Command Palette
Search for a command to run...
解锁隐性经验:从文本中合成工具使用轨迹
解锁隐性经验:从文本中合成工具使用轨迹
Zhihao Xu Rumei Li Jiahuan Li Rongxiang Weng Jingang Wang Xunliang Cai Xiting Wang
摘要
使大型语言模型(LLMs)在多轮交互中有效利用工具,是构建强大自主代理的关键。然而,获取多样化且真实的多轮工具使用数据仍是一项重大挑战。在本研究中,我们提出了一种新颖的基于文本的范式。我们观察到,文本语料库天然蕴含丰富的多步骤问题求解经验,可作为未被充分挖掘、可扩展且真实可靠的多轮工具使用任务数据来源。基于这一洞察,我们提出了GEM——一种数据合成流水线,通过四阶段流程实现从文本语料库中生成并提取多轮工具使用轨迹:相关性过滤、工作流与工具提取、轨迹定位以及复杂度优化。为降低计算成本,我们进一步采用监督微调训练了一个专用的轨迹生成器(Trajectory Synthesizer)。该模型将复杂的生成流程压缩为一个高效、端到端的轨迹生成器。实验表明,我们的GEM-32B在BFCL V3多轮基准测试中实现了16.5%的性能提升。在特定领域数据(Airline与Retail)上,我们的模型性能部分超越了在τ-bench数据上训练的模型,凸显了基于文本合成范式所具备的优越泛化能力。值得注意的是,该轨迹生成器在保持与完整流水线相当生成质量的同时,显著降低了推理延迟与计算成本。
一句话总结
中国人民大学与美团的研究人员提出 GEM,一种基于文本的数据合成框架,通过四阶段流水线从语料库中生成逼真的多轮工具使用轨迹,实现了高效训练蒸馏后的轨迹生成器,其性能与全流水线相当但延迟更低,在 BFCL V3 上达到最先进水平,并在航空和零售任务中超越领域内模型。
主要贡献
-
现有训练多轮工具使用智能体的方法依赖预定义 API 和仿真环境,由于获取完整工具集成本高、难度大,导致数据多样性与真实性受限;本文提出一种基于文本的新范式,利用非结构化文本语料库——富含真实世界、多步骤问题求解叙事——作为可扩展且真实的数据源,用于生成工具使用轨迹。
-
所提出的 GEM 流水线通过四个阶段系统地将文本工作流转化为结构化、多轮工具使用轨迹:相关性过滤、工作流与工具提取、轨迹定位与复杂度优化,实现了无需预定义工具即可合成高质量、跨领域数据。
-
实验表明,基于 GEM 合成数据训练的模型在 BFCL V3 多轮基准上提升 14.9%,并达到在领域内 τ-bench 数据上训练模型的性能水平;而蒸馏后的轨迹生成器在显著降低推理成本与延迟的同时,仍保持同等质量。
引言
作者针对真实世界工具使用自主智能体的训练挑战展开研究,现有方法依赖预定义 API 模拟交互,限制了数据多样性与可扩展性。该方法面临数据稀缺与领域覆盖狭窄的问题,阻碍了泛化能力。为克服这一局限,他们提出一种新颖的“文本到轨迹”范式,直接从非结构化真实文本语料库(如操作文档)中提取多轮工具使用工作流,利用人类问题求解叙事的内在丰富性。其 GEM 流水线系统性地选择、提取、生成并优化高质量轨迹,将文本工作流转化为具有真实约束、模糊性与复杂依赖关系的结构化智能体交互。实验表明,基于 GEM 合成数据训练的模型在基准任务上取得显著提升,包括在 BFCL V3 多轮任务上实现 14.9% 的性能增益,并展现出强大的跨领域泛化能力,媲美在领域内数据上训练的模型。该方法实现了可扩展、低成本且真实的数据生成,为更鲁棒、更具泛化能力的智能体系统铺平道路。
数据集

- 数据集通过四阶段流水线合成,将原始文本转化为高质量、多轮工具使用轨迹,以真实世界文本片段作为原始材料。
- 第一阶段对原始文本片段进行过滤,仅保留描述多步操作的片段,使用第 3.1 节中的相同标注提示与模型,以确保真实性和质量。
- 第二阶段,流水线从文本中提取抽象工作流并合成功能性工具,每个工具均遵循 OpenAI 模式标准——设计为单一、连贯的功能,具有清晰的参数名称与数据类型。
- 第三阶段使用强教师模型(GLM-4.6)生成完整的多轮轨迹,输出结构化内容,包括系统提示、用户请求、助手回复以及多轮对话中的真实工具响应。
- 第四阶段对轨迹进行优化,以提升复杂度、多样性和真实性——扩展工具种类、增强环境反馈、引入模糊或复杂用户查询,并确保工具调用链非平凡。
- 验证分为两个阶段:首先进行基于规则的检查,确保结构正确性(有效工具定义、格式规范、闭合角色标签);其次由 LLM 判官(Qwen3-32B)验证所有工具参数是否语境合理且无幻觉。
- 仅通过两个验证阶段的轨迹被保留为 Tfinal,用于监督微调(SFT)。
- 通过 SFT 训练数据合成器,学习从原始文本到多轮工具使用轨迹的端到端映射,实现低成本、可扩展的数据生成。
- 数据集在训练中采用来自多样化领域的轨迹混合,如图 9 所示的领域分析所示,确保广泛覆盖与真实世界相关性。
- 处理过程包括元数据构建,如工具定义、角色标签与结构化对话组件,未进行裁剪——完整轨迹按生成状态保留。
方法
作者利用一种新颖的数据合成流水线 GEM,旨在直接从大规模文本语料库生成多轮工具使用轨迹。该方法与传统依赖预定义工具与合成仿真的方法形成对比,后者常缺乏真实人类问题求解行为的多样性与真实性。整体框架如图所示,包含四个阶段:相关性过滤、工作流与工具提取、轨迹定位与复杂度优化。流水线首先处理原始文本语料库,识别并保留描述多步工作流的片段。这些片段随后用于提取功能性工具及其对应工作流,并进一步转化为可执行轨迹。为提升效率与可扩展性,作者进一步通过监督微调训练专用的轨迹生成器。该模型将复杂的多阶段生成过程蒸馏为端到端生成器,实现低成本、高吞吐量的数据合成,同时保持轨迹质量。

该方法分为两个主要阶段。第一阶段“工具与工作流提取”涵盖文本过滤及抽象工作流与功能性工具的提取。原始文本语料库首先经过文本过滤,剔除非多步操作内容,保留描述多步流程的片段。从这些片段中,流水线提取工作流并以 JSON 或 OpenAI 模式格式设计功能性工具。此阶段对轨迹基础组件的建立至关重要,确保工具及其交互基于真实、现实世界的逻辑。提取的工具设计为语义清晰、可复用,并实现单一、连贯的能力,参数明确指定以反映现实世界约束。

第二阶段“轨迹生成”涉及实际轨迹的创建与优化。该阶段始于初始轨迹生成步骤,使用系统提示与用户任务生成初步轨迹。随后对轨迹进行优化,以增强其复杂度与多样性,鼓励包含多种交互模式,如澄清、错误恢复与遵守领域规则。优化后的轨迹经过最终验证流程,包括基于规则的检查以确保格式与工具调用有效,以及基于 LLM 的判官评估智能体的沟通能力、工具调用鲁棒性、推理与执行能力。该验证确保最终输出为高质量、多样化且真实的数据,适用于自主智能体训练。整个流程旨在生成包含多种交互模式的轨迹,总计至少出现三种不同模式,且每种模式在单个轨迹中最多使用两次。

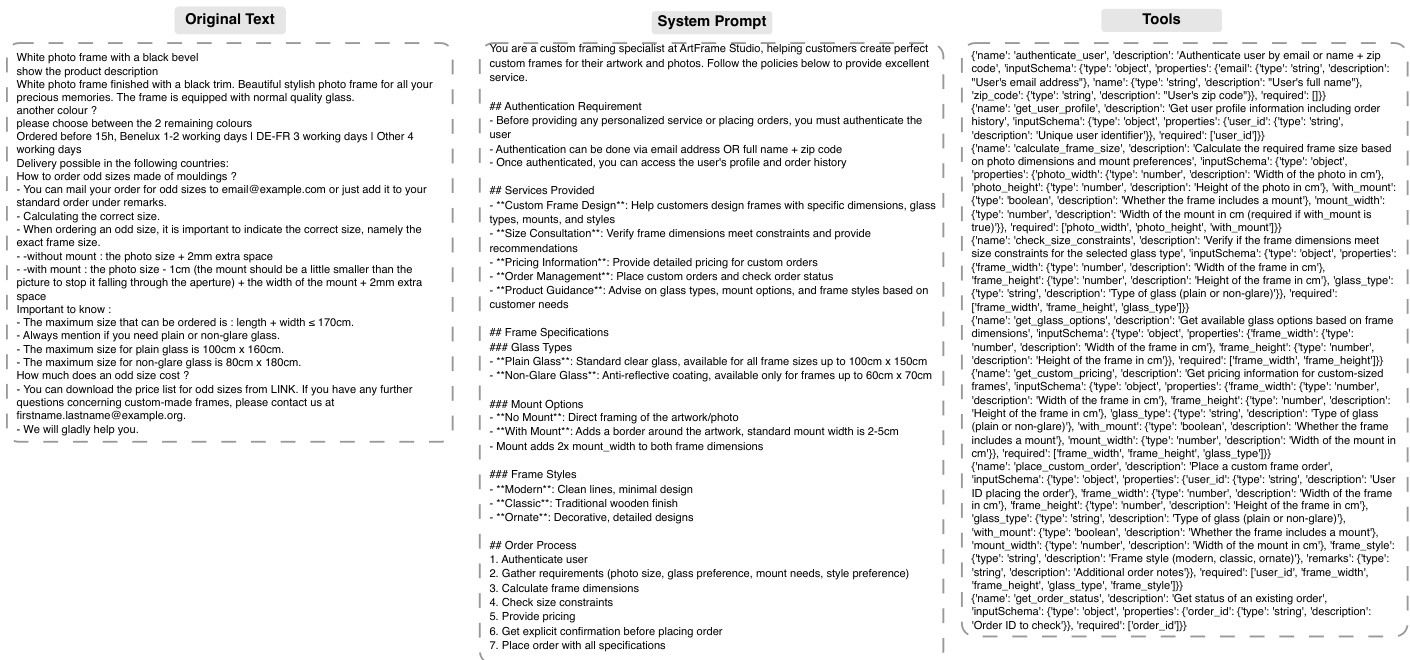
如图所示,系统提示为智能体生成适当工具调用提供必要的上下文与约束。其包含认证要求、服务内容、框架规格及操作顺序。工具以详细输入模式定义,确保参数类型正确并经过验证。提示还包含系统规则与约束,如框架最大尺寸与特定功能可用性,智能体必须遵守。这种结构化方法确保生成的轨迹不仅多样化,而且真实且扎根于特定领域,使其在训练自主智能体方面极为有效。最终输出为高质量的智能体轨迹数据集,可用于训练模型在多轮交互中有效使用工具。
实验
- 对 Ultra-fineWeb 语料库的初步分析表明,采样文本片段中 14% 包含多步工作流,揭示了任务类别、工具与环境的丰富多样性,验证了直接从非结构化文本中提取智能体轨迹的可行性。
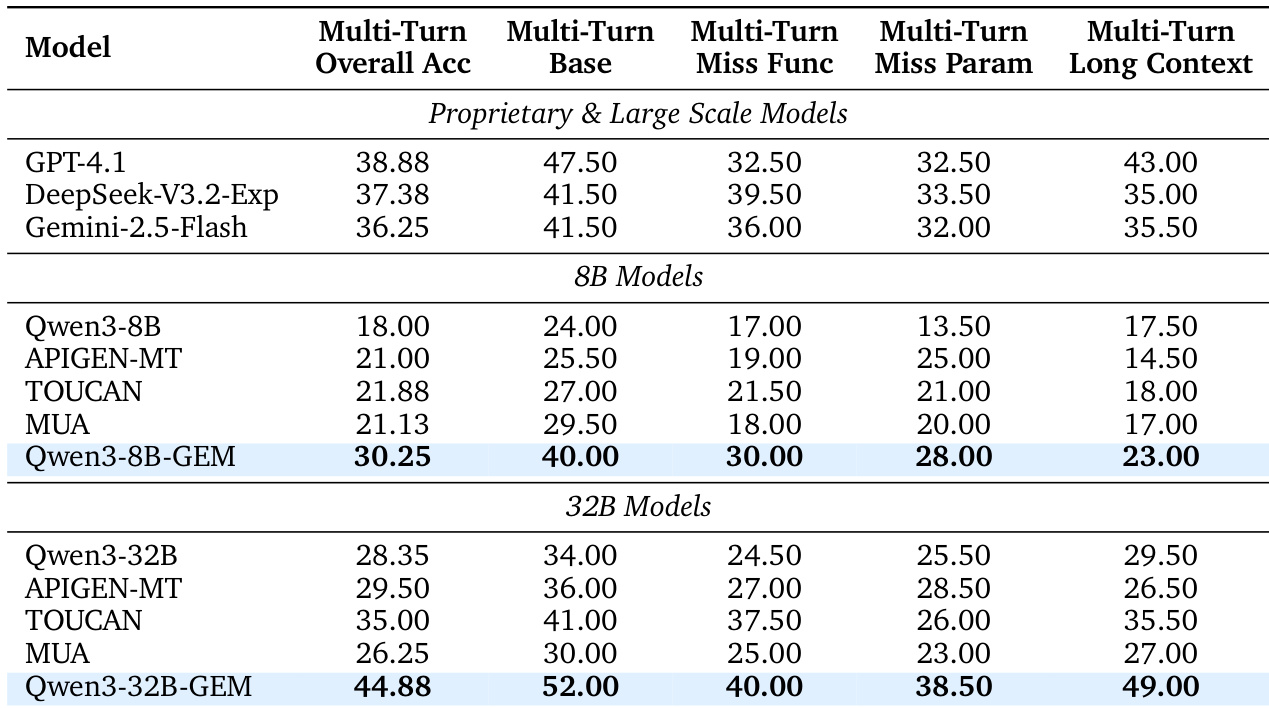
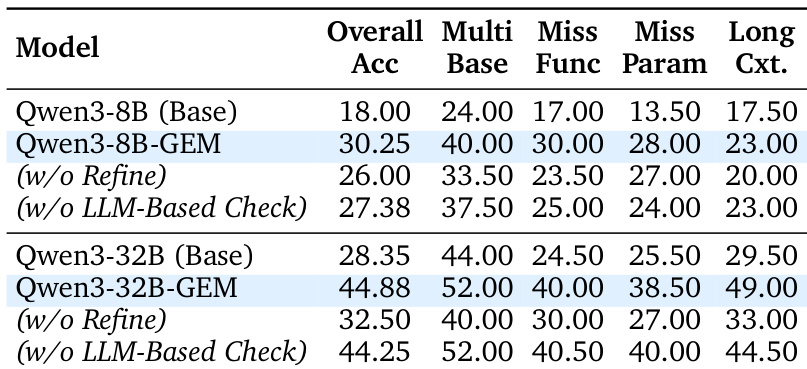
- GEM 合成流水线从文本生成高质量、跨领域合成轨迹,在 BFCL V3(8B)上达到 30.25% 准确率,在 32B 上达到 44.88%,超越开源基线及 GPT-4.1(38.88%)与 DeepSeek-V3.2-Exp(37.38%)等专有模型。
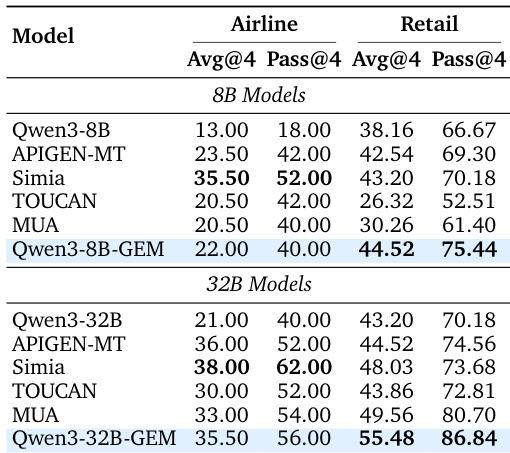
- 在 tau2-bench(航空与零售)上,Qwen3-8B-GEM 在零售任务中达到 Pass@4 75.44%,Qwen3-32B-GEM 达到 86.84%,尽管训练数据严格为跨领域,仍优于领域内基线如 SIMIA 与 MUA,展现出强大泛化能力。
- 在 10K 轨迹上训练的 GEM 合成器达到竞争性性能(BFCL 上 28.38%,tau2-零售上 Pass@4 73.68%),并可泛化至 Wikihow 等其他数据源,证实其低成本、端到端的有效性。
- 消融实验表明,优化阶段提升轨迹复杂度(如 32B 上准确率提升 +12.38%),基于 LLM 的检查减少幻觉,使 8B 模型性能提升 2.87%。
- 合成轨迹平均包含 8.6 个工具、46 轮对话、16.3 次工具调用——远超现有数据集复杂度,支持多轮、工具驱动推理的稳健训练。
作者使用 BFCL V3 基准评估多轮工具使用性能,结果显示 Qwen3-8B-GEM 总体准确率达 30.25%,优于其他开源模型,并在特定类别上匹配或超越 GPT-4.1 等专有模型。对于 32B 规模,Qwen3-32B-GEM 达到 44.88% 总体准确率,超越开源基线与 DeepSeek-V3.2-Exp 等专有模型,证明其合成数据流水线的有效性。
结果表明,优化阶段显著提升了合成轨迹的复杂度,平均消息数从 30.05 提升至 46.1,工具数从 5.01 提升至 8.6,工具调用数从 7.83 提升至 16.3。这表明优化增强了生成多轮工具使用交互的深度与丰富性。

作者通过优化阶段与基于 LLM 的检查提升合成工具使用轨迹质量,带来两个模型规模上的显著性能提升。结果显示,优化后的 Qwen3-8B-GEM 与 Qwen3-32B-GEM 在航空与零售领域上的 Avg@4 与 Pass@4 分数均高于未优化版本,证明优化过程在提升轨迹复杂度与准确性方面的有效性。
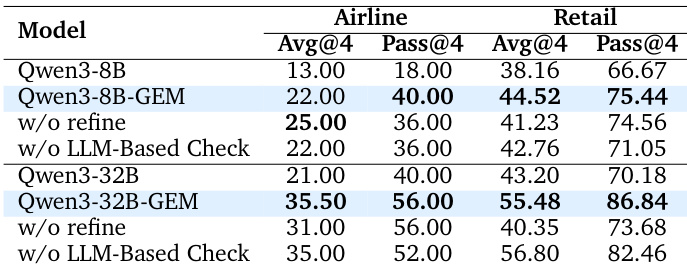
作者通过消融实验评估优化与基于 LLM 的检查对模型性能的影响,结果表明两个阶段均显著提升效果。移除优化阶段使 Qwen3-32B-GEM 总体准确率从 44.88% 降至 32.50%,而省略 LLM 检查使 Qwen3-8B-GEM 准确率从 30.25% 降至 27.38%,表明每个组件对合成轨迹质量均有实质性贡献。
结果显示,Qwen3-8B-GEM 在航空领域总体准确率为 22.00%,Pass@4 为 40.00%;Qwen3-32B-GEM 分别达到 35.50% 与 56.00%。这些结果表明,GEM 方法显著优于基线模型,Qwen3-32B-GEM 在开源模型中表现领先,并在零售领域取得具有竞争力的结果。