Command Palette
Search for a command to run...
基于LLM的软件工程问题求解进展与前沿:一项综合调查
基于LLM的软件工程问题求解进展与前沿:一项综合调查
摘要
问题求解(Issue Resolution)作为软件工程(Software Engineering, SWE)中一项复杂且在现实开发中至关重要的任务,已逐渐成为人工智能领域的一个重要挑战。SWE-bench 等基准测试的建立揭示了大型语言模型在该任务上面临的巨大困难,从而显著推动了自主编程代理(autonomous coding agents)的发展进程。本文对这一新兴研究领域进行了系统性综述。首先,我们考察了数据构建流程,涵盖自动化采集与数据合成等方法。随后,对现有方法论进行了全面分析,从无需训练的模块化框架,到基于训练的技术,包括监督微调(supervised fine-tuning)与强化学习(reinforcement learning)等范式。接着,我们深入探讨了数据质量与代理行为的关键评估问题,并总结了其在实际场景中的应用进展。最后,本文识别出当前面临的核心挑战,并展望了未来研究的若干有前景的方向。为促进该领域的持续发展,我们维护了一个开源资源库(https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution),作为本领域动态更新的知识与工具集合,供研究者参考与使用。
一句话总结
中山大学、华为及合作机构的研究人员对软件工程中的自主问题解决进行了综述,分析了数据管道、代理架构和训练方法,同时识别关键挑战,并维护一个开放仓库以推动这一新兴AI驱动领域的发展。
主要贡献
- 本文首次系统性地综述了AI驱动的软件工程问题解决,围绕数据管道、代理方法(单/多代理与工作流驱动)及行为分析构建该领域框架,填补了以往仅关注代码生成的综述所遗留的关键空白。
- 提出了定制化的分类体系,分析了175+篇相关工作,突出如SWE-agent的工具驱动仓库交互、Darwin Gödel Machine的自我演化、DEIBase的多代理协调等创新,同时考察了支持上下文感知与策略驱动决策的记忆架构。
- 综述识别了持续存在的挑战——包括推理不精确、协作建模与可扩展性——并提供开源仓库以跟踪进展,作为超越SWE-bench基准限制、推动自主编码代理发展的基础资源。
引言
作者利用大型语言模型的兴起,解决软件工程中的问题修复——这是一种复杂的仓库级任务,超越了函数生成,需要环境交互、工具使用和多步推理。以往工作多聚焦于代码补全或孤立生成,未能应对真实开发中动态、协作与维护密集的特性,SWE-bench等基准已暴露此缺陷。其主要贡献是对175篇论文的系统性综述,将该领域划分为三个支柱:数据构建、代理框架(单/多代理、工作流驱动)与实证分析——同时识别效率、安全性、多模态推理与评估严谨性等关键空白,并提供开源仓库以跟踪进展。
数据集

-
作者混合使用评估与训练数据集,数据源为真实GitHub仓库并辅以自动化合成,用于在软件问题修复任务上基准测试与训练模型。
-
评估数据集包括SWE-bench(2,294个Python问题,含仓库快照)及其验证子集SWE-bench Verified,后者过滤无效测试与描述不充分的问题。多语言扩展(SWE-bench Multilingual, Multi-SWE-bench)覆盖10+种语言,包括Java、Go和Rust。多模态数据集(如SWE-bench Multimodal, CodeV)整合UI截图与图表,支持前端任务。企业级数据集(如Miserendino等、Deng等)增加领域复杂性与长时程演化场景。
-
训练数据集分为三类:(1) 文本数据——来自SWE-bench的静态问题-PR对;(2) 环境数据——交互式Docker/Conda环境(如Multi-SWE-RL, R2E-Gym),使模型能接收执行反馈;(3) 轨迹数据——记录代理-环境交互(如来自Nebius, Jain等),经验证器筛选后生成多个候选方案。
-
数据构建依赖自动化管道:自动收集GitHub PR,提取CI/CD配置(如GitHub Actions)构建Docker环境,并通过执行检查过滤任务(如确保至少一个测试从失败转为通过)。自动化合成工具如SWE-Synth、SWE-Smith、SWE-Mirror通过重写代码、改写问题或移植缺陷到新仓库生成新任务——均在共享环境中验证以降低开销。
-
每个任务结构为三元组:(D) 问题描述,(C) 修复前代码库,(T) 测试套件分为F2P(失败转通过)与P2P(通过转通过)测试。模型生成补丁时不可见测试;评估阶段应用补丁、运行测试,若所有测试通过则计为成功。元数据包括仓库所有者/名称、提交哈希与测试规格。不使用裁剪;任务通过git checkout与Docker化环境隔离以确保可复现性。
方法
作者采用综合框架解决软件问题,整合无训练与基于训练的方法以合成有效代码补丁。整体流程始于输入——问题描述、代码库及关联测试——在环境中处理以生成补丁。框架支持多样方法,包括无需模型重训练及使用监督或强化学习增强模型能力的方法。
参考框架图  理解高层架构。该图展示核心组件:输入阶段(提供问题陈述与代码库)、问题解决方法(生成补丁)、评估阶段(应用补丁并测试)。流程为迭代式,生成补丁后经测试套件评估以判断是否成功解决。
理解高层架构。该图展示核心组件:输入阶段(提供问题陈述与代码库)、问题解决方法(生成补丁)、评估阶段(应用补丁并测试)。流程为迭代式,生成补丁后经测试套件评估以判断是否成功解决。
无训练方法(详见分类体系)依赖外部工具与复杂提示增强LLM推理能力,无需修改其参数。这些方法分为框架、模块与推理时扩展策略。框架图 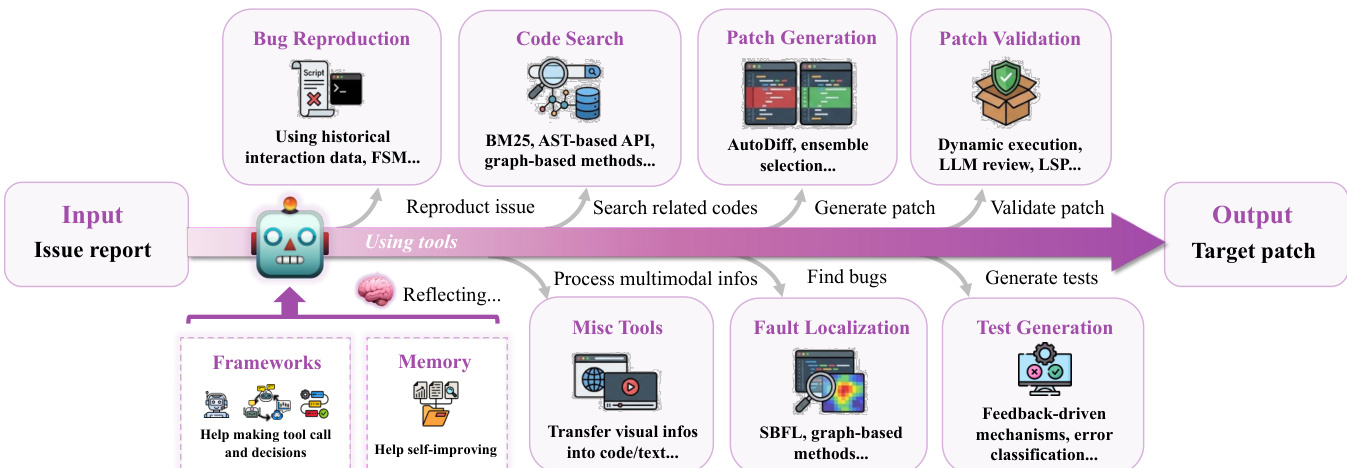 详细分解工具模块。工具按标准修复流程组织:起始于缺陷复现(自动生成可执行脚本触发缺陷),继而故障定位(使用如基于频谱的故障定位SBFL或图技术识别可疑代码区域),代码搜索工具(采用交互式检索、图理解与动态管理策略获取相关上下文),补丁生成工具(通过规范推断与稳健编辑格式提升输出质量),补丁验证工具(通过动态执行或静态分析确认正确性),测试生成工具(创建复现测试用例验证修复)。
详细分解工具模块。工具按标准修复流程组织:起始于缺陷复现(自动生成可执行脚本触发缺陷),继而故障定位(使用如基于频谱的故障定位SBFL或图技术识别可疑代码区域),代码搜索工具(采用交互式检索、图理解与动态管理策略获取相关上下文),补丁生成工具(通过规范推断与稳健编辑格式提升输出质量),补丁验证工具(通过动态执行或静态分析确认正确性),测试生成工具(创建复现测试用例验证修复)。
相比而言,基于训练的方法通过监督微调(SFT)与强化学习(RL)增强LLM基础编程能力。SFT方法聚焦数据扩展、课程学习与拒绝采样,使模型适应软件工程协议。SFT过程如框架图 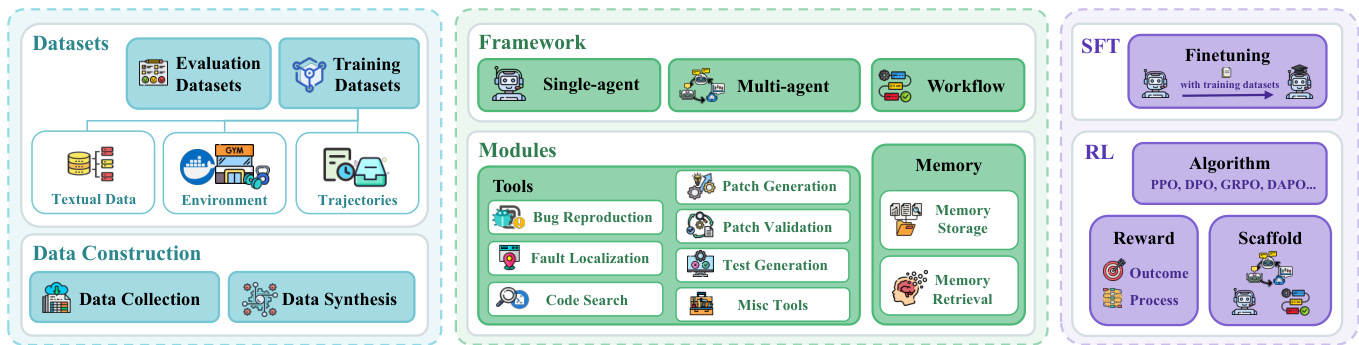 所示,使用训练数据集进行微调。RL方法通过迭代交互优化问题解决策略,依赖三个核心组件:策略更新算法、奖励设计与环境 rollout 管理支架。算法组件包括组相对策略优化(GRPO)、近端策略优化(PPO)与直接偏好优化(DPO)。奖励设计结合稀疏结果导向奖励与密集过程导向信号,为推理过程提供反馈。支架作为rollout推理框架,OpenHands为最常用选择。
所示,使用训练数据集进行微调。RL方法通过迭代交互优化问题解决策略,依赖三个核心组件:策略更新算法、奖励设计与环境 rollout 管理支架。算法组件包括组相对策略优化(GRPO)、近端策略优化(PPO)与直接偏好优化(DPO)。奖励设计结合稀疏结果导向奖励与密集过程导向信号,为推理过程提供反馈。支架作为rollout推理框架,OpenHands为最常用选择。
实验
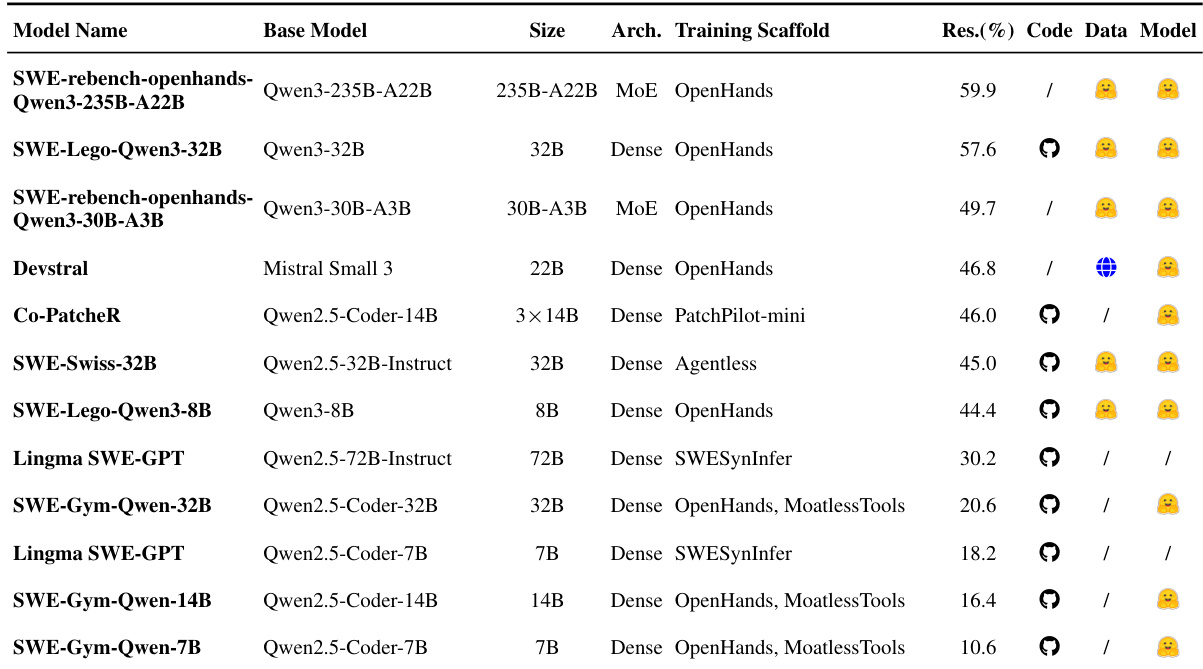
- 表3总结基于SFT的问题解决方法,按架构与训练支架分类模型,按性能排序。
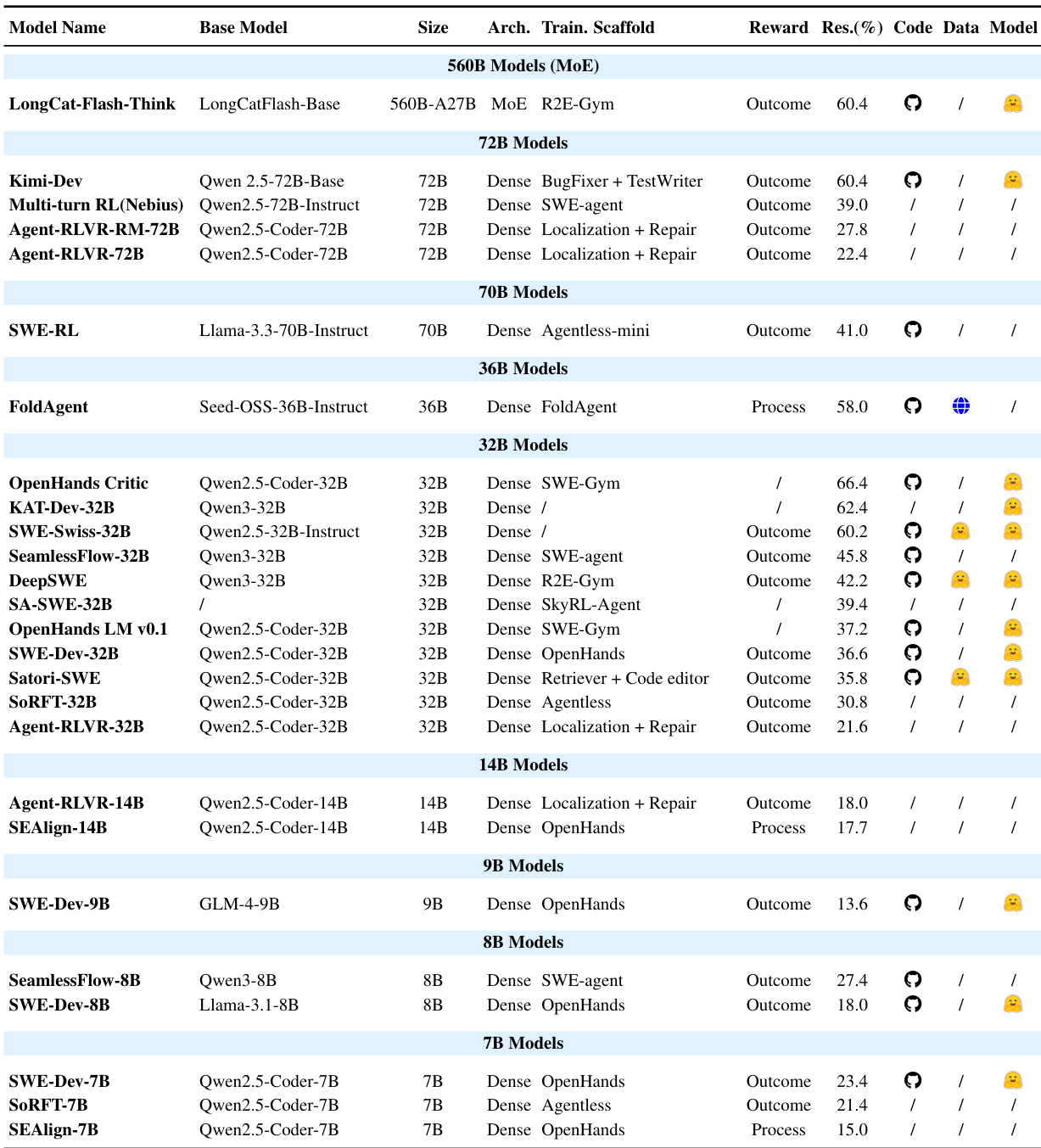
- 表4展示经RL微调的专用模型,表明小型稠密模型(7B–32B)在使用领域特定奖励时可匹敌大型基线;过程奖励日益补充稀疏结果奖励,以稳定长时程任务训练。
- 表5评估依赖外部推理支架的通用基础模型,作为对照组突出第4.2节中SFT与RL管道的性能提升。
作者使用表格比较用于问题解决的多种模型,按规模与训练方法分类。结果表明,小型模型如32B和7B在优化领域特定奖励(尤其是过程奖励等密集反馈信号)时可实现有竞争力的性能,有助于稳定复杂任务训练。
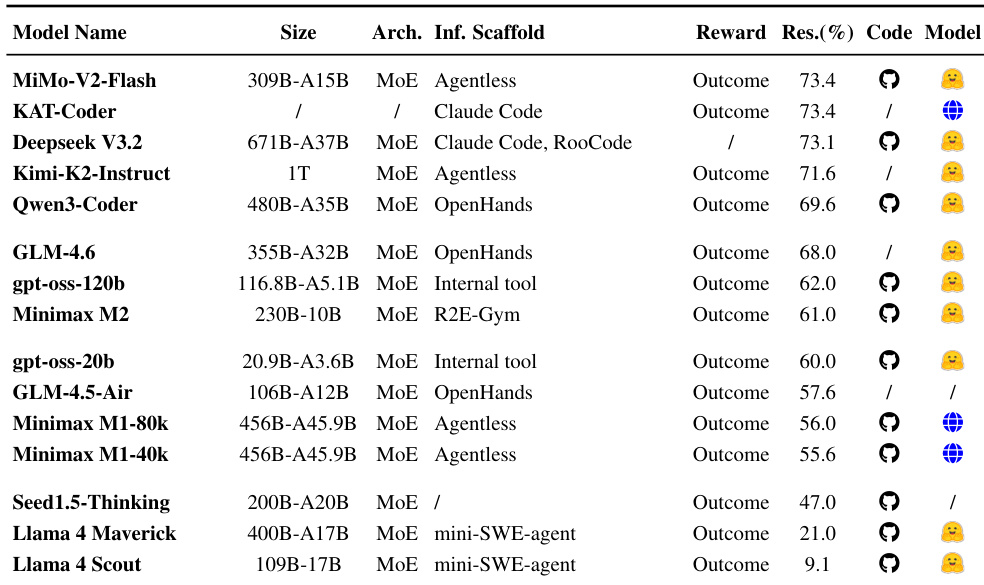
作者使用表格比较基于SFT的问题解决模型,按架构、推理支架与奖励类型分类。结果表明,使用结果导向奖励与专用支架的模型实现更高解决率,MiMo-V2-Flash与KAT-Coder以73.4%领先,而依赖通用支架或缺乏结构化奖励的模型表现显著更差。
作者使用多种基于SFT的模型评估问题解决性能,结果显示大型模型如SWE-rebench-openhands-Qwen3-235B-A22B实现最高准确率59.9%。数据表明模型规模与训练支架显著影响性能,OpenHands与MoE架构通常优于其他,而小型模型如SWE-Gym-Qwen-7B仅达约10.6%。