Command Palette
Search for a command to run...
FlashLabs Chroma 1.0:具备个性化语音克隆能力的实时端到端语音对话模型
FlashLabs Chroma 1.0:具备个性化语音克隆能力的实时端到端语音对话模型
Tanyu Chen Tairan Chen Kai Shen Zhenghua Bao Zhihui Zhang Man Yuan Yi Shi
摘要
近期的端到端语音对话系统利用语音分词器和神经音频编码器,使大语言模型(LLM)能够直接处理离散的语音表示。然而,这类模型通常在说话人身份保持方面表现有限,限制了个性化语音交互的实现。在本工作中,我们提出 Chroma 1.0,这是首个开源、实时、端到端的语音对话模型,能够在实现低延迟交互的同时,完成高质量的个性化语音克隆。Chroma 通过采用交错式文本-音频令牌调度策略(1:2),支持流式生成,实现了亚秒级的端到端延迟,同时在多轮对话中保持了高质量的个性化语音合成。实验结果表明,Chroma 在说话人相似度上相较人类基线提升了 10.96%,实时因子(RTF)仅为 0.43,同时保持了强大的推理与对话能力。相关代码与模型已公开发布于 https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma 和 https://huggingface.co/FlashLabs/Chroma-4B。
一句话总结
FlashLabs 的研究人员推出了 Chroma 1.0,这是首个开源的实时语音对话模型,通过 1:2 的文本-音频标记调度机制保留说话人身份,实现亚秒级延迟和高保真语音克隆,同时在说话人相似度上超越人类基线,并保持强大的推理能力。
主要贡献
- Chroma 1.0 引入了首个开源的实时端到端语音对话系统,可在多轮对话中保持说话人身份,解决了先前模型为降低延迟而牺牲语音保真度或反之的瓶颈。
- 它采用新颖的 1:2 交错文本-音频标记调度机制,实现亚秒级延迟和流式生成,同时以短参考音频片段为条件进行语音合成,在说话人相似度上相较人类基线提升 10.96%。
- 尽管参数规模仅为 4B,Chroma 仍保持强大的推理与对话能力,经基准测试验证其实时因子(RTF)为 0.43,并已公开发布以支持可复现性与进一步研究。
引言
作者利用语音标记化与神经编解码器的最新进展,构建了 Chroma 1.0 —— 一款开源、实时、端到端的语音对话系统,可在多轮对话中保留个性化语音身份。以往的端到端模型要么为低延迟牺牲说话人保真度,要么缺乏流式能力;而级联式 ASR-LLM-TTS 流程则丢失副语言线索并累积延迟。Chroma 通过引入交错的 1:2 文本-音频标记调度机制,仅需数秒参考音频即可实现亚秒级延迟与高保真语音克隆,在说话人相似度上相较人类基线提升 10.96%,且不牺牲推理或对话质量。
数据集

- 由于公开数据集无法满足模型对语义理解和推理能力的需求,作者使用自定义数据生成流程创建高质量语音对话数据。
- 该流程包含两个阶段:(1) 文本生成 —— 用户问题由类似 Reasoner 的 LLM 处理以生成文本响应;(2) 语音合成 —— 使用 TTS 系统将响应转换为语音,匹配参考音频的音色。
- 合成语音作为 Backbone 和 Decoder 模块的训练目标,使其学习语音克隆与声学建模。
- 未使用任何外部数据集;所有训练数据均通过此 LLM-TTS 协作合成生成。
- 未提及裁剪、元数据构建或额外过滤规则 —— 重点在于针对模型架构定制的端到端合成生成。
方法
Chroma 1.0 系统采用端到端架构,旨在实现高质量、实时语音对话,通过紧密耦合框架整合语音感知与语言理解。如下图所示,系统包含两个主要子系统:Chroma Reasoner 与语音合成流水线。Reasoner 负责多模态输入理解与文本响应生成,合成流水线则由 Chroma Backbone、Chroma Decoder 和 Chroma Codec Decoder 组成,分别负责声学建模、码本解码与波形重建。

Chroma Reasoner 基于 Thinker 模块构建,使用 Qwen2-Audio 编码流水线处理文本与音频输入,生成高层语义表征。它采用跨模态注意力机制融合文本与音频特征,并通过时间对齐的多模态旋转位置嵌入(TM-RoPE)统一为隐藏状态序列。该融合使模型能结合语音的韵律与节奏线索与文本语义,增强对话理解与上下文建模,以支持后续合成。
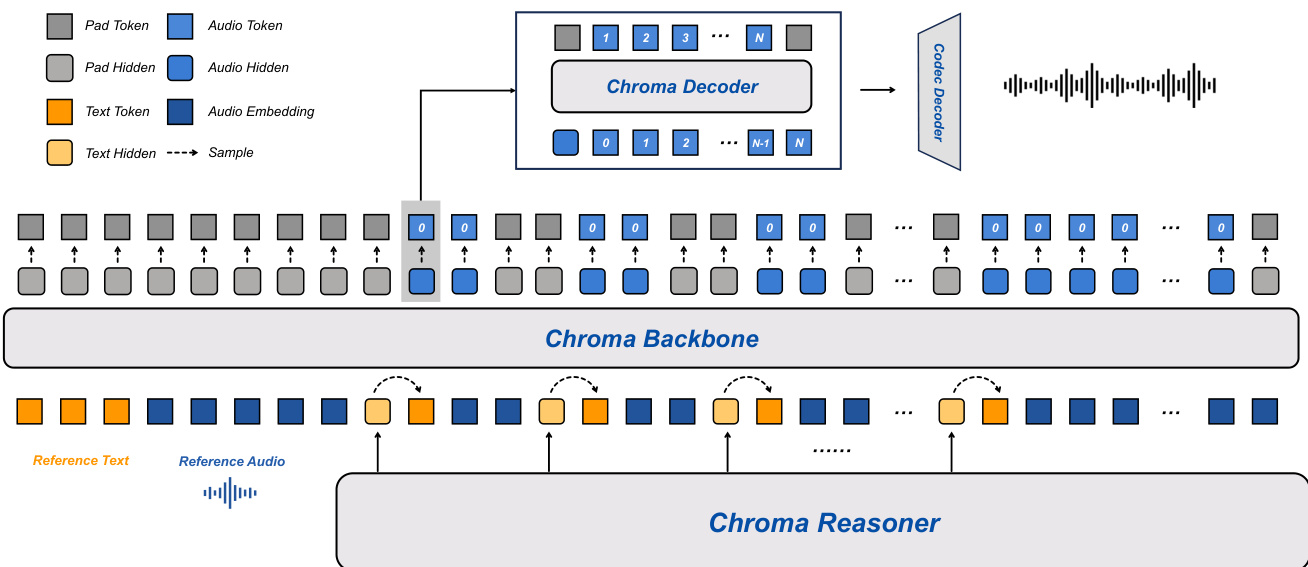
Chroma Backbone 是 LLaMA 架构的 1B 参数变体,生成与给定参考音频音色匹配的语音。它使用 CSM-1B 将参考音频及其对应文本编码为嵌入提示,并前置至输入序列,显式地将模型条件化于目标说话人的声学特征。为确保音频输出与 Reasoner 的文本模态严格对齐并保持低参数量,采用共享标记嵌入策略:Reasoner 的标记嵌入与隐藏状态作为统一文本上下文输入 Backbone。为支持高效流式生成,Backbone 以固定 1:2 比例交错文本标记与音频码标记 c0,使音频序列的自回归生成与 Reasoner 的增量文本生成并行,从而降低首标记延迟(TTFT)。
Chroma Decoder 是一个约 100M 参数的轻量模块,负责生成剩余声学码(ct1,…,ctN−1),而非由 Backbone 直接生成全部码本。该模块仅基于当前时间步 Backbone 输出进行帧同步推理,显著降低计算开销。在每个时间步 t,Chroma Decoder 接收 Backbone 生成的隐藏状态特征 ht 与初始音频码本 ct0,并使用层级特定投影头自回归生成每帧内剩余的 RVQ 码本 cti(i=1,…,N−1),条件依赖于已生成层级。此解耦设计降低推理延迟,并使 Chroma Decoder 能丰富韵律与发音细节等细粒度声学属性。
Chroma Codec Decoder 作为最终声学重建模块,将离散码本序列映射为连续、高保真语音波形。在每个时间步,它将 Backbone 生成的粗码本(c0)与 Chroma Decoder 生成的精细声学码本(c1,…,cN−1)拼接,形成完整的离散声学表征。该模块架构遵循 Mimi 声码器的解码器设计,采用因果卷积神经网络(Causal CNN),确保波形重建过程中的严格时间因果性以支持流式生成。为满足实时交互需求,系统使用 8 个码本(N=8),显著减少 Chroma Decoder 所需的自回归精炼步骤,提升推理效率。
训练策略优化 Backbone 与 Decoder,同时冻结 Reasoner 作为特征提取器。对于每组音频-文本对,Reasoner 提供固定文本嵌入与多模态隐藏状态,作为语义与韵律条件。Backbone 训练目标为自回归预测第一层粗声学码(c0),仅关注声学码前缀与对应 Reasoner 表征,以确保因果对齐。Decoder 通过预测剩余残差向量量化(RVQ)层级(c1:N−1)精炼粗声学表征,条件依赖于 Backbone 的粗码与隐藏状态,采用帧内自回归过程。该分解设计使 Decoder 能逐步提升声学保真度,同时保持与 Backbone 建立的粗轨迹一致。
实验
- 在 CommonVoice 上评估通用语音质量,在 URO-Bench 上评估推理能力;使用主观 CMOS 与客观 SIM/TTFT/RTF 指标。
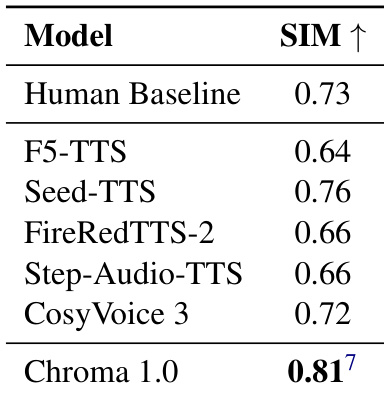
- 在零样本语音克隆中,说话人相似度(SIM)相较人类基线提升 10.96%,超越所有 SOTA 模型。
- 主观测试对比 ElevenLabs:ElevenLabs 在自然度上领先(NCMOS:57.2% vs 24.4%),但 Chroma 在说话人保真度上接近(SCMOS:40.6% vs 42.4%),表明其更强的副语言特征保留能力。
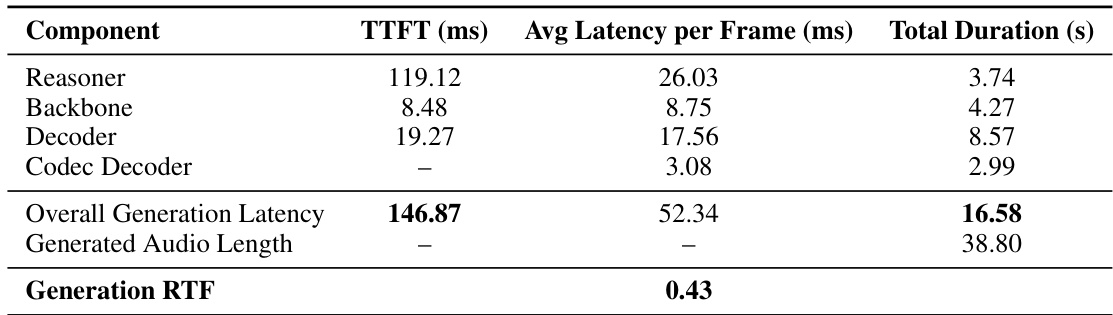
- 延迟:TTFT 为 146.87ms,RTF 为 0.43(比实时快 2.3 倍),支持响应式、流式交互。
- 在 URO-Bench 推理任务中总体排名第二(如 Storal 上 71.14%),尽管仅使用 4B 参数;在口语对话指标中领先(MLC 60.26%,CommonVoice 62.07%),且是唯一具备语音克隆能力的模型。
作者使用表格分析 Chroma 系统在语音生成过程中的延迟分解。结果显示,系统整体 TTFT 为 146.87ms,其中 Reasoner 组件贡献最大,为 119.12ms。系统生成音频的 RTF 为 0.43,表明其生成速度显著快于实时播放。
结果显示,ElevenLabs 在自然度上优于 Chroma,NCMOS 偏好率达 57.2%,而 Chroma 仅为 24.4%。在说话人相似度方面,Chroma 与 ElevenLabs 几乎持平,Chroma 获得 40.6% 的偏好,ElevenLabs 为 42.4%,表明尽管系统设计不同,两者语音克隆性能相当。

作者使用说话人相似度(SIM)指标评估语音克隆性能,数值越高表示说话人身份保留越好。结果显示,Chroma 1.0 的 SIM 得分为 0.81,超越所有对比模型,且比人类基线 0.73 提升 10.96%,证明其在捕捉细粒度副语言特征以实现高保真语音克隆方面的卓越能力。
作者通过在 URO-Bench 数据集上与其他端到端语音对话模型对比,评估 Chroma 的对话能力,衡量其在理解、推理与口语对话方面的表现。尽管为语音克隆优化,Chroma 在所有维度均取得竞争性结果,在推理与理解任务中排名第二,在口语对话中排名第一,同时保持显著更小的 4B 参数模型规模。

作者使用比较平均意见分(CMOS)评估合成语音的自然度,将 ElevenLabs 输出与参考音频对比。结果显示,评估者压倒性偏好 ElevenLabs 生成的音频(92.0% 偏好),而参考录音仅获 8.0% 偏好,表明评估者明显更倾向感知上更自然的合成语音。
