Command Palette
Search for a command to run...
MemoryRewardBench:面向大型语言模型长期记忆管理的奖励模型基准测试
MemoryRewardBench:面向大型语言模型长期记忆管理的奖励模型基准测试
Zecheng Tang Baibei Ji Ruoxi Sun Haitian Wang WangJie You Zhang Yijun Wenpeng Zhu Ji Qi Juntao Li Min Zhang
摘要
现有研究日益采用以记忆为中心的机制,以分段方式处理长序列上下文,而高效的记忆管理能力是大语言模型实现全序列信息有效传播的关键所在。因此,利用奖励模型(Reward Models, RMs)自动且可靠地评估记忆质量至关重要。本文提出 MemoryRewardBench,这是首个系统性研究奖励模型在评估长期记忆管理能力方面表现的基准测试。MemoryRewardBench 涵盖长上下文理解与长文本生成两类任务,包含10种具有不同记忆管理模式的设置,上下文长度覆盖8K至128K个标记(tokens)。对13个前沿奖励模型的评估结果显示,开源模型与专有模型之间的性能差距持续缩小,且新一代模型无论参数规模如何,均持续优于其前代模型。此外,本研究进一步揭示了当前奖励模型在多样化设置下评估大语言模型记忆管理能力方面的实际能力与根本局限性。
一句话总结
苏州大学、LCM实验室与中国移动的研究人员推出了MemRewardBench,这是首个评估奖励模型(RM)在10种不同场景下(上下文长度最高达128K tokens)评估大语言模型(LLM)长上下文记忆管理能力的基准测试,揭示了当前模型的性能趋势与局限性。
主要贡献
- MemRewardBench是首个专门评估奖励模型(RM)评估大语言模型长期记忆管理能力的基准测试,涵盖10种不同场景(包括理解和生成任务),上下文长度从8K到128K tokens。
- 该基准引入了两种评估标准——基于结果和基于过程——以将记忆管理质量与最终输出正确性分离,从而更细致地评估RM在判断记忆轨迹方面的能力。
- 对13种前沿RM的评估显示,新一代模型无论规模大小均优于旧模型,开源与专有模型之间的性能差距正在缩小,同时也揭示了当前RM在不同记忆模式下的关键局限性。
引言
作者利用奖励模型(RM)评估大语言模型在分段处理长上下文时的长期记忆管理能力——这对多轮对话和长篇推理等应用至关重要。以往的基准测试要么通过人工标注评估记忆,要么仅依赖基于结果的指标,缺乏对记忆更新本身的自动化、过程导向评估。MemRewardBench填补了这一空白,首次系统性地测试了13种RM在10种记忆管理场景下的表现(上下文长度8K至128K tokens),并采用基于结果和基于过程两种评估标准。其主要发现表明,新一代RM无论规模大小均优于旧模型,开源模型在推理任务上已可媲美专有模型——但在高内存需求的生成和对话任务上仍落后。
数据集

作者使用MemRewardBench评估奖励模型(RM)在三大核心任务中判断大语言模型长期记忆管理的能力:长上下文推理、多轮对话理解与长篇生成。每项任务旨在评估不同的记忆能力——MR(多跳推理)、TR(时序推理)、KU(知识更新)、DU(对话理解)和GEN(生成)——并同时采用基于结果和基于过程的评估标准。
关键数据子集与构建方式:
-
长上下文推理(基于BABILong和LongMIT):
- 规模:未明确说明,但基于现有长上下文数据集构建。
- 构建:使用MemAgent生成记忆轨迹。选中样本为正确最终结果;拒绝样本通过两种扰动生成:
- NOISE:注入冗余或错误的记忆更新(使用较弱LLM + LLM-as-judge修正循环)。
- DROP:移除关键上下文块以诱导证据缺失。
- 混合模式:结合并行处理(p=2或3块)与顺序聚合。
- 过滤:丢弃选中样本无法正确回答的轨迹;确保关键信息完全包含于单一块中。
-
多轮对话理解(基于LoCoMo和MemoryAgentBench):
- 规模:未明确说明,但包含两种记忆系统:A-Mem(语义标记)和Mem0(全局摘要)。
- 构建:选中样本 = 完整轮次记忆更新并得到正确答案。拒绝样本 = 跳过更新,分为两类:
- MEM:最终答案正确但记忆管理有缺陷。
- OUT:因缺失关键信息导致答案错误。
- 过滤:仅保留选中轨迹能得出正确答案的样本。
-
长篇生成(基于LongProc、LongGenBench、LongEval):
- 规模:未明确说明,但使用路径遍历(LongProc)和约束驱动生成(LongGenBench/LongEval)。
- 构建:
- 顺序:将指令分解为逐步约束;增量生成。
- 并行:将指令分解为子任务;独立生成后聚合。
- 选中样本:满足所有约束的黄金标准输出(由强LLM分块验证)。
- 拒绝样本:通过约束扰动(LongEval)或省略(LongGenBench)生成,保持输出长度。
- 过滤:拒绝包含幻觉或缺失中间记忆状态的样本。
数据在训练中的使用方式:
- 作者为每项任务和记忆模式(顺序、混合、MEM、OUT)构建偏好对(选中 vs. 拒绝)。
- 训练划分未明确说明,但该基准旨在评估RM而非训练。
- 未提及裁剪;而是通过分块(长上下文推理)或分解(长篇生成)模拟记忆管理。
- 元数据包括记忆轨迹类型(顺序/混合)、扰动类型(NOISE/DROP)和结果/记忆质量标签(MEM/OUT)。
- 处理包括LLM-as-judge验证、约束分解和轨迹缓存以确保可复现性。
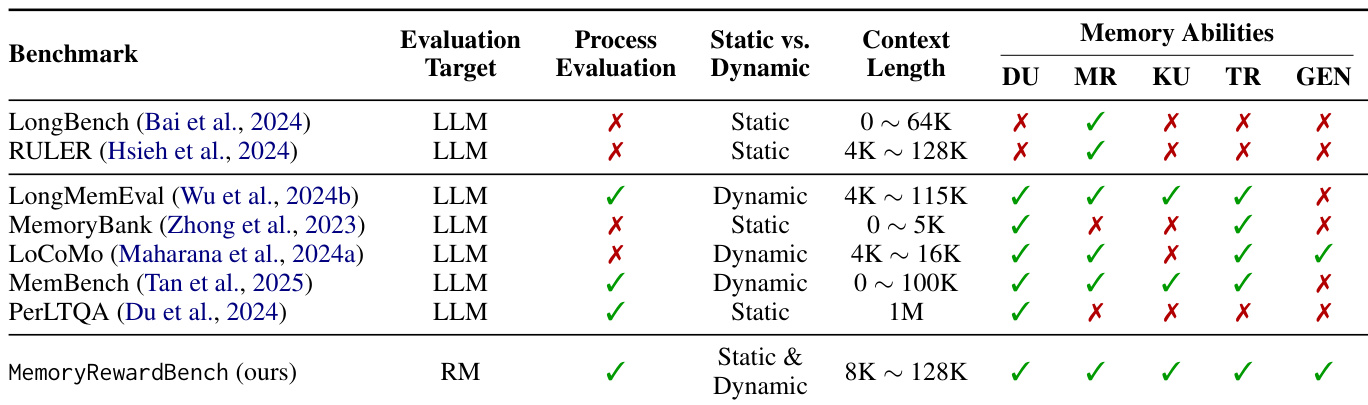
MemRewardBench独特地强调对中间记忆状态的过程级评估,支持静态(长上下文、长篇)和动态(对话)场景,且覆盖比以往基准更广的上下文长度范围。
方法
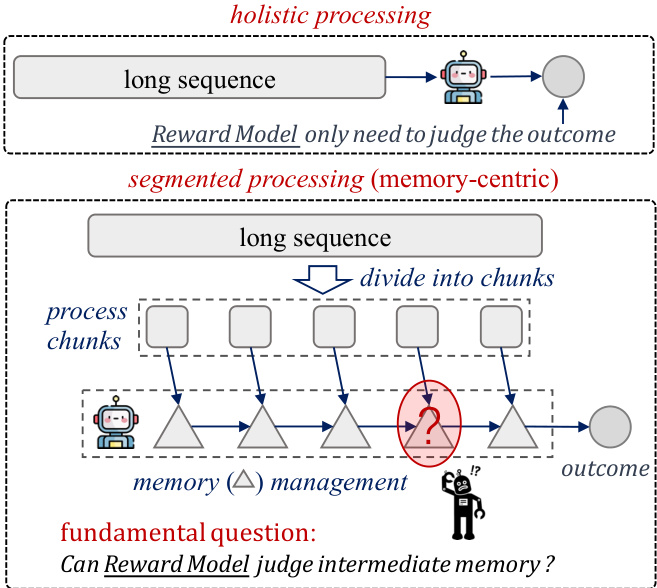
作者采用一种记忆管理框架,通过将长序列分解为可管理的块进行处理,其核心机制由两种基本模式控制:顺序处理与并行处理。如下图所示,整体方法从长序列开始,将其分割为较小块,再通过以记忆为中心的机制生成最终结果。该框架区分整体处理(将整个序列视为单一单元)与分段处理(将序列划分并分部分处理),从而引出核心问题:奖励模型能否有效判断中间记忆状态。
顺序模式按顺序处理各块,维护单一演进的记忆状态。给定模型 Φ 和块序列 C={c1,c2,⋯,cn},中间记忆 M={m1,m2,⋯,mn} 逐步更新:m1=Φ(c1),对于 t=2,⋯,n,mt=Φ(mt−1,ct)。最终结果由最后一个记忆状态 mn 导出。相比之下,并行模式将输入上下文划分为 k 个独立组 C={G1,⋯,Gk},每组 Gj={cj,1,⋯,cj,nj} 并行处理。在每组内应用顺序模式更新记忆状态,得到每组的最终记忆状态 m(j)。最终结果通过融合操作 g 聚合所有 m(j) 得到:o=q(m(1),⋯,m(k))。
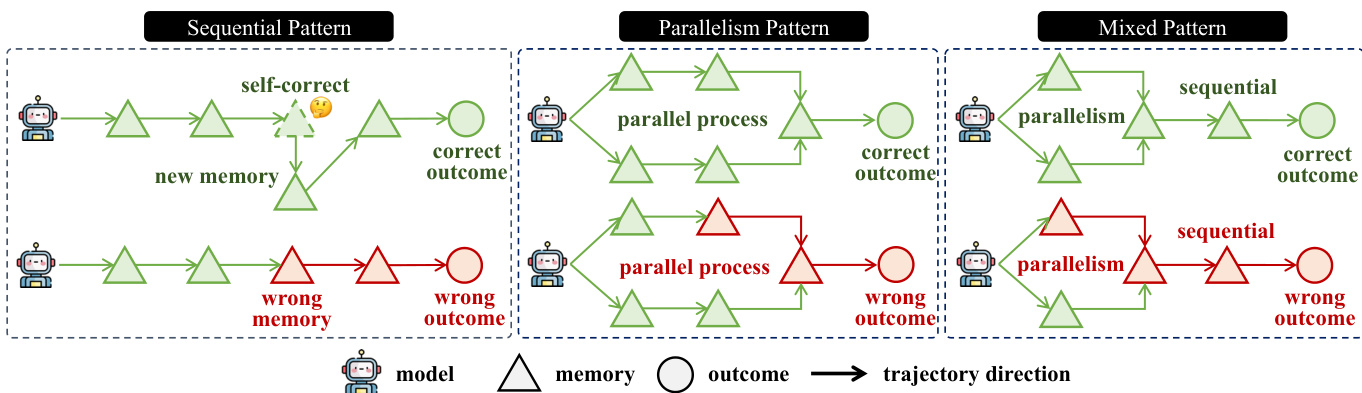
任何记忆管理策略均可归类为顺序模式、并行模式或两者的组合(称为混合模式)。混合模式结合顺序与并行处理步骤,支持更复杂灵活的记忆管理。该框架设计用于处理各种处理场景,包括自我修正与错误传播,如图中不同轨迹所示。模型在这些模式下有效管理记忆的能力对准确预测结果至关重要。
实验
- 评估了13种LLM(3种专有,10种开源)作为奖励模型(RM)用于记忆管理;专有模型整体领先,Claude-Opus-4.5平均准确率达74.75,其次是Gemini-3.0-Pro(71.63);GLM4.5-106A12B(68.21)优于专有Qwen3-Max(67.79)并领先开源模型。
- 在长上下文推理和长篇生成任务中,顺序记忆管理模式下的RM准确率显著高于并行模式,表明RM偏好逐步推理。
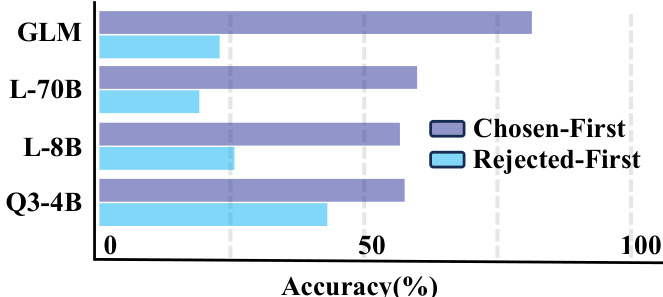
- RM在基于结果的标准下表现高度一致,但在基于过程的标准下(结果均正确但轨迹不同)表现出位置偏差和不一致性。
- 在长篇生成中,RM性能在约25%约束密度时达到峰值;超过该密度后,性能趋于平稳或下降,揭示其处理密集多面约束的能力有限。
- 多数RM在64K tokens内保持>50%准确率,但许多模型在超过32K后性能急剧下降;Llama-3.3-70B-Instruct在64K/128K时崩溃,而GLM-4.5-Air和Qwen2.5-72B-Instruct保持稳定。
- 在多轮对话中为记忆更新添加语义标签可提升RM准确率,提供简洁上下文,减少对冗长轨迹解析的依赖。
- Qwen3-14B因后训练增强优于更大模型如Qwen2.5-72B和Llama-3.3-70B,在约束遵守和推理保真度方面表现优异,尽管规模较小。
作者使用MemoryRewardBench评估奖励模型在多个与记忆相关的任务中的表现,并与现有基准进行比较。结果表明,MemoryRewardBench支持静态与动态记忆评估,覆盖广泛的上下文长度范围,并评估多样化的记忆能力,是评估LLM记忆管理的综合框架。
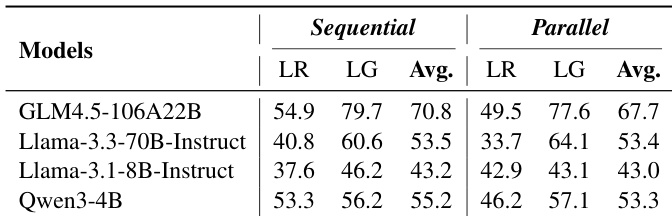
结果表明,所有模型和任务中,RM在顺序模式下的准确率显著高于并行模式。顺序处理的平均准确率始终高于并行处理,表明当前奖励模型强烈偏好逐步推理。
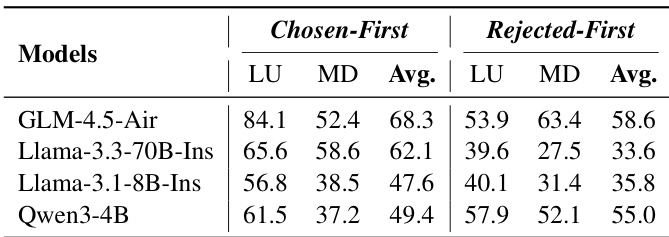
结果表明,RM在顺序记忆管理模式下的准确率显著高于并行模式,顺序模式在“选中优先”和“拒绝优先”设置下平均得分为68.3和58.6,而并行模式得分为49.4和55.0。这表明当前奖励模型强烈偏好逐步推理过程。
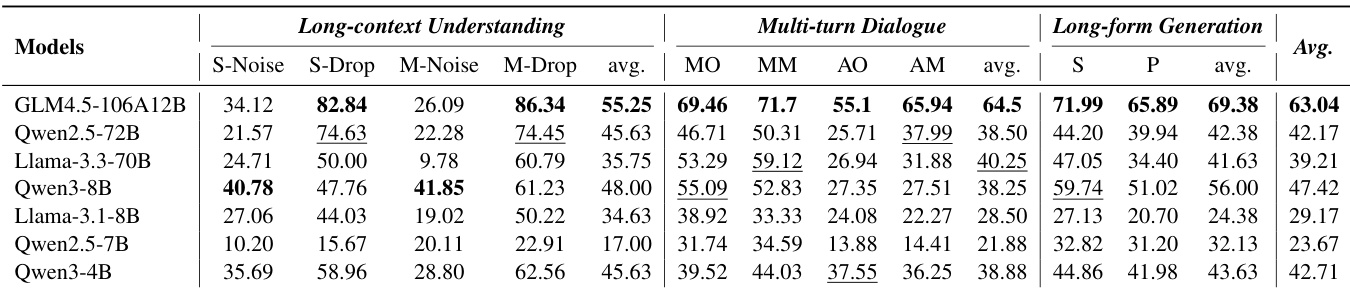
结果表明,顺序记忆管理模式在所有任务中始终优于并行模式,顺序模式在长上下文理解、多轮对话和长篇生成中均实现更高准确率。所有模型的平均性能在顺序模式下显著更优,表明当前奖励模型强烈偏好逐步推理过程。
结果表明,RM在顺序模式下的准确率显著高于并行模式,顺序模式在所有模型中始终优于并行模式。作者通过此比较得出结论:当前RM更偏好渐进式、逐步推理过程,这与其训练数据中常见的因果结构更吻合。