Command Palette
Search for a command to run...
MMDeepResearch-Bench:多模态深度研究Agent基准测试
MMDeepResearch-Bench:多模态深度研究Agent基准测试
摘要
深度研究代理(Deep Research Agents, DRAs)通过多步搜索与综合生成富含引用的报告,然而现有的评估基准主要针对纯文本场景或短格式多模态问答任务,未能充分涵盖端到端的多模态证据使用能力。为此,我们提出了MMDeepResearch-Bench(MMDR-Bench),一个包含140个由专家精心设计的任务的基准,覆盖21个不同领域。每个任务均提供图像-文本组合数据包,用于评估模型在多模态理解与基于引用的报告生成方面的能力。相较于以往设置,MMDR-Bench强调以报告形式进行综合输出,并明确要求模型在生成过程中显式引用证据,即必须将视觉元素与来源声明有效关联,并确保叙事内容、引用信息与视觉参考之间的一致性。为进一步提升评估的可解释性与诊断能力,我们提出了一套统一且可解释的评估流程:- Formula-LLM Adaptive Evaluation (FLAE):用于评估报告整体质量;- Trustworthy Retrieval-Aligned Citation Evaluation (TRACE):用于衡量引用与证据之间的对齐程度;- Multimodal Support-Aligned Integrity Check (MOSAIC):用于检测文本与视觉内容之间的一致性。上述三个模块均能输出细粒度的评估信号,支持对模型错误类型的精准诊断,超越单一综合评分的局限性。在25个前沿先进模型上的实验结果揭示了生成质量、引用规范性与多模态锚定性之间的系统性权衡:仅具备出色文笔并不足以保证对证据的忠实使用,而多模态一致性仍是深度研究代理面临的核心瓶颈。
一句话总结
来自俄亥俄州立大学、亚马逊、密歇根大学等机构的研究人员推出了 MMDeepResearch-Bench,这是一个包含 140 项专家级任务的多模态基准,用于评估基于引用的报告合成能力,并提出了 FLAE、TRACE 和 MOSAIC 三种细粒度评估方法,揭示了当前深度研究代理在证据保真度和多模态对齐方面存在的关键缺陷。
主要贡献
- 我们推出了 MMDR-Bench,这是首个包含 140 项专家策划、覆盖 21 个领域的多模态任务基准,旨在评估深度研究代理在整合视觉素材与引用支撑主张方面生成长篇报告的能力,弥补了以往研究中缺乏端到端多模态评估的空白。
- 我们提出了一种三组件评估流程——FLAE 用于报告质量、TRACE 用于引用对齐、MOSAIC 用于文本-视觉一致性——每个组件都能提供可解释的细粒度信号,超越聚合分数诊断失败原因,从而精确评估多模态接地和证据保真度。
- 对 25 种最先进模型的实验表明,行文质量、引用规范性和多模态完整性之间存在持续的权衡,结果显示,优秀的叙述输出并不意味着忠实使用证据,而视觉接地仍是当前研究代理的关键瓶颈。
引言
作者利用大型多模态模型的最新进展,应对在文本与视觉数据上执行深度、基于证据研究的代理日益增长的需求。以往基准要么专注于纯文本报告生成,要么仅限于短篇多模态问答,未能评估系统如何将视觉证据整合进长篇、富含引用的综合报告——这是现实研究工作流中的关键缺口。他们的主要贡献是 MMDeepResearch-Bench(MMDR-Bench),一个包含 140 项任务的基准,涵盖 21 个领域的专家制作图文包,配以三部分评估框架:FLAE 用于报告质量、TRACE 用于引用保真度、MOSAIC 用于文本-视觉一致性——共同实现超越单一分数的细粒度代理失败诊断。
数据集

-
作者将 MMDR-Bench 定义为一个多模态深度研究基准,包含 140 项专家策划的任务,覆盖 21 个领域,分为两类:日常类(40 项任务,覆盖 11 个领域)和研究类(100 项任务,覆盖 10 个领域)。日常任务使用截图和 UI 捕获等随意视觉素材,而研究任务则使用图表和表格等结构化视觉素材,要求更深层次的综合能力。
-
每项任务是一个图文包:一个文本查询配以可变数量的图像,这些图像必须在生成的报告中被解释并引用。任务由领域专家策划,并通过清晰性、多模态必要性(图像必须不可或缺)和证据接地(报告必须可通过引用验证)检查进行精炼。
-
该基准支持多语言,主要为英文和中文,长尾部分包含其他语言。任务标注了难度(简单、困难、复杂),并附带元数据,包括语言和视觉模态类型。
-
作者将完整的 140 项任务集用作评估基准——而非训练。未应用训练集划分或混合比例;数据集作为固定测试套件,用于评估多模态理解和带引用的证据支撑报告生成。除专家策划和标注步骤外,未提及裁剪或预处理。
方法
针对长篇深度研究报告的评估框架围绕三个主要模块构建:FLAE(公式-LLM 自适应评估)、TRACE(可信检索对齐引用评估)和 MOSAIC(多模态支持对齐完整性检查)。这些模块并行处理生成的报告,分别评估不同方面的质量,并通过门控机制整合以产生最终分数。整体流程始于代理生成的多模态深度研究报告,随后由三个评估器分别处理。FLAE、TRACE 和 MOSAIC 的输出通过一个多模态门控,判断报告是否达到每个模块的最低阈值,仅当所有门控激活时才计算最终分数。
FLAE 从三个与任务无关的维度评估报告:可读性(READ.)、洞察力(INSH.)和结构完整性(STRU.)。该评估通过双通道方法进行。公式通道使用一组轻量级、直接可观察的文本特征 ϕ(R)(如词汇多样性、句子长度分布、参考文献部分存在性等合规指标)计算各维度得分。这些特征通过带 Sigmoid 激活和裁剪的线性模型的固定、可审计变换映射至分数,确保可复现性。LLM 判断通道使用校准提示,基于任务和报告生成各维度得分。为结合这两个通道,FLAE 采用自适应融合机制。一个判断 LLM 计算融合系数 α(t,R),控制公式得分与判断得分的混合比例,该系数被约束仅依赖于与模型无关的信号,如报告长度和格式合规性。这种自适应融合旨在减轻偏差,确保最终得分是客观指标与专家判断的平衡组合。最终 FLAE 得分为各维度融合得分的加权和,权重由独立的判断 LLM 提示自适应确定。
TRACE 评估报告在引用来源中的接地情况及其对任务的忠实度。它首先解析报告以提取主张-URL 对,将每个引用映射到其对应来源。对于可访问的来源,判断 LLM 验证每个主张的支持情况,考虑证据一致性、覆盖范围和文本保真度。该过程产生三个引用保真度指标:一致性(Con.)、覆盖率(Cov.)和文本保真度(FID.)。此外,TRACE 包含严格的视觉证据保真度(VEF.)检查,确保报告正确解释并回答任务的视觉要求。VEF. 得分为 0 至 10 的离散值,通过固定阈值 6 强制执行 PASS/FAIL 判定,使该组件在不同判断模型间可审计且一致。最终 TRACE 得分为 VEF. 得分与其他三个指标的加权组合,权重为任务自适应。
MOSAIC 通过验证图像引用语句是否忠实于底层视觉内容,评估报告多模态内容的完整性。它首先解析报告以提取多模态项(MM-items),包括引用图像的文本和图像本身。这些项根据其视觉模态(照片、数据图表或示意图)路由至特定类型评估器,使用轻量级路由器。每项在三个维度上评分:视觉语义对齐(SEM.)、视觉数据解释准确性(ACC.)和复杂视觉问答质量(vQA)。项目级得分通过这些维度得分的加权聚合计算。最终 MOSAIC 得分源自项目级得分,其激活由其他两个评估器的表现控制。
实验
- 通过 MMDR-Bench 评估多模态深度研究代理,结合 FLAE(20%)、TRACE(50%)和 MOSAIC(30%)并采用门控激活;Gemini-2.5-Pro 作为判断 LLM。
- Gemini Deep Research 总体排名第一,在证据质量(TRACE)方面表现优异,并保持强大的多模态对齐(MOSAIC);Gemini 3 Pro(预览版)在非代理网页启用模型中领先。
- 仅当视觉可靠接地时,视觉才能提升性能;向 Qwen 3 模型添加视觉功能会增加细粒度提取错误(如误读数字、标签),揭示提示保真度瓶颈。
- 多模态对齐与引用接地可能背离:Gemini Deep Research 提高了证据覆盖率,但在多步合成过程中实体误归因增加。
- 工具使用放大强大骨干模型的优势,但无法取代它们;Tongyi Deep Research(30B)表现不如更大模型,而 Gemini Deep Research(Gemini 3 Pro)结合了高覆盖率和整体实力。
- 在研究类任务中,Gemini Deep Research 和 Gemini 3 Flash 广泛领先;GPT-5.2 在计算机与数据科学领域表现优异;Qwen 3 VL 通过图表/示意图接地在环境与能源领域占据主导。
- 人工评估(12 位专家,140 项任务)确认评估器对齐:完整系统优于普通判断器;VEF. 和 MOSAIC 提高了人工一致性(PAR/OPC 指标)。
- 跨判断器测试(GPT-5.2 与 Gemini-2.5-Pro)显示总体分数稳定(±0.30 分),尽管各模块存在差异;MOSAIC 在不同判断器间保持高度一致。
- VEF. 使用严格的任务特定视觉真实值(得分 ≥6 时为 PASS/FAIL);身份错误强制立即 FAIL;通过任务百分比报告通过率(例如,38.57% = 38.57% 通过率)。
- 失败分析揭示:视觉启用模型增加 DTE(细节提取错误);代理系统因多步合成漂移增加 EMI(实体误识别)。
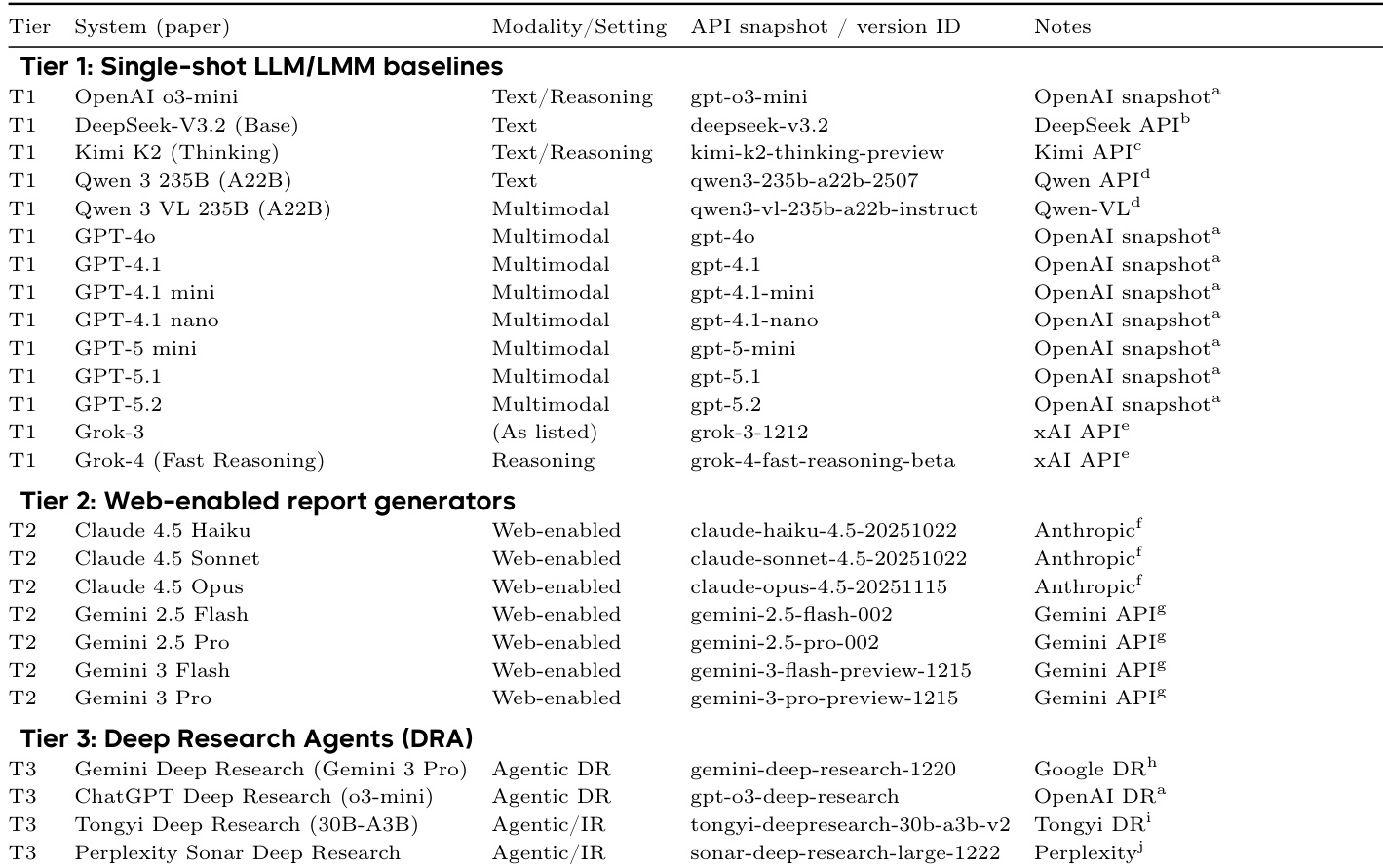
作者使用多模态评估框架评估深度研究代理,结果显示 Gemini-2.5-Pro 在大多数指标上优于 GPT-5.2,尤其在 AVG FLAE 和包含 VEF. 的 AVG MMDR 上。GPT-5.2 在 AVG TRACE 和不含 VEF. 的 AVG MMDR 上表现更好,表明其证据质量更强但视觉保真度较低,而 Gemini-2.5-Pro 保持更一致的多模态对齐和整体性能。
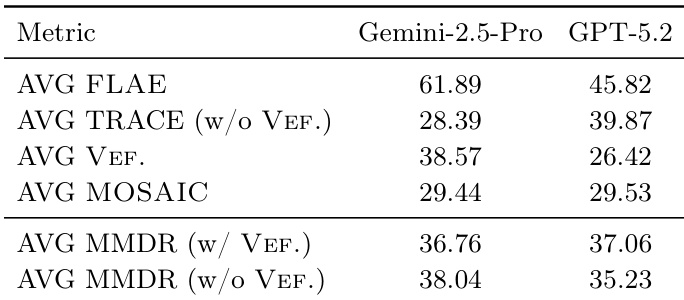
作者在 MOSAIC 评估中为视觉项使用标准化评分系统,每种视觉类型的得分基于特征得分和质量指标的加权组合。对于数据图表和 OCR 图表,得分基于准确性和视觉质量;对于照片,结合语义和视觉质量;对于示意图,平衡视觉质量与结构正确性的二元指标。
作者通过比较 140 项任务上的成对偏好和分数相关性,评估其自动评估器与专家判断的一致性。结果显示,使用从判断输出导出的融合系数的完整评估器比仅公式或仅判断基线与专家达成更高一致性(PAR 73.5,OPC 96.4),表明融合方法更好地捕捉人类偏好。

作者使用人工一致性检查评估其自动评估器与专家判断在多模态报告上的一致性。结果显示,完整的 MMDR-Bench-Eval 系统在成对一致性(PAR)和分数相关性(OPC)方面比普通提示式判断器与专家达成更高一致,表明评分更符合人类判断。移除 MOSAIC 会降低性能,而省略 VEF. 影响较小,表明两个组件均有助于更精确的评估。

作者使用三级评估框架评估多模态深度研究代理,第一级为单次推理 LLM/LMM 基线,第二级为网页启用报告生成器,第三级为专用深度研究代理。结果显示,Gemini Deep Research(Gemini 3 Pro)获得最高总体分数,得益于强大的证据质量和多模态对齐,同时表明视觉和工具使用仅在可靠且良好集成到系统中时才提供益处。