Command Palette
Search for a command to run...
为Gemini构建可投入生产的探测器
为Gemini构建可投入生产的探测器
János Kramár Joshua Engels Zheng Wang Bilal Chughtai Rohin Shah Neel Nanda Arthur Conmy
摘要
前沿语言模型的能力正在迅速提升,因此我们亟需更强的防御机制,以应对恶意用户滥用日益强大的系统所带来的风险。先前的研究表明,激活探测(activation probes)可能是一种有前景的滥用防护技术,但我们识别出一个关键的遗留挑战:现有探测器在面对重要的生产环境分布变化时,难以实现有效泛化。特别是,我们发现现有探测架构在从短上下文输入向长上下文输入的分布转移下表现不佳。为此,我们提出了几种新型探测架构,能够有效应对这一长上下文分布变化。我们在网络攻击(cyber-offensive)领域对这些探测器进行了评估,测试其在多种与生产环境相关的分布偏移下的鲁棒性,包括多轮对话、长上下文提示以及自适应红队测试(adaptive red teaming)。结果表明,尽管我们提出的新型架构能够有效处理上下文长度问题,但要实现广泛的泛化能力,仍需结合合理的架构选择与在多样化分布上的训练。此外,我们还发现,将探测器与提示式分类器(prompted classifiers)相结合,可在极低的计算成本下实现最优的检测准确率,这得益于探测器本身的计算高效性。这些研究发现已成功应用于谷歌前沿语言模型 Gemini 的面向用户实例中,指导了滥用防护探测器的实际部署。最后,我们初步发现,利用 AlphaEvolve 自动优化探测架构搜索与自适应红队测试,已取得积极成果,表明部分人工智能安全研究的自动化在当前已具备可行性。
一句话摘要
谷歌DeepMind的研究人员提出了一种新颖的激活探测器架构——特别是MultiMax和滚动均值注意力探测器——显著提升了对长上下文输入的泛化能力,这是前沿语言模型在生产环境中防范滥用的关键挑战。通过结合架构创新、在多样化分布上训练,并与提示分类器级联,该方法以极低的成本实现了接近大语言模型(LLM)的准确率,成功部署于面向用户的Gemini实例中。该工作进一步表明,通过AlphaEvolve进行自动化搜索可发现高性能探测器设计,揭示了自动化AI安全研究的早期可行性。
主要贡献
- 现有激活探测器在关键生产分布变化下无法有效泛化,尤其是在从短上下文过渡到长上下文输入时,限制了其在真实部署中作为滥用防范手段的有效性。
- 作者提出MultiMax探测器架构,并在长上下文数据上展示了其卓越性能;同时,通过AlphaEvolve实现的自动化架构搜索发现了一种优于基线的探测器变体,具有高度统计显著性。
- 一种级联分类器将探测器与大语言模型结合,仅在探测器不确定时调用语言模型,实现了比单独使用LLM更低的假阴性率,且推理成本不足其10%,从而在生产环境中实现了高效且稳健的滥用检测。
引言
像Gemini这样的前沿语言模型正面临日益增长的滥用风险,尤其是在网络攻击领域,恶意用户可通过对抗性提示利用模型能力。为应对这一问题,激活探测器——一种在内部隐藏状态上训练的轻量级模型——作为昂贵语言模型分类器的低成本替代方案,已逐渐成为实时输入监控的有效手段。然而,先前的探测器架构在关键生产分布变化下难以泛化,特别是面对长上下文输入时,受限于内存和计算资源,训练此类数据成本过高。作者指出,这种脆弱性是关键限制:在短上下文上训练的探测器在面对扩展或多轮交互时会失效,削弱了其在真实部署中的可靠性。其主要贡献在于系统性地研究了四种提升探测器鲁棒性的策略:引入一种提升长上下文性能的新MultiMax探测器架构,利用AlphaEvolve实现探测器架构的自动化搜索,构建一种仅在探测器不确定时才调用语言模型的级联分类器,以实现高准确率与低成本的平衡,以及证明在多个随机种子上训练可降低方差并提升泛化能力。这些进展使得探测器成功部署于生产环境的Gemini系统中,性能接近全量语言模型,同时仅使用极小的计算资源,尽管在应对自适应、演化的攻击方面仍存在挑战。
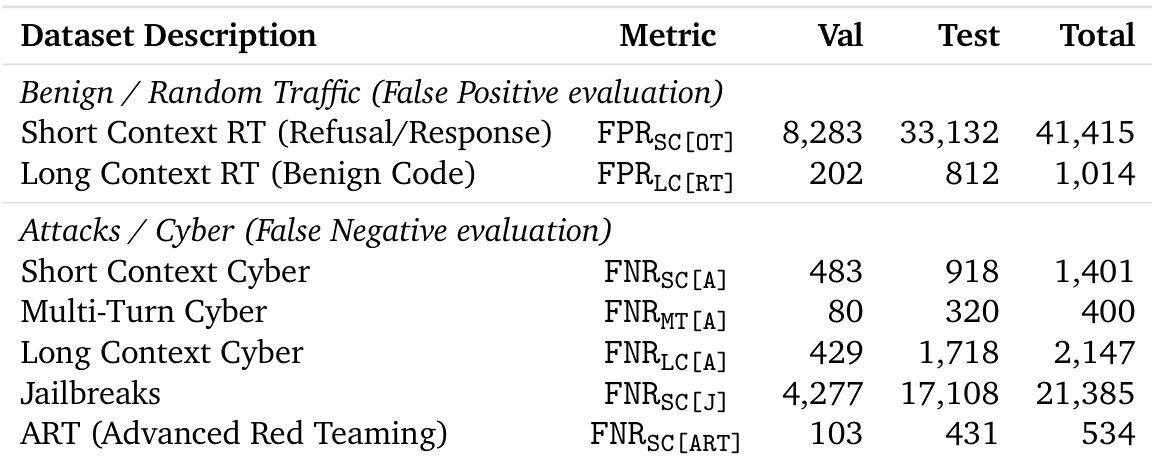
数据集

- 数据集包含多个聚焦于网络滥用的来源,划分为训练、验证和测试集,各集合间无提示重叠。
- 训练数据包含良性与恶意网络提示的混合,为降低计算负担,排除了长上下文示例。
- 验证集和测试集旨在体现与训练数据的分布差异,确保对泛化能力的稳健评估。
- 测试集包含长上下文数据,经过严格过滤以防止数据泄露:移除了1,711行与短上下文训练数据匹配的长上下文样本,保留436行干净样本用于评估。
- 作者采用加权误差指标确定最优阈值τ*,对误触发的假阳性赋予较高权重(50),其次为假阴性(5),再为硬负样本假阳性(2)。
- 此加权策略优先降低在良性非网络数据上的假阳性,如PII脱敏流量、能力评估数据和无关合成提示,反映了误触发的高代价。
- 最终测试损失为所有测试数据集上FPR与FNR的加权平均,作为方法比较的主要指标。
- 探测器训练所需的激活值使用TPU机器存储在磁盘上,支持单层探测器的快速迭代;评估则使用CPU工作节点,尤其适用于超出单节点内存的长上下文数据。
- 采用自定义数据加载流水线,结合轮询批处理分配及对填充和流水线的优化,实现了小批量、稳定且高效的长上下文探测器训练,提升了加速器利用率。
方法
作者采用模块化框架设计和评估基于部署语言模型中提取的隐藏状态对词元序列进行分类的探测器架构。整个流程始于从语言模型的固定中间层提取残差流激活,得到形状为(n,d)的词元级表示序列,其中n为序列长度,d为隐藏维度。这些激活作为探测器的输入,经过一系列变换与聚合,生成标量分类得分。
参见框架图 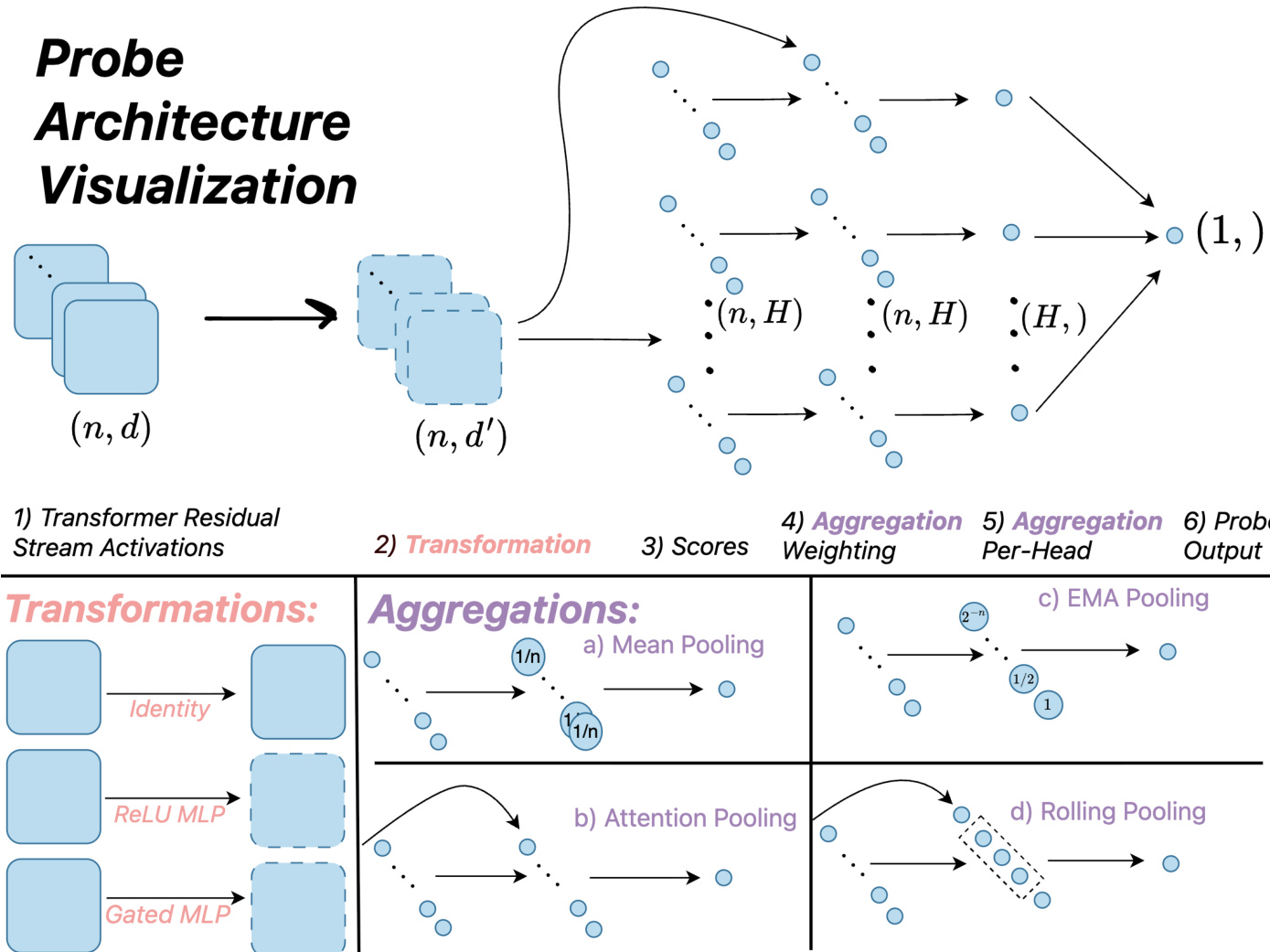 。该架构遵循六步流程:(1) Transformer残差流激活,(2) 每位置变换,(3) 得分计算,(4) 聚合加权,(5) 每头聚合,(6) 探测器输出。变换步骤对每个词元的激活应用函数,生成形状为(n,d′)的变换表示。该步骤包括线性探测器的恒等映射、均值池化MLP探测器的ReLU基MLP,以及更复杂架构的门控MLP。随后计算得分,通常为变换激活的线性投影。
。该架构遵循六步流程:(1) Transformer残差流激活,(2) 每位置变换,(3) 得分计算,(4) 聚合加权,(5) 每头聚合,(6) 探测器输出。变换步骤对每个词元的激活应用函数,生成形状为(n,d′)的变换表示。该步骤包括线性探测器的恒等映射、均值池化MLP探测器的ReLU基MLP,以及更复杂架构的门控MLP。随后计算得分,通常为变换激活的线性投影。
聚合是将词元级表示序列压缩为单一标量得分的核心机制。该框架支持多种聚合策略。例如,均值池化对序列中得分取平均,而指数移动平均(EMA)聚合通过递归更新维持得分的运行平均。基于注意力的聚合计算得分的加权平均,权重由学习到的查询向量与变换激活推导得出,使探测器能够聚焦于相关词元。作者还引入滚动池化策略,即在固定大小的滑动窗口内计算注意力,并将各窗口得分的最大值作为最终输出。
作者比较了多种探测器架构,包括线性探测器、EMA探测器、MLP探测器等基线方法,以及其新设计。线性探测器采用简单线性变换与均值池化。EMA探测器在推理时对得分应用指数移动平均以优化线性探测器。MLP探测器在池化前使用多层感知机变换激活。作者提出两种新架构:MultiMax探测器,用硬最大操作替代注意力探测器中的softmax加权,防止长上下文中的信号稀释;以及滚动均值注意力探测器的最大值版本,结合滑动窗口内的注意力与窗口级输出的最大值。这些架构旨在提升对长上下文的泛化能力并减少误触发。该框架还支持级联分类器,即先用快速探测器进行初步分类,仅在探测器不确定时调用更昂贵的语言模型,从而实现成本与准确率之间的权衡。
实验
- 使用AlphaEvolve发现新型探测器架构,其中两种表现最佳的变体——MultiMax和滚动均值注意力探测器——在对抗性查询检测任务中优于现有基线,包括线性探测器和注意力探测器。
- 在主评估数据集上,采用MultiMax聚合的滚动均值注意力探测器达到2.53%的测试误差,优于线性探测器均值(0.064测试损失),并超越所有LLM,经自助重采样验证具有统计显著性(表4)。
- 架构选择带来的性能提升远超种子选择:最佳架构实现0.025测试损失,而中位种子选择仅提升0.003;在辅助数据集上,最佳与最差架构间AUROC差距达0.109。
- AlphaEvolve使基线注意力探测器与最优性能之间的测试误差差距缩小约50%,且早期与最终发现的架构在多样化数据集上均达到高中位AUROC(0.975)。
- 在短上下文数据上训练的探测器在性能上达到或超过在长上下文数据上训练的模型(2.38% vs. 2.53%测试误差),表明架构改进可克服数据局限。
- 将最佳探测器与Gemini 2.5 Flash-Lite结合的级联分类器实现了更优的成本-准确率权衡,Flash-Lite因更低成本和相当准确率,在整个前沿范围内均优于Pro。
- 种子选择适度提升性能(平均测试损失降低0.008),但架构搜索的影响远为显著,表明从业者应优先关注架构设计而非大量种子调优。
作者使用表格详细说明其评估数据集的构成,明确列出各数据集在不同网络与良性流量类别下的测试样本与总样本数量。表格显示,各数据集规模差异显著,其中短上下文RT(拒绝/响应)数据集测试集最大,达33,132样本,而ART(高级红队)数据集最小,仅431个测试样本。
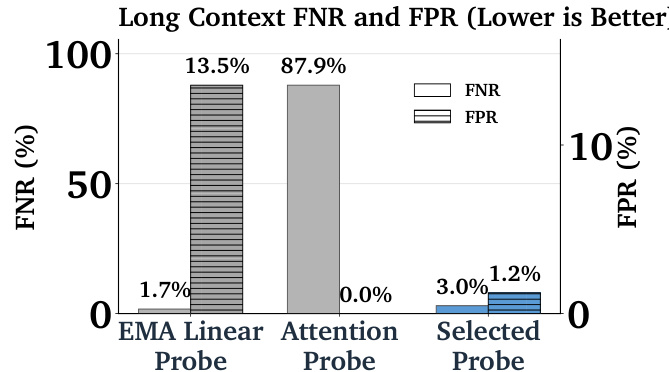
作者比较了不同探测器架构在长上下文泛化性能上的表现,结果显示EMA线性探测器的假阳性率较低(1.7%),但假阴性率较高(13.5%);注意力探测器假阳性率为0.0%,但假阴性率高达87.9%;而所选探测器实现了平衡表现,假阴性率为3.0%,假阳性率为1.2%。
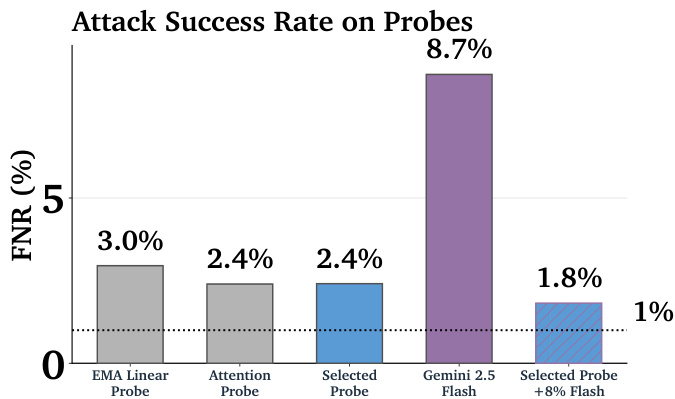
作者使用柱状图比较了各类探测器与语言模型在对抗攻击下的假阴性率(FNR)。结果显示,Gemini 2.5 Flash模型的攻击成功率最高,达8.7%,显著优于所有探测器。所选探测器实现1.8%的FNR,表明最佳探测器仍存在显著攻击漏洞,但远低于LLM的水平。
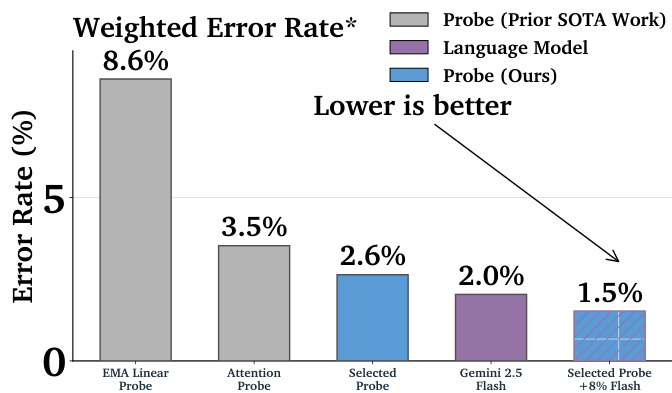
作者比较了不同探测器与语言模型分类器的加权误差率,结果显示所选探测器达到2.6%的误差率,低于注意力探测器的3.5%和EMA线性探测器的8.6%。最佳配置(所选探测器与Gemini 2.5 Flash结合)进一步将误差率降至1.5%,显著优于先前方法。
作者使用AlphaEvolve生成新型探测器架构,表现最佳的变体在多个数据集上显著优于现有线性探测器基线。结果显示,顶级架构(包括AlphaEvolve的MultiMax变体和滚动均值注意力探测器的最大值版本)的测试误差低于所有先前方法,尽管无单一方法在所有分布偏移下全面占优。