Command Palette
Search for a command to run...
CoDance:一种用于鲁棒多主体动画的解绑-重绑范式
CoDance:一种用于鲁棒多主体动画的解绑-重绑范式
Shuai Tan Biao Gong Ke Ma Yutong Feng Qiyuan Zhang Yan Wang Yujun Shen Hengshuang Zhao
摘要
角色图像动画在多个领域正变得日益重要,这主要源于对强大且灵活的多主体渲染技术的迫切需求。尽管现有方法在单人动画方面表现优异,但在处理任意数量的主体、多样化的角色类型以及参考图像与驱动姿态之间的空间错位问题时仍面临挑战。我们认为,这些局限性源于过于僵化的空间绑定机制,该机制强制要求姿态与参考图像之间进行严格的像素级对齐,同时模型难以一致地将动作重新绑定到目标主体上。为解决上述问题,我们提出 CoDance——一种新颖的“解绑-重绑”(Unbind-Rebind)框架,该框架能够基于单一且可能未对齐的姿态序列,实现任意数量、类型和空间布局的角色动画。具体而言,解绑(Unbind)模块引入了一种新型的姿态偏移编码器,通过在姿态及其潜在特征上施加随机扰动,打破姿态与参考图像之间的刚性空间绑定,从而促使模型学习一种与位置无关的动作表征。为确保精确控制与主体关联,我们进一步设计了重绑(Rebind)模块,利用文本提示提供的语义引导以及主体掩码提供的空间引导,将学习到的动作精准地分配至目标角色。此外,为支持全面的评估,我们构建了一个全新的多主体基准测试集——CoDanceBench。在 CoDanceBench 及现有数据集上的大量实验表明,CoDance 达到了当前最优(SOTA)性能,在不同角色类型和空间布局下均展现出卓越的泛化能力。相关代码与模型权重将开源发布。
一句话总结
香港大学、蚂蚁集团、华中科技大学、清华大学以及北卡罗来纳大学教堂山分校的研究人员提出 CoDance,一种新颖的解绑-重绑框架,通过在训练中引入随机姿态扰动以学习与位置无关的动作表征,并利用文本和掩码引导进行动作重绑定,从而仅从单一错位姿态序列中实现可控制姿态的多主体动画,在不同主体数量和空间配置下均达到最先进性能。
主要贡献
- 现有角色动画方法在多主体场景中表现不佳,因其参考图像与驱动姿态之间存在刚性空间绑定,导致在处理任意主体数量、类型或空间配置时出现错位或动作纠缠。
- CoDance 提出解绑-重绑框架:解绑模块通过一种新型姿态偏移编码器引入随机姿态与特征扰动,学习与位置无关的动作表征;重绑模块则利用文本提示和主体掩码实现对目标角色的精确、可控动画。
- 在新构建的 CoDanceBench 及现有数据集上进行的广泛评估表明,该方法性能达到最先进水平,对多样化主体、空间布局及错位输入均具有强泛化能力,定量指标与感知质量均得到验证。
引言
角色图像动画在虚拟演出、广告和教育内容等应用中日益重要,其中常需对多种类型和空间布局的多个主体进行动画处理。以往方法虽在单人动画中表现良好,但在多主体场景中因姿态与参考图像之间存在刚性空间绑定而失效,该绑定要求精确对齐,限制了其在超过两人以上的场景中的可扩展性。这导致动作纠缠、对非人类角色泛化能力差,且对错位敏感。本文提出 CoDance,一种新颖的解绑-重绑框架,通过在训练中对姿态骨架及其潜在特征施加随机扰动,将动作与外观解耦,使模型学习与位置无关的动作语义。为恢复精确控制,重绑模块利用文本提示提供语义引导,通过主体掩码实现空间定位,从而即使在姿态错位情况下也能准确生成任意数量和配置的主体动画。该方法在新基准 CoDanceBench 上得到验证,展现出最先进性能及在多样化布局与角色类型间的强泛化能力。
数据集

- 数据集包含公开的 TikTok 和 Fashion 数据集,并额外增加了约 1,200 个自采集的 TikTok 风格视频。
- 重绑阶段的训练通过 10,000 个文本到视频样本增强,以强化语义关联;同时使用 20 个多人主体视频以指导空间绑定。
- 评估涵盖单人与多人场景:
- 单人:采用 TikTok 中的 10 个视频和 Fashion 中的 100 个视频,遵循先前工作 [13, 14, 75]。
- 多人:使用 Follow-Your-Pose-V2 基准和新构建的 CoDanceBench 基准,后者包含 20 个多人舞蹈视频。
- 为确保公平比较,定量结果基于仅在独舞视频上训练的模型报告,排除 CoDanceBench 中的多人数据。
- 训练过程中使用特定比例的混合数据,但具体比例未详细说明。
- 未描述显式裁剪策略,但视频处理过程确保与姿态和动作输入对齐。
- 元数据构建涉及将视频内容与姿态序列及文本描述对齐,尤其针对文本到视频样本和多人协调任务。
- 评估指标包括帧级指标(PSNR、SSIM、L1、LPIPS)用于衡量感知保真度与失真,以及视频级指标(FID、FID-VID、FVD)用于评估分布真实性。
方法
研究人员采用基于扩散模型的框架进行多角色动画,以扩散 Transformer(DiT)作为骨干网络。整体流程如框架图所示,输入包括参考图像 Ir、驱动姿态序列 I1:Fp、文本提示 T 和主体掩码 M。变分自编码器(VAE)编码器从参考图像中提取潜在特征 fer。该潜在表示与主体掩码共同构成生成过程的初始输入。驱动姿态序列由姿态偏移编码器处理,该编码器由堆叠的 3D 卷积层组成,以捕捉时空特征。提取的姿态特征随后与噪声潜在输入的补丁化标记拼接,形成 DiT 骨干网络的条件输入。
该方法的核心创新在于解绑-重绑范式,旨在克服刚性空间对齐的局限性。解绑模块以姿态偏移编码器实现,分别在输入层和特征层操作,以解耦姿态与其原始空间上下文。在输入层,姿态解绑模块通过随机平移和缩放驱动姿态的骨架来随机破坏对齐。在特征层,特征解绑模块通过施加随机平移并复制对应姿态的特征区域进一步增强姿态特征,迫使模型学习更抽象、语义化的动作理解。该过程确保模型不依赖于参考图像与目标姿态之间的固定空间对应关系。
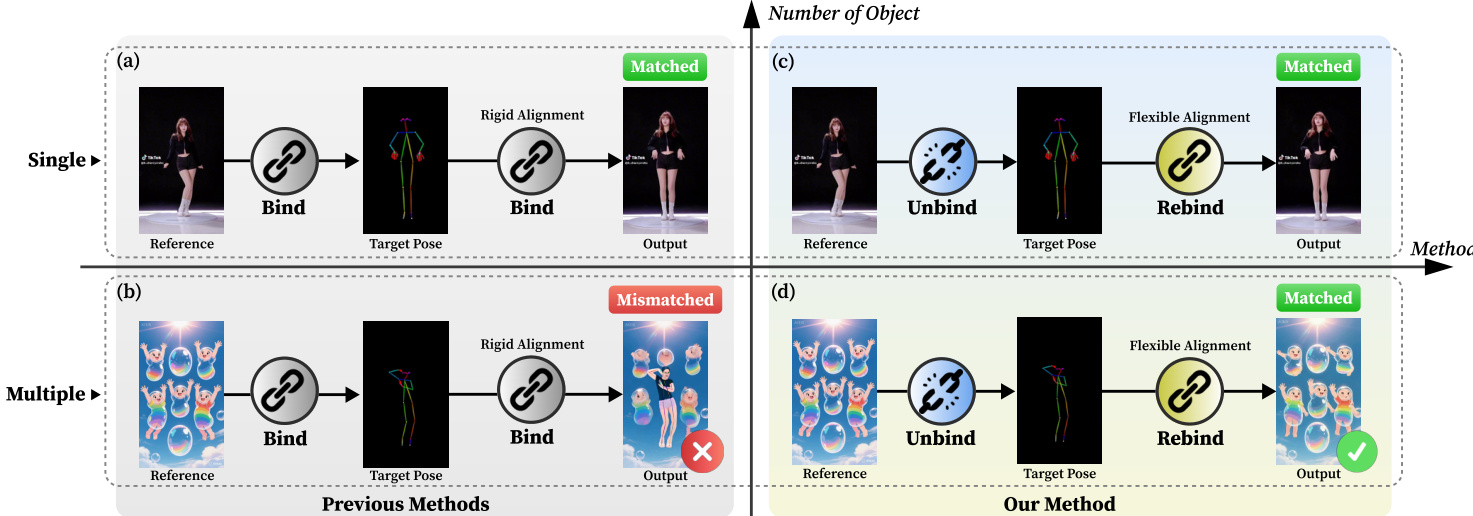
解绑操作完成后,重绑模块通过两种互补机制重新建立学习到的动作与参考图像中目标主体之间的正确对应关系。从语义角度看,文本提示 T 经由 umT5 文本编码器处理,其输出特征通过交叉注意力层注入 DiT 块,提供关于需动画化主体的身份与数量的明确指导。为解决前景-背景模糊问题并确保精确的空间控制,采用空间重绑机制。从参考图像中使用预训练分割模型(如 SAM)提取的主体掩码 M 输入掩码编码器,生成的掩码特征与噪声潜在向量逐元素相加,将动画限制在指定区域。为增强模型的语义理解能力并防止对动画特定提示的过拟合,训练过程在动画数据与多样化文本到视频(TI2V)数据集之间交替进行。DiT 骨干网络从预训练的 T2V 模型初始化,并通过低秩适应(LoRA)层进行微调。最后,去噪后的潜在表示传递至 VAE 解码器,重建输出视频 I1:Fg。需要注意的是,解绑模块与混合数据训练策略仅在训练阶段应用。
实验
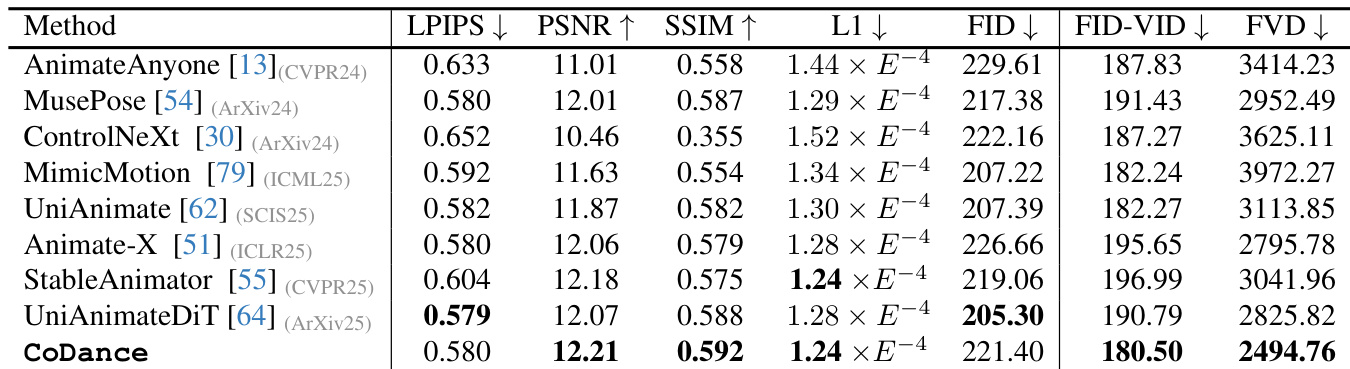
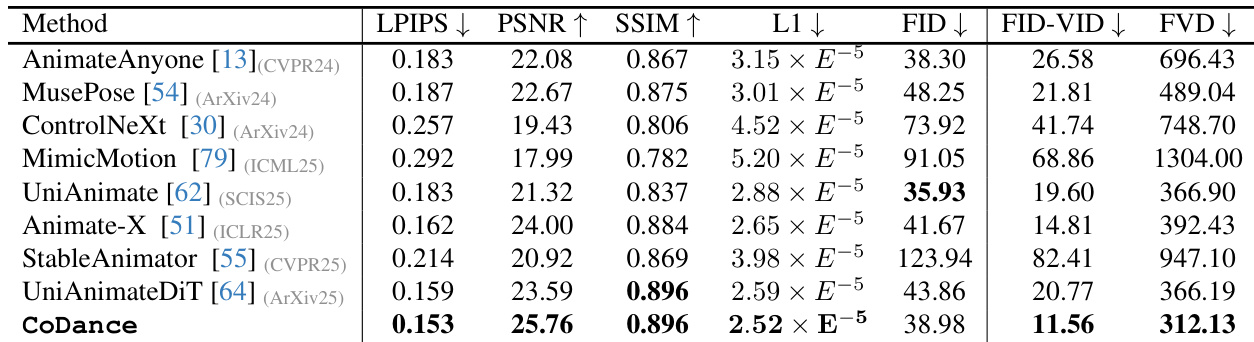
- 在 Follow-Your-Pose-V2 和所提基准上与 SOTA 方法(AnimateAnyone、MusePose、ControlNeXt、MimicMotion、UniAnimate、Animate-X、StableAnimator、UniAnimate-DiT)对比,本方法在感知相似性(LPIPS)、身份一致性(PSNR/SSIM)和动作保真度(FID-FVD、FVD)方面均优于所有方法,尽管仅在单人数据上训练,仍展现出多主体动画的显著优势。
- 在具有挑战性的单人驱动姿态到多人参考图像场景中,本方法保持身份保真与动作连贯性,而基线方法因刚性绑定及无法处理基数不匹配而失败。
- 定性结果(图 4、图 5)显示,本方法在 1–5 个主体场景中始终生成准确、语义正确的动画,避免了身份混淆与动作失真等伪影,而对比方法则普遍存在形状失真与动作不协调问题。
- 用户研究(表 3,10 名参与者)显示,本方法在视频质量、身份保真与时间一致性方面均获得最高偏好率,证实其感知优越性。
- 消融实验确认解绑与重绑模块均不可或缺:解绑模块通过打破刚性对齐实现身份保真,空间重绑模块实现动作定位,完整模型通过结合两者实现连贯、主体特定的动画。
结果表明,CoDance 在所有关键指标上均优于对比方法,取得最低的 LPIPS 与 FID 分数,以及最高的 PSNR、SSIM 与 FVD 值。作者通过该表证明,与现有单人模型相比,其方法在感知相似性、身份一致性和动作保真度方面有显著提升,而后者在多主体场景中因刚性对齐约束而失效。
结果表明,CoDance 在视频质量、身份保真与时间一致性三项评估指标上均取得最高分,全面超越所有对比方法,证明所提出的解绑-重绑策略在多主体动画场景中维持身份与动作连贯性的有效性。

结果表明,CoDance 在多项指标上均优于所有对比方法,取得最低的 LPIPS 与 FID-VID 分数,以及最高的 PSNR、SSIM 与 FVD 值,表明其在感知相似性、身份一致性和动作保真度方面具有显著优势。作者通过多人动画设置证明,传统单人模型因刚性对齐而失效,而 CoDance 的解绑-重绑策略即使在相同单人数据约束下,仍能为每个主体生成准确且连贯的动作。