Command Palette
Search for a command to run...
ACoT-VLA:面向视觉-语言-动作模型的动作思维链
ACoT-VLA:面向视觉-语言-动作模型的动作思维链
Linqing Zhong Yi Liu Yifei Wei Ziyu Xiong Maoqing Yao Si Liu Guanghui Ren
摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型已成为应对多样化操作任务的关键通用机器人策略,传统方法通常依赖于通过视觉-语言模型(VLM)嵌入直接将多模态输入映射为动作。近期研究引入了显式的中间推理机制,例如子任务预测(语言层面)或目标图像生成(视觉层面),以指导动作生成。然而,这些中间推理过程往往具有间接性,且在传递精确动作执行所需完整、细粒度信息方面存在固有局限。为此,我们提出一种更为有效的推理范式:在动作空间中进行直接的、逐步的思辨。为此,我们提出动作链式思维(Action Chain-of-Thought, ACoT),即把推理过程本身建模为一系列结构化的粗粒度动作意图序列,用以引导最终策略的生成。本文提出一种新型架构——ACoT-VLA,以实现ACoT范式。具体而言,我们设计了两个互补组件:显式动作推理器(Explicit Action Reasoner, EAR)与隐式动作推理器(Implicit Action Reasoner, IAR)。EAR负责生成显式的粗粒度参考轨迹,作为动作层级的推理步骤;IAR则从多模态输入的内部表征中提取潜在的动作先验,与EAR协同构建完整的ACoT,从而为下游动作头提供条件,实现具身化(grounded)的策略学习。在真实世界与仿真环境中的大量实验表明,所提方法显著优于现有基准,分别在LIBERO、LIBERO-Plus和VLABench三个基准测试中取得了98.5%、84.1%和47.4%的成功率,充分验证了ACoT-VLA在复杂操作任务中的卓越性能与泛化能力。
一句话总结
北京航空航天大学与AgiBot的作者提出ACoT-VLA,一种新颖的VLA架构,通过引入动作链式思维(Action Chain-of-Thought)推理,使显式的粗粒度动作意图与隐式的潜在动作先验共同指导精确动作生成,从而在LIBERO、LIBERO-Plus和VLABench基准上超越了先前方法。
主要贡献
-
本文通过引入动作链式思维(ACoT)这一新范式,解决了视觉-语言-动作模型中的语义-运动学鸿沟问题,将推理形式化为动作空间中的一系列显式粗粒度动作意图,相比以往基于语言或视觉的中间推理方式,实现了更扎实、更精确的机器人策略学习。
-
为实现ACoT,作者提出ACoT-VLA,整合了两个互补组件:显式动作推理器(EAR),从多模态输入生成粗略参考轨迹;隐式动作推理器(IAR),通过交叉注意力推断潜在动作先验。二者共同为策略执行提供丰富的动作空间引导。
-
在真实世界与仿真环境中的大量实验表明该方法的有效性,在LIBERO、LIBERO-Plus和VLABench基准上分别取得了98.5%、84.1%和47.4%的最先进成功率。
引言
作者针对视觉-语言-动作(VLA)模型中存在的语义-运动学鸿沟问题展开研究,即来自视觉和语言的高层抽象输入难以提供机器人控制所需的精确低层动作指导。以往方法依赖于语言或视觉空间中的推理——或通过语言链生成子任务,或通过世界模型模拟未来状态——这两种方式均对动作执行提供间接且次优的引导,限制了在真实机器人任务中的泛化能力与物理接地性。为克服这一局限,作者提出动作链式思维(ACoT),一种将推理重新定义为动作空间中一系列显式、运动学接地的动作意图的新范式。他们提出ACoT-VLA,一个统一框架,包含两个互补模块:显式动作推理器(EAR),从多模态输入合成粗略运动轨迹;隐式动作推理器(IAR),通过下采样输入与可学习查询之间的交叉注意力推断潜在动作先验。该双机制实现直接、丰富的动作空间引导,显著提升策略性能。在仿真与真实世界基准上的实验表明,该方法取得最先进结果,分别在LIBERO、LIBERO-Plus和VLABench上达到98.5%、84.1%和47.4%的成功率。
数据集

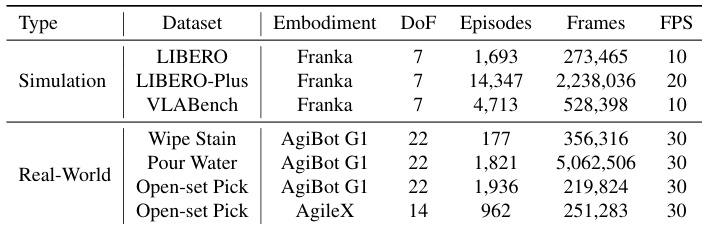
- 数据集包含三个公开的仿真基准:LIBERO、LIBERO-Plus和VLABench,以及三个任务的自采真实世界数据:擦除污渍、倒水、开放集抓取。
- LIBERO包含1,693个episode和273,465帧,采样频率为10 Hz,具有统一的轨迹长度和平滑运动模式,被广泛用作标准基准。
- LIBERO-Plus包含14,347个episode和2,238,036帧,采样频率为20 Hz,设计时引入了运动幅度和相机-机器人视角的扰动性变化,以挑战策略在结构化分布偏移下的泛化能力。
- VLABench的训练集包含4,713个episode和528,398帧,采样频率为10 Hz,由于任务动态复杂,要求具备高级视觉与物理推理能力。
- 真实世界数据包括:擦除污渍任务177个episode(356,316帧),特征为密集工具-表面接触与精细力控;倒水任务1,821个episode(5,062,506帧),具有长时程、多阶段执行特征;开放集抓取任务包含AgiBot G1的1,936个episode(219,824帧)和AgileX的962个episode(251,283帧),均具有多样化的桌面布局和自然语言指令。
- 作者在训练中混合使用这些数据集,训练划分基于完整episode集合,混合比例根据任务复杂度与规模进行调整。
- 数据经过一致的帧采样与时间对齐处理;真实任务的episode经过筛选,确保任务完成与有效示范。
- 未进行显式裁剪,但训练期间视觉输入被标准化为固定分辨率。
- 构建了任务类型、平台、指令模态等元数据,以支持多任务学习与评估。
方法
作者提出ACoT-VLA,一种新颖架构,通过将动作链式思维(ACoT)范式形式化为动作空间中的一系列结构化粗粒度动作意图,实现推理过程。该框架基于共享的预训练视觉-语言模型(VLM)主干,处理自然语言指令与当前视觉观测,生成上下文键值缓存。该缓存作为两个互补动作推理器——显式动作推理器(EAR)与隐式动作推理器(IAR)——的基础,分别提供不同形式的动作空间引导。整体架构旨在协同整合这些显式与隐式线索,以条件化最终动作预测。

如图所示,该框架由三个主要组件构成,均作用于共享VLM主干提取的特征。第一个组件为显式动作推理器(EAR),是一个轻量级Transformer模块,用于合成粗略参考轨迹,提供显式动作空间引导。第二个组件为隐式动作推理器(IAR),采用可学习查询的交叉注意力机制,从VLM内部表示中提取潜在动作先验。第三个组件为动作引导预测(AGP)头,通过交叉注意力协同整合显式与隐式引导,条件化最终去噪过程,生成可执行的动作序列。
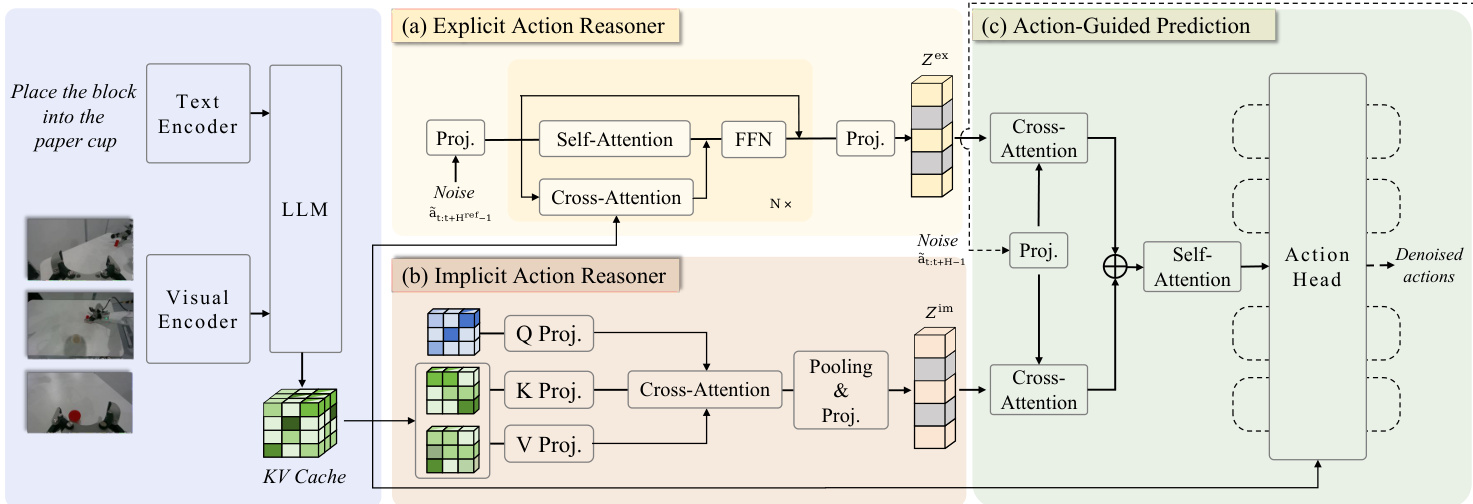
显式动作推理器(EAR)通过输入一个噪声动作序列,生成去噪后的参考动作序列。该过程始于VLM将指令与观测编码为上下文键值缓存。随后,EAR(记为πθref)通过一系列Transformer层处理噪声动作序列。在每一层中,自注意力机制捕捉动作序列内的时序依赖,而与VLM键值缓存的交叉注意力注入多模态上下文先验。中间表示通过前馈网络以残差并行方式更新。通过流匹配训练,EAR学习动作轨迹的分布,生成去噪动作序列,并将其编码为动作嵌入Zex,作为显式动作空间引导。
隐式动作推理器(IAR)直接作用于VLM的键值缓存,以提取潜在动作先验。对于每个VLM层,初始化一个可学习查询矩阵,并使用可学习线性投影器将对应的键值对下采样至低维空间。随后应用交叉注意力,从各层下采样后的键值对中提取与动作相关的信息。所得特征通过平均池化整合,并经MLP投影器转换,生成紧凑表示ziim,捕捉隐式动作语义。通过聚合所有层的表示,IAR获得隐式动作相关特征Zim,与显式运动先验形成互补。
动作引导预测(AGP)策略将显式与隐式动作引导整合至策略学习中。给定一个噪声动作片段,首先编码为噪声动作嵌入,作为动作查询。该查询通过双重交叉注意力操作与Zex和Zim交互,以检索互补先验。所关注的表示Sex与Sim随后被拼接,并通过自注意力融合模块处理,整合为统一表示hˉ。该聚合表示最终输入动作头,预测去噪动作序列。整个框架在标准流匹配均方误差目标下进行优化,EAR与动作头分别设有独立损失。
实验
- 在LIBERO、LIBERO-Plus和VLABench仿真基准上进行评估:达到最先进性能,在LIBERO上相比π₀.₅平均成功率提升1.6个百分点,并在扰动条件下取得显著增益(如LIBERO-Plus中机器人初始状态偏移下提升+16.3%),表明更强的鲁棒性与泛化能力。
- 在VLABench上,意图得分(IS)与进展得分(PS)均取得最佳结果,未见纹理轨迹上分别提升+12.6% IS与+7.2% PS,凸显对分布偏移的强抵抗能力。
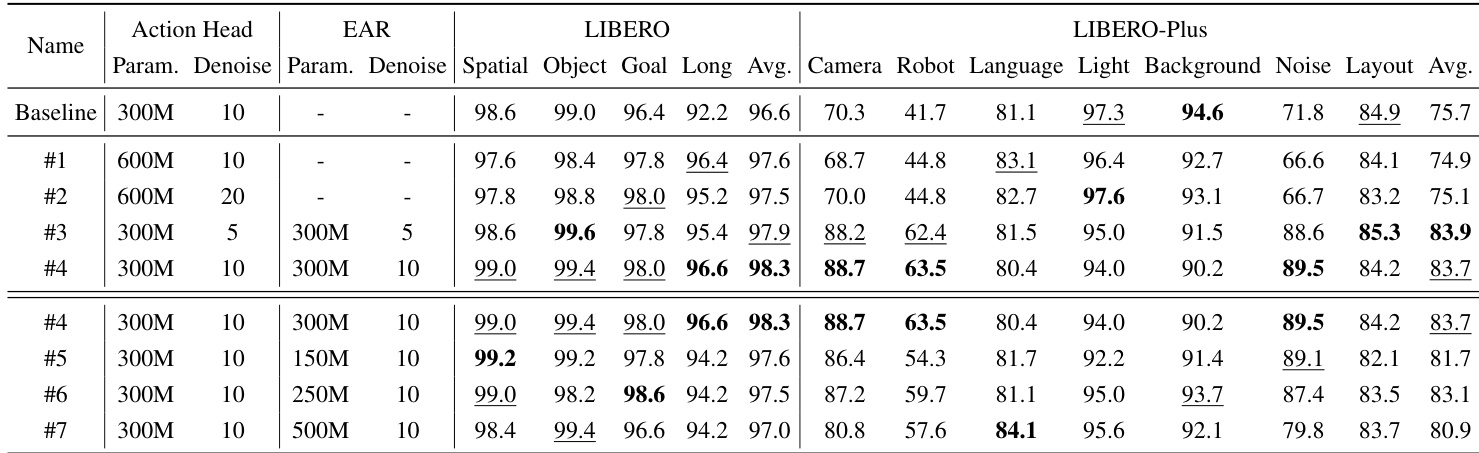
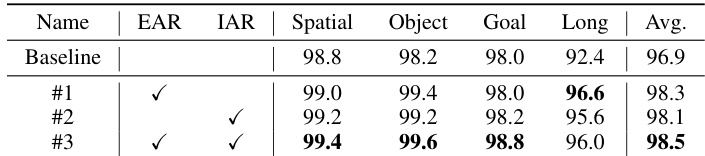
- 在LIBERO与LIBERO-Plus上的消融研究证实,显式动作推理器(EAR)与隐式动作推理器(IAR)模块均贡献显著,EAR + IAR达到98.5%成功率,表明显式动作引导与来自VLM键值缓存的隐式动作线索具有互补优势。
- 在AgiBot G1与AgileX机器人上的真实世界部署,三个任务(擦除污渍、倒水、开放集抓取)综合成功率达66.7%,优于π₀.₅(61.0%)与π₀(33.8%),验证了方法的有效性与跨平台适应能力,尤其在真实感知与执行噪声下表现优异。
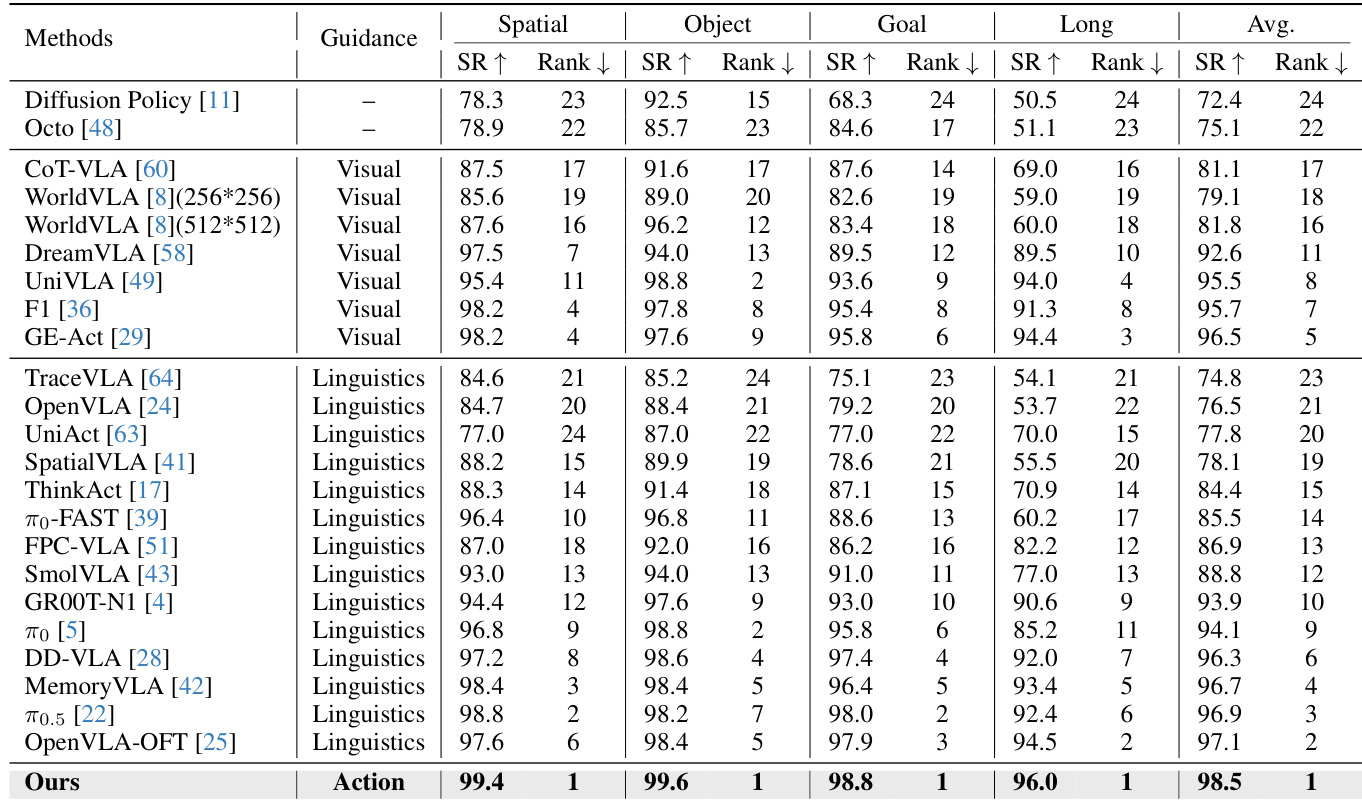
作者使用LIBERO基准评估其方法,与多种最先进方法在四个任务套件上进行对比。结果表明,该方法取得最高平均成功率98.5%,全面超越所有基线,尤其在长时程操作任务中达到96.0%成功率,充分证明动作空间引导的有效性。
结果表明,所提方法在VLABench基准的所有评估轨迹上均优于基线方法。作者在意图得分与进展得分上分别取得63.5%与47.4%的最高平均成功率,显著提升在分布内与分布外设置下的性能。

作者在仿真与真实世界基准上采用统一训练设置,根据环境差异调整动作时域与控制类型。结果表明,该方法在真实任务中平均成功率高于基线方法,验证了在真实感知条件下有效性及在不同机器人本体间的适应能力。
作者使用LIBERO基准评估所提模块的影响,结果表明,引入显式动作推理器(EAR)与隐式动作推理器(IAR)在所有任务套件上均提升性能。结果表明,结合两个模块后取得最高平均成功率98.5%,在长时程任务中提升显著,表明显式与隐式动作引导对鲁棒策略学习具有互补作用。
作者使用LIBERO与LIBERO-Plus基准评估其方法,结果表明,该方法在所有任务套件与扰动条件下均持续优于基线。所提方法在两个基准上均取得最高成功率,尤其在长时程任务及相机视角偏移、传感器噪声等挑战性扰动下表现优异,充分证明动作空间引导的有效性。