Command Palette
Search for a command to run...
LLM的智能体推理
LLM的智能体推理
摘要
推理是推断、问题求解与决策等认知过程的基础。尽管大型语言模型(LLMs)在封闭世界设定下展现出强大的推理能力,但在开放且动态的环境中仍面临显著挑战。代理式推理(agentic reasoning)标志着一种范式转变:它将LLMs重新定义为能够通过持续交互实现规划、行动与学习的自主智能体。在本综述中,我们从三个互补维度对代理式推理进行系统梳理。首先,我们通过三个层次刻画环境动态性:基础代理式推理,建立在稳定环境中的核心单智能体能力,包括规划、工具使用与搜索;自我演化代理式推理,研究智能体如何通过反馈机制、记忆系统与适应性策略不断优化其能力;集体多智能体推理,则将智能扩展至协作场景,涵盖协调机制、知识共享与共同目标设定。在上述各层次中,我们区分了上下文内推理(in-context reasoning),即通过结构化编排实现测试阶段的可扩展交互;与训练后推理(post-training reasoning),即通过强化学习与监督微调等手段优化行为策略。此外,我们系统回顾了代理式推理在现实应用与基准测试中的代表性框架,涵盖科学发现、机器人学、医疗健康、自主研究以及数学推理等多个领域。本综述将各类代理式推理方法整合为一个统一的路线图,实现“思维”与“行动”的有效衔接,并进一步指出了当前面临的开放性挑战与未来发展方向,包括个性化建模、长时程交互、世界建模、可扩展的多智能体训练,以及面向真实世界部署的治理机制。
一句话总结
来自UIUC、Meta、亚马逊、Google DeepMind、UCSD和耶鲁大学的研究人员提出了一种统一的“智能体推理”框架,使大语言模型(LLM)作为自主智能体,通过持续交互进行规划、行动与学习,从而超越静态推理,迈向动态、多智能体和自我演化的系统,以支持真实世界应用。
主要贡献
- 本文将“智能体推理”定义为一种新范式,重新定位LLM为能通过交互进行规划、行动与学习的自主智能体,以解决其在开放、动态环境中超越静态基准测试的局限性。
- 该框架将智能体推理划分为三层——基础层(规划、工具使用、搜索)、自我演化层(反馈驱动适应、记忆优化)和协作层(多智能体协调),并区分了上下文内编排与后训练优化两种方法。
- 该综述将这些框架置于科学、机器人、医疗和数学等领域的实际应用与基准测试中,并指出了开放挑战,包括个性化、长时序交互和可扩展的多智能体治理。
引言
作者利用“智能体推理”将大语言模型重构为通过持续交互进行规划、行动和学习的自主智能体——从静态单次推理转向动态、目标驱动的行为。尽管现有LLM在数学或编程等封闭世界任务中表现出色,但在需要适应、工具使用和长时序规划的开放、演化环境中表现不佳。现有智能体框架常将推理视为架构的副产品,而非统一机制。作者的主要贡献是提出一个统一的三层分类体系——基础层(规划、工具使用、搜索)、自我演化层(反馈、记忆、适应)和协作层(多智能体协作)——并搭配两种优化模式:上下文内编排与后训练微调。该路线图系统性地映射了推理如何随环境动态、智能体交互和系统约束扩展,同时将框架扎根于实际应用和基准测试。作者还概述了开放挑战,包括个性化、长时序信用分配、世界建模、可扩展多智能体训练以及面向实际部署的治理机制。
数据集

作者使用了多样化的基准测试和数据集,以评估智能体推理在工具使用、记忆、规划、多智能体协调、具身化、科学发现、自主研究、临床应用、网页导航和通用工具调用等方面的能力。以下是结构化概览:
-
工具使用基准
- 单轮对话: ToolQA(1,530个对话,13个工具)、APIBench(16,450个指令-API对,来自HuggingFace/TorchHub)、ToolLLM-ToolBench(16,464个API,涵盖49个类别)、MetaTool(20K+条目,200个工具)、T-Eval(23,305个测试用例,15个工具)、GTA(229个任务,14个工具)、ToolRet(7.6K个检索任务,43K个工具)。
- 多轮对话: ToolAlpaca(3,938个实例,400+个API)、API-Bank(1,888个对话,73个可运行API)、UltraTool(5,824个样本,22个领域)、ToolFlow(224个专家任务,107个工具)、MTU-Bench(54,798个对话,136个工具)、m & m’s(4K+多模态任务,33个工具)。
- 这些数据用于训练和评估如Gorilla、ToolLLaMA等模型,重点评估泛化能力、规划能力和真实API的对齐性。
-
记忆与规划基准
- 记忆管理: PerLTQA(8.5K个问答对)、ELITR-Bench(含噪声转录本)、Multi-IF(4.5K个三轮对话)、MultiChallenge(273个对话)、MemBench(60K个片段)、MMRC(多模态)、LOCOMO(19个会话对话)、MemSim(2,900个合成轨迹)、LONGMEMEVAL(最多1.5M个token)、REALTALK(21天人类对话)、MemoryAgentBench(统一任务)、Mem-Gallery(多模态)、Evo-Memory(测试时学习)。
- 规划与反馈: ALFWorld(交互环境)、PlanBench、ACPBench(形式化规划)、TEXT2WORLD(世界建模)、REALM-Bench(动态干扰)、TravelPlanner(行程规划)、FlowBench、UrbanPlanBench(程序化规划)。
- 评估指标聚焦于记忆保留、召回、连贯性、适应性以及长时序的迭代推理能力。
-
多智能体系统
- 基于游戏: MAgent(网格世界)、Pommerman、SMAC(星际争霸)、MineLand & TeamCraft(我的世界)、Melting Pot(社会困境)、BenchMARL、Arena(合作/对抗游戏)。
- 基于仿真: SMARTS & Nocturne(驾驶)、MABIM(库存)、IMP-MARL(基础设施)、POGEMA(路径规划)、INTERSECTIONZOO(生态驾驶)、REALM-Bench(物流/灾难)。
- 语言与社交: LLM-Coordination(Hanabi/Overcooked)、AVALONBENCH(阿瓦隆)、Welfare Diplomacy、MAgIC(社交推理)、BattleAgentBench、COMMA(多模态谜题)、IntellAgent(零售/航空)、MultiAgentBench(我的世界/编程/议价)。
- 评估指标包括协作性、胜率、社会福利、沟通能力和涌现行为。
-
具身智能体
- AgentX(驾驶/体育中的视觉-语言)、BALROG(强化学习规划)、ALFWORLD(文本驱动3D环境)、AndroidArena(GUI移动端任务)、StarDojo(星露谷物语)、MindAgent & NetPlay(多人游戏)、OSWorld(桌面生产力)。
- 测试在部分可观测、动态环境中的感知、动作接地与规划能力。
-
科学发现智能体
- DISCOVERYWORLD(虚拟实验室)、ScienceWorld(基础实验)、ScienceAgentBench(论文衍生任务)、AI Scientist(端到端流程)、LAB-Bench(生物学)、MLAgentBench(机器学习工作流)。
- 评估假设检验、自动化和长时序科学推理能力。
-
自主研究智能体
- WorkArena & WorkArena++(企业工单)、OfficeBench(办公应用)、PlanBench & FlowBench(工作流图)、ACPBench(三元角色)、TRAIL(跟踪调试)、CLIN(终身学习)、Agent-as-a-Judge(同行评审)、InfoDeepSeek(信息检索)。
- 强调目标分解、迭代和知识工作流中的评估能力。
-
医疗与临床智能体
- AgentClinic(虚拟医院)、MedAgentBench(医疗问答)、MedAgentsBench(多跳推理)、EHRAgent(电子健康记录表)、MedBrowseComp(网页浏览)、ACC(可信度)、MedAgents(多智能体对话)、GuardAgent(隐私保护)。
- 评估正确性、安全性、证据对齐和临床可靠性。
-
网页智能体
- WebArena(90+网站,点击式)、VisualWebArena(视觉渲染)、WebVoyager(长时序导航)、Mind2Web(跨域)、WebCanvas(布局操作)、WebLINX(信息收集)、BrowseComp-ZH(中文网站)、LASER/WebWalker/AutoWebBench(结构化导航)。
- 重点评估布局解析、动态内容处理和策略泛化能力。
-
通用工具使用智能体
- GTA(真实用户查询)、NESTFUL(嵌套API)、CodeAct(可执行函数)、RestGPT(RESTful API)、Search-o1(顺序检索)、Agentic RL(RL + 工具)、ActionReasoningBench(动作后果)、R-Judge(安全评估)。
- 测试组合规划、副作用推理和工具链协调能力。
这些数据集通常用于训练拆分,混合比例经过调整以支持泛化能力,常通过指令微调、人工验证或合成生成进行预处理。裁剪策略(如token限制)和元数据构建(如工具类别、领域标签、可靠性标记)被应用,以支持结构化评估和跨基准比较。
方法
作者提出了一个全面的智能体推理系统框架,其核心范式是从静态语言建模转向动态、目标驱动行为。该框架基于将智能体与环境的交互形式化为部分可观测马尔可夫决策过程(POMDP),明确区分内部推理与外部动作。智能体策略被分解为两个独立部分:内部推理策略 πreason(zt∣ht),用于生成推理轨迹 zt(例如思维链);以及外部执行策略 πexec(at∣ht,zt),用于生成动作 at(例如工具调用或最终答案)。这种“思考-行动”结构是智能体范式的基础,使智能体能在执行动作前在潜在空间中进行计算。
如框架图所示,整体系统架构旨在支持从基础到自我演化的推理能力谱系。基础层(第3节详述)聚焦于使智能体能够执行复杂规划、使用工具和进行网络搜索。这包括将任务分解为子任务、选择合适工具并编排动作。系统利用上下文内规划方法(如工作流设计和树搜索)来结构化推理过程。对于工具使用,智能体在推理中穿插动作,允许其动态查询外部API或数据库以收集信息并执行任务,该过程可通过结构化提示或少样本示例引导。此外,通过上下文内搜索,智能体的推理可借助检索增强生成(RAG)与外部知识源对齐。
在此基础上,自我演化层(第4节详述)引入了使智能体随时间提升自身能力的机制。这通过反馈循环实现,使智能体能反思自身表现。框架识别出三种主要反馈模式:反思反馈(允许智能体在推理阶段修订推理)、参数适应(通过监督或强化学习更新模型参数)和验证器驱动反馈(使用外部信号如成功/失败引导重采样)。该层还包括自我演化记忆,即智能体的记忆并非静态,而是主动管理和更新,使其能从过往经验中学习并调整策略。
系统能力通过协作式多智能体推理进一步扩展(第5节详述)。这涉及将任务分配给具有不同角色(如领导者、执行者或批评者)的专用智能体。这种基于角色的协作允许分解复杂问题并协调行动,使系统能处理单个智能体无法胜任的任务。框架还强调了这些核心推理能力在机器人、医疗、金融和科学发现等领域的应用,展示了智能体范式的多功能性。作者的方法将这些多样化能力统一在一个控制理论框架下,为构建先进、自主的人工智能系统提供了系统性且可扩展的架构。
实验
- 后训练规划方法通过强化学习或控制理论验证奖励设计和最优控制,如Reflexion、Reflect then-Plan和Rational Decision Agents等系统使用基于效用的学习来引导行为。
- 奖励建模与塑造应用于文献[189, 190],而最优控制在文献[191–194]中被明确讨论,通过扩散模型进行轨迹优化的方法见于文献[195–197]。
- 离线强化学习方法[119, 198, 147]使用预训练的动力学或成本模型优化规划,通过在连续或学习的奖励空间上操作,补充符号或启发式方法。
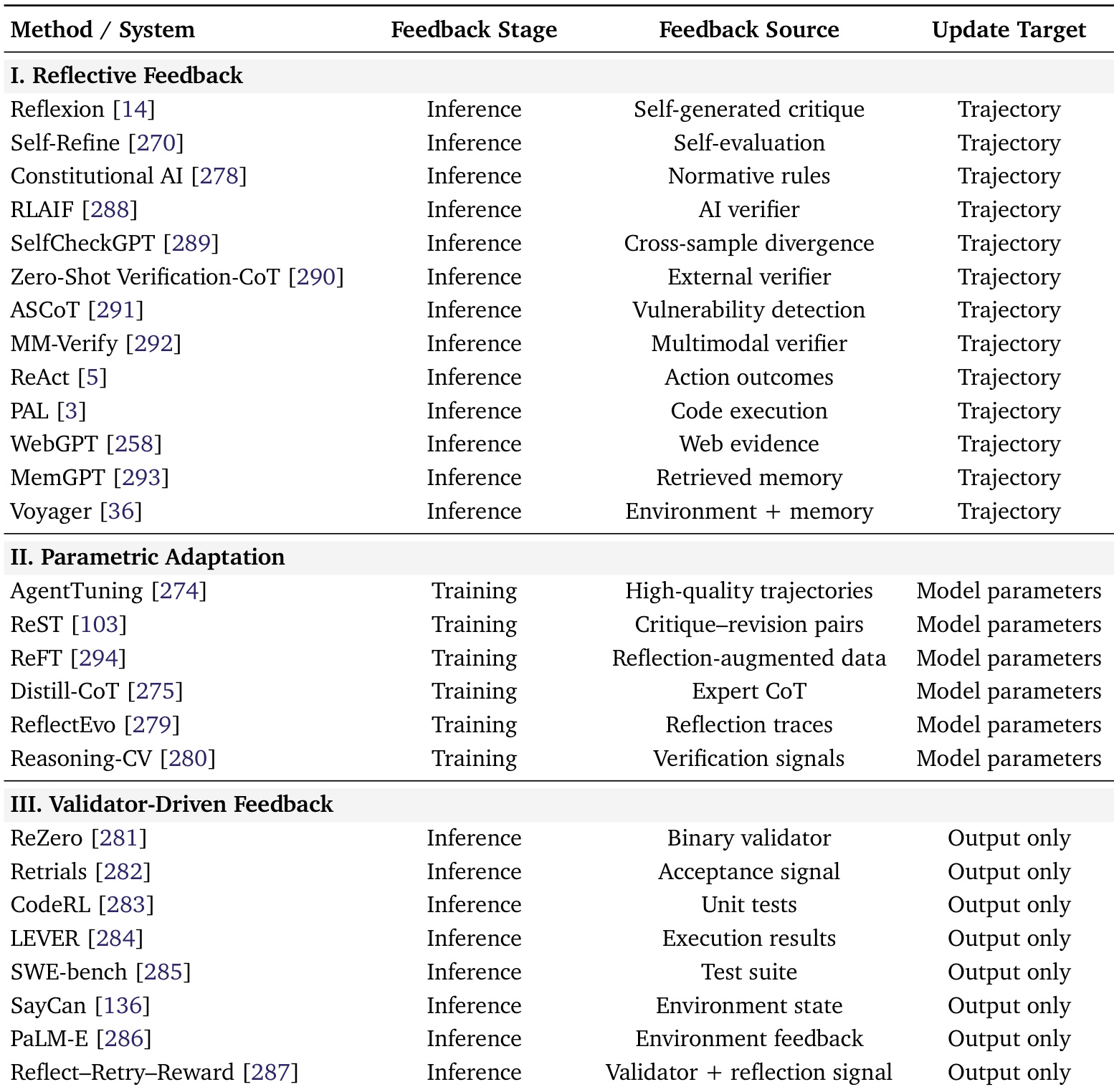
作者使用表格将工具使用优化系统分为三种反馈类型:反思式、参数适应式和验证器驱动式。结果表明,反思式方法主要依赖推理阶段来自自身或外部的反馈以更新轨迹,而参数适应式和验证器驱动式方法则聚焦于训练阶段或推理阶段的反馈,用于调整模型参数或仅调整输出。