Command Palette
Search for a command to run...
STEM:通过嵌入模块扩展Transformer
STEM:通过嵌入模块扩展Transformer
Ranajoy Sadhukhan Sheng Cao Harry Dong Changsheng Zhao Attiano Purpura-Pontoniere Yuandong Tian Zechun Liu Beidi Chen
摘要
细粒度稀疏性在不按比例增加每标记计算开销的前提下,有望实现更高的参数容量,但通常面临训练不稳定、负载均衡困难以及通信开销高等问题。本文提出STEM(通过嵌入模块扩展Transformer,Scaling Transformers with Embedding Modules),一种静态的、基于标记索引的方法:该方法将前馈网络(FFN)的上投影层替换为局部层内嵌入查找,同时保持门控机制和下投影层为密集结构。这一设计消除了运行时的路由开销,支持CPU卸载与异步预取,且将模型容量与每标记的浮点运算量(FLOPs)以及跨设备通信完全解耦。实证结果表明,STEM在极端稀疏条件下仍能实现稳定训练。相较于密集基线模型,STEM在提升下游任务性能的同时,显著降低了每标记的FLOPs与参数访问次数(约消除三分之一的FFN参数)。STEM能够学习具有大角度分布的嵌入空间,从而增强其知识存储能力。更有趣的是,这种增强的知识容量还带来了更好的可解释性:由于STEM嵌入具有明确的标记索引特性,因此可无需修改输入文本或引入额外计算,以简单直观的方式实现知识编辑与知识注入。此外,STEM显著提升了长序列场景下的性能表现:随着序列长度增长,激活的参数数量随之增加,从而实现实际测试阶段的容量扩展。在3.5亿与10亿参数规模的模型上,STEM整体准确率提升可达约3%–4%,在知识密集型与推理密集型基准测试中表现尤为突出(如ARC-Challenge、OpenBookQA、GSM8K、MMLU)。总体而言,STEM是一种高效扩展参数化记忆的有效方法,兼具更优的可解释性、更强的训练稳定性以及更高的计算效率。
一句话总结
卡内基梅隆大学与Meta AI提出STEM,一种静态的、基于标记索引的稀疏架构,用层内嵌入查找替代FFN的上投影,实现稳定训练,将每标记的FLOPs和参数访问量减少约三分之一,并通过可扩展的参数激活提升长上下文性能。通过将容量与计算和通信解耦,STEM支持异步预取的CPU卸载,利用具有大角度分布的嵌入实现更高的知识存储容量,同时无需修改输入文本即可实现可解释、可编辑的知识注入——在知识和推理基准测试中,相比密集基线性能提升高达约3–4%。
主要贡献
-
STEM通过用静态的、基于标记索引的嵌入查找替代FFN的上投影,解决了在不增加每标记计算量的前提下扩展参数容量的挑战,消除了运行时路由,支持高效的CPU卸载与异步预取,同时保留密集的门控和下投影层。
-
该方法在极端稀疏条件下实现稳定训练,并在知识和推理基准测试(如ARC-Challenge、GSM8K、MMLU)中相比密集基线性能提升约3–4%,通过具有大角度分布的可学习嵌入空间,将每标记的FLOPs和参数访问量减少约三分之一,从而增强知识存储能力。
-
STEM的基于标记索引的嵌入设计支持无需修改输入文本或增加计算量的可解释知识编辑与注入,其容量可随序列长度实际扩展,激活更多不同参数,相比MoE和PKM方法在长上下文性能和系统效率方面均有提升。
引言
作者利用一种静态的、基于标记索引的嵌入模块,高效扩展Transformer架构,将前馈网络的上投影替换为层内查找,同时保持门控和下投影为密集结构。该设计显著降低了每标记的FLOPs和参数访问量——消除了约三分之一的FFN参数——且未增加跨设备通信或运行时路由开销。与以往稀疏方法(如MoE依赖动态路由导致训练不稳定和负载不均,或PKM模型面临高推理查找成本和欠训练问题)不同,STEM在极端稀疏条件下实现稳定训练。其核心创新在于将参数容量与计算和通信解耦,支持CPU卸载与异步预取,并实现可扩展的长上下文性能。所学习的嵌入空间具有大角度分布,增强了知识存储与可解释性,支持无需修改输入文本或增加计算的直接知识编辑与注入。STEM在350M和1B模型上,于知识与推理基准测试中实现高达3–4%的准确率提升,为大规模语言模型中参数化记忆的扩展提供了一条稳健、高效且可解释的路径。
数据集

- 数据集由多个来源组成:OLMo-MIX-1124(3.9T标记),为DCLM与Dolma 1.7的混合;NEMOTRON-CC-MATH-v1(数学导向);以及NEMOTRON-PRETRAINING-CODE-v1(代码导向)。
- 预训练阶段,作者从OLMo-MIX-1124中子采样1T标记。
- 中期训练阶段,数据混合比例为65% OLMo-MIX-1124、5% NEMOTRON-CC-MATH-v1、30% NEMOTRON-PRETRAINING-CODE-v1。
- 用于上下文长度扩展时,作者使用PROLONG-DATA-64K,其中63%为长上下文,37%为短上下文,序列通过跨文档注意力掩码打包至最多32,768标记。
- 数据处理中未进行显式裁剪,但序列被打包以适配模型的最大上下文长度。
- 为长上下文评估构建元数据,支持“针在 haystack”基准测试,用于测试扩展上下文中的检索能力。
- 作者使用预训练数据在1000亿标记上训练350M模型,在1万亿标记上训练1B模型;中期训练使用1000亿标记,上下文扩展使用200亿标记。
- 训练采用AdamW优化器,余弦学习率调度,10%预热,最小学习率设为峰值的0.1倍。
- 模型架构使用独立的输入嵌入和语言模型头,三分之一的FFN层被稀疏替代(STEM或哈希层MoE),保持与密集基线相当的激活FLOPs。
方法
作者在仅解码器的Transformer中采用改进的前馈网络(FFN)架构,基于SwiGLU激活函数和FFN的键值记忆视角,提出STEM(静态标记嵌入混合)模型。标准SwiGLU FFN如图(a)所示,将输入隐藏状态xℓ通过门控投影Wℓg、上投影Wℓu和下投影Wℓd进行处理。变换定义为yℓ=Wℓd(SiLU(Wℓgxℓ)⊙(Wℓuxℓ)),其中上投影生成用于从下投影中检索信息的地址向量,门控投影提供上下文相关的调制。
STEM设计如图(c)所示,从根本上重构了这一过程,用基于标记索引的嵌入查找替代上投影。对于给定层ℓ和输入标记t,模型访问每层嵌入表Uℓ∈RV×dff,检索向量Uℓ[t]。输出计算为yℓ=Wℓ(d)(SiLU(Wℓ(g)xℓ)⊙Uℓ[t])。这一设计灵感源于FFN的键值记忆视角:上投影充当内容检索的键,门控投影充当上下文相关的调制器。通过用静态的、标记特定的嵌入替代上投影,STEM将参数容量与每标记计算解耦,实现更高效且可解释的架构。
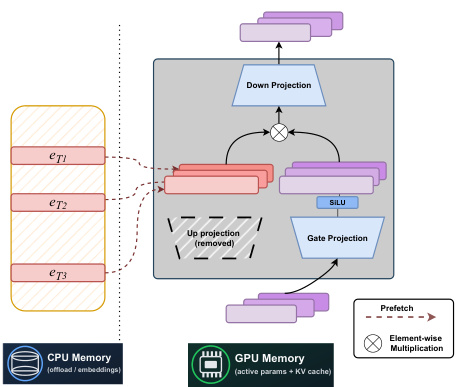
系统架构如图所示,突出显示了STEM模型的关键组件。模型前向传播从输入隐藏状态xℓ开始,经门控投影Wℓg处理后,通过SiLU激活函数。同时,标记t用于索引CPU内存,对应STEM嵌入Uℓ[t]被预取。该嵌入随后与SiLU函数输出逐元素相乘。结果传递至下投影Wℓd,生成最终输出yℓ。图中还显示,STEM嵌入存储在CPU内存中,支持卸载和异步预取,降低GPU内存占用和通信开销。下投影和门控投影保留在GPU内存中作为活跃参数,而STEM嵌入存储在CPU内存中,实现高效的内存管理。
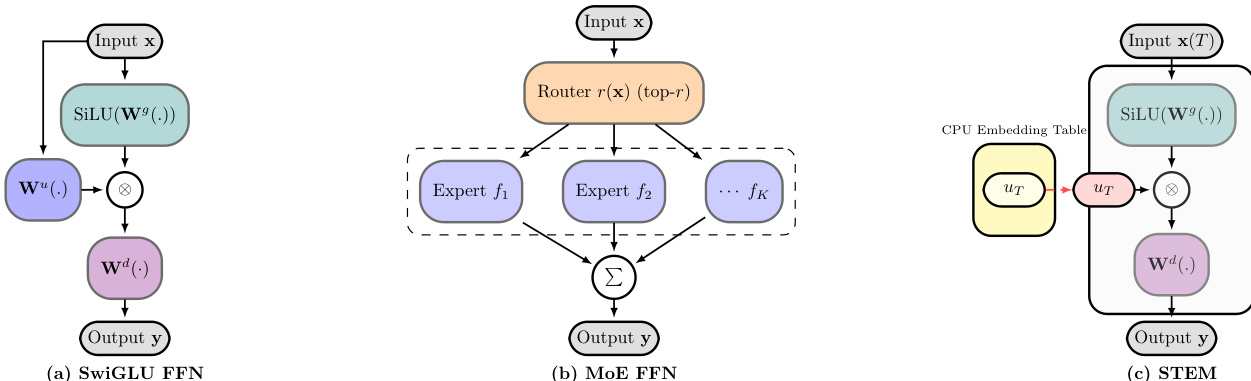
图(a)、(b)和(c)中的架构对比展示了从标准SwiGLU FFN到专家混合(MoE)FFN,再到STEM FFN的演进过程。标准SwiGLU FFN(a)使用单一密集的上投影。MoE FFN(b)用多个专家FFN和一个路由器替代,根据输入选择部分专家。相比之下,STEM FFN(c)用存储在CPU内存中的基于标记索引的嵌入查找替代上投影。该设计避免了可训练路由器及其带来的专家并行通信开销,更具效率和可扩展性。STEM架构还支持更好的可解释性,因为嵌入与特定标记直接关联,可用于知识编辑。
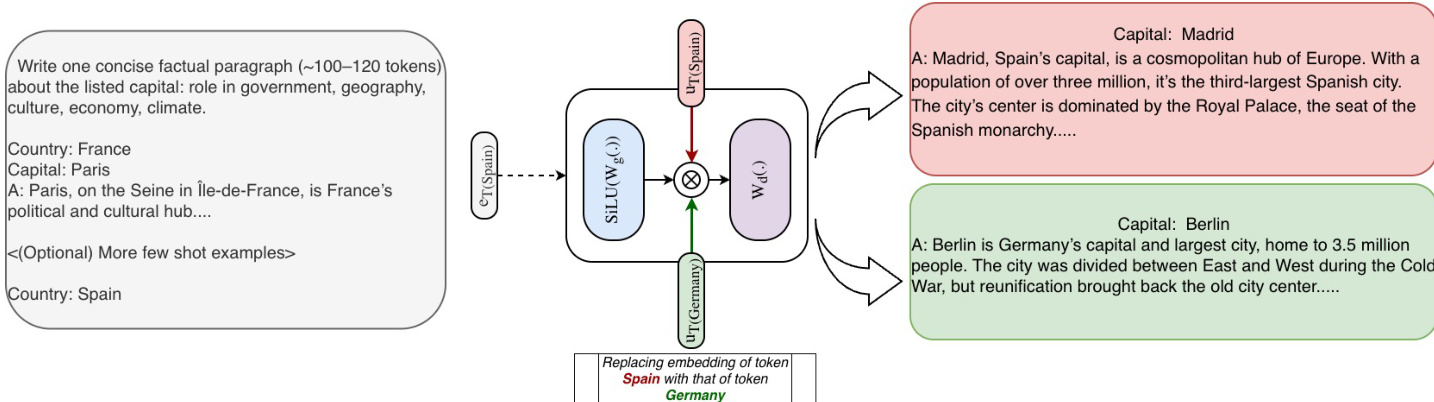
图中知识编辑演示展示了如何通过修改特定标记的嵌入来改变模型输出。提示“Country: Spain”用于生成关于马德里的段落。通过将标记“Spain”的STEM嵌入替换为“Germany”的嵌入,模型生成了关于柏林的段落。这展示了STEM实现精确、基于标记索引的知识编辑能力,这是嵌入与标记之间清晰映射的直接结果。图中还显示,即使源实体和目标实体的标记化长度不同,也可通过填充、复制或子集选择等策略完成编辑。这种以目标明确且可解释方式操控模型知识的能力,是STEM架构的关键优势。
实验
- STEM用基于标记索引的嵌入替代门控FFN中的上投影,实现稳定训练,无损失突增,优于细粒度MoE模型。
- 在ARC-Challenge和OpenBookQA上,STEM相比密集基线性能提升约9–10%,且随着STEM层增加,性能持续改善。
- STEM提升长上下文推理能力:在“针在 haystack”测试中,32k上下文长度下准确率比密集基线高出13%。
- STEM将每标记FLOPs和参数访问量减少最多三分之一,训练ROI相比密集基线提升1.08倍(1/3层)、1.20倍(1/2层)和1.33倍(全层)。
- STEM在嵌入空间中表现出大角度分布(低成对余弦相似度),增强信息存储容量并减少表征干扰。
- STEM支持可解释、可逆的知识编辑:交换特定标记的嵌入可改变事实预测(如马德里→柏林),而无需修改输入。
- STEM在GSM8K、MMLU、BBH、MuSR和LongBench多跳/代码理解任务上优于密集基线,展现更强的推理与知识检索能力。
- STEM在不同批量大小下保持效率,得益于静态的、基于标记索引的稀疏性与减少的参数流量,持续实现FLOPs和内存访问节省。
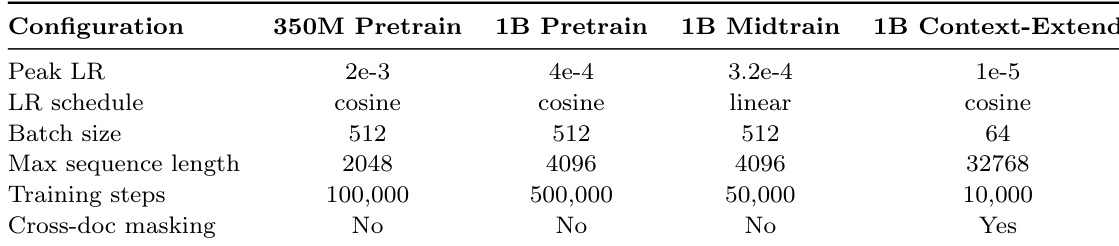
作者在所有配置中采用一致的学习率调度,预训练阶段使用余弦衰减,中期训练使用线性衰减,同时根据各设置的计算需求调整峰值学习率和批量大小。中期训练和上下文扩展任务的训练步数减少,且仅在上下文扩展实验中启用跨文档掩码。
结果表明,STEM模型在所有上下文长度下均优于密集基线,最大提升出现在0–2k范围内,STEM得分为27.6,而基线为24.0。在更长上下文下性能差距缩小,但STEM始终保持一致优势,表明其具备更强的长上下文能力。

作者比较了标准FFN与STEM架构在预填充和解码阶段的计算与通信成本。在预填充和训练阶段,STEM通过用基于标记索引的嵌入替代上投影,减少FLOPs,节省B(dffL) FLOPs。在解码阶段,STEM将参数加载成本降低一半,并消除通信,每步节省ddff。

作者使用STEM将门控FFN中的上投影替换为基于标记索引的嵌入,相比密集和MoE基线,实现更好的训练稳定性和知识密集型任务性能。结果表明,STEM在ARC-Challenge和OpenBookQA等基准测试中始终优于密集基线,性能提升随替换的FFN层增加而增大,同时减少每标记的FLOPs和参数访问量。

作者在1B规模的中期训练模型上,将STEM模型与密集基线进行多下游任务对比。结果表明,STEM在知识密集型任务(如ARC-E、PIQA、OBQA)中持续优于基线,提升2.1至4.1分,而在其他任务上达到相当或略优性能。所有评估任务的平均得分从57.50提升至58.49,表明模型整体性能显著提升。
