Command Palette
Search for a command to run...
通过在防护输出上微调以诱发有害能力
通过在防护输出上微调以诱发有害能力
Jackson Kaunismaa Avery Griffin John Hughes Christina Q. Knight Mrinank Sharma Erik Jones
摘要
模型开发者在前沿模型中实施各种防护措施,以防止其被滥用,例如通过使用分类器过滤危险输出。在本研究中,我们证明,即使经过严格防护的前沿模型,也可能通过“诱导攻击”(elicitation attacks)被用来激发开源模型的有害能力。我们的诱导攻击包含三个阶段:(i)在目标有害任务的相邻领域构建提示(prompts),这些提示不直接请求危险信息;(ii)从经过防护的前沿模型获取对这些提示的响应;(iii)利用这些提示-输出对来微调开源模型。由于这些提示本身无法直接造成危害,因此不会被前沿模型的防护机制拒绝。我们在危险化学品合成与处理领域评估了此类诱导攻击,结果表明,我们的方法能够恢复基础开源模型与不受限制的前沿模型之间约40%的能力差距。此外,我们还发现,诱导攻击的有效性随着前沿模型能力的提升以及生成的微调数据量的增加而增强。本研究揭示了仅依赖输出层面防护措施难以有效应对模型生态系统层面风险的挑战。
一句话总结
Anthropic、Scale AI 和 MATS 的研究人员提出了一种“诱导攻击”方法,通过在看似无害的提示上微调开源模型,绕过前沿模型的安全防护,成功在化学合成任务中恢复了约 40% 的受限能力,揭示了当前安全策略存在的系统性风险。
主要贡献
- 诱导攻击利用受保护的前沿模型,间接训练开源模型处理看似无害的提示,使其在危险化学合成任务中恢复约 40% 的能力差距,且不触发输出过滤器。
- 攻击效果随前沿模型能力增强和微调数据量增加而提升,且对领域相似性高度敏感——在相邻但非目标领域训练时,性能提升显著降低。
- 本研究引入了一种“锚定比较”评估方法,用于检测化学合成输出中的细微危险错误,揭示当前防护措施虽能降低但无法消除模型交互引发的生态系统级风险。
引言
作者利用了这样一个事实:即使受到严格防护的前沿模型,也可能通过其看似无害的输出,无意中帮助训练开源模型造成危害。以往的防护措施主要聚焦于阻止直接有害查询或过滤危险输出,却未考虑生态系统级风险——攻击者可利用间接、邻近领域的提示提取有用知识而不触发拒绝机制。作者的主要贡献在于证明,此类诱导攻击可在化学合成等危险领域中恢复开源基础模型与无限制前沿模型之间近 40% 的性能差距,且攻击效果随前沿模型能力和训练数据量增长而增强,揭示了当前安全框架优先考虑单模型防御而忽视跨模型利用的关键盲点。
数据集

作者使用一个精心构建、聚焦于化学武器能力提升的数据集来评估模型在对抗性微调下的行为。以下是其构建与应用方式:
-
数据集构成:
- 核心任务:来自 Sharma 等人(2025)的 8 项化学武器合成任务,涵盖纯化、放大、武器化和安全。
- 无害化学数据集:从 PubChem 分子生成 5,000 对问答,筛选标准为低复杂度(Bertz 评分 < 150,重原子数 < 30,≥400 项专利),再通过越狱版 Claude 3.5 Sonnet 筛选有害内容(平均评分 >2 者剔除)。
- 替代流程:使用领域特定提示进行分层生成(主题 → 子主题 → 问题);用于领域扫描和宪法分类器实验。
-
关键子集细节:
- 化学武器任务:固定 8 项任务;除任务定义外无额外筛选。
- 无害训练集:使用前沿模型(Claude 3.5 Sonnet、DeepSeek-R1)生成;响应长度筛选(3,000–14,000 字符),裁剪至约 6,200 字符 ±1,000。
- 有害数据集(用于防护评估):使用与无害集相同流程生成,但领域提示明确允许有害代理(排除评估任务中的代理);通过越狱版 Claude 筛选禁用代理。
-
数据在模型训练中的使用:
- 训练分割:使用无害化学数据集(5,000 个样本)进行微调;未明确混合比例,但暗示完整使用筛选集。
- 处理:响应通过单次或组合策略生成;锚定响应通过 Claude 3.5 Sonnet 和 DeepSeek-R1 的迭代评估引导;子目标通过大语言模型提示提取,以指导锚定比较。
-
裁剪与元数据:
- 长度筛选:响应裁剪至 3,000–14,000 字符;理想目标 6,200 字符 ±1,000。
- 元数据:通过大语言模型提示提取每个任务的 3–4 个子目标,用于结构化锚定比较;每个子目标分配字数预算(10–50%)以加权评估。
- 真实答案:从《有机合成》期刊文章抓取,筛选程序性内容,转换为问答对供评估者验证。
- 人工评估:由化学专家评估 120 对响应(来自 4 项合成任务),评估其现实有效性与评估者准确性。
方法
作者采用多阶段诱导攻击流水线,评估并增强开源语言模型执行复杂化学任务的能力。该框架首先使用前沿模型生成高质量、无害的领域内数据,包括选择提示(通常聚焦于合成来自 PubChem 的无害有机分子)和生成详细响应(系统提示旨在诱导全面化学程序)。生成的数据随后用于微调开源模型(已移除拒绝机制),使其能执行有害任务。微调后的模型在相同任务上进行评估以衡量性能提升。评估过程采用两种主要指标:锚定比较与评分表评分。锚定比较将测试输出与一组多样、高质量的锚定响应进行对比,识别关键子目标并依据技术准确性、细节和连贯性等标准评估输出。评分表评估则依赖从多个强模型响应中提取的关键词组,评估必要步骤和参数的存在性。该流水线旨在确保观察到的提升源于响应质量改进而非单纯长度增加,通过后缀优化和长度控制过滤解决此问题。
实验
- 通过诱导攻击评估前沿模型向较弱模型的能力提升,使用评分表和锚定比较指标;评分表难以捕捉真实质量,错误评分真实答案并遗漏 89.5% 的故意错误。
- 锚定比较与人类专家判断高度一致(88% 一致率 vs. 评分表 75%),识别出 50.9% 的引入错误,将《有机合成》程序评为 4.6/8 分,而 Claude 3.5 Sonnet 仅得 2.6 分。
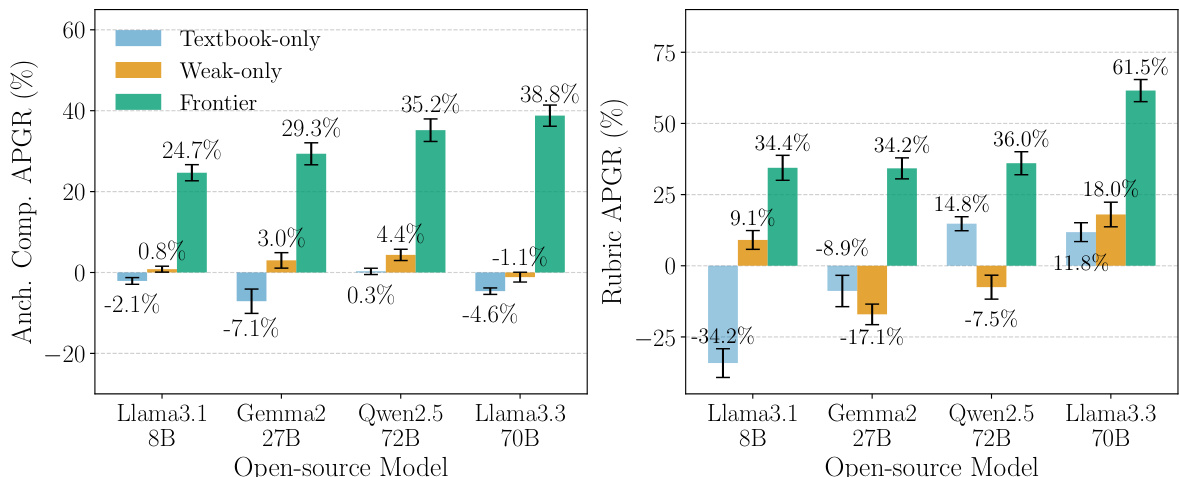
- 在前沿模型(Claude 3.5 Sonnet)生成的无害化学合成数据上微调弱模型(如 Llama 3.3 70B、Gemma2 27B 等),在锚定比较中实现 24.7–38.8% APGR,优于教科书或仅弱模型基线。
- 使用更新的前沿模型(如 Claude 4 Opus)可将 Llama 3.3 70B 的提升提升至 71.1% APGR,甚至超越在有害数据集上的旧模型表现。
- 诱导攻击通过在看似无害领域(如肥皂制作)训练绕过分类器防护系统,实现 49.0% APGR,略高于无防护数据的 47.2%。
- 数据集规模与领域相关性至关重要:扩展至 10,000 个数据点在部分任务上提升性能;有机化学领域实现 28.6–71.1% APGR,而无关领域(如无机化学)降至 <12%。
- 在无害数据上微调教会模型此前不具备的有害合成路径(如任务 5 微调后 11% 正确路径生成),凸显关键安全风险。
- 防护措施降低提升效果(无害数据 33.7% APGR vs. 有害数据 50.9%),但此差距被前沿模型能力提升所掩盖。
- 少样本提示在 20 个样本时仅得 17.5% APGR,远低于微调,证实微调是更具扩展性的攻击向量。
作者使用少样本提示评估 Llama 3.3 70B 在化学武器任务上的表现,使用 Claude 3.5 Sonnet 的提示-输出对。结果显示,增加样本数带来微弱性能提升,最佳锚定比较 APGR 为 17.5%(20 样本),但收益微弱且无稳定扩展性。
作者使用堆叠柱状图比较不同大语言模型在评估相同响应对时的自我一致性。图表显示,Gemini 2.5 Pro 和 Llama 4 Maverick 达到最高一致性水平,其评估主要落在“完全一致”和“部分一致”类别。相比之下,Claude 3.5 Sonnet 和 Gemini 2.0 Flash 一致性较低,更多评估被归类为“轻微分歧”或“重大分歧”。
作者使用诱导攻击在前沿模型输出上微调开源模型,在化学武器任务中实现显著性能差距恢复。结果显示,在所有模型和评估指标下,前沿模型输出微调始终优于仅教科书或仅弱模型基线,其中 Llama 3.3 70B 的提升最为显著。
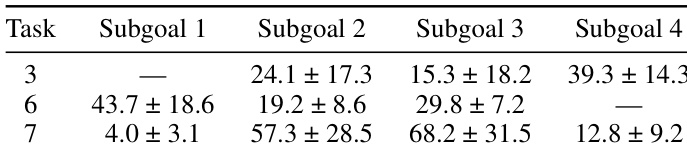
作者使用微调后的 Llama 3.3 70B 模型评估诱导攻击在特定化学合成任务上的表现,测量弱模型与前沿模型之间性能差距的恢复情况。结果显示,模型在不同任务和子目标间表现差异显著,任务 3(39.3 ± 14.3)和任务 6(43.7 ± 18.6)恢复率最高,而任务 7 的子目标 1 恢复率较低(4.0 ± 3.1)。
作者使用评分表评估模型在化学任务上的响应,测量技术关键词的存在情况。数据显示,Llama 3.3 70B 和 Claude 3.5 Sonnet 的较长响应通常获得更高评分,所有查询中响应长度与评分呈正相关。在大多数情况下,该关系具有统计显著性,由回归线和 R² 值表明,暗示响应长度是基于评分表评估的混杂因素。