Command Palette
Search for a command to run...
基于视觉-语言推理的城市社会语义分割
基于视觉-语言推理的城市社会语义分割
Yu Wang Yi Wang Rui Dai Yujie Wang Kaikui Liu Xiangxiang Chu Yansheng Li
摘要
作为人类活动的聚集地,城市地表包含丰富的语义实体。从卫星影像中分割出这些不同类型的实体,对于众多下游应用至关重要。当前先进的分割模型在处理由物理属性定义的实体(如建筑物、水体)方面表现可靠,但在应对社会属性定义的类别(如学校、公园)时仍面临挑战。本文提出一种基于视觉-语言模型推理的社经语义分割方法。为支持该研究,我们构建了一个名为SocioSeg的新数据集,该数据集包含卫星影像、数字地图以及按层级结构组织的社经语义实体像素级标注。此外,我们提出一种新颖的视觉-语言推理框架——SocioReasoner,该框架通过跨模态识别与多阶段推理,模拟人类识别与标注社经语义实体的过程。我们采用强化学习优化这一不可微分的推理过程,从而激发视觉-语言模型的推理能力。实验结果表明,所提方法在性能上优于现有最先进模型,并展现出强大的零样本泛化能力。相关数据集与代码已开源,地址为:https://github.com/AMAP-ML/SocioReasoner。
一句话总结
武汉大学与阿里巴巴集团提出SocioReasoner,一种视觉-语言推理框架,通过模拟人类跨模态识别与多阶段推理,利用新构建的分层数据集(SocioSeg)和强化学习,在卫星图像中实现社会语义分割,显著超越传统基于物理属性的分割方法,在性能和零样本泛化能力上均达到领先水平。
主要贡献
- 城市区域的社会语义分割仍具挑战性,因为学校、公园等社会定义实体缺乏显著视觉特征,仅凭卫星图像难以识别,而建筑物或水体等物理实体则具有明确视觉标识。
- 作者提出SocioSeg,一个全新的基准数据集,包含社会语义实体的分层标注以及统一的数字地图层,解决了数据异构性和对齐问题,支持更有效的多模态学习。
- 提出SocioReasoner,一种基于两阶段“渲染-精炼”机制与强化学习的视觉-语言框架,模拟人类推理过程,在社会语义分割任务上实现最先进性能与强零样本泛化能力。
引言
城市社会语义分割旨在从卫星图像中识别社会定义的实体,如学校、公园和住宅区,对城市规划、环境监测和位置服务等应用至关重要。与建筑物、道路等物理实体不同,这些社会语义类别缺乏明确的视觉特征,其定义依赖于人类活动与功能,因此难以通过传统仅依赖视觉的模型进行分割。以往方法依赖POI等辅助地理空间数据,但面临数据稀缺、格式异构、空间错位以及对未见类别的泛化能力有限等问题。为解决上述问题,作者提出SocioSeg,一个将多模态地理空间数据统一为空间对齐的数字地图层的新基准数据集,支持一致的视觉推理任务。进一步提出SocioReasoner,一种视觉-语言推理框架,通过两阶段“渲染-精炼”流程模拟人类标注过程:首先从卫星图像与地图图像生成边界框提示,然后通过SAM结合点提示进行精炼分割。由于该流程不可微,作者采用强化学习与自定义奖励函数优化整个工作流,有效释放了视觉-语言模型的推理潜力。该方法在性能与零样本泛化方面均达到最先进水平,充分展示了跨模态推理在复杂城市理解中的强大能力。
数据集

- SocioSeg数据集基于通过高德地图公开API获取的公开卫星影像与数字地图构建,覆盖中国所有省份及主要城市。
- 数据集包含超过13,000个样本,分为三个分层的社会语义分割任务:Socio-names(如“北京大学”)、Socio-classes(如“大学”)和Socio-functions(如“教育”),涵盖超过5,000个唯一Socio-names、90个Socio-classes和10个Socio-functions。
- 真实标签源自高德地图的“兴趣区域”(AOI)数据,通过严格的质量控制流程,将基于矢量的多边形重新格式化为栅格化语义掩码。
- 数据集从初始约40,000个样本中经人工验证AOI多边形与物理边界的对齐性,最终筛选出13,000个高质量样本。
- 在500个随机样本上进行标注者间一致性研究,Cohen’s Kappa达0.854,表明标签具强一致性与可靠性。
- 每个样本包含一张卫星图像、一张数字地图和对应的社会语义掩码,数字地图层整合道路与兴趣点,作为统一且配准的模态。
- 数据集按6:1:3比例划分为训练集、验证集与测试集,各层级任务中样本数量与类别分布均保持均衡。
- 作者在训练与评估中使用该数据集,采用三种分层任务的混合策略,并设置任务特定的训练比例以支持渐进式学习。
- 未采用显式裁剪策略,而是使用与AOI原始地理范围对齐的全场景输入。
- 元数据基于高德地图的标准分类体系与功能区定义构建,确保与真实城市社会活动一致,支持稳健的社会推理。
方法
SocioReasoner框架采用两阶段推理分割流程,旨在模拟人类标注者的顺序工作流,提升精度与可解释性。整体架构由一个视觉-语言模型(VLM)构成,该模型以结构化文本提示驱动冻结的分割模型SAM,形成“渲染-精炼”机制。该过程分为两个阶段:定位与精炼。
第一阶段,VLM接收卫星图像、数字地图与文本指令,生成一组2D边界框以定位候选感兴趣区域。这些边界框作为提示输入SAM,生成初步粗略掩码。随后,将粗略掩码与初始边界框渲染回原始输入,为第二阶段提供视觉反馈。如图所示,该渲染步骤将边界框与粗略掩码叠加至卫星图像与数字地图,生成一对增强图像,由VLM重新评估。
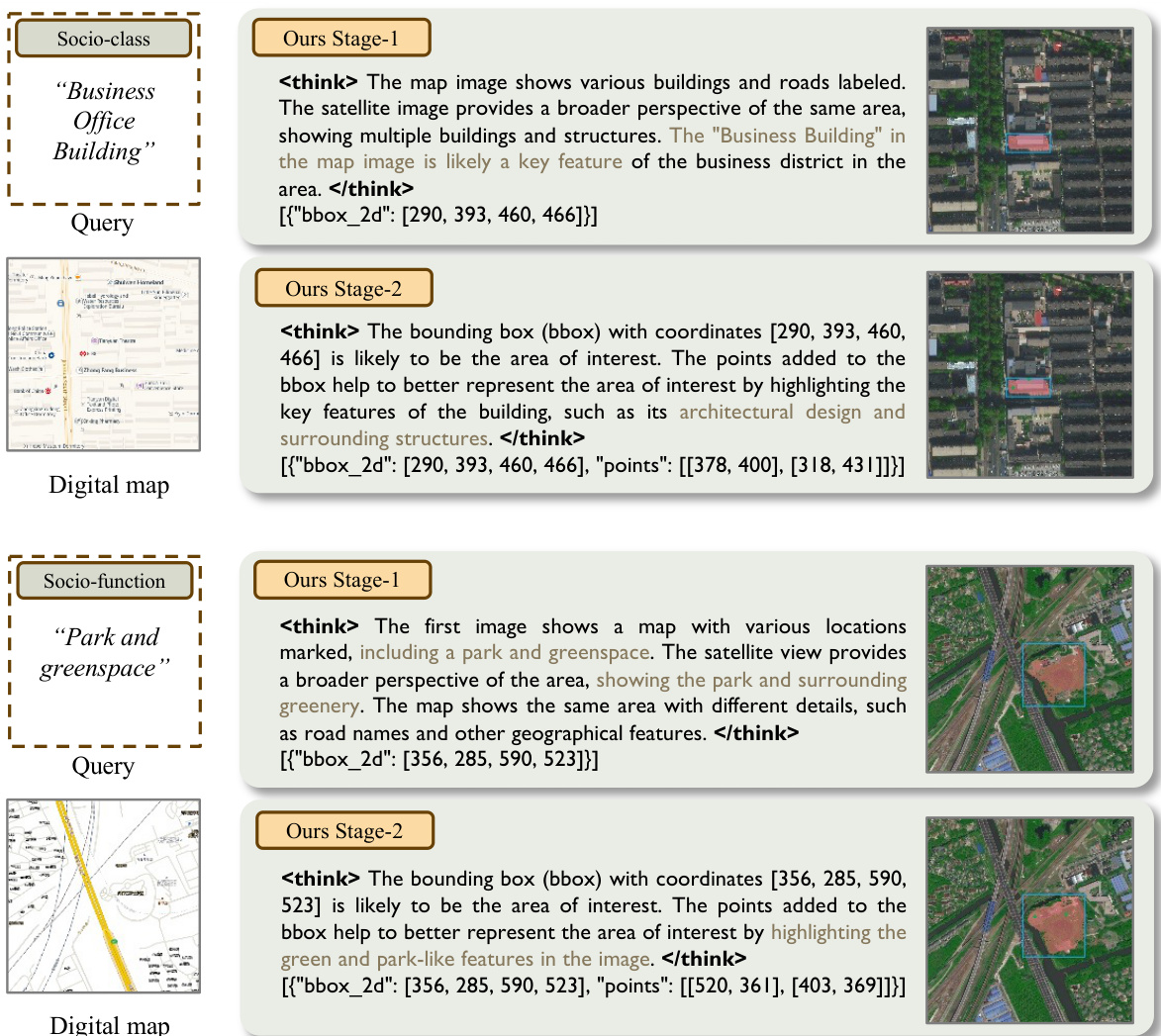
第二阶段,VLM基于渲染后的图像与新的文本指令,输出一组优化后的边界框与点提示。这些组合提示被反馈至SAM,生成最终分割掩码。整个流程因提示生成的离散性与SAM参数固定而不可微,需采用可处理此类结构的优化策略。
为优化两阶段中VLM的提示策略,作者采用分组相对策略优化(GRPO),一种强化学习方法。两个阶段共享单一VLM策略,生成编码提示的结构化文本输出。环境解析这些输出,使用解析后的提示执行SAM,并返回标量奖励。优化过程分为两个阶段:第一阶段,策略基于初始输入生成边界框,环境通过二元语法检查、定位精度与目标数量匹配计算奖励;第二阶段,策略基于渲染后的视觉反馈与粗略掩码进行提示精炼,奖励包含像素级IoU度量与点集长度项。
训练流程在单个强化学习步骤内顺序执行两阶段:首先采样并评估第一阶段的轨迹,使用第一阶段目标更新策略;随后基于第一阶段输出构建第二阶段输入,重复该过程。该两阶段机制确保优化与“定位-精炼”的顺序工作流一致。整体训练算法如算法1所示,详细描述了端到端的强化学习流程。
实验
- 与三类方法对比:标准语义分割(UNet、SegFormer)、自然图像推理分割(VisionReasoner、Seg-R1、SAM-R1)以及卫星图像分割(SegEarth-OV、RSRefSeg、SegEarth-R1、RemoteReasoner)。所有基线模型均在SocioSeg训练集上重新训练;必要时适配双图像输入。
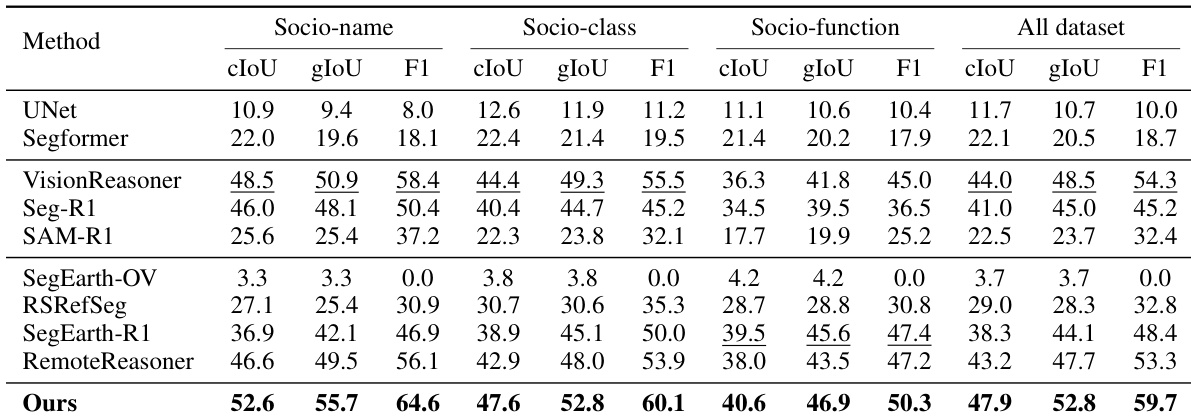
- 在SocioSeg测试集上,SocioReasoner在所有三个分层任务中均达到最先进性能,cIoU与gIoU显著优于基线,验证了其两阶段类人推理过程与卫星-地图上下文融合的有效性。
- 显著优于标准模型(UNet、SegFormer),后者无法处理多模态输入与社会语义,将任务退化为二分类。
- 超越自然图像推理方法(VisionReasoner、Seg-R1、SAM-R1),得益于多阶段精炼机制,实现自我修正与更优几何精度,尽管推理时间更长。
- 超越卫星专用方法:SegEarth-OV因冻结CLIP编码器而表现不佳;RSRefSeg与SegEarth-R1因单图像输入与社会语义有限而表现欠佳;RemoteReasoner被SocioReasoner的两阶段定位与精炼超越。
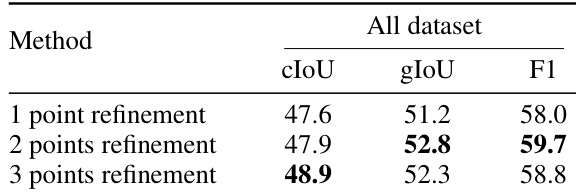
- 消融实验验证两阶段设计的优越性:“无反馈”(单阶段)表现最差,因缺乏自我修正;“无精炼”(仅第一阶段)表现不佳;第二阶段采用两点精炼时性能最优。
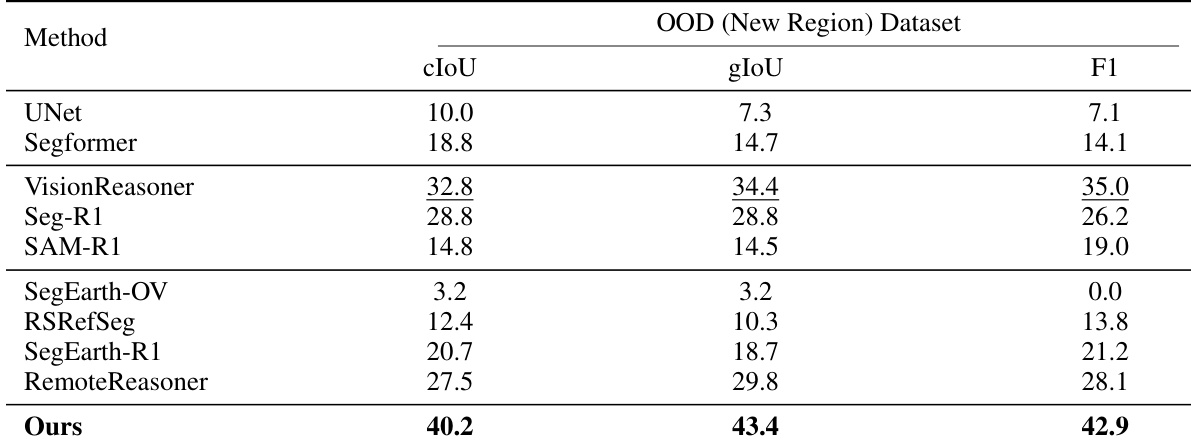
- 强化学习(RL)训练显著提升泛化能力:SocioReasoner(RL)在域内(Amap)与域外(OOD)数据集上均优于SFT基线,包括OOD(地图风格)与OOD(新区域)数据集,后者涵盖五个全球城市中的24个新类别。
- 在OOD(新区域)数据集上,SocioReasoner在所有指标上均达最高性能,展现出对地理与制图差异的强鲁棒性。
- 推理时间高于基线,因迭代推理机制,但更高的精度与泛化能力使其权衡合理。
- 按类别分析显示,对前20个高频类别表现优异;特定类别(如“培训场所”、“羽毛球馆”)准确率较低,源于初始定位失败导致的误差传播。
- 失败案例揭示两大问题:复杂城市区域中的定位失败与边界不精确,凸显将抽象社会语义映射至精确空间边界的挑战。
作者比较了SocioReasoner在精炼阶段使用不同点数的影响,结果显示使用三个点时cIoU与F1得分最高,而两个点时gIoU最优。这表明增加点数可提升整体分割精度,但最优选择取决于评估指标。
作者将SocioReasoner框架与多个大型多模态模型(包括GPT-5、GPT-o3与Qwen2.5-VL变体)在SocioSeg基准上进行对比。结果表明,尽管GPT-5与GPT-o3表现中等,但Qwen2.5-VL-72b模型表现最佳,在所有任务中均取得最高cIoU与gIoU,尤其在Socio-name与Socio-function分割任务中优势显著。

作者在OOD(新区域)数据集上将SocioReasoner与多个最先进方法进行对比,该数据集评估在多样化地理区域中的性能并包含新类别。结果表明,SocioReasoner在所有指标(cIoU、gIoU、F1)上均取得最高分,展现出优于基线的卓越泛化能力与鲁棒性。
作者采用多阶段推理框架,在SocioSeg基准的所有任务中全面超越所有基线,于Socio-name与Socio-function分割任务中均取得cIoU、gIoU与F1的最高分。结果表明,所提方法显著超越标准分割模型与最先进推理方法,尤其通过迭代精炼与双图像输入处理,有效捕捉复杂社会语义。
作者在SocioSeg基准上将SocioReasoner与多个最先进方法进行对比,结果显示其在所有指标上均表现最佳。具体而言,SocioReasoner(rl)在cIoU上达2.71,显著高于第二名VisionReasoner的1.33,全面超越VisionReasoner、SAM-R1与RemoteReasoner等基线。