Command Palette
Search for a command to run...
个性化误导之困:理解并缓解个性化LLM中的幻觉问题
个性化误导之困:理解并缓解个性化LLM中的幻觉问题
Zhongxiang Sun Yi Zhan Chenglei Shen Weijie Yu Xiao Zhang Ming He Jun Xu
摘要
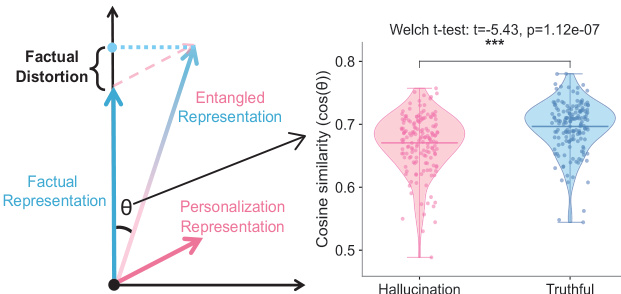
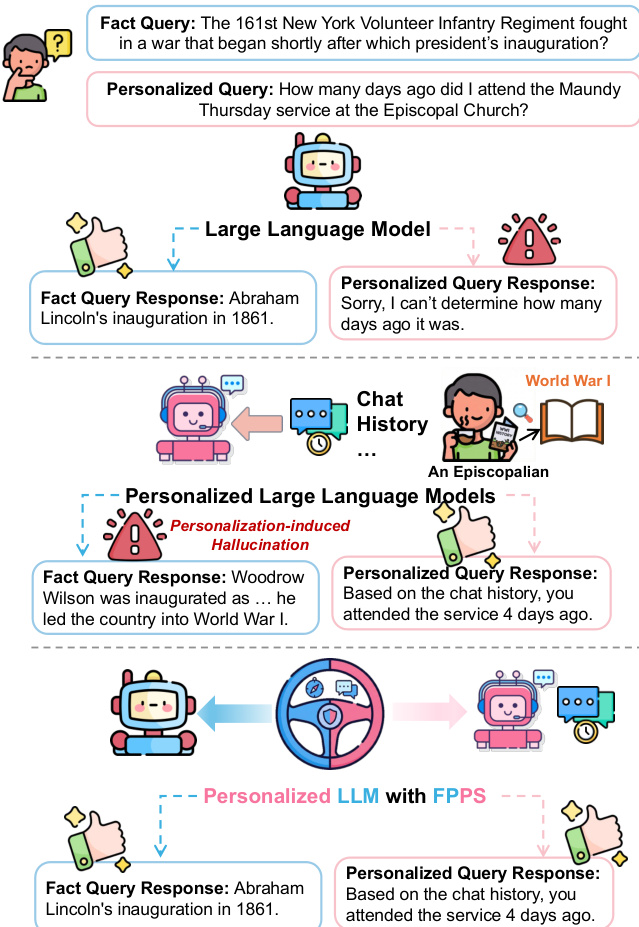
个性化大语言模型(LLMs)通过调整模型行为以适应个体用户,从而提升用户满意度。然而,个性化过程可能无意中扭曲事实推理。我们发现,当个性化大语言模型面对事实性问题时,会表现出一种现象:模型生成的答案更倾向于符合用户的历史行为模式,而非客观事实,从而引发由个性化诱导的幻觉(hallucinations),导致事实可靠性下降,并可能传播错误认知。这一问题的根源在于个性化表征与事实表征之间的表征纠缠(representational entanglement)。为应对这一挑战,我们提出了一种轻量级的推理阶段方法——事实保真性个性化引导(Factuality-Preserving Personalized Steering, FPPS),该方法能够在保持个性化行为特征的同时,有效缓解个性化引发的事实性偏差。此外,我们还构建了PFQABench,这是首个专为联合评估个性化场景下事实性与个性化问答性能而设计的基准测试平台。在多种大语言模型骨干架构及个性化方法上的实验结果表明,FPPS显著提升了事实准确性,同时维持了良好的个性化表现,验证了其有效性与通用性。
一句话摘要
中国人民大学、联想AI实验室和对外经济贸易大学的研究人员提出FPPS,一种轻量级的推理时方法,将大语言模型(LLM)中的事实推理与个性化解耦,防止个性化引发的幻觉,同时保留用户特定行为,在多个模型上通过新型PFQABench基准进行了验证。
主要贡献
-
个性化大语言模型(LLMs)由于模型隐空间中个性化与事实知识的表征纠缠,可能在对齐用户历史偏好而非客观事实时引入事实性幻觉。
-
作者提出事实性保持的个性化引导(FPPS),一种轻量级的推理时方法,通过表征偏移分析检测事实性扭曲,并施加有针对性的、最小侵入性调整以恢复准确性,同时保留个性化行为。
-
作者引入PFQABench,首个联合评估事实性与个性化问答的基准,揭示了个性化下的系统性事实性退化,并证明FPPS在多个LLM主干模型和个性化方法中均能持续提升事实准确性。
引言
个性化大语言模型(LLMs)广泛应用于现实场景中,通过适应用户历史和偏好来提升用户参与度,通常采用基于提示的个性化方式。然而,这种个性化可能无意中扭曲事实推理,导致模型输出与用户过往陈述一致而非客观事实——这是由于模型隐空间中个性化信号与事实知识存在纠缠。以往研究主要聚焦于一般性幻觉缓解或偏好对齐,却忽视了这一特定失效模式:个性化本身成为事实性不准确的来源。作者提出FPPS,一种轻量级、推理时的框架,通过识别脆弱层、探测纠缠并施加针对性引导,检测并纠正由个性化引发的事实性扭曲,从而在不牺牲个性化的情况下保持事实性。为实现系统性评估,作者还提出PFQABench,首个联合评估真实用户会话中事实准确性和个性化质量的基准,证明FPPS显著提升了事实可靠性,同时在多个LLM架构上维持了个性化性能。
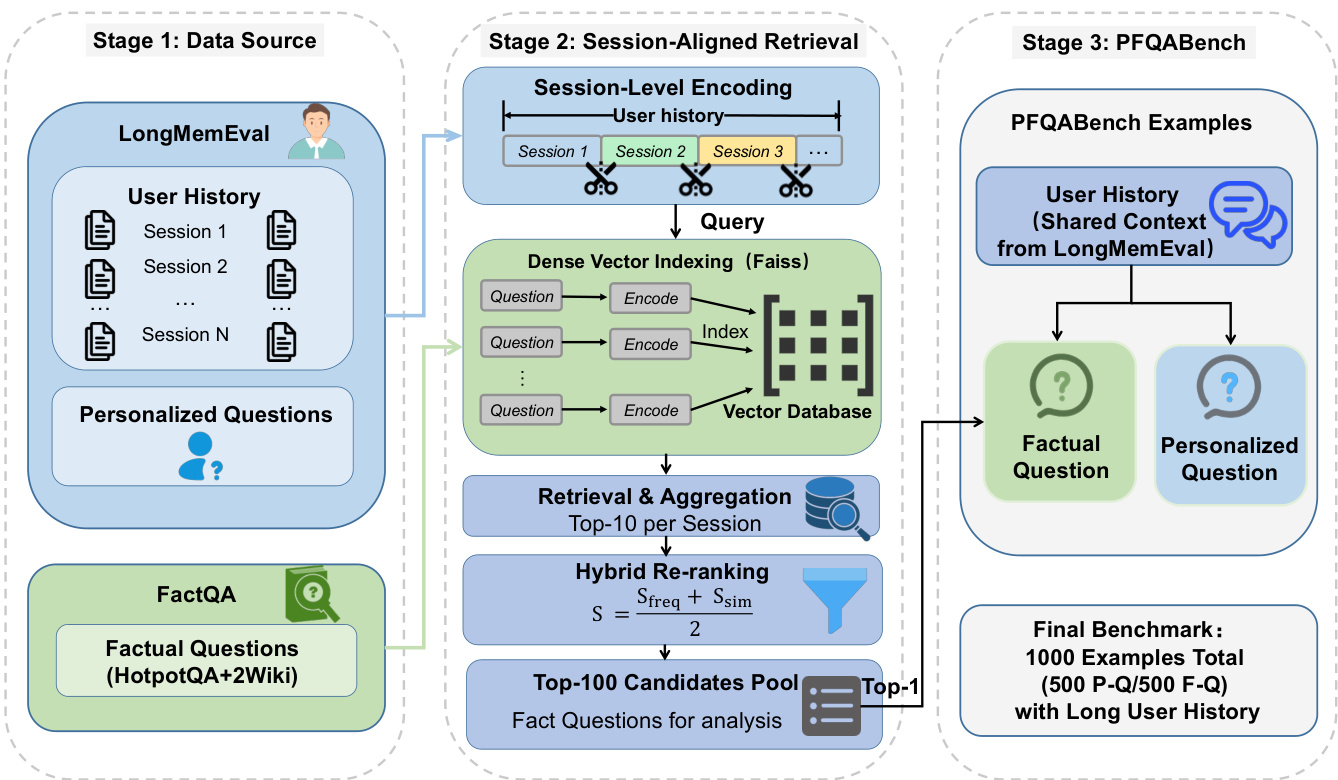
数据集

- 数据集PFQABench结合了LongMemEval(Wu等,2025)中的长期用户交互历史与FactQA中的以事实为中心的多跳问题,FactQA由HotpotQA和2WikiMultiHopQA(Yang等,2018;Ho等,2020)合并构建而成。
- 数据集包含1,000个样本,覆盖500名用户,均匀分为500个需用户历史的个性化问题和500个设计为不受个性化影响的事实性问题。
- 事实性问题从精心筛选的池中每用户抽取一个,而个性化问题直接来自LongMemEval,确保用户历史与查询上下文一致。
- 采用分层划分:训练集包含250个个性化问题和250个事实性问题,剩余各250个保留用于测试集,以确保无偏评估。
- 作者使用训练集对模型进行微调,混合个性化与事实性问题类型,保持平衡比例以反映数据集设计。
- 处理过程中,每个事实性问题均与同用户的一个个性化对应问题配对,实现对个性化如何影响事实准确性的受控评估。
- 构建元数据以追踪用户身份、问题类型和来源,支持对个性化引发的事实性漂移进行细粒度分析。
- 未使用显式裁剪;而是通过精细对齐与采样,确保个性化与事实信号之间的一致性,避免污染。
方法
作者提出事实性保持的个性化引导(FPPS),一种推理时框架,旨在缓解大语言模型中由个性化引发的幻觉,同时保留个性化性能。整体框架分为三个阶段:层选择、探测检测和自适应引导。如框架图所示,过程始于离线分析,识别对事实预测受个性化影响最显著的模型层。随后在选定层训练一个事实性探测器,以估计个性化与事实推理之间的纠缠程度。最后在推理阶段,根据探测器输出对隐藏表示施加自适应引导,选择性纠正事实性扭曲,而不损害个性化响应。
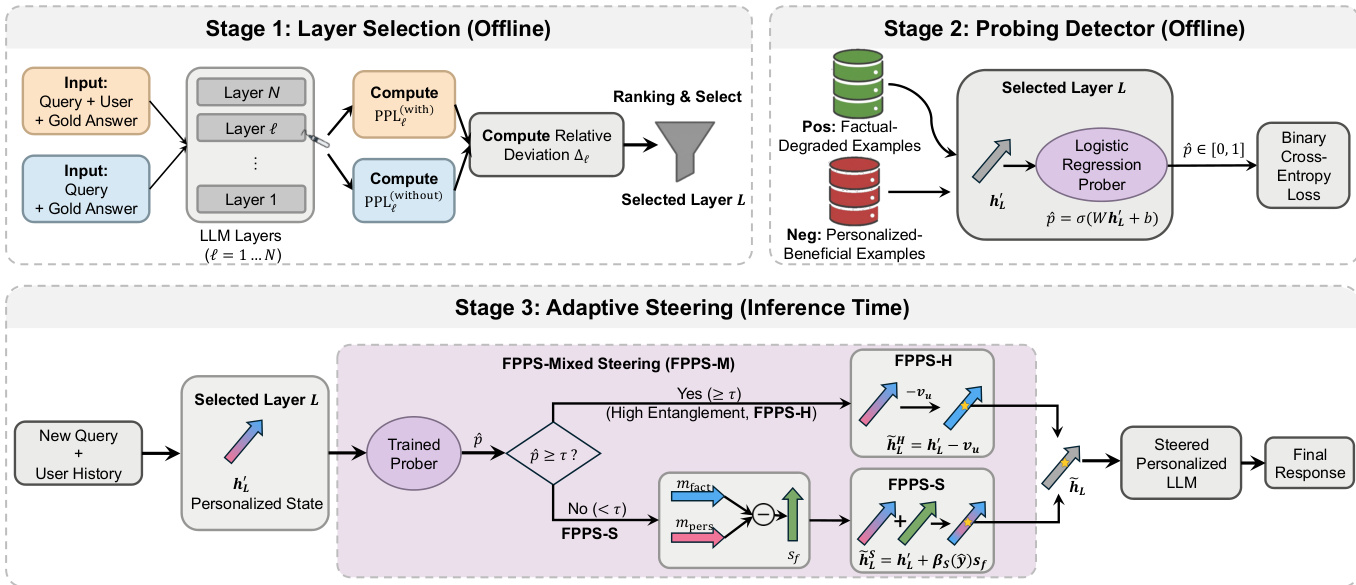
第一阶段:层选择,旨在识别对个性化影响事实预测最敏感的模型层 L。通过构建包含与不包含用户历史的对比输入,计算每个层 ℓ 的相对困惑度偏差 Δℓ。该偏差衡量用户历史对事实答案似然性的扰动强度。作者在两类样本上评估 Δℓ:事实性退化案例(个性化破坏正确性)和个性化有益案例(个性化促进正确性)。选择在两组中均表现出最一致且最大偏差的层 L 作为后续探测与引导的焦点。
第二阶段:探测检测,在选定层 L 上训练一个逻辑回归分类器,以估计个性化与事实推理之间的纠缠程度。探测器以最终标记的隐藏状态 hL′ 为输入,输出概率 p^∈[0,1],表示当前表示依赖个性化并可能影响事实推理的可能性。事实性退化样本作为正样本训练,个性化有益样本作为负样本。该探测器输出 p^ 作为引导机制的控制信号。
第三阶段:自适应引导,对个性化修改后的隐藏状态 hL′ 应用探测条件变换。框架实现三种变体:FPPS-H、FPPS-S 和 FPPS-M。FPPS-H 是一种硬引导变体,当估计的纠缠度 p^ 超过预设阈值 τ 时,将个性化视为有害。在此模式下,个性化完全从隐藏表示中移除,恢复为非个性化对应表示 hL=hL′−vu。FPPS-S 是一种软引导变体,基于探测器输出进行连续修正。其使用引导向量 sf=mfact−mpers,将表示向内部事实推理模式偏移,远离历史条件下的个性化漂移。引导操作为 h~LS=hL′+βS(p^)sf,其中 βS(p^)=γ(p^−0.5),γ>0 控制强度。FPPS-M 结合两者优势:当纠缠度较低(p^<τ)时使用软引导,当纠缠度较高(p^≥τ)时默认采用硬移除。这确保在个性化安全且有益时实现连续调节,在其可能破坏事实预测时实现完全抑制。
实验
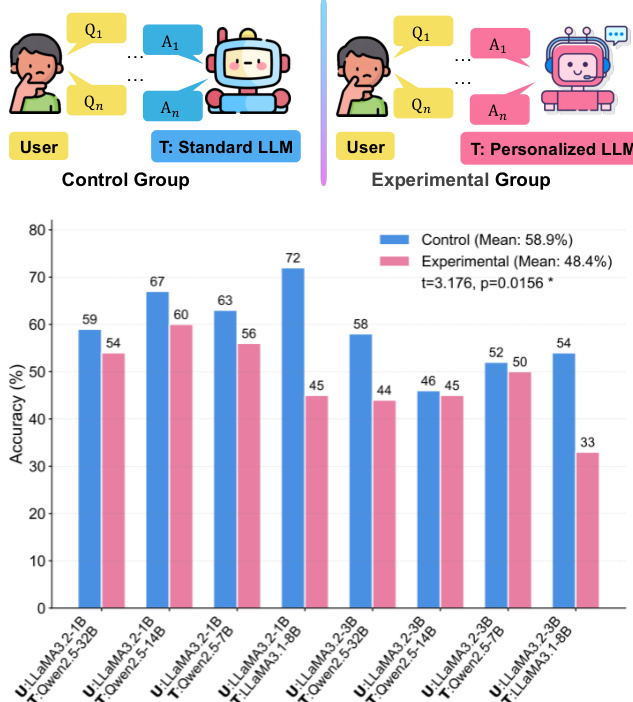
- 受控模拟显示,与标准LLM相比,个性化LLM在事实知识获取准确率上平均降低10.5%(配对t检验:t = 3.176,p = 0.016),凸显个性化对用户学习的负面影响。
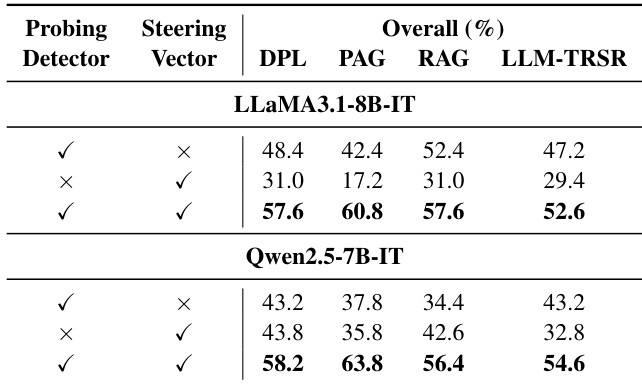
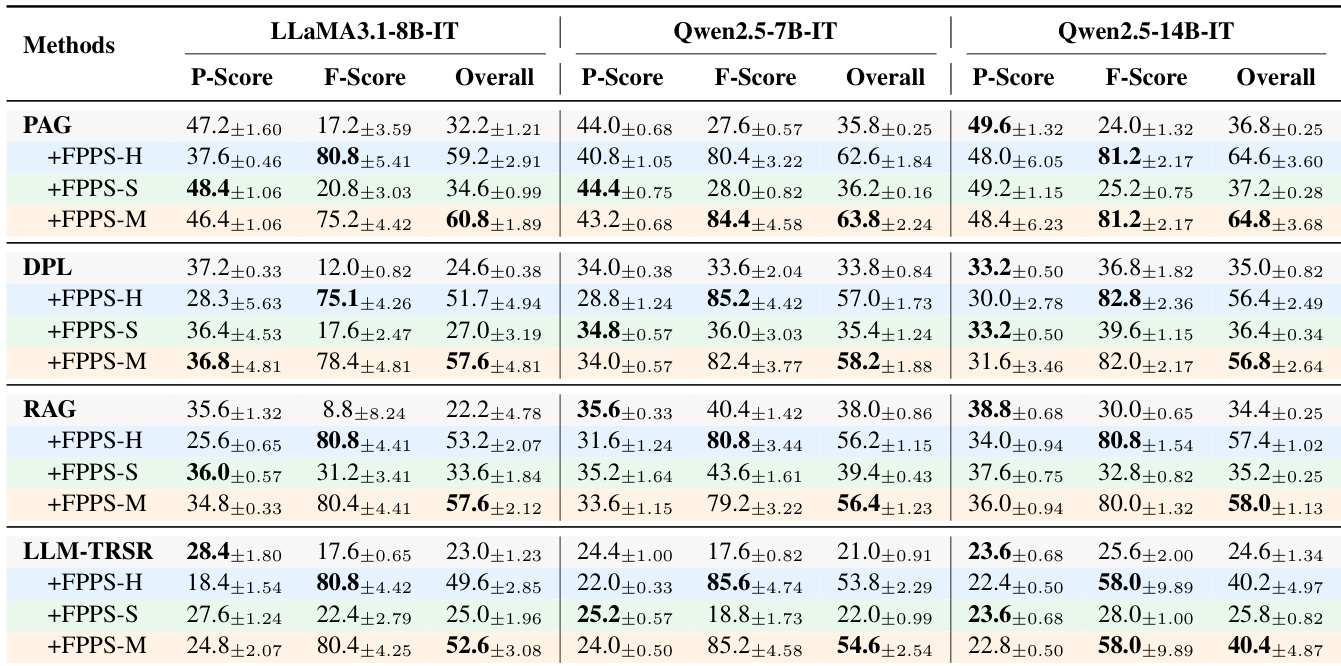
- FPPS在所有模型和个性化基线中均使整体得分提升超过50%,其中FPPS-M在事实正确性(F-Score)与个性化实用性(P-Score)之间取得最佳平衡。
- 消融研究证实,探测检测器与引导向量均对性能至关重要,随机替换导致显著退化。
- 在基于RAG的个性化中增加用户历史长度会大幅降低F-Score,但FPPS-M在所有历史长度下均保持稳定事实性能,证明其对纠缠的鲁棒性。
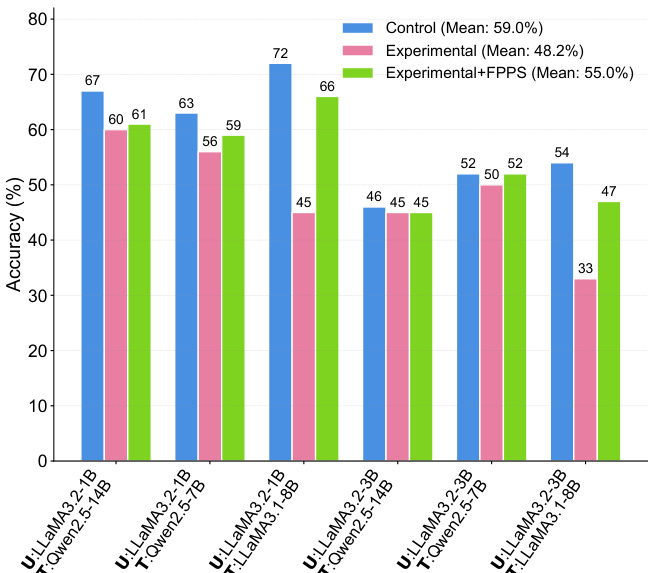
- FPPS-M缓解了个性化引发的学习错误,在教学模拟中平均提升事实准确性7.0%,有效缩小了个性化LLM与标准LLM之间的差距。
- 敏感性分析表明,FPPS-M对阈值调优具有鲁棒性,在广泛的风险阈值范围内均表现优异;超参数分析确认在高层语义层进行适度引导的有效性。
作者通过消融研究评估FPPS-M的组件,表明探测检测器与引导向量对有效缓解个性化引发的幻觉均不可或缺。结果表明,移除任一组件均导致显著性能下降,完整FPPS配置在所有模型与个性化方法中始终取得最佳综合得分。
作者通过受控模拟比较由标准LLM与个性化LLM教学的用户在事实知识学习上的表现,实验组在所有模型对中均表现出持续较低的事实准确性。结果表明,个性化LLM使事实学习效果平均降低10.5%,凸显其对用户事实理解的显著负面影响。
作者通过受控模拟比较由个性化LLM与标准LLM教学的用户在事实知识学习上的表现,发现个性化LLM平均导致事实准确性下降。结果表明,将FPPS应用于个性化LLM可显著提升事实学习准确性,缩小与标准LLM的差距。
作者通过受控模拟评估个性化LLM对事实知识学习的影响,发现由个性化LLM教学的用户相比标准LLM教学的用户表现出更低的事实准确性。结果表明,所提出的FPPS方法在所有模型和个性化基线上均显著提升事实准确性,其中FPPS-M通过平衡事实可靠性与个性化实用性,实现最佳整体性能。
作者使用PFQABench评估个性化LLM对事实知识学习的影响,用户与个性化或标准LLM作为教师互动。结果表明,由个性化LLM教学的用户相比标准LLM教学的用户表现出更低的事实准确性,表明个性化对事实理解具有负面影响。
