性,但在长格式处理和深度语义推理方面存在困难。值得注意的是,系统通常能正确解析用户意图,但缺乏提取准确信息或跟踪时间问题的精度,强调了 LongSpeech 基准对于识别当前局限性的必要性。
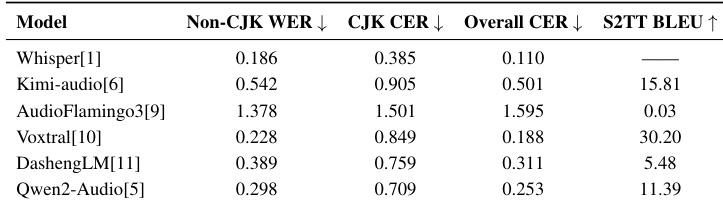
该表评估了各种音频语言模型在语音识别和翻译任务上的性能,揭示了不同的专业性而非全面的统一优势。虽然 Whisper 实现了最低的识别错误率,但它不支持翻译,而 Voxtral 展示了最强的翻译能力。其他模型如 AudioFlamingo3 与专用基线相比,在这两个指标上的错误率显著更高。Voxtral 在评估的模型中提供了最强的语音转文本翻译性能。Whisper 实现了最准确的语音识别,但缺乏翻译功能。AudioFlamingo3 表现最弱,在识别和翻译中的错误率最高。
作者评估了音频语言模型在从内容分离到时间定位等任务上的表现,揭示了当前长语音处理中的重大局限性。虽然模型通常在解析查询意图方面表现出色,但难以生成准确的答案,特别是在时间定位等推理密集型任务中。Voxtral 整体表现最强,尽管 AudioFlamingo3 在语言检测方面显示出优势。Voxtral 在情感分析、摘要和时间定位任务中取得了最高分数。DashengLM 在说话人计数方面显示出高可解析率,但无法提供正确的数字答案。语言检测是 AudioFlamingo3 显著优于其他模型的唯一任务。

这些实验评估了音频语言模型在语音识别、翻译和长格式处理任务上的表现,揭示了不同的专业性而非全面的统一优势。Voxtral 作为整体表现最强的模型脱颖而出,特别是在翻译和推理任务中,而 Whisper 实现了最准确的识别但缺乏翻译功能。虽然当前模型擅长解析查询意图,但在为复杂推理生成准确答案方面表现出重大局限性,AudioFlamingo3 尽管在语言检测方面具有优势,但表现最弱。