Command Palette
Search for a command to run...
ABC-Bench:面向真实世界开发中的智能体后端编码基准测试
ABC-Bench:面向真实世界开发中的智能体后端编码基准测试
摘要
大型语言模型(LLMs)向自主智能体(autonomous agents)的演进,已将人工智能编程的应用范围从局部代码生成拓展至复杂、基于代码仓库、以执行为导向的系统性问题求解。然而,当前主流评估基准大多仅在静态环境中考察代码逻辑,忽视了真实工程实践中动态的、全流程的需求,尤其是在后端开发领域,其对环境配置与服务部署具有高度严谨的要求。为填补这一空白,我们提出ABC-Bench——一个专为评估智能体在真实可执行工作流中进行后端编程能力而设计的基准测试。通过可扩展的自动化流水线,我们从开源代码仓库中精心筛选出涵盖8种编程语言和19种框架的224个实际开发任务。与以往评估不同,ABC-Bench要求智能体完整掌控从代码仓库探索到容器化服务部署的全生命周期,并通过外部端到端API测试。我们的大规模评估结果显示,即便最先进的模型在这些综合性任务上也难以实现可靠表现,凸显了当前模型能力与实际后端工程需求之间存在的显著差距。相关代码已开源,访问地址为:https://github.com/OpenMOSS/ABC-Bench。
一句话摘要
复旦大学、上海奇稷智峰科技有限公司与上海创新研究院的作者们提出了 ABC-Bench,这是一个新颖的基准测试,通过端到端、可执行的工作流评估智能体后端编码能力,涵盖从代码探索到跨 8 种语言和 19 个框架的容器化服务部署的完整生命周期管理,揭示了尽管当前大语言模型在静态代码任务中表现达到顶尖水平,但在真实世界工程能力方面仍存在显著差距。
主要贡献
- 当前针对 AI 编码智能体的基准测试主要关注静态、局部的代码修改,无法捕捉真实后端开发中动态的端到端需求,这些需求包括环境配置、服务部署和集成测试。
- ABC-Bench 引入了一个可扩展、自动化的流水线,生成了 224 个真实后端任务,覆盖 8 种语言和 19 个框架,要求智能体完成从代码仓库探索到部署容器化服务并成功通过外部 API 测试的完整开发生命周期。
- 评估结果显示,即使表现最佳的模型也仅达到 63.2% 的 pass@1 率,环境配置与部署成为关键瓶颈,暴露出当前智能体能力与实际工程需求之间的显著差距。
引言
作者利用大语言模型(LLM)在软件工程中作为自主智能体的日益增长趋势,旨在填补评估后端开发能力的关键空白。尽管以往的基准测试聚焦于静态或沙箱环境中孤立的代码修改,但它们未能捕捉真实世界后端工程中完整的动态工作流——即代码变更必须与环境配置、容器化、部署以及端到端 API 验证相结合。这种脱节限制了当前评估的可靠性,因为模型往往在逻辑上成功,但在执行中因配置错误或部署问题而失败。为弥合这一差距,作者提出了 ABC-Bench,一个可扩展、接近生产环境的基准测试,要求智能体完成从代码仓库分析到运行容器化服务并成功通过外部 API 测试的整个后端开发生命周期。该基准测试基于 2,000 个真实开源仓库自动生成,包含 224 个任务,覆盖 8 种语言和 19 个框架,确保了高度的现实多样性。评估结果表明,即使顶尖模型也仅达到 63.2% 的通过率,环境配置与部署成为主导失败点,凸显了当前智能体与实际工程需求之间的巨大能力鸿沟。
数据集

- ABC-Bench 包含 224 个任务,源自 127 个公开的 GitHub 仓库,均采用 MIT 许可证,确保符合开源条款,避免使用专有或许可不明确的代码。
- 数据集涵盖 8 种编程语言和 19 个后端框架,任务覆盖数据统计分析、搜索系统、电商平台、支付网关和开发者工具等真实世界领域。
- 在 224 个任务中,132 个聚焦于预配置运行时环境中的逻辑实现,而 92 个要求智能体自主完成环境配置和容器化服务启动,以测试端到端的运行能力。
- 任务最初生成 600 个候选,经筛选以确保语言、框架和任务类型之间的均衡分布,最终形成高质量、多样化的基准测试。
- 在构建过程中,自动化流水线处理仓库快照,检测并移除敏感凭证(如 API 密钥、令牌、私钥)以保护隐私,同时排除个人或人口统计信息、日志及不当内容。
- 数据集构建不依赖人工标注或众包;仅由研究团队内部手动验证任务标题和描述以保证质量。
- 作者在训练与评估设置中使用该数据集,任务按比例划分为训练集与测试集,混合比例设计以反映语言、框架和任务类型的分布。
- 对于需要容器化的任务,模型必须在项目根目录生成一个能成功构建并运行应用的 Dockerfile,具体要求包括依赖安装和正确的文件结构。
- 元数据由仓库和任务级信息自动生成,无外部人工参与,所有数据处理均旨在保持技术准确性,同时确保隐私与伦理合规。
方法
作者利用 ABC-Pipeline,一个自动化工作流,通过将开源仓库转化为全生命周期基准任务,实现大规模生成真实后端开发任务。该流水线分为三个阶段:仓库探索、环境配置与验证、任务实例化。
在第一阶段,仓库探索中,流水线从 2,000 个开源、MIT 许可的仓库池中筛选出高质量的后端候选项目。一个自主智能体对每个仓库进行探索,识别功能 API 组,避免依赖可能不完整或过时的现有测试。相反,该智能体主动生成专用验证套件,用于评估服务连通性与功能逻辑,这些套件将在后续用于验证模型的解决方案。本阶段还生成 API 测试脚本,如 test_connect.py 和 test_func.py,以确保服务端点的正确性。
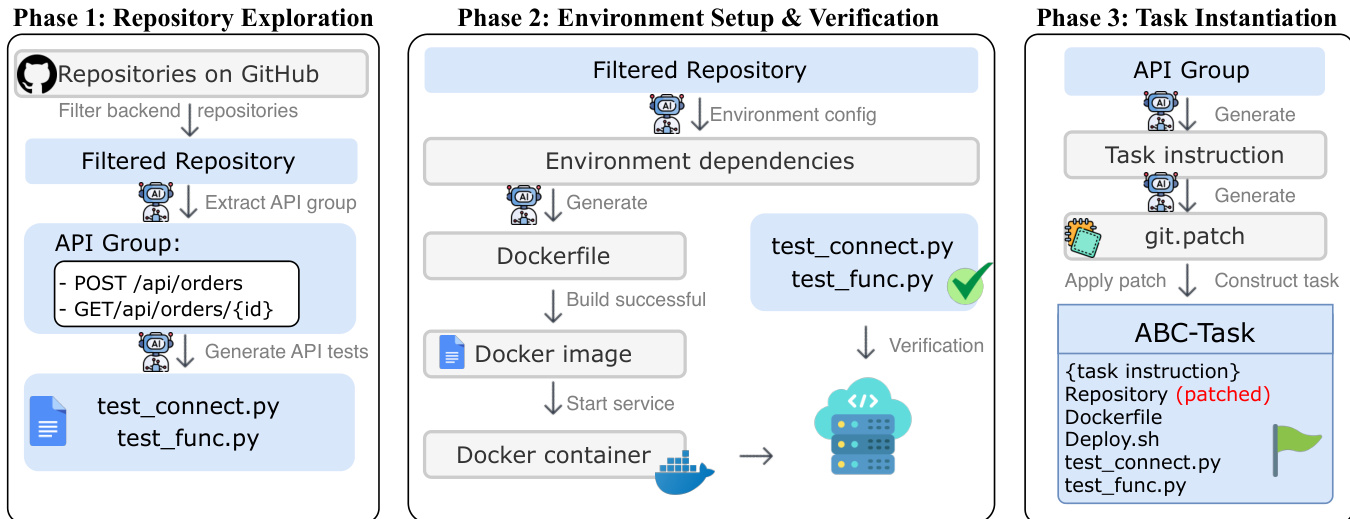
如图所示,第二阶段“环境配置与验证”专注于合成可部署的运行时环境。智能体分析仓库结构以解析依赖关系,并生成必要的容器配置文件,包括 Dockerfile。随后尝试构建运行时镜像,并在隔离容器中启动服务。该阶段确保服务能够正常启动并在预期端口监听,为后续验证建立功能性基础设施。流水线通过执行一系列端到端 API 测试(如健康检查)来验证环境,确认服务处于可操作且响应状态。
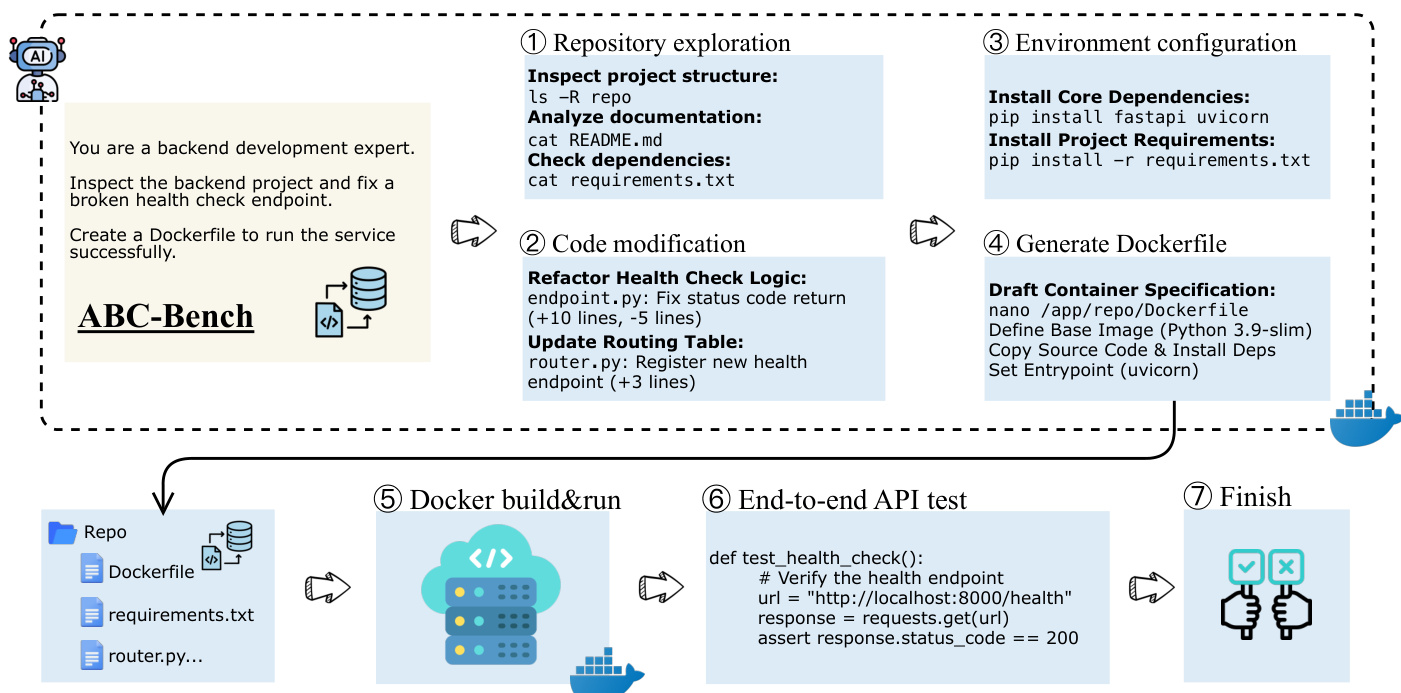
在最终阶段,任务实例化中,流水线采用掩码策略构建基准任务。针对选定的 API 组,智能体生成自然语言任务指令,并合成代表正确实现的解决方案补丁。随后执行反向操作,选择性地掩码目标端点的实现逻辑,以模拟预实现状态。最终生成的 ABC-Task 包含掩码后的仓库、任务指令、环境配置文件和验证套件。对于被指定为环境配置挑战的任务,流水线会从最终包中移除所有合成的环境配置文件,并在任务指令中明确补充要求,以使模型自主完成运行时环境配置。这确保了基准测试能够同时评估代码实现与环境配置能力。
实验
- ABC-Bench 评估了 224 个全生命周期后端任务,验证了自主仓库探索、环境配置、部署及基于 API 的验证能力;ABC-Pipeline 实现了从 GitHub 可扩展地提取任务,降低了构建真实数据集的门槛。
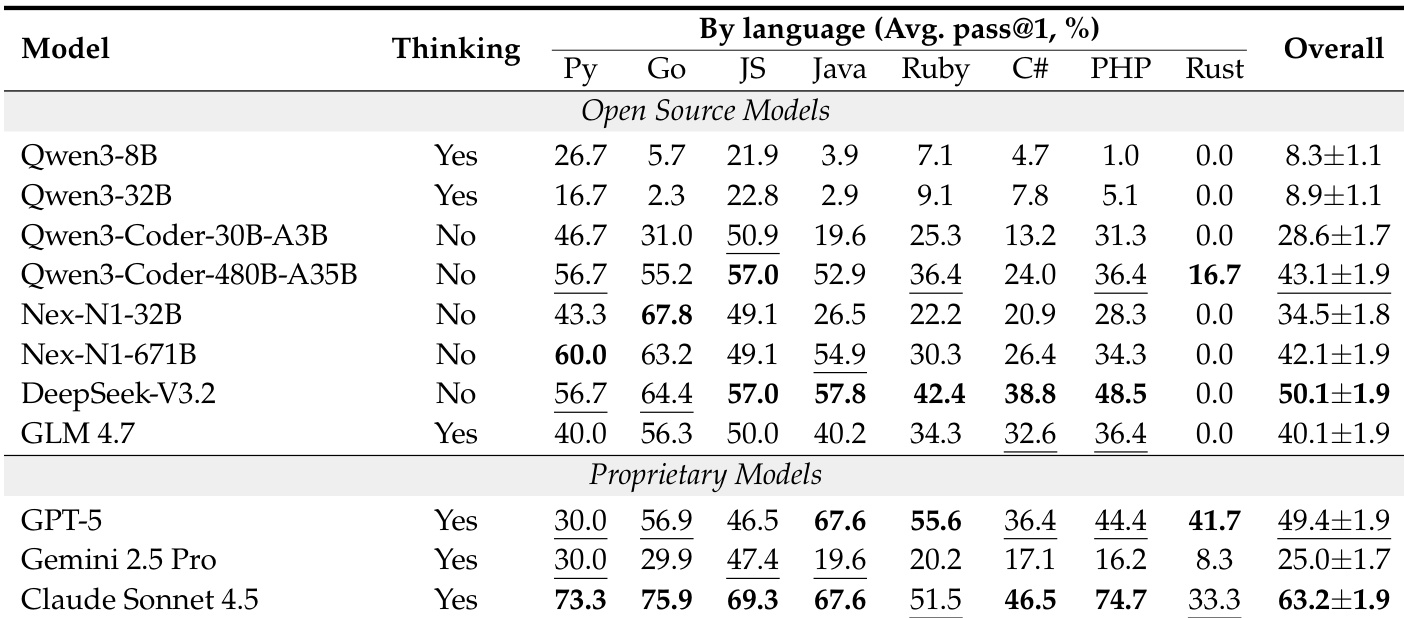
- 在 ABC-Bench 上,Claude Sonnet 4.5 在 224 个任务中达到 63.2% 的 pass@1,而较小模型如 Qwen3-8B 的得分低于 10%,凸显了端到端软件工程的挑战性。
- 环境配置是主要瓶颈:GPT-5 和 DeepSeek-V3.2 等模型虽在 S₂(功能执行)得分超过 80%,但 S₁(构建成功)低于 50%,表明其在配置与依赖管理方面存在关键差距。
- 性能在不同语言栈间差异显著:Rust 任务尤为困难,多数模型失败(如 DeepSeek-V3.2 为 0.0%),仅顶级专有模型(Claude Sonnet 4.5、GPT-5)超过 30% 成功率。
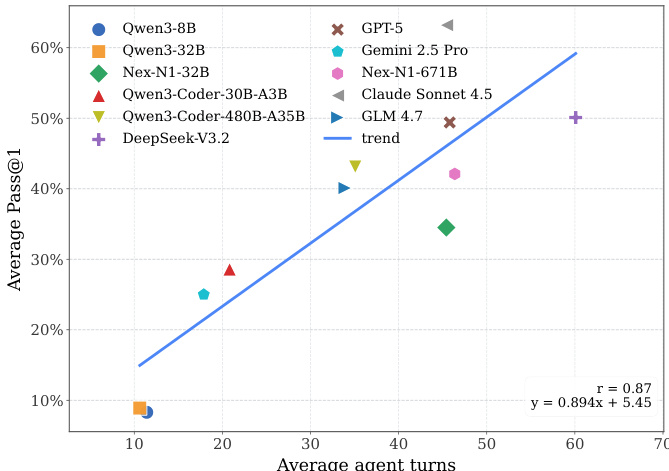
- 交互深度与成功率呈强正相关(r = 0.87),顶级模型平均交互超过 60 轮,而弱模型不足 10 轮,凸显持续迭代推理的必要性。
- 智能体框架选择显著影响性能:OpenHands 使 DeepSeek-V3.2 和 GPT-5 达到峰值性能(约 50%),而 mini-SWE-agent 将 GPT-5 的成功率降至 20% 以下。
- 通过在 Nex-N1 数据上进行监督微调的智能体后训练,Qwen3-8B 的 pass@1 从 8.3% 提升至 13.9%,Qwen3-32B 从 8.9% 提升至 33.8%,证明高质量智能体训练数据的价值。
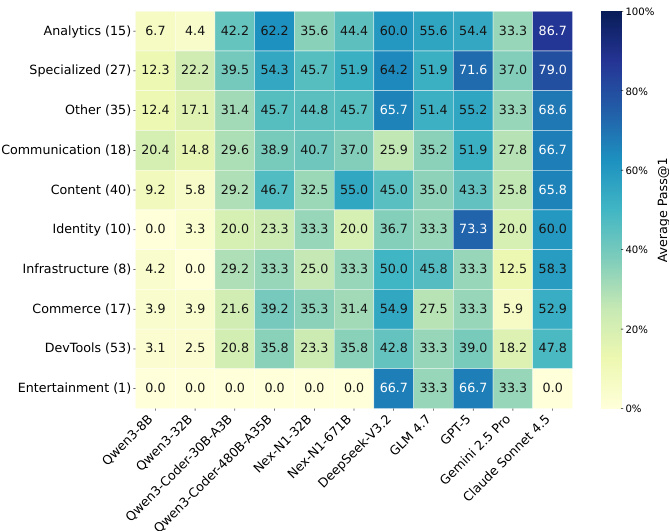
- 任务类别分析揭示领域特定挑战:DevTools 任务始终困难(顶级模型为 47.8%),而 Analytics 和 Specialized 任务较易(Claude Sonnet 4.5 达 86.7%)。
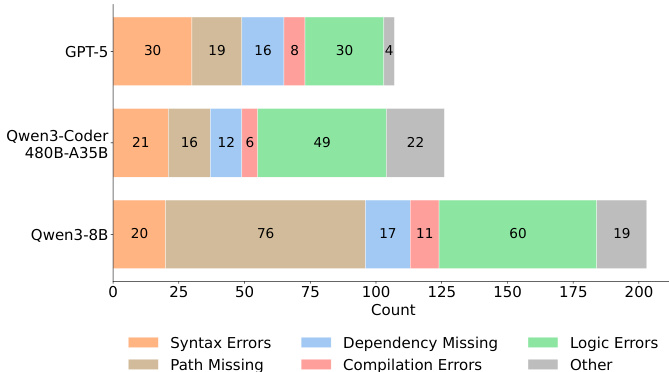
- 错误分析显示,环境相关失败(如路径缺失、依赖缺失)占主导,尤其在小模型中;大模型则更多出现逻辑错误,表明失败模式从语法错误向高层次推理错误转变。
作者采用标准化评估框架在 ABC-Bench 上评估模型,衡量其在不同编程语言中的表现,并识别环境配置为主要瓶颈。结果表明,尽管专有模型如 Claude Sonnet 4.5 达到高整体通过率,开源模型在 Rust 任务及小参数规模下表现显著不足,凸显全生命周期软件开发中的持续挑战。
作者分析了各模型的错误类型,发现 Qwen3-8B 等小模型主要因语法和路径等基础问题失败,而 GPT-5 和 Qwen3-Coder 等大模型则表现出更复杂的逻辑错误,表明随着模型规模增大,失败模式发生转变。
结果显示,智能体平均交互轮数与平均 pass@1 性能之间存在强正相关关系,相关系数为 0.87。作者利用这一关系强调,成功的全生命周期软件开发需要持续、迭代的交互,顶级模型如 Claude Sonnet 4.5 的执行轨迹显著长于弱模型。
作者提出 ABC-Bench,一个评估模型在全生命周期后端任务(包括探索、代码生成、环境配置、部署和端到端验证)上表现的基准测试。与现有基准不同,ABC-Bench 全面覆盖所有这些阶段,如其评估框架中包含的四个阶段——探索、代码、环境、部署——所示。

作者在 ABC-Bench 上评估模型,该基准测试涵盖全生命周期后端任务,使用标准化沙箱环境,要求智能体自主配置环境、部署服务并成功通过功能 API 测试。结果表明,环境配置是主要瓶颈,GPT-5 和 DeepSeek-V3.2 等模型虽具备高功能成功率,但在初始构建阶段失败,而 Qwen3-8B 等小模型在两个阶段均表现不佳。